This article has included the series of Java common interview questions. Git open source address: https://gitee.com/mydb/interview
HashSet implements the Set interface and is supported by the hash table (actually HashMap). HashSet does not guarantee the iteration order of the Set, but allows the insertion of null values. That is, HashSet cannot guarantee that the element insertion order and iteration order are the same.
HashSet has the feature of de duplication, that is, it can automatically filter out duplicate elements in the set to ensure that the elements stored in HashSet are unique.
1. Basic usage of HashSet
The basic operation methods of HashSet are: add, remove, contains and size. The performance of these methods is fixed operation time if the hash function disperses the elements in the correct position in the bucket.
The basic usage of HashSet is as follows:
// Create HashSet collection
HashSet<String> strSet = new HashSet<>();
// Add data to HashSet
strSet.add("Java");
strSet.add("MySQL");
strSet.add("Redis");
// Cycle through all elements in the HashSet
strSet.forEach(s -> System.out.println(s));2.HashSet disorder
HashSet cannot guarantee that the order of inserting elements and the order of circular output elements must be the same, that is, HashSet is actually an unordered set. The specific code examples are as follows:
HashSet<String> mapSet = new HashSet<>();
mapSet.add("Shenzhen");
mapSet.add("Beijing");
mapSet.add("Xi'an");
// Cycle through all elements in the HashSet
mapSet.forEach(m -> System.out.println(m));The results of the above procedures are as follows:
It can be seen from the above code and execution results that the sequence of HashSet insertion is Shenzhen - > Beijing - > Xi'an, while the sequence of circular printing is Xi'an - > Shenzhen - > Beijing. Therefore, HashSet is disordered and the sequence of insertion and iteration cannot be guaranteed to be consistent.
PS: if you want to ensure that the insertion order is consistent with the iteration order, you can use LinkedHashSet to replace the HashSet.
3.HashSet incorrect usage
Some people say that HashSet can only ensure that the basic data types are not repeated, but can not guarantee that the user-defined objects are not repeated? Is that right?
We illustrate this problem with the following example.
3.1 HashSet and basic data types
HashSet is used to store basic data types. The implementation code is as follows:
HashSet<Long> longSet = new HashSet<>(); longSet.add(666l); longSet.add(777l); longSet.add(999l); longSet.add(666l); // Cycle through all elements in the HashSet longSet.forEach(l -> System.out.println(l));
The results of the above procedures are as follows:
From the above results, it can be seen that using HashSet can ensure that the basic data types are not repeated.
3.2 HashSet and custom object types
Next, store the custom object in the HashSet. The implementation code is as follows:
public class HashSetExample {
public static void main(String[] args) {
HashSet<Person> personSet = new HashSet<>();
personSet.add(new Person("Cao Cao", "123"));
personSet.add(new Person("Sun Quan", "123"));
personSet.add(new Person("Cao Cao", "123"));
// Cycle through all elements in the HashSet
personSet.forEach(p -> System.out.println(p));
}
}
@Getter
@Setter
@ToString
class Person {
private String name;
private String password;
public Person(String name, String password) {
this.name = name;
this.password = password;
}
}The results of the above procedures are as follows: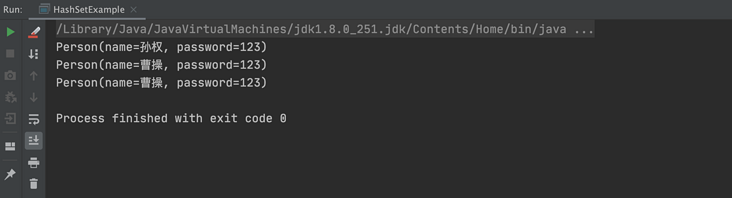
It can be seen from the above results that the user-defined object type has not been de duplicated, that is to say, the HashSet cannot de duplicate the user-defined object type?
In fact, it is not. The de duplication function of HashSet depends on the hashCode and equals methods of the element. The two methods return true, that is, the same object, otherwise it is different objects. The reason why the previous Long type elements can be de duplicated is that the hashCode and equals methods have been rewritten in the Long type. The specific implementation source code is as follows:
@Override
public int hashCode() {
return Long.hashCode(value);
}
public boolean equals(Object obj) {
if (obj instanceof Long) {
return value == ((Long)obj).longValue();
}
return false;
}
//Omit other source codeFor more information about hashCode and equals, see: https://mp.weixin.qq.com/s/40zaEJEkQYM3Awk2EwIrWA
Then, to enable HashSet to support custom object de duplication, you only need to rewrite hashCode and equals methods in the custom object. The specific implementation code is as follows:
@Setter
@Getter
@ToString
class Person {
private String name;
private String password;
public Person(String name, String password) {
this.name = name;
this.password = password;
}
@Override
public boolean equals(Object o) {
if (this == o) return true; // Reference equality returns true
// If it is equal to null or the object type is different, false is returned
if (o == null || getClass() != o.getClass()) return false;
// Force to custom Person type
Person persion = (Person) o;
// Returns true if name and password are equal
return Objects.equals(name, persion.name) &&
Objects.equals(password, persion.password);
}
@Override
public int hashCode() {
// Compare whether name and password are equal
return Objects.hash(name, password);
}
}Rerun the above code, and the execution result is shown in the following figure: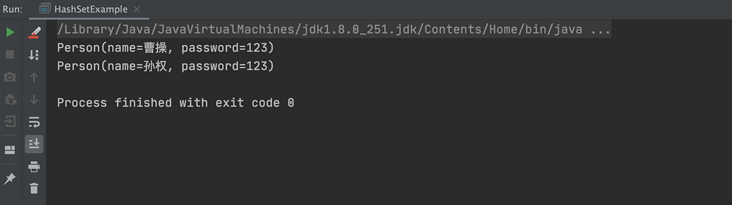
It can be seen from the above results that the previous repetition "Cao Cao" has been de duplicated.
4. How does HashSet ensure that elements are not repeated?
As long as we understand the process of adding elements in HashSet, we can know why HashSet can ensure that elements are not repeated?
The execution process of adding elements to a HashSet is as follows: when adding an object to a HashSet, the HashSet will first calculate the hashcode value of the object to determine the location where the object is added, and will also compare it with the hashcode values of other added objects. If there is no matching hashcode, the HashSet will assume that the object does not appear repeatedly and insert the object into the corresponding location. However, if an object with the same hashcode value is found, the equals() method of the object will be called to check whether the objects are really the same. If they are the same, the HashSet will not add duplicate objects to the HashSet, so as to ensure that the elements are not repeated.
In order to better understand the adding process of HashSet, we can try to read the specific implementation source code of HashSet. The implementation source code of HashSet adding method is as follows (the following source code is based on JDK 8):
// When put() in hashmap returns null, the operation is successful
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}From the above source code, we can see that the add method in the HashSet actually calls the put in the HashMap, so let's continue to look at the put implementation in the HashMap:
// Return value: if there is no element at the insertion position, null is returned; otherwise, the previous element is returned
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}It can be seen from the above source code that the put() method in HashMap calls the putVal() method. The source code of putVal() is as follows:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K, V>[] tab;
Node<K, V> p;
int n, i;
//If the hash table is empty, call resize() to create a hash table and record the length of the hash table with variable n
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
/**
* If the specified parameter hash has no corresponding bucket in the table, there is no collision
* Hash Function, (n - 1) & hash calculates the slot where the key will be placed
* (n - 1) & hash In essence, hash% n-bit operation is faster
*/
if ((p = tab[i = (n - 1) & hash]) == null)
// Just insert the key value pair into the map
tab[i] = newNode(hash, key, value, null);
else {// Element already exists in bucket
Node<K, V> e;
K k;
// The hash value of the first element (node in the array) in the comparison bucket is equal, and the key is equal
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
// Assign the first element to e and record it with E
e = p;
// There is no key value pair in the current bucket, and the bucket is a red black tree structure. It is inserted according to the red black tree structure
else if (p instanceof TreeNode)
e = ((TreeNode<K, V>) p).putTreeVal(this, tab, hash, key, value);
// There is no key value pair in the current bucket, and the bucket is a linked list structure. It is inserted into the tail according to the linked list structure
else {
for (int binCount = 0; ; ++binCount) {
// Traverse to the end of the linked list
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// Check whether the length of the linked list reaches the threshold and change the organization form of the slot node to red black tree
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
// < key, value > and put operations < key, value > of linked list nodes
// When it is the same, do not repeat the operation and jump out of the loop
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// Find or create a key value pair with key and hashCode equal to the inserted element, and put it
if (e != null) { // existing mapping for key
// Record the value of e
V oldValue = e.value;
/**
* onlyIfAbsent When it is false or the old value is null, it is allowed to replace the old value
* Otherwise, no replacement is required
*/
if (!onlyIfAbsent || oldValue == null)
e.value = value;
// Post access callback
afterNodeAccess(e);
// Return old value
return oldValue;
}
}
// Update structured modification information
++modCount;
// rehash when the number of key value pairs exceeds the threshold
if (++size > threshold)
resize();
// Post insert callback
afterNodeInsertion(evict);
return null;
}As can be seen from the above source code, when putting a key value pair into a HashMap, first determine the storage location of the Entry according to the hashCode() return value of the key. If the hash values of two keys are the same, it will judge whether the equals() of the keys of the two elements are the same. If they are the same, it will return true, indicating that they are duplicate key value pairs. Then the return value of the add() method in the HashSet will be false, indicating that the HashSet failed to add elements. Therefore, if an existing element is added to the HashSet, the newly added set element will not overwrite the existing element, so as to ensure that the elements are not repeated. If it is not a duplicate element, the put method will eventually return null. The add method passed to the HashSet is successful.
summary
The bottom layer of HashSet is implemented by HashMap, which can realize the de duplication function of duplicate elements. If you store custom objects, you must override hashCode and equals methods. HashSet ensures that elements are not repeated by using the put method of HashMap. Before storage, judge whether they exist according to the hashCode and equals of the key. If they exist, they will not be inserted repeatedly, so as to ensure that elements are not repeated.
When the death comes, he will not be surprised, and he will not be angry without reason.
Blogger: post-80s programmers. Hobbies: reading, writing and jogging.
The official account: Java interview