This article is shared from Huawei cloud community< [SparkSQL notes] introduction and practice tutorial of SparkSQL (I) >, author: Copy engineer.
1.Spark SQL overview
Spark SQL is a module for processing structured data. Unlike Spark RDD, spark SQL provides better data structure information (source data) and performance. It can interact with spark SQL through SQL and DataSet API.
2. Introduction to spark SQL programming
The main programming entry point of Spark SQL module is SparkSession. The SparkSession object not only provides users with API s for creating DataFrame objects, reading external data sources and converting them into DataFrame objects and executing sql queries, but also records the control and tuning parameters of how users want Spark applications to run in Spark clusters. It is the context and basis of Spark SQL.
2.1 create SparkSession
SparkSession sparkSession = SparkSession.builder().master("local").appName("SparkSQLDemo1").config("spark.testing.memory", 471859200).getOrCreate();master("local") and new sparkconf() Setmaster ("local") is the same. SparkSession includes SparkContext, SqlContext, etc. it is a more powerful entry object and a more unified entry.
appName("SparkSQLDemo1") sets the task name
config(): set the configuration property, and there are multiple overloaded methods:
public synchronized SparkSession.Builder config(String key, String value) public synchronized SparkSession.Builder config(String key, long value) public synchronized SparkSession.Builder config(String key, double value) public synchronized SparkSession.Builder config(String key, boolean value) public synchronized SparkSession.Builder config(SparkConf conf)
SparkSession in Spark 2.0 provides powerful built-in support for Hive, including the functions of writing query statements using HiveQL, accessing Hive UDF and reading data from Hive table. If you only test these functions for the purpose of learning, you don't need to install Hive in the cluster, you can test Hive support in Spark local mode.
2.2 create DataFrame
The API provided by SparkSession object can create DataFrame objects from existing RDD S, Hive tables or other structured data sources.
To illustrate here, DataSet is a substitute for DataFrame, which is more powerful than DataFrame. DataFrame is equivalent to DataSet[Row]
public static void main(String[] args) {
SparkSession sparkSession = SparkSession.builder().master("local").appName("SparkSQLDemo1").config("spark.testing.memory", 471859200).getOrCreate();
System.out.println(sparkSession.version());
Dataset<Row> json = sparkSession.read().json("D:\\sparksqlfile\\jsondata\\student.json");
//The show method is to display all data, or show (int rownum) can display the first N data
json.show();
sparkSession.close();
}Sample data:
{"id":1,"name":"Xiao Hong","age":"19","phone":"111"}
{"id":2,"name":"Wang Ming","age":"20","phone":"222"}
{"id":3,"name":"Zhuge Liang","age":"21","phone":"333"}
{"id":4,"name":"Wang Mao","age":"23","phone":"444"}
{"id":5,"name":"Sanmao","age":"17","phone":"555"}
{"id":6,"name":"Lao Zhang","age":"16","phone":"666"}Log printing:
INFO 2019-11-25 20:26 - org.apache.spark.sql.catalyst.expressions.codegen.CodeGenerator[main] - Code generated in 18.6628 ms
+---+---+----+-----+
|age| id|name|phone|
+---+---+----+-----+
| 19| 1| Xiao Hong| 111|
| 20| 2| Wang Ming| 222|
| 21| 3| Zhuge Liang| 333|
| 23| 4| Wang Mao| 444|
| 17| 5| Sanmao| 555|
| 16| 6| Lao Zhang| 666|
+---+---+----+-----+
INFO 2019-11-25 20:26 - org.spark_project.jetty.server.ServerConnector[main] - Stopped Spark@23db87{HTTP/1.1}{0.0.0.0:4040}You can see that the json data file has been parsed, and the field name in json has also been parsed into the field name of the table. If there is any inconsistency in the key value of your json, it will be parsed into the field name, but if there is no value, it will be null by default
For example:

Log printing:

See, there are all different key values.
2.3 basic operation of dataframe
DataFrame provides us with flexible, powerful and bottom-level optimized APIs, such as select, where, orderBy, groupBy, limit and union. DataFrame provides a series of operators that are very familiar to developers. DataFrame encapsulates all components of SQL select statements into APIs with the same name to help programmers through select, where orderBy and other DataFrame API s flexibly combine to achieve the same logical expression as SQL. Therefore, DataFrame programming only needs to make a declarative description of the calculation conditions, calculation requirements and final required results like SQL, rather than the original operation of the data set step by step like RDD programming.
Usage instance of DataFrame API (take json data above as an example):
- Output the structure information of DataSet object in tree format
Dataset<Row> json = sparkSession.read().json("D:\\sparksqlfile\\jsondata\\student.json");
// Display DataSet structure information
json.printSchema();Log printing:
root |-- age: string (nullable = true) |-- id: long (nullable = true) |-- name: string (nullable = true) |-- phone: string (nullable = true)
The structure information of the table has been listed according to the tree structure, which is determined according to the value value of the json file.
2. Query one or more columns in the DataSet through the Select() method of the DataSet
SparkSession sparkSession = SparkSession.builder().master("local").appName("SparkSQLDemo1").config("spark.testing.memory", 471859200).getOrCreate();
Dataset<Row> json = sparkSession.read().json("D:\\sparksqlfile\\jsondata\\student.json");
// Define field
Column id = new Column("id");
Column name = new Column("name");
// Query a single field
json.select("id").show();
// Query multiple fields
json.select(id,name).show();
// Close saprkSesison. The close and stop here are the same as 2.1 X starts with close 2.0 Stop used by X
sparkSession.close();Select also has a select(String col, String... cols). The first parameter is not very clear. I'll add it later. In addition, it is very important to have an object Column here. This object will be used by all java development sparkSQL in the future. This object is the field we use in the database, and this object has rich methods to operate the field.
3. Use the select(), where(), orderBy() method of DataSet object in combination to find the id, name, age and telephone number of students whose id is greater than 3, in descending order of id
Here, in order to show the results more intuitively, I modified the json file and added several lines of data:
{"id":1,"name":"Xiao Hong","age":"19","phone":"111"}
{"id":2,"name":"Wang Ming","age":"20","phone":"222"}
{"id":3,"name":"Zhuge Liang","age":"21","phone":"333"}
{"id":4,"name":"Wang Mao","age":"23","phone":"444"}
{"id":5,"name":"Sanmao","age":"17","phone":"555"}
{"id":6,"name":"Lao Zhang","age":"16","phone":"666"}
{"id":7,"name":"Zhang Hao","age":"16","phone":"777"}
{"id":8,"name":"Wang Liu","age":"16","phone":"888"}There are two forms of where condition query:
public Dataset<T> where(Column condition) public Dataset<T> where(String conditionExpr)
The first is to query by Column object operation conditions, and the second is to query by writing conditions directly
// Condition query
// id > 3
Column id = new Column("id").gt(3);
// age = 16
Column name = new Column("age").equalTo("16");
// id > 3 and age =16
Column select = id.and(name);
// Direct writing conditions
json.select("id","name","age","phone").where("id > 3 and age = 16").orderBy(new Column("id").desc()).show();
// Generate ID > 3 and age = 16 from multiple where
json.select("id","name","age","phone").where(id).where(name).orderBy(new Column("id").desc()).show();
// Through Column operation, ID > 3 and age = 16 are obtained
json.select("id","name","age","phone").where(select).orderBy(new Column("id").desc()).show();The three are written in the same way and the result is the same.

4. Use the groupBy() method provided by the DataSet object to analyze the age distribution of students
// Grouping query
// Single field grouping query
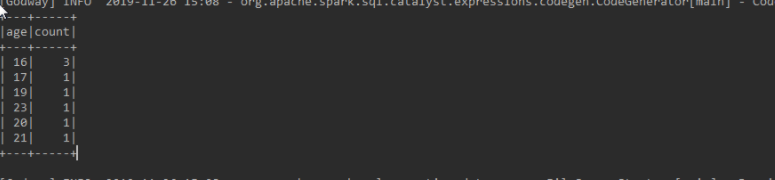
json.groupBy(new Column("age")).count().show();
// Multiple field grouping query
ArrayStack<Column> stack = new ArrayStack<>();
stack.push(new Column("id"));
stack.push(new Column("age"));
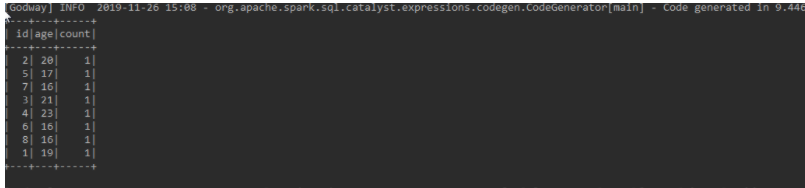
json.groupBy(stack).count().show();
// Multiple field grouping query
json.groupBy(new Column("id"),new Column("age")).count().show();There are many forms of group:
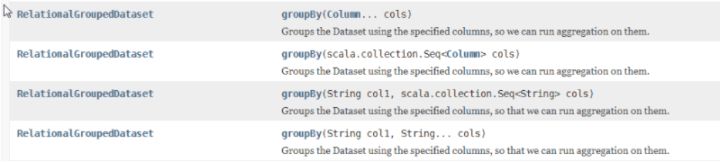
As for how you want to write, as long as it is correct.
If you want to operate on fields, for example, we often write sqlselect age+1 from student like this, sparkSQL can be implemented completely, just like this: new column ("age") Plus (1), which means age + 1
The above example shows that the API provided by DataSet can be flexibly combined to realize the clear and concise logical expression like SQL. If RDD programming is adopted, first of all, RDD is not sensitive to the file format of JSON. It will read the JSON file line by line like reading the text file and convert it into RDD[String], Instead of automatically parsing JSON format data and automatically inferring structure information (Schema) like DataSet, we must first instantiate a JSON parser in the program to parse JSON strings to obtain an array composed of real data. In fact, RDD[String] is transformed into RDD[Array[String]] composed of arrays recording multiple common field values line by line, Then, RDD operator operations such as map, filter, takeOrdered, distinct and union are used to carry out specific data operations step by step to realize business logic.
In contrast, we can see that sometimes with the same amount of data and the same analysis requirements, RDD programming not only has a larger amount of code, but also is very likely to increase the overhead of the cluster due to the bad operation of programmers. Sometimes, using DataFrame API combination programming can achieve complex analysis requirements with only one line of code.
2.4 execute SQL query
SparkSession provides users with a SparkSession to execute sql statements directly sql (string SQLTEXT) method. The sql statement can be directly passed into the sql() method as a string. The result of sql query is still a DataFrame object. To directly execute the query of sql statement on Spark SQL module, first register the DataSet object marking the structured data source as a temporary table, and then query the temporary table in the sql statement. The specific steps are as follows:
SparkSession sparkSession = SparkSession.builder().master("local").appName("SparkSQLDemo1").config("spark.testing.memory", 471859200).getOrCreate();
Dataset<Row> json = sparkSession.read().json("D:\\sparksqlfile\\jsondata\\student.json");
// Registration temporary form
json.createOrReplaceTempView("student");
// select * from student can also be used for sql query
Dataset<Row> sql = sparkSession.sql("select id,name,age,phone from student");
sql.show();
// Close saprkSesison. The close and stop here are the same as 2.1 X starts with close 2.0 Stop used by X
sparkSession.close();The results show that:

From the above operations, it can be seen that DataSet is the data abstraction of Spark SQL core. The read data source needs to be transformed into DataSet object, so that various API s of DataSet can be used for rich operations. DataSet can also be registered as a temporary table to directly execute SQL query, and the DataFrame object is also returned after the operation on DataFrame.
In addition, because this summary describes how to directly query SQL through the SQL interface provided by SparkSession, and how to write the SQL statements required to complete the business requirements, you can directly learn from Baidu query related SQL tutorials. The SQL interface of Spark SQL fully supports the select standard syntax of SQL, including SELECT DISTINCT, from clause, where clause, order by clause, group by clause, having clause, join clause, as well as typical SQL functions, such as avg(), count(), max(), min(). In addition, Spark SQL also provides a large number of powerful available functions, It can be embedded in SQL statements, including aggregation functions, time control functions, mathematical statistics functions, character string control functions, etc. readers who are interested or have analysis needs in this regard can check the official documents http://spark.apache.org/docs/latest/api/scala/index.html#org.apache.spark.sql
2.5 global temporary table
The global temporary view is relative to the temporary view. The scope of the global temporary view is all sessions in a Spark application. It will continue to exist and be shared in all sessions until the Spark application terminates
Therefore, in the same application, a temporary table needs to be used in different sessions, so the temporary table can be registered as a global temporary table to avoid redundant I/O and improve the system execution efficiency. Of course, if a temporary table is only used in a session in the whole application, it only needs to be registered as a local temporary table to avoid unnecessary memory storage of global temporary tables
Note that the global temporary table is the same as the database global reserved by the system_ Temp is associated, and global is required for reference_ Temp ID.
example:
SparkSession sparkSession = SparkSession.builder().master("local").appName("SparkSQLDemo1").config("spark.testing.memory", 471859200).getOrCreate();
Dataset<Row> json = sparkSession.read().json("D:\\sparksqlfile\\jsondata\\student.json");
// Registration temporary form
json.createOrReplaceTempView("student");
// sql query
Dataset<Row> sql = sparkSession.sql("select * from student");
sql.show();
// Register as global temporary table
try {
json.createGlobalTempView("student_glob");
} catch (AnalysisException e) {
e.printStackTrace();
}
// Current session queries global temporary tables
Dataset<Row> sqlGlob = sparkSession.sql("select * from global_temp.student_glob");
sqlGlob.show();
// Create a new SparkSeesion query global temporary table
Dataset<Row> newSqlGlob = sparkSession.newSession().sql("select * from global_temp.student_glob");
newSqlGlob.show();
// Close saprkSesison. The close and stop here are the same as 2.1 X starts with close 2.0 Stop used by X
sparkSession.close();The results are the same.
2.6 DataSet implementation WordCount
The serialization of objects in Dataset[T] does not use Java standard serialization or Kryo, but uses a special encoder to serialize objects for processing or transmission over the network. Although both encoder and standard serialization are responsible for converting objects into bytes, the encoder is dynamically generated according to the element type (T) of Dataset[T], and allows Spark to perform many operations (such as filtering, sorting and hashing) without deserializing bytes back to objects. Therefore, it avoids the waste of resources caused by unnecessary deserialization and is more efficient.
SparkSession sparkSession = SparkSession.builder().master("local").appName("SparkSQLDemo1").config("spark.testing.memory", 471859200).getOrCreate();
Dataset<String> stringDataset = sparkSession.read().textFile("D:\\sparksqlfile\\jsondata\\word.txt");
// Split string per line
Dataset<String> dataset = stringDataset.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String s) throws Exception {
String[] split = s.split("\t", -1);
return Arrays.asList(split).iterator();
}
},Encoders.STRING());
// Group by key value
KeyValueGroupedDataset<String, String> groupByKey = dataset.groupByKey(new MapFunction<String, String>() {
@Override
public String call(String value) throws Exception {
return value.toLowerCase();
}
},Encoders.STRING());
// Summation display data
groupByKey.count().show();
// Close saprkSesison. The close and stop here are the same as 2.1 X starts with close 2.0 Stop used by X
sparkSession.close();Log printing:
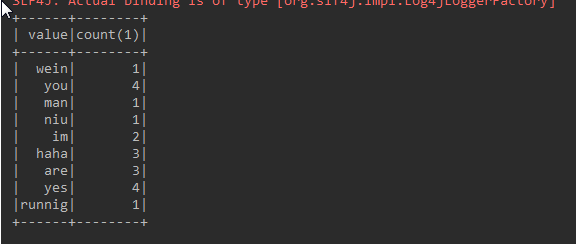
Metadata:
im runnig man you are yes haha yes you wein im niu you are yes haha you are yes haha
2.7 converting RDDs to DataFrame
In addition to calling sparksession read(). JSON / CSV / Orc / parquet / JDBC method creates DataFrame objects from various external structured data sources. Spark SQL also supports the conversion of existing RDDS into DataSet objects. However, it should be noted that RDDS composed of objects of any type can not be converted into DataSet objects. Only when each T object constituting RDD[T] has a public and distinct field structure, Then we can implicitly or explicitly summarize the necessary structural information (Schema) for creating DataSet objects, transform them, and then call the powerful and rich API that RDD does not have on the DataSet, or execute concise SQL queries.
Spark SQL supports two different methods to convert existing RDDs into datasets, that is, implicitly inferring or explicitly specifying the Schema of DataSet objects.
Instance data:
Wang Ming 13 17865321121 Building 1, tianlongsi community, Nanjing Class 1, grade 5 Liu Hong 14 15643213452 Building 2, tianlongsi community, Nanjing Class 1, grade 5 Zhang San 15 15678941247 Building 3, tianlongsi community, Nanjing Class 2, grade 5 Zhuge Liu Fang 14 14578654123 Building 1, tianlongsi community, Nanjing Class 1, grade 5
1. Use Reflection mechanism to infer schema structure information
The first way to convert RDDs into DataFrame is to use the SparkSQL internal reflection mechanism to automatically infer the schema (RDD structure information) of RDD containing specific types of objects for hermit conversion. In this way, it is often because the T object contained in the transformed RDD[T] is an object with a typical one-dimensional table and strict field structure. Therefore, SparkSQL can easily automatically infer a reasonable schema. This method of implicitly creating DataSet based on reflection mechanism often only needs concise code to complete the transformation, and the operation effect is good.
The Scala interface of SparkSQL supports the automatic conversion of RDD S containing sample class objects into DataSet objects. The structure information of the table has been pre-defined in the declaration of the sample class. The name and type of the parameters of the sample class can be read through the internal reflection mechanism and transformed into the Schema of the DataSet object. The sample class can contain not only simple data types such as Int, Double and String, but also nested or complex types such as Seq or Arrays.
Instance: implicitly convert RDD of student sample object to DataSet object
public static void main(String[] args) {
SparkSession sparkSession = SparkSession.builder().master("local").appName("SparkSQLDemo1").config("spark.testing.memory", 471859200).getOrCreate();
// Read file to JavaRDD
JavaRDD<String> stringRDD = sparkSession.sparkContext().textFile("D:\\sparksqlfile\\jsondata\\student.txt",1).toJavaRDD();
// Javardd < string > to javardd < person >
JavaRDD<Person> personRDD = stringRDD.map(new Function<String, Person>() {
@Override
public Person call(String v1) {
String[] split = v1.split("\t", -1);
return new Person(split[0],Integer.valueOf(split[1]),split[2],split[3],split[4]);
}
});
// RDD to DataSet
Dataset<Row> personDataSet = sparkSession.createDataFrame(personRDD, Person.class);
personDataSet.show();
// Registration temporary form
personDataSet.createOrReplaceTempView("person");
// Query temporary table
Dataset<Row> selectDataSet = sparkSession.sql("select * from person where age between 14 and 15");
selectDataSet.show();
// Traverse the DataSet and obtain the Ds of name through subscript
Dataset<String> nameDs = selectDataSet.map(new MapFunction<Row, String>() {
@Override
public String call(Row value) {
// Row's fields are sorted according to the dictionary, so the fourth is the name field
return "name:"+value.getString(3);
}
}, Encoders.STRING());
nameDs.show();
// Row gets the field value by specifying the field name and returns the Object object
Dataset<String> nameDs2 = selectDataSet.map(new MapFunction<Row, String>() {
@Override
public String call(Row value) {
return "name:"+value.getAs("name");
}
}, Encoders.STRING());
nameDs2.show();
// Close saprkSesison. The close and stop here are the same as 2.1 X starts with close 2.0 Stop used by X
sparkSession.close();
}Log screenshot:
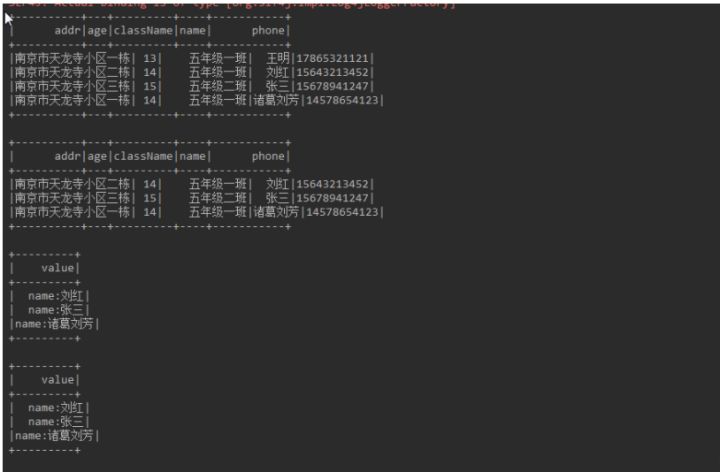
2. The developer specifies the Schema
The second way to convert RDD into Dataset is through programming interface, which allows you to create a schema first and then apply it to the existing RDD[Row]. Compared with the previous method, the RDD composed of sample classes or basic data type (Int, String) objects passes through sparksession Unlike the direct implicit conversion of createdataframe to iDataset, it not only needs to build schema according to requirements and data structure, but also needs to convert RDD[T] into RDD[Row] composed of Row objects. Although this method has more code, it also provides higher degree of freedom and flexibility.
When the case class cannot be defined in advance (for example, the data set structure information has been included in each line, and the fields of a text data set need to be resolved into different field names for different users), the Dataset conversion can be completed through the following three parts:
(1) : convert from source RDD to RDD of Rows as required
(2) : create a schema represented by a StructType that conforms to the Rows structure in the RDD created in step 1.
(3) : apply the schema to the RDD of the row through the createDataFrame method provided by SparkSession.
It can be seen that the essence of transforming RDD into Dataset is to give RDD internal structure information containing specific types of objects, so that the Dataset can master richer structure and information (it can be understood as the header of traditional database, which contains field name, type and other information). In this way, it better shows that Dateset supports sql query.
example:
SparkSession sparkSession = SparkSession.builder().master("local").appName("SparkSQLDemo1").config("spark.testing.memory", 471859200).getOrCreate();
// Read file to JavaRDD
JavaRDD<String> peopleRDD = sparkSession.sparkContext().textFile("D:\\sparksqlfile\\jsondata\\student.txt",1).toJavaRDD();
String[] schemaString = {"name", "age"};
// Create custom schema
List<StructField> fields = new ArrayList<>();
for (String s : schemaString) {
fields.add(DataTypes.createStructField(s,DataTypes.StringType,true));
}
StructType schema = DataTypes.createStructType(fields);
// Javardd < string > to javardd < row > line record
JavaRDD<Row> rowRdd = peopleRDD.map(new Function<String, Row>() {
@Override
public Row call(String v1) {
String[] split = v1.split("\t", -1);
return RowFactory.create(split[0],split[1]);
}
});
// JavaRDD to DataSet
Dataset<Row> personDataset = sparkSession.createDataFrame(rowRdd, schema);
personDataset.show();2.8 user defined functions
In addition to using the rich built-in functions of Dataset, you can also program and use user-defined functions (UDF s) to meet specific analysis needs. SparkSQL mainly supports the creation of user-defined untyped aggregate functions and user-defined strongly typed aggregate functions
1. User defined untyped aggregate function
The user-defined typeless aggregate function must inherit the UserDefinedAggregateFunction abstract class, and then override the abstract member variables and member methods in the parent class. In fact, the process of rewriting parent class abstract member variables and methods is the process of realizing the input, output specifications and calculation logic of user-defined functions.
Example: the function of finding the average value
UDF function code:
public class MyAverage extends UserDefinedAggregateFunction {
private StructType inputSchema;
private StructType bufferSchema;
public MyAverage() {
ArrayList<StructField> inputFields = new ArrayList<>();
inputFields.add(DataTypes.createStructField("inputColumn",DataTypes.LongType,true));
inputSchema = DataTypes.createStructType(inputFields);
ArrayList<StructField> bufferFields = new ArrayList<>();
bufferFields.add(DataTypes.createStructField("sum",DataTypes.LongType,true));
bufferFields.add(DataTypes.createStructField("count", DataTypes.LongType,true));
bufferSchema = DataTypes.createStructType(bufferFields);
}
// Data types of input arguments of this aggregate function
// The data type of the input parameter of the aggregate function (in fact, it is the data type of the column specified by the Dataset in which the function works)
@Override
public StructType inputSchema() {
return inputSchema;
}
// Data types of values in the aggregation buffer
// The buffer structure of the aggregate function returns the field structure previously defined for recording the accumulated value and the accumulated number
@Override
public StructType bufferSchema() {
return bufferSchema;
}
// The data type of the returned value
// The data type of the return value of the aggregate function
@Override
public DataType dataType() {
return DataTypes.DoubleType;
}
// Whether this function always returns the same output on the identical input
// Does this function always return the same output on the same input
@Override
public boolean deterministic() {
return true;
}
// Initializes the given aggregation buffer. The buffer itself is a `Row` that in addition to
// standard methods like retrieving a value at an index (e.g., get(), getBoolean()), provides
// the opportunity to update its values. Note that arrays and maps inside the buffer are still
// immutable.
// Initializes the given buffer aggregate buffer
// The buffer aggregation buffer itself is a Row object, so you can call its standard methods to access the elements in the buffer, such as retrieving a value at the index
@Override
public void initialize(MutableAggregationBuffer buffer) {
buffer.update(0,0L);
buffer.update(1,0L);
}
// Updates the given aggregation buffer `buffer` with new input data from `input`
@Override
public void update(MutableAggregationBuffer buffer, Row input) {
if (!input.isNullAt(0)){
long updatedSum = buffer.getLong(0) + input.getLong(0);
long updatedCount = buffer.getLong(1)+1;
buffer.update(0,updatedSum);
buffer.update(1,updatedCount);
}
}
// Merges two aggregation buffers and stores the updated buffer values back to `buffer1`
@Override
public void merge(MutableAggregationBuffer buffer1, Row buffer2) {
long mergedSum = buffer1.getLong(0) + buffer2.getLong(0);
long mergedCount = buffer1.getLong(1) + buffer2.getLong(1);
buffer1.update(0,mergedSum);
buffer1.update(1,mergedCount);
}
@Override
public Object evaluate(Row buffer) {
return ((double)buffer.getLong(0))/buffer.getLong(1);
}
}Run code:
public static void main(String[] args) {
SparkSession sparkSession = SparkSession.builder().master("local").appName("XXXXXXXXXX").config("spark.testing.memory", 471859200).getOrCreate();
// read file
Dataset<Row> df = sparkSession.read().json("D:\\sparksqlfile\\jsondata\\student5.json");
// Register custom functions
sparkSession.udf().register("myAverage",new MyAverage());
// Display raw data
df.createOrReplaceTempView("student");
df.show();
// Averaging using custom UDF
Dataset<Row> result = sparkSession.sql("SELECT myAverage(age) as average_salary FROM student");
result.show();
}Log printing:
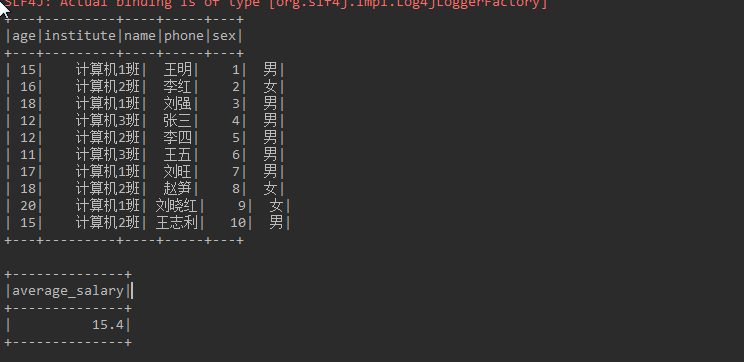
2. User defined strongly typed aggregate function
The user-defined strongly typed aggregate function needs to inherit the Aggregator abstract class, and also needs to rewrite the parent class abstract method (reduce,merge,finish) to realize the calculation logic of the user-defined aggregate function. Compared with the former UDF, the user-defined strongly typed aggregate function is closely combined with the data types of specific data sets, which enhances the security, but reduces the applicability.
Example: strong type aggregate function for finding user average
Data entity class:
// Defines the data type of the input data of the Employee sample type specification aggregate function
public class Employee implements Serializable {
private String name;
private long age;
private String sex;
private String institute;
private String phone;
public Employee() {
}
public Employee(String name, long age, String sex, String institute, String phone) {
this.name = name;
this.age = age;
this.sex = sex;
this.institute = institute;
this.phone = phone;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public long getAge() {
return age;
}
public void setAge(long age) {
this.age = age;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
public String getInstitute() {
return institute;
}
public void setInstitute(String institute) {
this.institute = institute;
}
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
@Override
public String toString() {
return "Employee{" +
"name='" + name + '\'' +
", age=" + age +
", sex='" + sex + '\'' +
", institute='" + institute + '\'' +
", phone='" + phone + '\'' +
'}';
}
}Define aggregate function buffer:
// Defines the data type of the Average sample class specification buffer aggregate buffer
public class Average implements Serializable {
private long sum;
private long count;
public Average() {
}
public Average(long sum, long count) {
this.sum = sum;
this.count = count;
}
public long getSum() {
return sum;
}
public void setSum(long sum) {
this.sum = sum;
}
public long getCount() {
return count;
}
public void setCount(long count) {
this.count = count;
}
@Override
public String toString() {
return "Average{" +
"sum=" + sum +
", count=" + count +
'}';
}
}UDF Code:
// The user-defined strongly typed aggregate function must inherit the Aggregator abstract class. Note that you need to pass in the aggregate function input data, buffer buffer and generic parameters of the returned results
public class MyAverage2 extends Aggregator<Employee,Average,Double> {
// A zero value for this aggregation. Should satisfy the property that any b + zero = b
// Define the zero value of the aggregate, which should satisfy any b + zero = b
@Override
public Average zero() {
return new Average(0L, 0L);
}
// Combine two values to produce a new value. For performance, the function may modify `buffer`
// and return it instead of constructing a new object
// Define the aggregation logic of how the buffer aggregation buffer as the Average object handles each input data (Employee object),
// Like the update method of the untyped aggregate function for averaging in the above example, each call to reduce will update the buffer of the buffer aggregate function
// And take the updated buffer as the return value
@Override
public Average reduce(Average buffer, Employee employee) {
long newSum = buffer.getSum() + employee.getAge();
long newCount = buffer.getCount() + 1;
buffer.setSum(newSum);
buffer.setCount(newCount);
return buffer;
}
// Merge two intermediate values
// The logic is the same as that of the merge method of the untyped aggregate function for obtaining the average value in the above example
@Override
public Average merge(Average b1, Average b2) {
long mergeSum = b1.getSum() + b2.getSum();
long mergeCount = b1.getCount() + b2.getCount();
b1.setSum(mergeSum);
b1.setCount(mergeCount);
return b1;
}
// Transform the output of the reduction
// Define the logic of the output result. reduction represents the final aggregation result of the buffer aggregation buffer after multiple reductions and merge s
// The Average object still records the accumulation of all data and the number of accumulation times
@Override
public Double finish(Average reduction) {
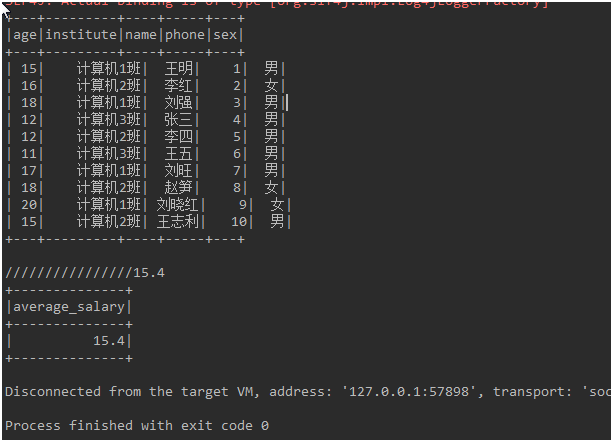
System.out.println("////////////////"+((double) reduction.getSum()) / reduction.getCount());
return ((double)reduction.getSum())/reduction.getCount();
}
// Transform the output of the reduction
// Specifies the encoder type of the intermediate value
@Override
public Encoder<Average> bufferEncoder() {
return Encoders.bean(Average.class);
}
// Specifies the Encoder for the final output value type
// Specifies the encoder type for the final output
@Override
public Encoder<Double> outputEncoder() {
return Encoders.DOUBLE();
}
}Run code:
public static void main(String[] args) {
SparkSession sparkSession = SparkSession.builder().master("local").appName("XXXXXXXXXX").config("spark.testing.memory", 471859200).getOrCreate();
Encoder<Employee> employeeEncoder = Encoders.bean(Employee.class);
// read file
Dataset<Employee> employeeDataset = sparkSession.read().json("D:\\sparksqlfile\\jsondata\\student5.json").as(employeeEncoder);
employeeDataset.show();
// Convert the function to 'TypedColumn' and give it a name
MyAverage2 myAverage2 = new MyAverage2();
TypedColumn<Employee, Double> average_salary = myAverage2.toColumn().name("average_salary");
// Averaging using custom strongly typed UDF s
Dataset<Double> result = employeeDataset.select(average_salary);
result.show();
}journal:
Click follow to learn about Huawei's new cloud technology for the first time~