1 Preface
Elasticsearch is a popular search engine in Java. The traditional database search uses the like 'keyword%'. When there is too much content, the performance will be greatly reduced, so elasticsearch appears.
Next, record the installation process of Elasticsearch under Linux.
2. Install Elasticsearch under Linux
2.1 download and unzip the installation package
-
Official website download address: https://www.elastic.co/cn/downloads/elasticsearch
Select the appropriate version to download, and then upload it to Linux
You can also directly execute the following commands on the Linux command line to download (the download is slow):
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.13.2-linux-x86_64.tar.gz -
Execute the decompression command:
tar -zxvf elasticsearch-7.13.2-linux-x86_64.tar.gz -C /usr/local
2.2 solving the problem of es strongly relying on jdk
Because es and jdk are strongly dependent, when we include our own jdk in the ElasticSearch package of the new version, but after we have installed the jdk in Linux, we will find that when we start es, we first look for the installed jdk in Linux. At this time, if the jdk versions are inconsistent, the jdk will not run normally. The error is as follows:
Note: if the jdk is not configured for the Linux service, the default jdk under the es directory will be used directly, but no error will be reported
warning: usage of JAVA_HOME is deprecated, use ES_JAVA_HOME Future versions of Elasticsearch will require Java 11; your Java version from [/usr/local/jdk1.8.0_291/jre] does not meet this requirement. Consider switching to a distribution of Elasticsearch with a bundled JDK. If you are already using a distribution with a bundled JDK, ensure the JAVA_HOME environment variable is not set.
terms of settlement:
-
Enter the bin directory
cd /usr/local/elasticsearch-7.13.2/bin -
Modify elasticsearch configuration
vim ./elasticsearch############## Add configuration resolution jdk Version problem ############## # Modify the jdk to the configuration directory of the jdk in es export JAVA_HOME=/usr/local/elasticsearch-7.13.2/jdk export PATH=$JAVA_HOME/bin:$PATH if [ -x "$JAVA_HOME/bin/java" ]; then JAVA="/usr/local/elasticsearch-7.13.2/jdk/bin/java" else JAVA=`which java` fi
2.3 solve the problem of insufficient memory
Since the jvm space allocated by elasticsearch is 2g by default, it is unnecessary to modify the jvm space if the Linux server is originally configured with a high configuration.
error:
OpenJDK 64-Bit Server VM warning: INFO: os::commit_memory(0x00000000c6a00000, 962592768, 0) failed; error='Not enough space' (errno=12)
at org.elasticsearch.tools.launchers.JvmOption.flagsFinal(JvmOption.java:119)
at org.elasticsearch.tools.launchers.JvmOption.findFinalOptions(JvmOption.java:81)
at org.elasticsearch.tools.launchers.JvmErgonomics.choose(JvmErgonomics.java:38)
at org.elasticsearch.tools.launchers.JvmOptionsParser.jvmOptions(JvmOptionsParser.java:13
Enter the config folder to start configuration and edit the JVM options:
vim /usr/local/elasticsearch-7.13.2/config/jvm.options
The default configuration is as follows: -Xms2g -Xmx2g The default configuration takes up too much memory. Turn it down: -Xms256m -Xmx256m
2.4 create a dedicated user to start ES
root cannot directly start Elasticsearch, so you need to create a special user to start ES
java.lang.RuntimeException: can not run elasticsearch as root
at org.elasticsearch.bootstrap.Bootstrap.initializeNatives(Bootstrap.java:101)
at org.elasticsearch.bootstrap.Bootstrap.setup(Bootstrap.java:168)
at org.elasticsearch.bootstrap.Bootstrap.init(Bootstrap.java:397)
at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:159)
at org.elasticsearch.bootstrap.Elasticsearch.execute(Elasticsearch.java:150)
at org.elasticsearch.cli.EnvironmentAwareCommand.execute(EnvironmentAwareCommand.java:75)
at org.elasticsearch.cli.Command.mainWithoutErrorHandling(Command.java:116)
at org.elasticsearch.cli.Command.main(Command.java:79)
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:115)
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:81)
-
Create user
useradd user-es -
Create group:
chown user-es:user-es -R /usr/local/elasticsearch-7.13.2 -
Switch to user es user
su user-es -
Enter the bin directory
cd /usr/local/elasticsearch-7.13.2/bin -
Start elasticsearch
./elasticsearch
If the following error message appears (the maximum number of files is too small, the thread is too small, and the memory is too low):
2.5 modify ES core configuration information
-
Execute the command to modify elasticsearch YML file content
vim /usr/local/elasticsearch-7.13.2/config/elasticsearch.yml -
Modify data and log directories
You don't need to modify it here. If you don't modify it, it will be placed in the elasticsearch root directory by default# Data directory location path.data: /home/New user name/elasticsearch/data # Log directory location path.logs: /home/New user name/elasticsearch/logs
-
Modify the bound ip to allow remote access
#Only local access is allowed by default. After it is modified to 0.0.0.0, it can be accessed remotely # Bind to 0.0.0.0 and allow any ip to access network.host: 0.0.0.0
-
Initialization node name
cluster.name: elasticsearch node.name: es-node0 cluster.initial_master_nodes: ["es-node0"]
-
Modify port number (not required)
http.port: 19200
2.6 vm.max_map_count [65530] is too low
The above steps still fail to start successfully. Continue to solve the problem:
ERROR: [1] bootstrap checks failed. You must address the points described in the following [1] lines before starting Elasticsearch. bootstrap check failure [1] of [1]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
elasticsearch user has too little memory permission and needs at least 262144. Solution:
In / etc / sysctl The conf file can be permanently modified by adding the following contents at the end
-
Switch to root
Execute the command: su root -
Execute command
vim /etc/sysctl.conf -
Add the following
vm.max_map_count=262144 -
Save exit, refresh configuration file
sysctl -p -
Switch the user es user and continue to start
su user-es -
Start es service
/usr/local/elasticsearch-7.13.2/bin/elasticsearch
After successful startup, you can http://127.0.0.1:19200/ Access. If the following contents appear, the ES installation is successful:
{
"name": "es-node0",
"cluster_name": "elasticsearch",
"cluster_uuid": "SRwJX4sYQ8el4N5wj4tOmA",
"version": {
"number": "7.13.2",
"build_flavor": "default",
"build_type": "tar",
"build_hash": "4d960a0733be83dd2543ca018aa4ddc42e956800",
"build_date": "2021-06-10T21:01:55.251515791Z",
"build_snapshot": false,
"lucene_version": "8.8.2",
"minimum_wire_compatibility_version": "6.8.0",
"minimum_index_compatibility_version": "6.0.0-beta1"
},
"tagline": "You Know, for Search"
}
2.7 possible max file descriptors [4096] problems
[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65535]
Switch to root and execute the command:
vi /etc/security/limits.conf
Add the following:
* soft nofile 65536 * hard nofile 131072 * soft nproc 2048 * hard nproc 4096
Then restart linux
2.8 start and stop of ES service
-
The foreground runs, and Ctrl + C terminates the program
./elasticsearch -
Background operation
./elasticsearch -d
Start complete when started appears -
Shut down ES service
kill pidexplain:
Elasticsearch port 9300, 9200, where:
9300 is the tcp communication port, which is used for communication between cluster ES nodes, and 9200 is the RESTful interface of http protocol
Well, the stand-alone Elasticsearch service has finally been installed. It's still a little troublesome~
3. Install the elasticsearch head plug-in
Easticsearch only provides various restful APIs on the back end, so how can we intuitively see its information?
Elasticsearch head is a client tool for elasticsearch, which is used to display data.
Elastic search head is written in JavaScript language and can be deployed using npm
npm is the package manager under Nodejs.
3.1 installing node environment
If the Linux service has installed the node environment, you can skip this step. If there is no node environment, you can refer to another blog post: Installing node environment under Linux
When the npm environment is ready, install elastic search head
3.2 installing elasticsearch head
3.2.1 download elasticsearch head installation package
Download address: https://github.com/mobz/elasticsearch-head
3.2.2 unzip the zip package
Execute command:
unzip elasticsearch-head-5.0.0.zip
Move the installation package to / usr/local:
mv elasticsearch-head-5.0.0 /usr/local/
3.2.3 npm install
-
Enter the installation directory
cd /usr/local/elasticsearch-head-5.0.0 -
Execute command installation
npm install
Note: if the execution fails, you can install cnpm. Before using cnpm, you need to install cnpm through
npm install -g cnpm --registry=https://registry.npm.taobao.org This command installs -
Display all usage help information
npm -l
Under the root directory of each project, there is usually a package JSON file, which defines various modules required by the project and the configuration information of the project (such as metadata such as name, version, license, etc.)
The npm install command automatically downloads the required modules according to the configuration file, that is, the running and development environment required for the configuration project.
3.2.4 start elasticsearch head service
-
Start service
npm run start or NPM run script start -
It can be started in the background
nohup npm run-script start &
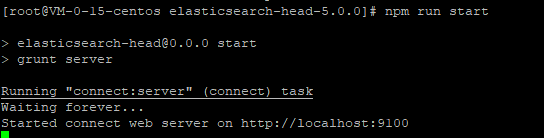
The following figure shows that the elasticsearch head service is started successfully:
3.2.5 accessing elasticsearch head service
Then visit: http://localhost:9100/
Elasticsearch head service accessed successfully:

3.2.6 accessing elasticsearch using Head plug-in
Failed to access. To allow cross domain, you need to modify elasticsearch YML file, add the following:
http.cors.enabled: true http.cors.allow-origin: "*"
The following interface appears, indicating that the access is successful:

Well, this tutorial is here first. Welcome old fellow commentary.
Reference links: https://www.cnblogs.com/jhtian/p/12664890.html
Blogging is to remember what you are easy to forget, and it is also a summary of your work. I hope you can make your own efforts to do better and make progress together!
If there is any problem, you are welcome to discuss it together. If there is any problem with the code, you are welcome to correct it!
Add a pair of wings to your dream so that it can fly freely in the sky!