Inspiration from ziplost to quicklist and then listpack
When introducing Redis's optimized design of data structure to improve memory utilization, it mentioned that compressed list (ziplost) can be used to save data. So now you should also know that the biggest feature of ziplost is that it is designed as a memory compact data structure, occupying a continuous memory space, so as to save memory.
However, in the computer system, any design has both advantages and disadvantages. The same holds for ziplist. Although ziplist saves memory overhead, it also has two design costs:
- First, you cannot save too many elements, otherwise the access performance will be reduced;
- Second, you can't save too large elements, otherwise it will easily lead to memory reallocation and even chain update. The so-called chain update simply means that each item in the ziplost has to be reallocated memory space, resulting in reduced performance of the ziplost.
Therefore, in view of the design deficiency of ziplist, Redis code has designed two new data structures in the process of development and evolution:
- quicklist
- listpack
The design goal of these two data structures is to maintain the memory saving advantages of ziplist as much as possible and avoid the potential performance degradation of ziplist. In today's class, I'll give you a detailed introduction to the design and implementation ideas of quicklist and listpack. However, before specifically explaining these two data structures, I'd like to take you to understand why the design of zipplist has defects. In this way, you can compare the design of quicklist and listpack with that of ziplist, so that you can more easily master the design considerations of quicklist and listpack.
Moreover, the difference between ziplist and quicklist is also a frequently asked interview question. Because the listpack data structure is relatively new, you may not know much about its design and implementation. After learning this lesson, you can actually easily deal with the use of these three data structures. In addition, you can learn from the step-by-step optimization design of these three data structures the design trade-offs adopted by Redis data structures between memory overhead and access performance. If you need to develop efficient data structures, you can apply this design idea.
OK, then, let's first understand the defects in the design and implementation of ziplist.
Deficiency of ziplost
As you already know, the layout of a ziplost data structure in memory is a continuous memory space. The starting part of this space is a fixed size 10 byte metadata, which records the total bytes of ziplist, the offset of the last element and the number of list elements, while the memory space behind these 10 bytes stores the actual list data. In the last part of the ziplost, a 1-byte identifier (fixed to 255) is used to indicate the end of the ziplost, as shown in the following figure:
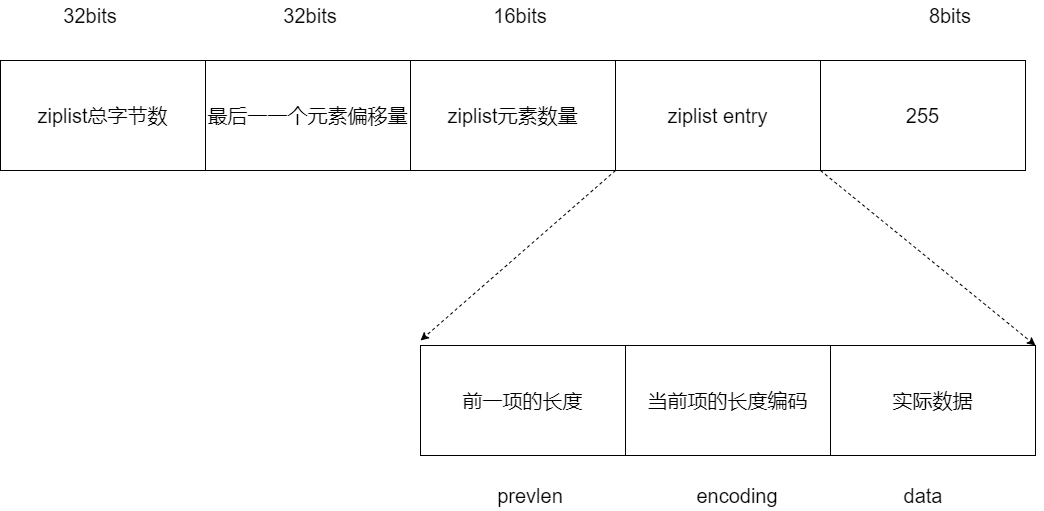
However, although ziplist saves memory space by saving data through a compact memory layout, ziplist also faces two subsequent shortcomings: high search complexity and potential chain update risk. Now, let's understand these two problems respectively.
High search complexity
Because the size of the header and tail metadata of the ziplost is fixed, and the location of the last element is recorded in the ziplost header, you can quickly find the first or last element in the ziplost.
But the problem is that when you want to find the elements in the middle of the list, ziplost has to traverse from the beginning or end of the list. When the ziplost saves too many elements, the complexity of finding intermediate data increases. What's worse, if a string is saved in the ziplost, the ziplost needs to judge each character of the element one by one when looking for an element, which further increases the complexity.
Because of this, when we use ziplist to save Hash or Sorted Set data, we will be in redis In the conf file, the number of elements saved in the ziplost is controlled by two parameters: Hash Max ziplost entries and Zset Max ziplost entries.
Moreover, in addition to the high search complexity, if the memory space is insufficient when inserting elements, the ziplost also needs to reallocate a continuous memory space, which will further lead to the problem of chain update.
Continuous update risk
We know that because ziplst must use a continuous memory space to save data, when a new element is inserted, ziplst needs to calculate the required space and apply for the corresponding memory space. In this series of operations, we can insert functions from the elements of the ziplost__ Zip listinsert__ The ziplistInsert function first calculates the length of the current ziplist. This step is through ziplist_ The bytes macro definition can be completed, as shown below. At the same time, the function also declares the reqlen variable, which is used to record the new space required after inserting the element.
Ziplost. Exe of the source code C file. The following is the complete code of this function. First show the complete code, and then look at the details.
/* Insert item at "p". */
unsigned char *__ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen) {
// Get the current ziplost length curlen; Declare the reqlen variable to record the required length of the newly inserted element
size_t curlen = intrev32ifbe(ZIPLIST_BYTES(zl)), reqlen, newlen;
unsigned int prevlensize, prevlen = 0;
size_t offset;
int nextdiff = 0;
unsigned char encoding = 0;
long long value = 123456789; /* initialized to avoid warning. Using a value
that is easy to see if for some reason
we use it uninitialized. */
zlentry tail;
// If the insertion position is not at the end of the ziplost, the length of the previous item is obtained
/* Find out prevlen for the entry that is inserted. */
if (p[0] != ZIP_END) {
ZIP_DECODE_PREVLEN(p, prevlensize, prevlen);
} else {
unsigned char *ptail = ZIPLIST_ENTRY_TAIL(zl);
if (ptail[0] != ZIP_END) {
prevlen = zipRawEntryLengthSafe(zl, curlen, ptail);
}
}
/* See if the entry can be encoded */
if (zipTryEncoding(s,slen,&value,&encoding)) {
/* 'encoding' is set to the appropriate integer encoding */
reqlen = zipIntSize(encoding);
} else {
/* 'encoding' is untouched, however zipStoreEntryEncoding will use the
* string length to figure out how to encode it. */
reqlen = slen;
}
/* We need space for both the length of the previous entry and
* the length of the payload. */
reqlen += zipStorePrevEntryLength(NULL,prevlen);
reqlen += zipStoreEntryEncoding(NULL,encoding,slen);
/* When the insert position is not equal to the tail, we need to
* make sure that the next entry can hold this entry's length in
* its prevlen field. */
int forcelarge = 0;
nextdiff = (p[0] != ZIP_END) ? zipPrevLenByteDiff(p,reqlen) : 0;
if (nextdiff == -4 && reqlen < 4) {
nextdiff = 0;
forcelarge = 1;
}
/* Store offset because a realloc may change the address of zl. */
offset = p-zl;
newlen = curlen+reqlen+nextdiff;
zl = ziplistResize(zl,newlen);
p = zl+offset;
/* Apply memory move when necessary and update tail offset. */
if (p[0] != ZIP_END) {
/* Subtract one because of the ZIP_END bytes */
memmove(p+reqlen,p-nextdiff,curlen-offset-1+nextdiff);
/* Encode this entry's raw length in the next entry. */
if (forcelarge)
zipStorePrevEntryLengthLarge(p+reqlen,reqlen);
else
zipStorePrevEntryLength(p+reqlen,reqlen);
/* Update offset for tail */
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+reqlen);
/* When the tail contains more than one entry, we need to take
* "nextdiff" in account as well. Otherwise, a change in the
* size of prevlen doesn't have an effect on the *tail* offset. */
assert(zipEntrySafe(zl, newlen, p+reqlen, &tail, 1));
if (p[reqlen+tail.headersize+tail.len] != ZIP_END) {
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+nextdiff);
}
} else {
/* This element will be the new tail. */
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(p-zl);
}
/* When nextdiff != 0, the raw length of the next entry has changed, so
* we need to cascade the update throughout the ziplist */
if (nextdiff != 0) {
offset = p-zl;
zl = __ziplistCascadeUpdate(zl,p+reqlen);
p = zl+offset;
}
/* Write the entry */
p += zipStorePrevEntryLength(p,prevlen);
p += zipStoreEntryEncoding(p,encoding,slen);
if (ZIP_IS_STR(encoding)) {
memcpy(p,s,slen);
} else {
zipSaveInteger(p,value,encoding);
}
ZIPLIST_INCR_LENGTH(zl,1);
return zl;
}
Then__ The ziplistInsert function determines whether the current position to insert is at the end of the list. If it is not the end, you need to get the prevlen and prevlensize of the element at the current insertion position. This part of the code is as follows:
// If the insertion position is not at the end of the ziplost, the length of the previous item is obtained
/* Find out prevlen for the entry that is inserted. */
if (p[0] != ZIP_END) {
ZIP_DECODE_PREVLEN(p, prevlensize, prevlen);
} else {
unsigned char *ptail = ZIPLIST_ENTRY_TAIL(zl);
if (ptail[0] != ZIP_END) {
prevlen = zipRawEntryLengthSafe(zl, curlen, ptail);
}
}
In fact, in the ziplost, each element will record the length of its previous item, that is, prevlen. Then, in order to save memory overhead, ziplist will use different space to record prevlen. The size of this prevlen space is prevlensize.
For A simple example, when A new element B is inserted in front of an element A, the prevlen and prevlensize of A must change accordingly according to the length of B. So now, Let's assume that the prevlen of A only occupies 1 byte (that is, prevlensize is equal to 1), and the maximum length of the previous item that can be recorded is 253 bytes. At this time, if the length of B exceeds 253 bytes, the prevlen of A needs to use 5 bytes to record (for the specific encoding method of prevlen, you can review and review Lecture 4), so you need to apply for an additional 4 bytes of space. However, if the insertion position of element B is at the end of the list, we don't need to consider the prevlen of the following elements when inserting element B.
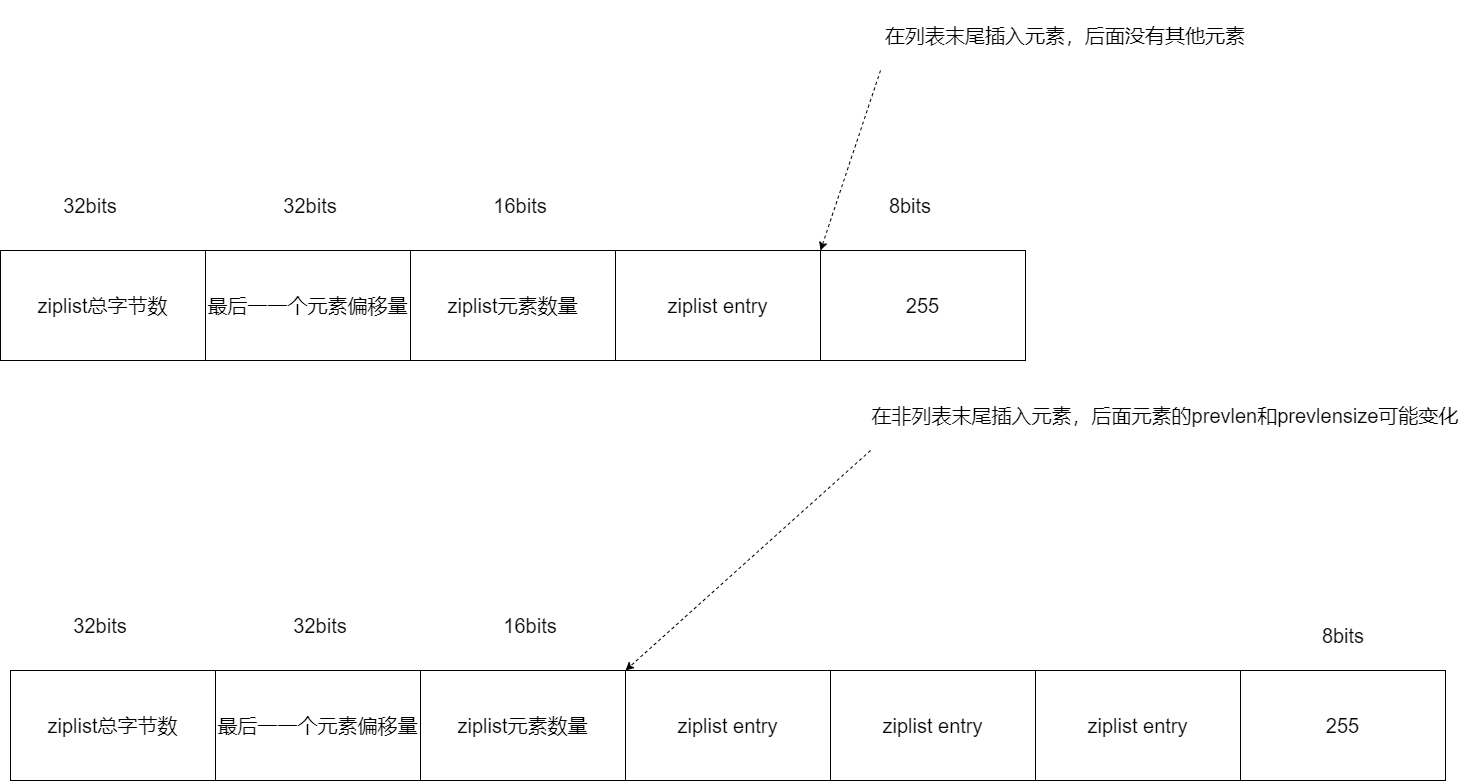
Therefore, in order to ensure that the ziplist has enough memory space to store the prevlen information of the inserted element and the inserted position element__ The ziplistInsert function obtains the prevlen and prevlensize of the insertion position element, and then calculates the length of the insertion element.
Now we know that a ziplost element includes three parts: prevlen, encoding and actual data. Therefore, when calculating the space required to insert elements__ The ziplist insert function also calculates the length of these three parts respectively. This calculation process can be divided into four steps.
-
The first step is to calculate the length of the actual inserted element.
-
First of all, you should know that the calculation process is related to whether the inserted element is an integer or a string__ The ziplistInsert function will first call the zipTryEncoding function, which will determine whether the inserted element is an integer.
-
If it is an integer, calculate the space required for encoding and actual data according to different integer sizes;
-
If it is a string, record the length of the string as the required additional space. The code of this process is as follows:
-
/* See if the entry can be encoded */
if (zipTryEncoding(s,slen,&value,&encoding)) {
// If it is an integer, calculate the space required for encoding and actual data according to different integer sizes;
/* 'encoding' is set to the appropriate integer encoding */
reqlen = zipIntSize(encoding);
} else {
// If it is a string, record the length of the string as the required additional space.
/* 'encoding' is untouched, however zipStoreEntryEncoding will use the
* string length to figure out how to encode it. */
reqlen = slen;
}
- The second step is to call the zipStorePrevEntryLength function to calculate the prevlen of the insertion position element into the required space.
This is because after inserting the element__ The ziplistInsert function may allocate additional space for the element at the insertion location. This part of the code is as follows:
/* We need space for both the length of the previous entry and * the length of the payload. */
reqlen += zipStorePrevEntryLength(NULL,prevlen);
- Step 3: call the zipStoreEntryEncoding function to calculate the corresponding encoding size according to the length of the string.
In the first step just now__ The ziplistInsert function only records the length of the string itself for string data, so in step 3__ The zipstinsert function also calls the zipStoreEntryEncoding function to calculate the corresponding encoding size according to the length of the string, as shown below:
reqlen += zipStoreEntryEncoding(NULL,encoding,slen);
Well, here, the ziplistInsert function has recorded the prevlen length, encoding size of the inserted element and the length of the actual data in the reqlen variable. In this way, the overall length of the inserted element is, which is also the size to be recorded by the prevlen of the inserted element.
- Step 4: call the zipPrevLenByteDiff function to determine the prevlen of the insertion position element and the actual required prevlen size.
Finally__ The ziplistInsert function will call the zipPrevLenByteDiff function to determine the size difference between the prevlen of the inserted element and the prevlen actually required. This part of the code is as follows. The size difference of prevlen is recorded using nextdiff:
nextdiff = (p[0] != ZIP_END) ? zipPrevLenByteDiff(p,reqlen) : 0;
Here, if nextdiff is greater than 0, it indicates that there is not enough space for the insertion position element. You need to add a space of nextdiff size to save the new prevlen. Then__ When the ziplistInsert function adds a new space, it will call the ziplistResize function to reallocate the space required by the ziplist. The parameters received by the ziplistResize function are the ziplist to be reallocated and the size of the reallocated space respectively. And__ The parameter of reallocation size passed in by ziplistInsert function is the sum of three lengths. So what is the sum of the three lengths? The three lengths are
- ziplist existing size (curlen)
- Additional space required for the element to be inserted itself (reqlen)
- And the new space (nextdiff) required to insert the location element prevlen.
The following code shows the call and parameter passing logic of the ziplistResize function:
newlen = curlen+reqlen+nextdiff; zl = ziplistResize(zl,newlen);
Further, how to expand the capacity of the ziplisterresize function after obtaining the sum of the three lengths?
We can take a further look at the implementation of the ziplisterresize function. This function will call the zrealloc function to reallocate the space, and the size of the reallocated space is determined by the passed in parameter len. In this way, we know that the ziplistResize function involves memory allocation. Therefore, if we frequently insert too much data into the ziplist, it may cause multiple memory allocations, which will affect the performance of Redis.
The following code shows a partial implementation of the ziplistResize function, you can take a look.
/* Resize the ziplist. */
unsigned char *ziplistResize(unsigned char *zl, size_t len) {
assert(len < UINT32_MAX);
// Reallocate the memory space of zl. The reallocated size is len
zl = zrealloc(zl,len);
ZIPLIST_BYTES(zl) = intrev32ifbe(len);
zl[len-1] = ZIP_END;
return zl;
}
Well, so far, we've learned that when ziplist inserts new elements, it calculates the required new space and reallocates it. When the newly inserted element is large, the prevlensize of the element at the insertion position will increase, which will also increase the space occupied by the element at the insertion position.
In this way, this new space will cause the problem of chain update.
In fact, the so-called chain update means that when an element is inserted, it will cause the current element to add prevlensize space. When the space of the current location element increases, it will further increase the space required for prevlensize of subsequent elements of the element.
In this way, once all subsequent elements at the insertion position are inserted, their own space will increase due to the increase of prevlenszie of previous elements. The phenomenon that the space of each element needs to be increased is chain update. I drew the picture below. You can have a look.
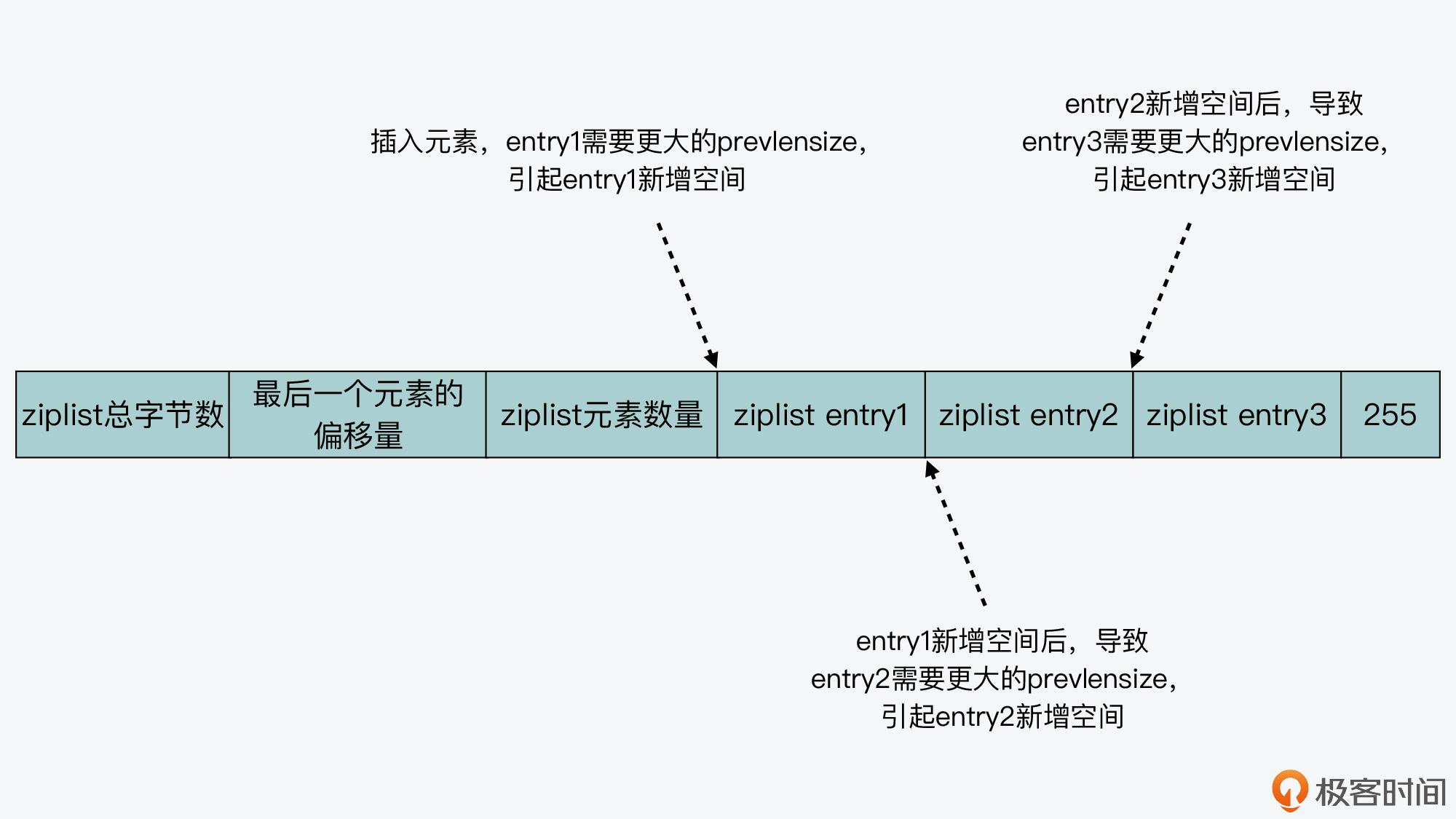
Once the chain update occurs, the memory space occupied by ziplist will be reallocated many times, which will directly affect the access performance of ziplist. Therefore, although the compact memory layout of ziplist can save memory overhead, if the number of saved elements increases or the elements become larger, ziplist will face performance problems. So, is there any way to avoid the problem of ziplost? This is the design idea of quicklist and listpack, the two data structures I want to introduce to you next.
Design and implementation of quicklist
The design of quicklist actually combines the respective advantages of linked list and zipplist. Simply put, a quicklist is a linked list, and each element in the linked list is a zip list.
Let's take a look at the data structure of quicklist, which is in quicklist H file, and the specific implementation of quicklist is in quicklist C in the document. First, the definition of the quicklist element, that is, quicklistNode. Because quicklist is a linked list, each quicklistNode contains pointers * prev and * next pointing to its pre order and post order nodes respectively. At the same time, each quicklistNode is a ziplost. Therefore, in the structure of quicklistNode, there is a pointer * zl to ziplost.
In addition, some attributes are defined in the quicklistNode structure, such as the byte size of ziplost, the number of elements contained, encoding format, storage method, etc. The following code shows the structure definition of quicklistNode. You can have a look.
On QuickList You can see it in H
/* Node, quicklist, and Iterator are the only data structures used currently. */
/* quicklistNode is a 32 byte struct describing a ziplist for a quicklist.
* We use bit fields keep the quicklistNode at 32 bytes.
* count: 16 bits, max 65536 (max zl bytes is 65k, so max count actually < 32k).
* encoding: 2 bits, RAW=1, LZF=2.
* container: 2 bits, NONE=1, ZIPLIST=2.
* recompress: 1 bit, bool, true if node is temporary decompressed for usage.
* attempted_compress: 1 bit, boolean, used for verifying during testing.
* extra: 10 bits, free for future use; pads out the remainder of 32 bits */
typedef struct quicklistNode {
// Previous quicklistNode
struct quicklistNode *prev;
// The last quicklistNode
struct quicklistNode *next;
// Ziplost pointed to by quicklistNode
unsigned char *zl;
// Byte size of ziplost
unsigned int sz; /* ziplist size in bytes */
// Number of elements in ziplost
unsigned int count : 16; /* count of items in ziplist */
// Encoding format, native byte array or compressed storage
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
// Storage mode
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
// Is the data compressed
unsigned int recompress : 1; /* was this node previous compressed? */
// Can data be compressed
unsigned int attempted_compress : 1; /* node can't compress; too small */
// Reserved bit
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
After understanding the definition of quicklistNode, let's look at the structure definition of quicklist.
As a linked list structure, quicklist defines the head and tail pointers of the whole quicklist in its data structure. In this way, we can quickly locate the chain header and tail of quicklist through the data structure of quicklist.
In addition, the quicklist also defines attributes such as the number of quicklistnodes and the total number of elements of all zip lists. The structure definition of quicklist is as follows:
/* quicklist is a 40 byte struct (on 64-bit systems) describing a quicklist.
* 'count' is the number of total entries.
* 'len' is the number of quicklist nodes.
* 'compress' is: 0 if compression disabled, otherwise it's the number
* of quicklistNodes to leave uncompressed at ends of quicklist.
* 'fill' is the user-requested (or default) fill factor.
* 'bookmakrs are an optional feature that is used by realloc this struct,
* so that they don't consume memory when not used. */
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count; /* total count of all entries in all ziplists */
unsigned long len; /* number of quicklistNodes */
int fill : QL_FILL_BITS; /* fill factor for individual nodes */
unsigned int compress : QL_COMP_BITS; /* depth of end nodes not to compress;0=off */
unsigned int bookmark_count: QL_BM_BITS;
quicklistBookmark bookmarks[];
} quicklist;
Then, from the structure definitions of quicklistNode and quicklist, we can draw the following schematic diagram of quicklist.
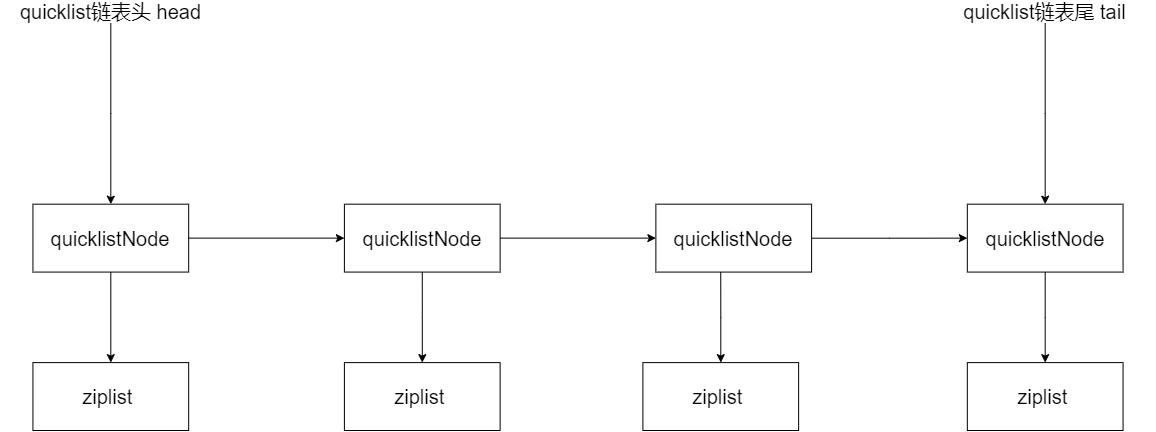
Because quicklist adopts a linked list structure, when inserting a new element, quicklist will first check whether the ziplost at the insertion position can accommodate the element_ quicklistNodeAllowInsert function to complete the judgment.
_ The quicklistNodeAllowInsert function will calculate the size of the newly inserted element (new_sz), which is equal to the current size of the quicklistNode (node - > SZ), the size of the inserted element (SZ), and the prevlen occupation size of the ziplost after the element is inserted. After calculating the size, _quicklistnodeallowinsertfunction will judge the newly inserted data size in turn (SZ) whether it meets the requirements, that is, whether a single ziplost does not exceed 8KB, or whether the number of elements in a single ziplost meets the requirements. As long as one of these conditions is met, quicklist can insert new elements into the current quicklistNode, otherwise quicklist will create a new quicklistNode to save the newly inserted elements. The following code shows You can see the judgment logic of whether to allow inserting data into the current quicklistNode.
On QuickList C file can be viewed
REDIS_STATIC int _quicklistNodeAllowInsert(const quicklistNode *node,
const int fill, const size_t sz) {
if (unlikely(!node))
return 0;
int ziplist_overhead;
/* size of previous offset */
if (sz < 254)
ziplist_overhead = 1;
else
ziplist_overhead = 5;
/* size of forward offset */
if (sz < 64)
ziplist_overhead += 1;
else if (likely(sz < 16384))
ziplist_overhead += 2;
else
ziplist_overhead += 5;
/* new_sz overestimates if 'sz' encodes to an integer type */
unsigned int new_sz = node->sz + sz + ziplist_overhead;
if (likely(_quicklistNodeSizeMeetsOptimizationRequirement(new_sz, fill)))
return 1;
/* when we return 1 above we know that the limit is a size limit (which is
* safe, see comments next to optimization_level and SIZE_SAFETY_LIMIT) */
else if (!sizeMeetsSafetyLimit(new_sz))
return 0;
else if ((int)node->count < fill)
return 1;
else
return 0;
}
In this way, by controlling the size or the number of elements in each quicklistNode, quicklist can effectively reduce the chain update after adding or modifying elements in ziplist, thus providing better access performance.
In addition to designing the quicklist structure to deal with the problem of zipplist, Redis also added the listpack data structure in version 5.0 to completely avoid chain updates. Let's continue to learn its design and implementation ideas. Design and implementation of listpack
Design and implementation of listpack
Listpack is also called compact list. Its feature is to use a continuous memory space to compactly save data. At the same time, in order to save memory space, listpack list items use a variety of encoding methods to represent data of different lengths, including integers and strings.
The implementation file related to listpack is listpack c. The header file includes listpack H and listpack_malloc.h.
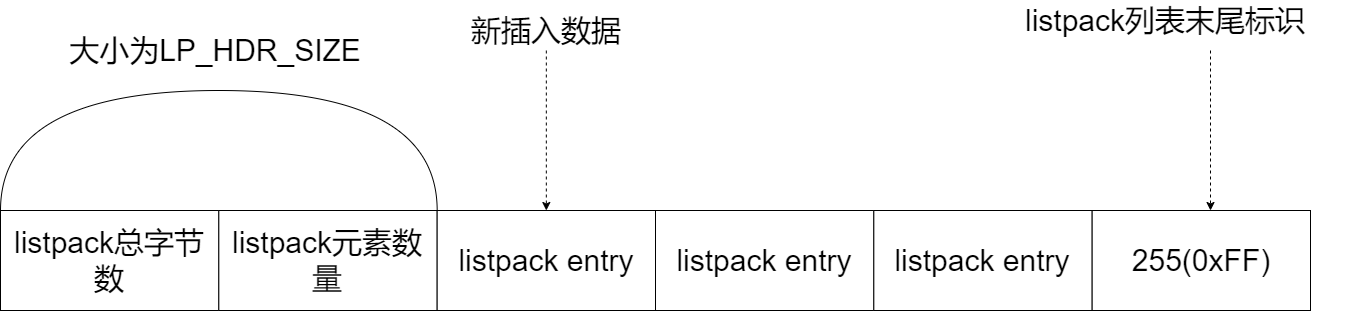
Let's first look at the creation function lpNew of listpack, because from the code logic of this function, we can understand the overall structure of listpack. The lpNew function creates an empty listpack. The initial allocated size is LP_HDR_SIZE plus 1 byte. LP_ HDR_ The size macro is defined in listpack In C, it defaults to 6 bytes, of which 4 bytes are the total number of bytes recording listpack, and 2 bytes are the number of elements recording listpack. In addition, the last byte of listpack is used to identify the end of listpack, and its default value is macro definition LP_EOF. Like the end tag of the ziplost list item, LP_ The EOF value is also 255.
listpack.c view in file
Macro definition
#define LP_HDR_SIZE 6 /* 32 bit total len + 16 bit number of elements. */ #define LP_EOF 0xFF
function
/* Create a new, empty listpack.
* On success the new listpack is returned, otherwise an error is returned.
* Pre-allocate at least `capacity` bytes of memory,
* over-allocated memory can be shrinked by `lpShrinkToFit`.
* */
unsigned char *lpNew(size_t capacity) {
unsigned char *lp = lp_malloc(capacity > LP_HDR_SIZE+1 ? capacity : LP_HDR_SIZE+1);
if (lp == NULL) return NULL;
lpSetTotalBytes(lp,LP_HDR_SIZE+1);
lpSetNumElements(lp,0);
lp[LP_HDR_SIZE] = LP_EOF;
return lp;
}
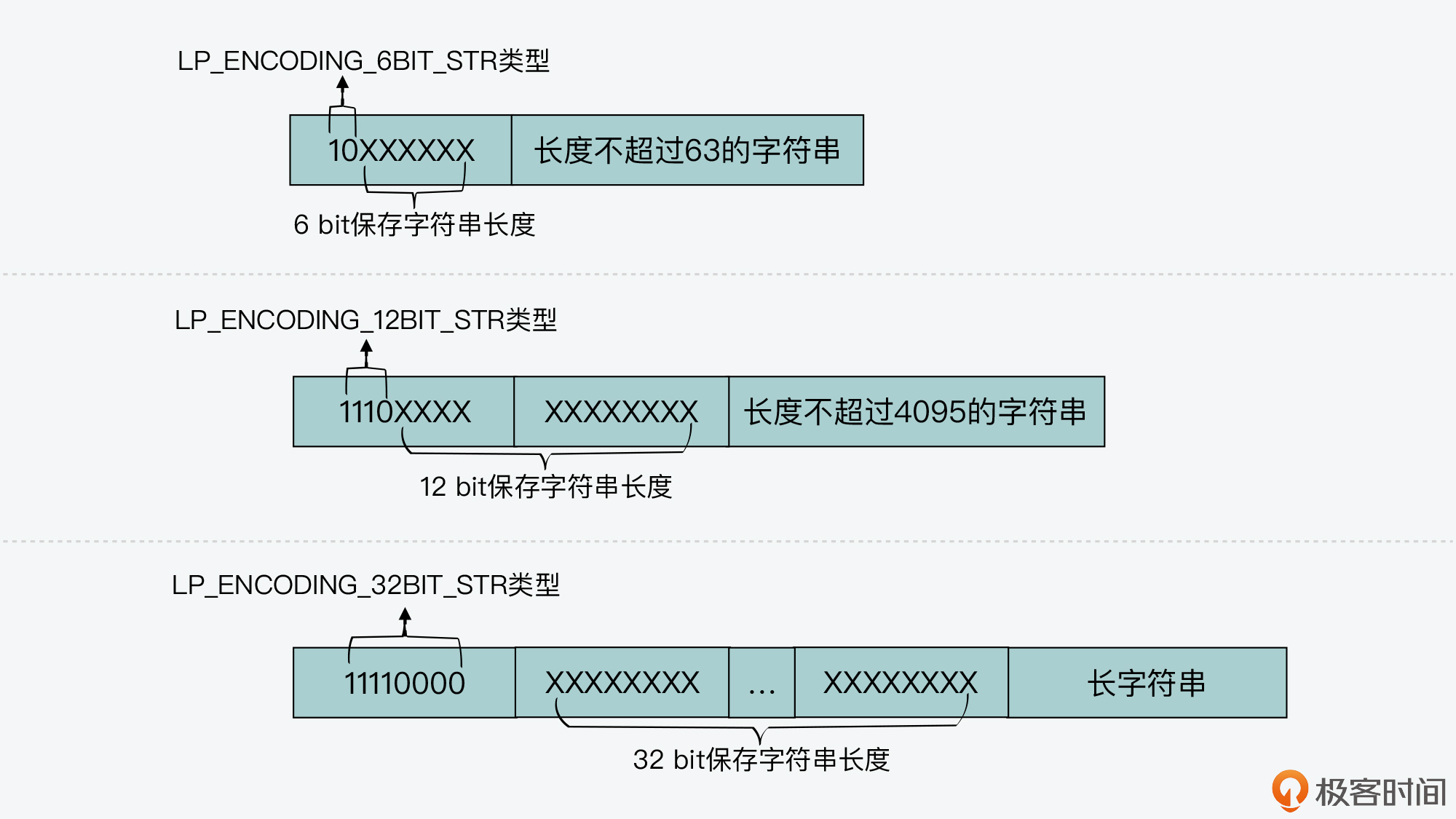
You can take a look at the figure below, which shows the size of LP_ HDR_ The listpack header of size and the listpack tail with a value of 255. When a new element is inserted, it will be inserted between the head and tail of the listpack.
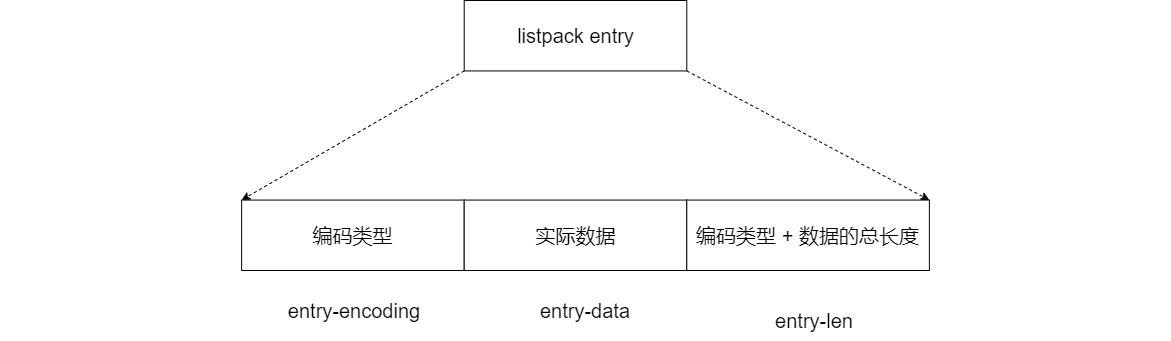
Well, after understanding the overall structure of listpack, let's take a look at the design of listpack list items. Like the ziplost list item, the listpack list item also contains metadata information and the data itself. However, in order to avoid the chain update problem caused by ziplost, each list item in listpack will no longer save the length of its previous list item like ziplost list item. It will only contain three aspects, namely
- The encoding type of the current element (entry encoding)
- Element data (entry data)
- And the length of the encoding type and element data (entry len)
As shown in the figure below.
Here, for the design of listpack list items, you need to focus on two key points: the coding type of list item elements and the method to avoid chain update of list items. Now I'll show you the details. Listpack list item encoding method let's first look at the encoding type of listpack elements. If you read listpack C file, you will find a large number of similar LP in this file_ ENCODING_ N_ BIT_ Int and LP_ ENCODING_ N_ BIT_ The macro definition of STR is as follows:
#define LP_ENCODING_7BIT_UINT 0 #define LP_ENCODING_7BIT_UINT_MASK 0x80 #define LP_ENCODING_IS_7BIT_UINT(byte) (((byte)&LP_ENCODING_7BIT_UINT_MASK)==LP_ENCODING_7BIT_UINT) #define LP_ENCODING_6BIT_STR 0x80 #define LP_ENCODING_6BIT_STR_MASK 0xC0 #define LP_ENCODING_IS_6BIT_STR(byte) (((byte)&LP_ENCODING_6BIT_STR_MASK)==LP_ENCODING_6BIT_STR) #define LP_ENCODING_13BIT_INT 0xC0 #define LP_ENCODING_13BIT_INT_MASK 0xE0 #define LP_ENCODING_IS_13BIT_INT(byte) (((byte)&LP_ENCODING_13BIT_INT_MASK)==LP_ENCODING_13BIT_INT) #define LP_ENCODING_12BIT_STR 0xE0 #define LP_ENCODING_12BIT_STR_MASK 0xF0 #define LP_ENCODING_IS_12BIT_STR(byte) (((byte)&LP_ENCODING_12BIT_STR_MASK)==LP_ENCODING_12BIT_STR) #define LP_ENCODING_16BIT_INT 0xF1 #define LP_ENCODING_16BIT_INT_MASK 0xFF #define LP_ENCODING_IS_16BIT_INT(byte) (((byte)&LP_ENCODING_16BIT_INT_MASK)==LP_ENCODING_16BIT_INT) #define LP_ENCODING_24BIT_INT 0xF2 #define LP_ENCODING_24BIT_INT_MASK 0xFF #define LP_ENCODING_IS_24BIT_INT(byte) (((byte)&LP_ENCODING_24BIT_INT_MASK)==LP_ENCODING_24BIT_INT) #define LP_ENCODING_32BIT_INT 0xF3 #define LP_ENCODING_32BIT_INT_MASK 0xFF #define LP_ENCODING_IS_32BIT_INT(byte) (((byte)&LP_ENCODING_32BIT_INT_MASK)==LP_ENCODING_32BIT_INT) #define LP_ENCODING_64BIT_INT 0xF4 #define LP_ENCODING_64BIT_INT_MASK 0xFF #define LP_ENCODING_IS_64BIT_INT(byte) (((byte)&LP_ENCODING_64BIT_INT_MASK)==LP_ENCODING_64BIT_INT) #define LP_ENCODING_32BIT_STR 0xF0 #define LP_ENCODING_32BIT_STR_MASK 0xFF #define LP_ENCODING_IS_32BIT_STR(byte) (((byte)&LP_ENCODING_32BIT_STR_MASK)==LP_ENCODING_32BIT_STR)
These macro definitions actually correspond to the element encoding type of listpack. Specifically * *, the listpack element encodes integers and strings of different lengths * *. Let's take a look at them separately here.
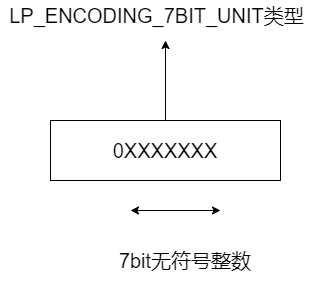
First, for integer encoding, when the encoding type of listpack element is LP_ENCODING_7BIT_UINT indicates that the actual data of the element is a 7-bit unsigned integer. And because LP_ ENCODING_ 7BIT_ The macro definition value of uint itself is 0, so the value of encoding type is 0, accounting for 1 bit.
At this time, the encoding type and the actual data of the element share one byte. The highest bit of this byte is 0, indicating the encoding type. The subsequent 7 bit s are used to store 7-bit unsigned integers, as shown in the following figure:
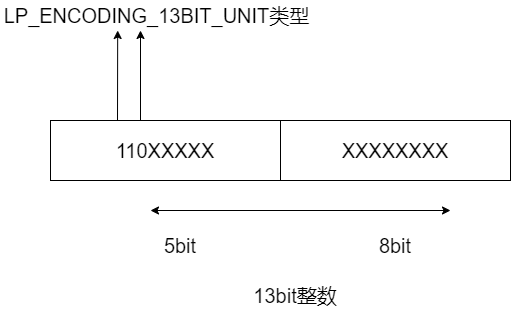
When the encoding type is LP_ENCODING_13BIT_INT, this indicates that the actual data of the element is a 13 bit integer. At the same time, because LP_ ENCODING_ 13BIT_ The macro definition value of int is 0xC0, which is converted to a binary value of 11 million. Therefore, the last 5 bits and the subsequent 1 byte of this binary value, a total of 13 bits, will be used to save 13bit integers. The first three bits 110 in the binary value are used to represent the current encoding type. I drew the picture below. You can have a look.
OK, after understanding LP_ENCODING_7BIT_UINT and LP_ ENCODING_ 13BIT_ After the two coding types of int, the remaining LP_ENCODING_16BIT_INT,LP_ENCODING_24BIT_INT,LP_ENCODING_32BIT_INT and LP_ENCODING_64BIT_INT, you should also know their coding method. These four types save integer data with 2 bytes (16 bit), 3 bytes (24 bit), 4 bytes (32 bit) and 8 bytes (64 bit) respectively. At the same time, their encoding type itself accounts for 1 byte, and their encoding type values are their macro definition values respectively.
Then, for string encoding, there are three types: LP_ENCODING_6BIT_STR,LP_ENCODING_12BIT_STR and LP_ENCODING_32BIT_STR. From the introduction just now, you can see that the number in front of bit in the integer encoding type name represents the length of the integer. Therefore, similarly, the number before bit in the string encoding type name represents the length of the string.
For example, when the encoding type is LP_ENCODING_6BIT_STR, the encoding type occupies 1 byte. The macro definition value of this type is 0x80 and the corresponding binary value is 1000 0000. The first two bits are used to identify the encoding type itself, and the last six bits store the string length. The data portion of the list item then holds the actual string. The following figure shows the layout of three string encoding types and data. You can have a look.
Implementation of listpack to avoid chain update
Finally, let's take a look at how listpack list items avoid chain updates. In listpack, because each list item only records its own length, it will not record the length of the previous item like the list item in ziplost. Therefore, when we add or modify elements in listpack, actually only the operation of each list item will be involved, and the length change of subsequent list items will not be affected, which avoids chain update.
However, you may have a question: if the listpack list item only records the length of the current item, does listpack support left to right forward query list or right to left reverse query list?
In fact, listpack can support forward and reverse query lists.
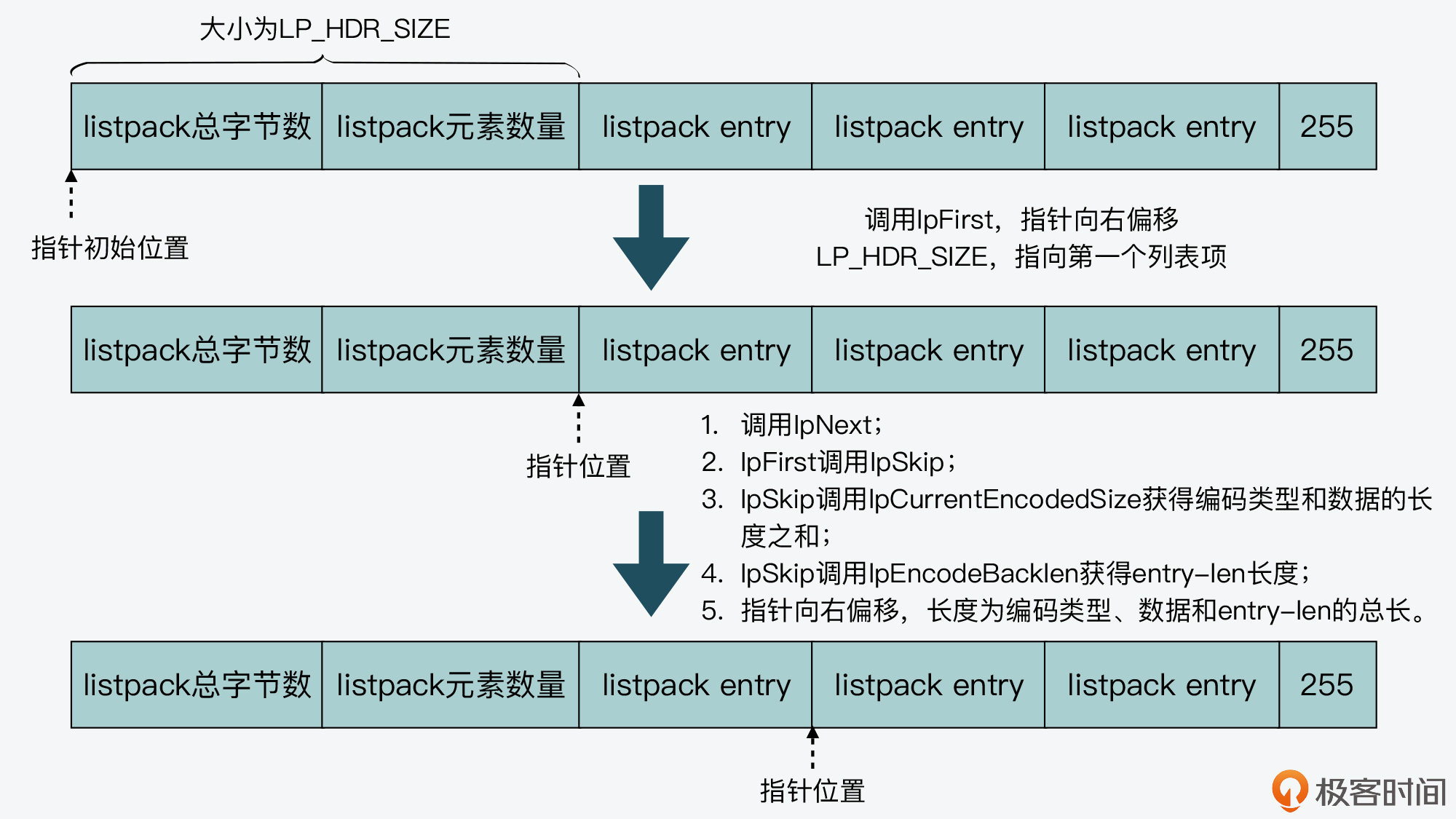
When the application queries listpack from left to right, we can call the lpFirst function first. The parameter of this function is a pointer to the listpack header. When it is executed, it will offset the pointer to the right_ HDR_ Size, that is, skip the listpack header. You can see the code of lpFirst function as follows:
/* Return a pointer to the first element of the listpack, or NULL if the
* listpack has no elements. */
unsigned char *lpFirst(unsigned char *lp) {
// Skip listpack header 6 bytes
unsigned char *p = lp + LP_HDR_SIZE; /* Skip the header. */
// If it is already the end byte of listpack, NULL is returned
if (p[0] == LP_EOF) return NULL;
lpAssertValidEntry(lp, lpBytes(lp), p);
return p;
}
Then, call the lpNext function, whose parameters include a pointer to a list item of listpack. The lpNext function will further call the lpSkip function and pass in the pointer of the current list item, as shown below:
Finally, the lpSkip function will call the two functions of lpCurrentEncodedSize and lpEncodeBacklen successively. The lpcurrentencodedsize function calculates the encoding type of the current item according to the value of the first byte of the current list item, and calculates the encoding type of the current item and the total length of the actual data according to the encoding type. Then, the lpencodebacklen function will further calculate the length of the last part of the list item entry len itself according to the sum of the encoding type and the length of the actual data. In this way, the lpskip function will know the coding type of the current item, the actual data and the total length of entry len, and can offset the current item pointer to the right by the corresponding length, so as to achieve the purpose of finding the next list item.
The following code shows the basic calculation logic of the lpEncodeBacklen function. You can have a look.
/* Store a reverse-encoded variable length field, representing the length
* of the previous element of size 'l', in the target buffer 'buf'.
* The function returns the number of bytes used to encode it, from
* 1 to 5. If 'buf' is NULL the function just returns the number of bytes
* needed in order to encode the backlen. */
unsigned long lpEncodeBacklen(unsigned char *buf, uint64_t l) {
// The total length of encoding type and actual data is less than or equal to 127, and the length of entry len is 1 byte
if (l <= 127) {
if (buf) buf[0] = l;
return 1;
} else if (l < 16383) {
// The total length of encoding type and actual data is greater than 127 but less than 16383, and the length of entry len is 2 bytes
if (buf) {
buf[0] = l>>7;
buf[1] = (l&127)|128;
}
return 2;
} else if (l < 2097151) {
// The total length of encoding type and actual data is greater than 16383 but less than 2097151, and the length of entry len is 3 bytes
if (buf) {
buf[0] = l>>14;
buf[1] = ((l>>7)&127)|128;
buf[2] = (l&127)|128;
}
return 3;
} else if (l < 268435455) {
// The total length of encoding type and actual data is greater than 2097151 but less than 268435455, and the length of entry len is 4 bytes
if (buf) {
buf[0] = l>>21;
buf[1] = ((l>>14)&127)|128;
buf[2] = ((l>>7)&127)|128;
buf[3] = (l&127)|128;
}
return 4;
} else {
// Otherwise, the entry len length is 5 bytes
if (buf) {
buf[0] = l>>28;
buf[1] = ((l>>21)&127)|128;
buf[2] = ((l>>14)&127)|128;
buf[3] = ((l>>7)&127)|128;
buf[4] = (l&127)|128;
}
return 5;
}
}
I also drew a diagram showing the basic process of traversing listpack from left to right. You can review it again.
OK, after understanding the forward query of listpack from left to right, let's look at the reverse query of listpack from right to left.
First, according to the total length of listpack recorded in the listpack header, we can directly locate the tail end tag of listapck. Then, we can call the lpPrev function, whose parameters include a pointer to a list item and return a pointer to the previous item of the current list item. The key step in the lpPrev function is to call the lpDecodeBacklen function.
The lpDecodeBacklen function reads the entry len of the current list item byte by byte from right to left. So, how does the lpDecodeBacklen function determine whether the entry len is over?
This depends on the encoding method of entry len. The highest bit of each byte of entry len is used to indicate whether the current byte is the last byte of entry len. There are two situations here, namely:
- The highest bit is 1, indicating that the entry len has not ended, and the left byte of the current byte still represents the content of the entry len;
- The highest bit is 0, indicating that the current byte is the last byte of entry len.
The lower 7 bits of each byte of entry len record the actual length information. Here, you should note that the lower 7 bits of each byte of entry len are stored in the big end mode, that is, the lower bytes of entry len are stored at the high address of memory. I drew the following picture to show the special coding method of entry len. You can have a look.
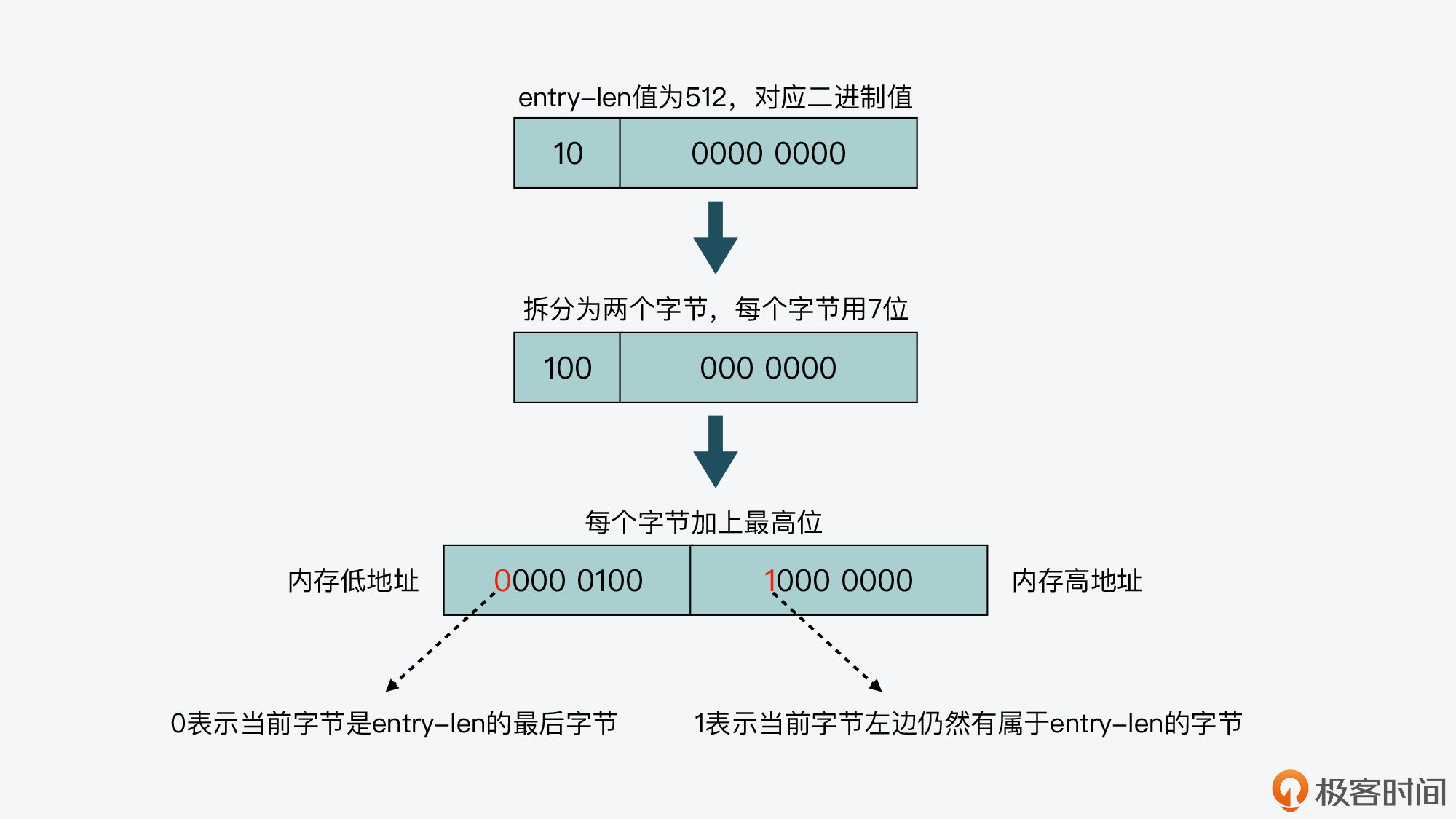
In fact, because of the special encoding method of entry len, the lpDecodeBacklen function can start from the pointer at the starting position of the current list item and parse it byte by byte to the left to obtain the entry len value of the previous item. This is also the return value of the lpDecodeBacklen function. From the introduction just now, we know that entry len records the sum of the encoding type and the length of the actual data. Therefore, the lpPrev function will call the lpEncodeBacklen function again to calculate the length of the entry len itself. In this way, we can get the total length of the previous item, and the lpPrev function can point the pointer to the starting position of the previous item. Therefore, according to this method, listpack implements the query function from right to left.
You should know that the main disadvantage of ziplost is that once there are more elements in ziplost, its search efficiency will be reduced. Moreover, if data is added or modified in the ziplist, the memory space occupied by the ziplist needs to be reallocated; To make matters worse, adding or modifying an element in the ziplost may lead to changes in the prevlen occupied space of subsequent elements, resulting in chain updates and reallocation of space for each element, which will reduce the access performance of the ziplost.
Therefore, in order to solve the problem of zipplist, Redis first designed and implemented quicklist in version 3.0. The quicklist structure is based on the ziplost, and uses a linked list to connect the ziplost. Each element of the linked list is a ziplost. This design reduces the reallocation of memory space during data insertion and the copy of memory data. At the same time, quicklist limits the size of ziplist on each node. Once a ziplist is too large, the method of adding a quicklist node will be adopted. However, because quicklist uses the quicklistNode structure to point to each ziplost, it undoubtedly increases the memory overhead. In order to reduce the memory overhead and further avoid the chain update problem of ziplost, Redis designed and implemented the listpack structure in version 5.0. The listpack structure follows the compact memory layout of ziplist, placing each element next to each other. Each list item in listpack no longer contains the length of the previous item. Therefore, when the data in a list item changes, resulting in the change of the length of the list item, the length of other list items will not be affected. Therefore, this avoids the chain update problem faced by ziplist. In a word, in the design and implementation of Redis's memory compact list, from zipplist to quicklist and then to listpack, you can see the design trade-offs between Redis's memory space overhead and access performance. This series of design changes are very worth learning.