1. Introduction to NoSQL development
1.1 technology development
- NoSQL: mainly used to solve performance related problems.
1. Monomer Era
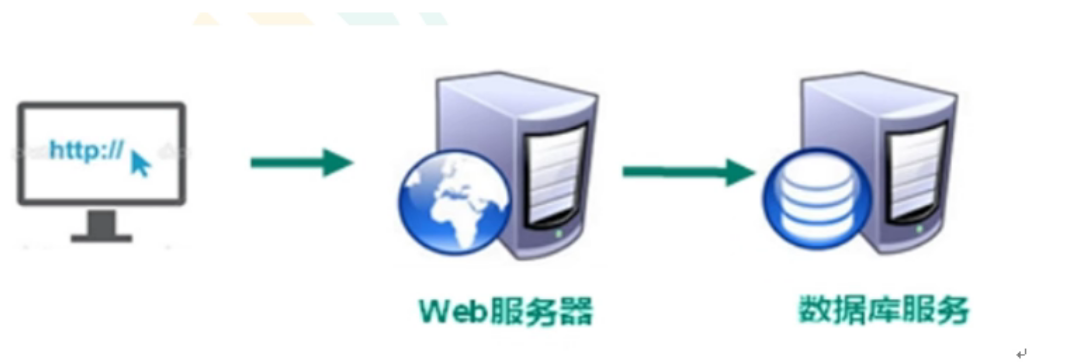
However, with the rapid increase in the amount of data, the application server will have CPU and memory pressure, and the database service will have IO pressure.
2. Solve CPU and memory pressure
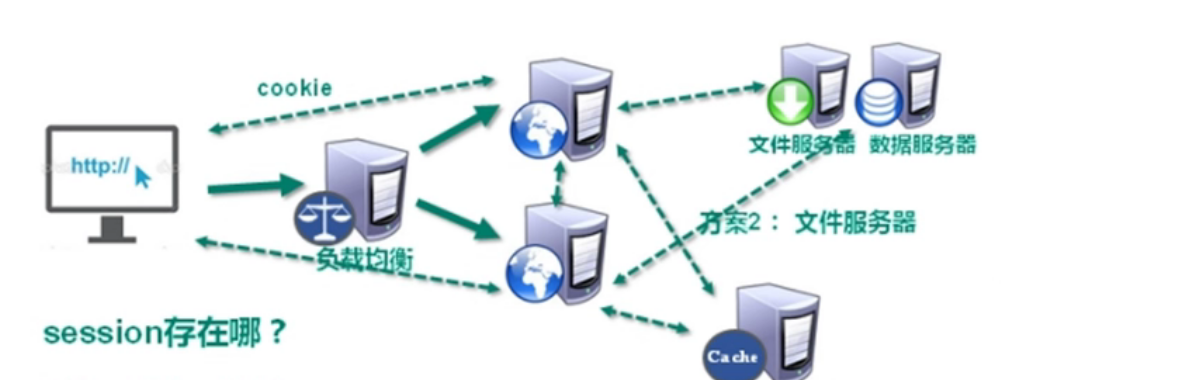
At this time, the user's request is divided equally by load balancing and distributed to each server. However, there is still a problem, that is, where the session exists.
- Storing the session in a cookie will lead to insecurity; Copying a session will result in session data redundancy. At this time, the problem of session is solved using NoSQL database. We store the session in NoSQL, and the cache database is completely in memory, which is fast and simple in data structure.
3. Reduce IO pressure
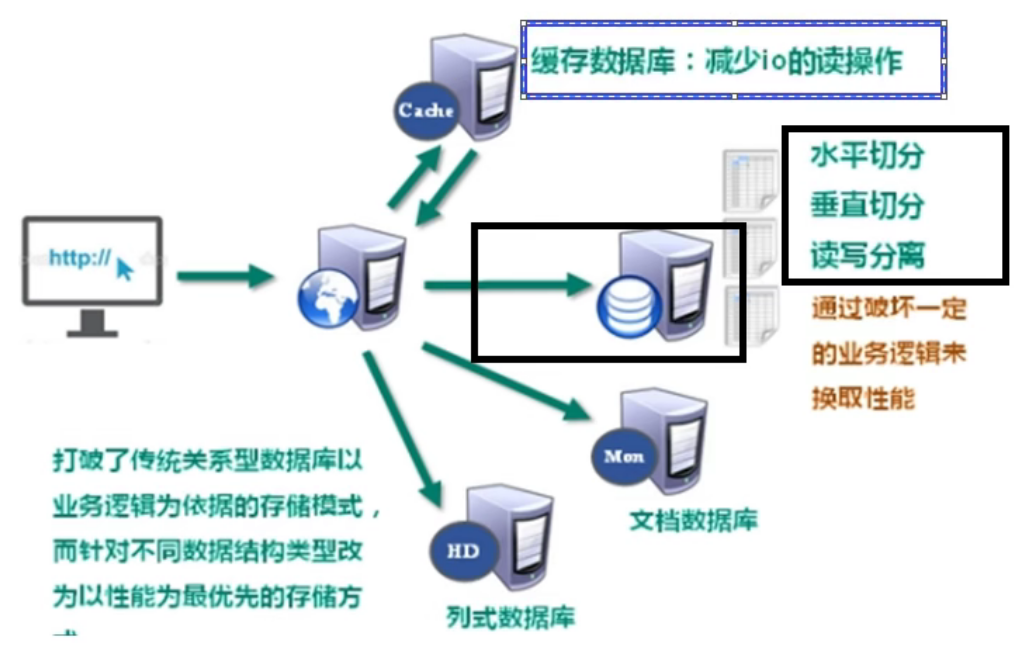
Since we will perform master-slave replication, read-write separation and other operations on the database, although this will improve certain performance, it will destroy certain business logic. Therefore, we store the recently frequently read data in the cache database, so as to reduce the read operation of IO.
1.2 NoSQL database
1. NoSQL database overview
NoSQL means "not just SQL", which generally refers to non relational databases. NoSQL does not rely on business logic storage, but is stored in a simple key value mode, which greatly increases the expansion ability of the database.
- Non compliance with SQL standards
- ACID is not supported
- Far more performance than SQL
2. Applicable scenarios of NoSQL
- Highly concurrent reading and writing of data
- Massive data reading and writing
- For high data scalability
3. NoSQL not applicable scenario
- Transaction support required
- Structured query storage based on sql, dealing with complex relationships, requires real-time query.
- If you don't need sql and you can't use sql, please consider using NoSQL.
4. Common NoSQL databases
- Memcache
- Redis
- MongoDB
1.3 determinant storage database
1. Line storage database
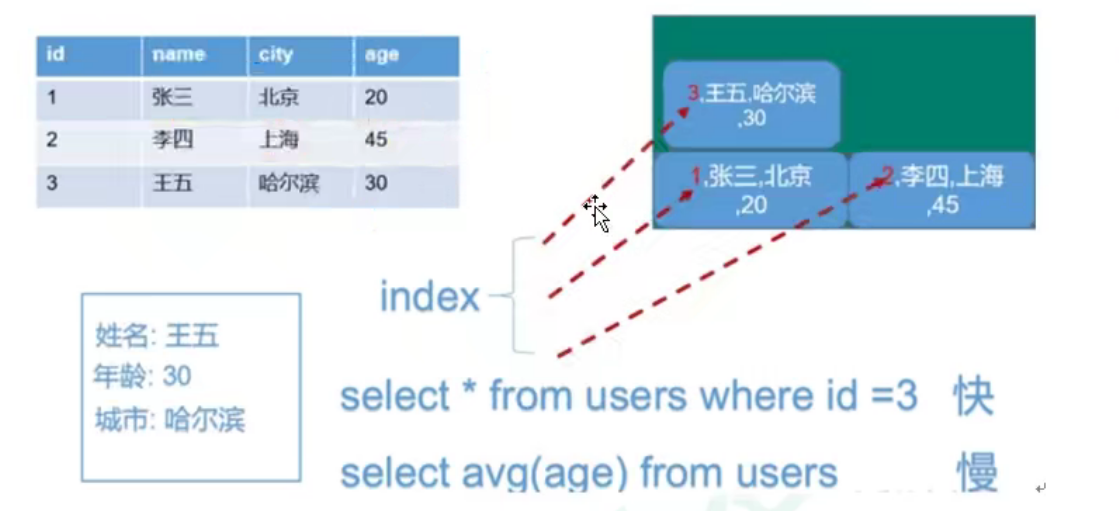
Here, the database is stored according to each row, so when we query someone's relevant information, it is very fast. If we look up the average age of everyone, it's very slow.
2. Column storage database
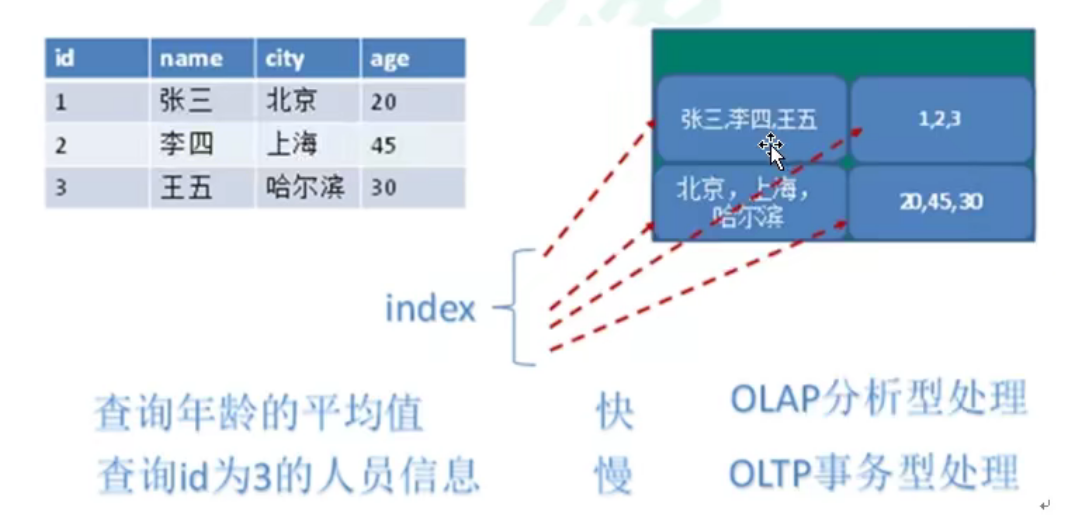
Here, the database is stored according to each column, so when we query the relevant information of a person, it is very slow. If we look up the average age of everyone, it's very fast.
2. Redis overview and installation
2.1 overview of Redis
1. Overview
- Redis is an open source key value storage system.
- Similar to Memcached, it supports relatively more stored value types, including string (string), list (linked list), set (set), zset (ordered set) and hash (hash type).
- These data types support push/pop, add/remove, intersection, union, difference and richer operations, and these operations are atomic.
- On this basis, Redis supports sorting in different ways.
- Like memcached, data is cached in memory to ensure efficiency.
- The difference is that Redis will periodically write the updated data to the disk or write the modification operation to the additional record file.
- On this basis, master-slave synchronization is realized.
2. Various data structures store persistent data
2.2. Redis installation
1. Detailed explanation of installation process
- stay redis official website Download the corresponding compressed package
- Prepare the corresponding gcc environment for installation
If there is a corresponding gcc environment on the virtual machine, please skip this step. View the command: gcc -- version. Otherwise, execute the following command:
yum install centos-release-scl scl-utils-build yum install -y devtoolset-8-toolchain scl enable devtoolset-8 bash
- We place the corresponding redis compressed package in the / opt directory through Xftp.
- Decompression command: tar -zxvf redis-6.2 1.tar. gz
- After decompression, enter the directory: CD redis-6.2 one
- On redis-6.2 1 directory, execute the make command again to compile
- If the c language environment is not ready, the make command will report an error - jemalloc / jemalloc h: There is no such document. We can solve it by the following methods.
- Run make distclean
- On redis-6.2 1 directory, execute the make command again (only compiled)
- If there is no problem, skip step 7 and continue: make install
2. Installation directory: / usr/local/bin
- Redis benchmark: a performance testing tool. You can run it in your own notebook to see how your notebook performs
- Redis check AOF: fix the problem AOF file. rdb and AOF will be described later
- Redis check dump: fix the problem dump RDB file
- Redis sentinel: redis cluster usage
- Redis server: redis server startup command
- Redis cli: client, operation portal
3. Startup mode
# Foreground start # If the foreground is started, it will close when the window is closed redis-server # Background start # To avoid this, we will redis If the conf file is corrected, we need to backup it to the / etc directory cp redis.conf /etc # Then, redis.com under the / etc directory Conf file # Change daemon no to yes # If the background is started, the window will not be closed if it is closed # The operation steps are as follows vi /etc/redis.conf # Find the corresponding line through / daem and change no to yes # start-up redis-server /etc/redis.conf # Access with client redis-cli # You can use the ping command to test. If PONG is displayed, it proves that the startup is successful # Closing mode shutdown exit # Or we can kill related processes through processes ps -ef | grep redis kill -9 Related process number
4. Introduction to relevant knowledge
- The default port number of redis is 6379
- redis contains 16 databases. Database 0 is used by default.
- Three differences from Memcache
- Support multiple data types
- Support persistence
- Single thread + multiplex IO
5. Single thread + multiplex IO
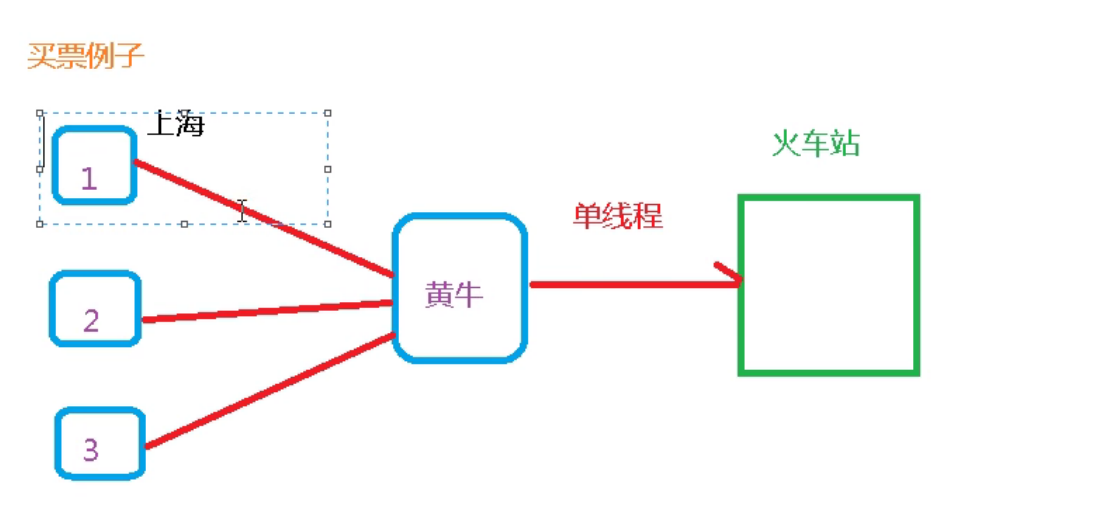
Ticket buying by scalpers here belongs to single thread, while multiple customers belong to multiple IO S. When scalpers buy tickets, she will inform the corresponding customers to get the corresponding tickets. But if you don't buy the corresponding ticket, customers won't wait all the time. He will do other things. Thus, the CPU is not idle and the efficiency of the CPU is improved.
3. Redis data type
3.1 Redis key
# View all key s of the current library key * # Determine whether a key exists exists key # Check the type of your key type key # Delete the specified key data del key # Select non blocking deletion according to value unlink key # Only the keys are deleted from the keyspace metadata. The real deletion will occur in subsequent asynchronous operations. # Sets the expiration time for the given key expire key 10 # Check how many seconds are left to expire, - 1 means it will never expire, - 2 means it has expired ttl key # Switch database select index # Corresponding database number # View the number of key s in the current database dbsize # Empty current library flushdb
3.2 Redis String (String)
1. Introduction
- String is the most basic data type of Redis. Like Memcached, it is a key corresponding to a value.
- The string type is binary safe, which means that Redis's string can contain any data. And the string value in a Redis can be 512M at most.
2. Common commands
# Add key value pair set key value # Query corresponding key value get key # Append the given value to the end of the original value append key value # Gets the length of the value strlen key # Set the value of the key only when the key does not exist setnx key value # When the value stored in the key is numeric, increase the numeric value by 1 incr key # When the value stored in the key is numeric, press the numeric value key 1 decr key # Increase or decrease the value stored in the key by a certain step incrby/decrby key <step>
3. Atomicity
- The so-called atomic operation refers to the operation that will not be interrupted by the thread scheduling mechanism.
- In a single thread, any operation that can be completed in a single instruction can be regarded as an atomic operation, because the terminal can only occur between instructions
- In multithreading, operations that cannot be interrupted by other processes (threads) are called atomic operations. The atomicity of Redis single command is mainly due to the single thread of Redis.
4. Case analysis
- Is i + + in java an atomic operation?
i + + in java is not an atomic operation. It is mainly divided into three stages: value taking, + +, and value assignment.
- i=0; Two threads perform + + 100 times on I respectively. What is the value?

The final value is 2 ~ 200. Take the picture above as an illustration. Thread a executes 99 times, and then the value of i is 99 But at this time, thread b interrupts thread a and obtains the execution right. Since the b thread has already performed the value taking operation, then there are + + and assignment operations. Get 1 and execute until i = 100. Then, thread a executes the + + step and performs the assignment to get i = 2 at this time. In 200, thread a executes 100 times, and thread b executes 100 times in sequence.
4. Command
# Set one or more key value pairs at the same time mset key1 value1 key2 value2 ... # Get one or more value s at the same time mget key1 key2 key3 ... # Set one or more key value pairs at the same time if and only if all given keys do not exist. If one of them exists, the times will be added. Because it is atomic, if one fails, all fail. msetnx key1 value1 key2 value2... # Get the value range, similar to substring in java, which contains the start position and end position. getrange key Start position end position # Use value to overwrite the string value stored by key, starting from the starting position (the index starts from 0) setrange key <Starting position> value # Set the expiration time in seconds while setting the key value setex key <Expiration time> value # Get the old value and set the new value at the same time getset key value
5. Data structure of the underlying implementation
- The data structure of String is a simple dynamic String, which can be modified.

- The internal space capacity actually allocated for the current string is generally higher than the actual string length len.
- When the string length is less than 1M, the expansion is to double the existing space.
- If it exceeds 1M, only 1M more space will be expanded at one time.
- Note that the maximum length of the string is 512M.
3.3 Redis List
1. Introduction
- Single key multi value
- Redis list is a simple string list, sorted by insertion order. You can add an element to the head (left) or tail (right) of the list.
- Its bottom layer is actually a two-way linked list, which has high operation performance at both ends. The performance of the middle node through index subscript operation will be poor.

2. Common commands
# Insert one or more values from left / right lpush/rpush key value1 value2 value3 .... # Spit out a value from the left / right. The value is in the key, and the light key dies. lpop/rpop key # Spit out a value from the right side of the key1 list and insert it to the left side of the key2 list. rpoplpush key1 key2 # Get elements by index subscript (left to right) lrange key start stop # 0 is the first on the left and - 1 is the first on the right, (0 ~ - 1 means to get all) lrange mylist 0 -1 # Get elements by index subscript (left to right) lindex key index # Get list length llen key # Insert newvalue before / after value linsert key before/after value newvalue # Delete n values from the left (from left to right) lrem key n value # Replace the value whose index is the index of the list key with value lset key index value
3. Data structure
- The data structure of List is quickList.
- When there are few list elements, a continuous memory storage will be used. This structure is ziplost, that is, compressed list. It stores all the elements next to each other and allocates a continuous piece of memory.
- When there is a large amount of data, it will be changed to quicklist. Redis combines the linked list and zipplist to form a quicklist. That is to string multiple ziplist s using bidirectional pointers. This not only meets the fast insertion and deletion performance, but also does not appear too much spatial redundancy.

3.4 Redis Set
1. Introduction
- Single key multi value. The special feature is that set can automatically arrange the weight
- Redis Set is an unordered Set of string type. Its bottom layer is actually a hash table with null value, so the complexity of adding, deleting and searching is O(1).
2. Common commands
# Add one or more member elements to the set key, and the existing member elements will be ignored, that is, they can be de duplicated sadd key value1 value2 ..... # Gets all the values of the collection. smembers key # Judge whether the set key contains the value, with 1 and no 0 sismember key value # Returns the number of elements in the collection. scard key # Delete one or more elements in the collection. srem key value1 value2 .... # Spit out a value randomly from the set. spop key # Randomly take n values from the set. Is not removed from the collection. srandmember key n # Moves a value in a set from one set to another smove source destination value # Returns the intersection element of two collections. sinter key1 key2 # Returns the union element of two collections. sunion key1 key2 # Returns the difference elements of two sets (those in key1, excluding those in key2) sdiff key1 key2
3. Data structure
- The Set data structure is a dict dictionary, which is implemented with a hash table.
- The same is true for Redis's set structure. It also uses a hash structure internally. All values point to the same internal value.
3.5 Redis Hash
1. Introduction
- Redis hash is a collection of key value pairs.
- Redis hash is a mapping table of field and value of string type. Hash is especially suitable for storing objects. Similar to map < string, Object > in Java
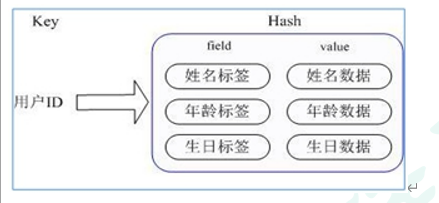
- The corresponding attribute data can be operated through key (user ID) + field (attribute tag). There is no need to store data repeatedly, and there will be no problems of serialization and concurrent modification control
2. Common commands
# Assign value to the field key in the key set hset key field value # Get value from key1 set field hget key1 field # Batch setting hash values hmset key1 field1 value1 field2 value2... # Check whether the given field exists in the hash table key. hexists key1 field # Lists all field s of the hash set hkeys key # List all value s of the hash set hvals key # Add an increment of 1 - 1 to the value of the field in the hash table key hincrby key field increment # Set the value of the field in the hash table key to value if and only if the field does not exist hsetnx key field value
3. Data structure
- There are two data structures corresponding to the Hash type: ziplost (compressed list) and hashtable (Hash table).
- When the field value length is short and the number is small, use ziplist; otherwise, use hashtable.
3.6. Redis ordered set Zset (sorted set)
1. Introduction
- Redis ordered set zset is very similar to ordinary set. It is a string set without duplicate elements.
- The difference is that each member of the ordered set is associated with a score, which is used to sort the members of the set from the lowest score to the highest score. The members of the collection are unique, but the scores can be repeated.
- Because the elements are ordered, you can also quickly get a range of elements according to score or position.
2. Common commands
# Add one or more member elements and their score values to the ordered set key. zadd key score1 value1 score2 value2... # Return the elements in the ordered set key whose subscript is between start and stop, with WITHSCORES, so that the scores and values can be returned to the result set together. zrange key start stop [WITHSCORES] # Returns all members in the ordered set key whose score value is between min and max (including those equal to min or max). Ordered set members are arranged in the order of increasing score value (from small to large). zrangebyscore key min max [withscores] [limit offset count] # Ditto, change to order from large to small. zrevrangebyscore key max min [withscores] [limit offset count] # Increment the score of the element zincrby key increment value # Delete the element with the specified value under the collection zrem key value # Count the number of elements in the set and score interval zcount key min max # Returns the ranking of the value in the collection, starting from 0. zrank key value
3. Data structure
- Hash: the function of hash is to associate the element value with the weight score to ensure the uniqueness of the element value. The corresponding score value can be found through the element value.
- Jump table: the purpose of the jump table is to sort the element value and obtain the element list according to the range of score.