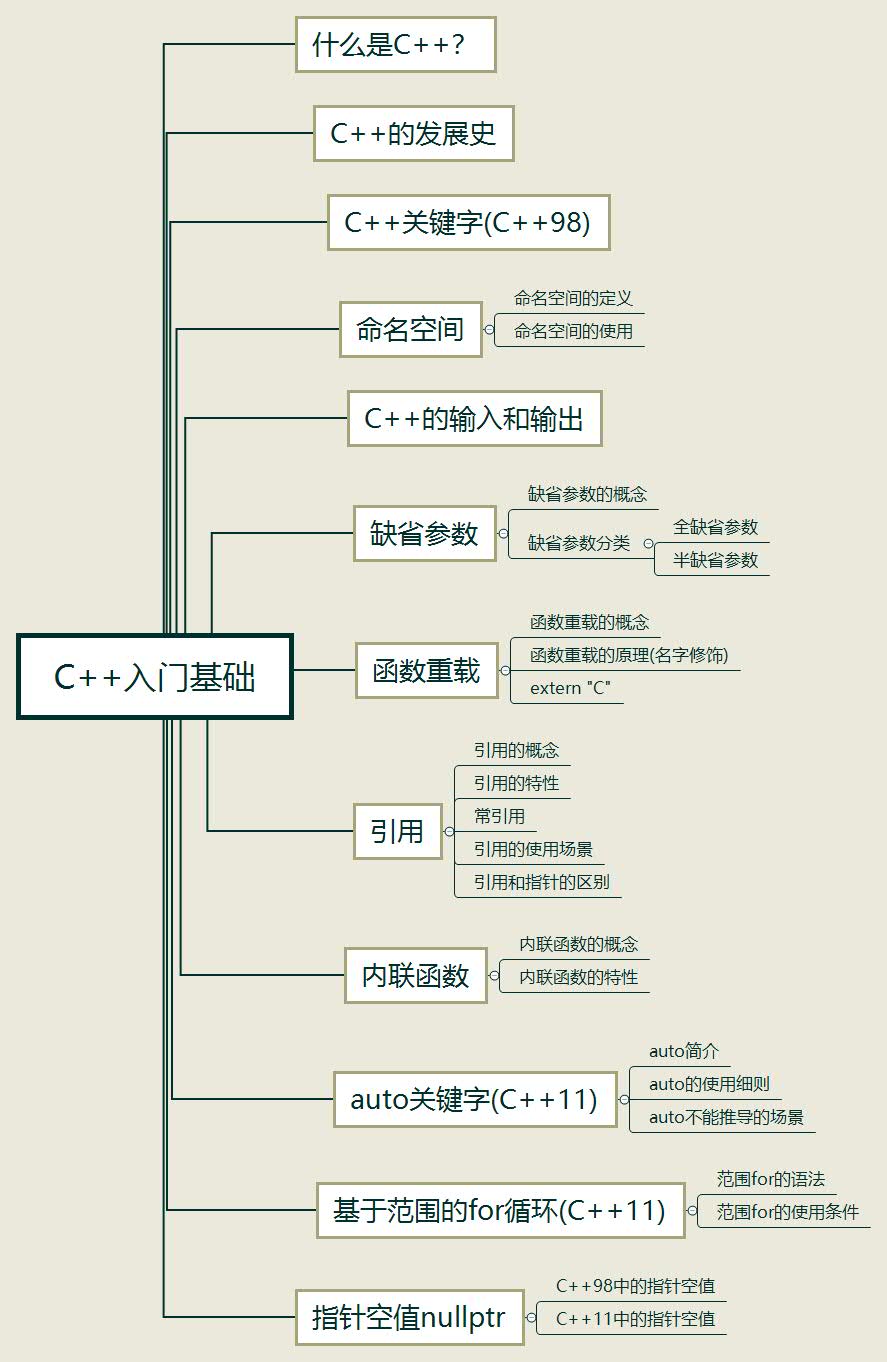
Content outline of this meeting:
What is C + +?
C language is a structured and modular language, which is suitable for dealing with small-scale programs. C language is not suitable for complex problems and large-scale programs that require a high degree of abstraction and modeling. In order to solve the software crisis, in the 1980s, the computer industry put forward the idea of OOP (object-oriented programming), and the object-oriented programming language came into being.
in 1982, Dr. Bjarne Stroustrup introduced and expanded the concept of object-oriented on the basis of C language and invented a new programming language. In order to express the origin relationship between the language and C language, it is named C + +. Therefore, C + + is based on C language. It can not only carry out procedural programming of C language, but also object-based programming characterized by abstract data types, but also object-oriented programming.
Development history of C + +
in 1979, when Benjani of Bell Labs and others tried to analyze the unix kernel, they tried to modularize the kernel, so they extended it on the basis of C language, added the mechanism of classes, and completed a running preprocessing program, called C with classes.
the development of language is also progressing with the progress of the times. Let's take a look at the historical version of C + +:
| stage | content |
|---|---|
| C with classes | Classes and derived classes, public and private members, class construction and deconstruction, friends, inline functions, overloading of assignment operators, etc |
| C++1.0 | Add the concept of virtual function, overloading of functions and operators, references, constants, etc |
| C++2.0 | More perfect support for object-oriented, adding protection members, multiple inheritance, object initialization, abstract classes, static members and const member functions |
| C++3.0 | Further improve and introduce templates to solve the ambiguity problem caused by multiple inheritance and the treatment of corresponding construction and deconstruction |
| C++98 | The first version of C + + standard, which is supported by most compilers, has been recognized by the international organization for Standardization (ISO) and the American Institute for standardization. It rewrites the C + + standard library in the form of template and introduces STL (Standard Template Library) |
| C++03 | The second version of C + + standard has no major changes in language features, mainly including correcting errors and reducing diversity |
| C++05 | The C + + Standards Committee released a Technical Report (TR1), officially renamed C++0x, which is planned to be released sometime in the first decade of this century |
| C++11 | Many features have been added to make C + + more like a new language, such as regular expression, range based for loop, auto keyword, new container, list initialization, standard thread library, etc |
| C++14 | The extension of C++11 is mainly to repair the loopholes and improvements in C++11, such as generic lambda expressions, derivation of return value types of auto, binary literal constants, etc |
| C++17 | Some minor improvements have been made on C++11, and 19 new features have been added, such as static_ The text information of assert () is optional, and the Fold expression is used for variable templates, initializers in if and switch statements, etc |
C + + is still developing backward
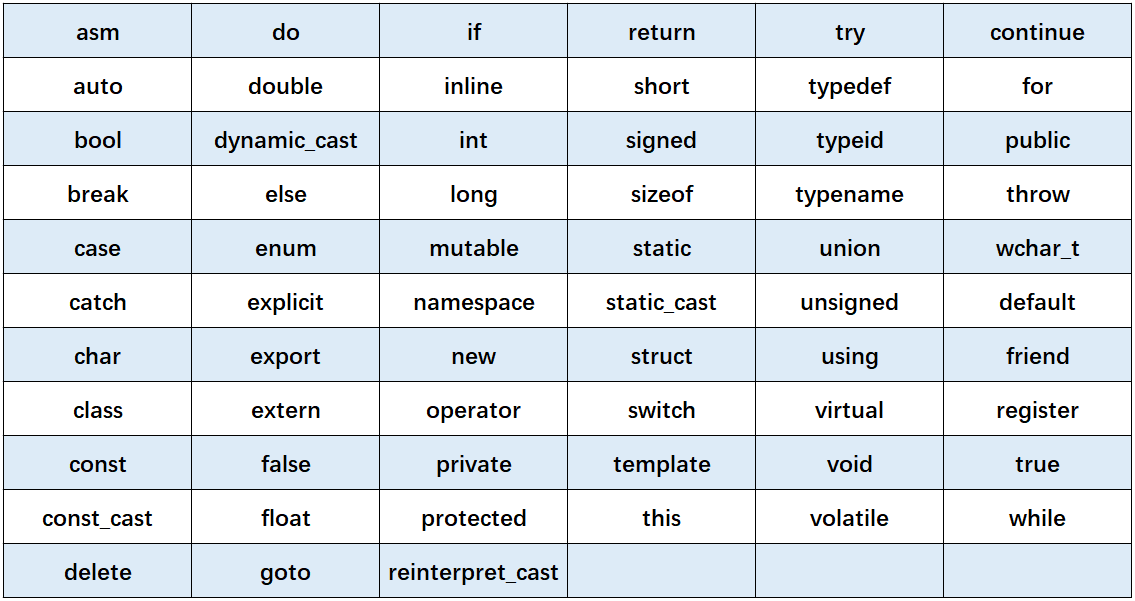
C + + keyword (C++98)
There are 63 keywords in C + +:
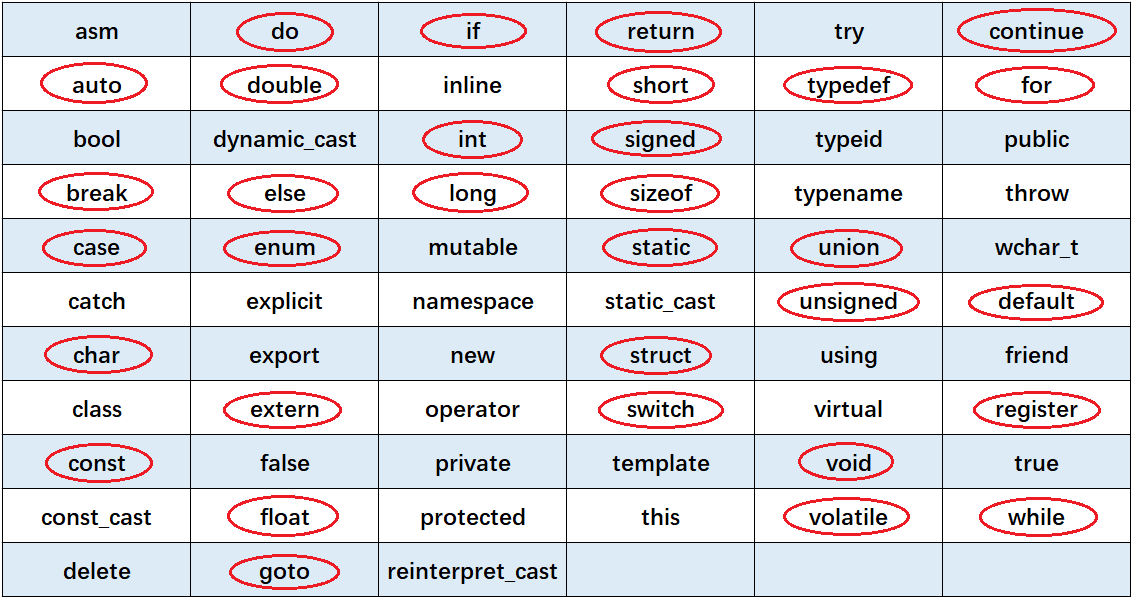
Don't think so. In fact, 32 of them are keywords in C language:
Namespace
in C/C + +, there are a large number of variables, functions and classes. The names of these variables, functions and classes will act on the global scope, which may lead to many naming conflicts.
the purpose of using namespace is to localize identifiers and names to avoid naming conflict or name pollution. The emergence of namespace keyword is aimed at this problem.
Definition of namespace
to define a namespace, you need to use the namespace keyword, followed by the name of the namespace, followed by a pair of {}, {} which is the member of the namespace.
1, Common definition of namespace
//Common definition of namespace
namespace N1 //N1 is the name of the namespace
{
//In the namespace, you can define both variables and functions
int a;
int Add(int x, int y)
{
return x + y;
}
}
2, Namespaces can be nested
//Nested definition of namespace
namespace N1 //Define a namespace named N1
{
int a;
int b;
namespace N2 //Nested definition of another namespace named N2
{
int c;
int d;
}
}
3, Multiple namespaces with the same name are allowed in the same project, and the compiler will finally synthesize their members in the same namespace
therefore, we cannot define two members with the same name in a namespace with the same name.
Note: a namespace defines a new scope, and all contents in the namespace are limited to that namespace.
Use of namespaces
now that we know how to define namespaces, how should we use members in namespaces?
there are three ways to use namespaces:
1, Add namespace name and scope qualifier
the symbol "::" is called a scope qualifier in C + +. We can access the corresponding members in the namespace through "namespace name:: namespace member".
//Add namespace name and scope qualifier
#include <stdio.h>
namespace N
{
int a;
double b;
}
int main()
{
N::a = 10;//Assign a value of 10 to the member a in the namespace
printf("%d\n", N::a);//Print member a in namespace
return 0;
}
2, using to bring in members from a namespace
we can also introduce the members specified in the namespace by "using namespace name:: namespace member". In this way, the introduced member variables can be used directly in the code after the statement.
//using to bring in members from a namespace
#include <stdio.h>
namespace N
{
int a;
double b;
}
using N::a;//Bring member a from namespace into
int main()
{
a = 10;//Assign a value of 10 to the member a in the namespace
printf("%d\n", a);//Print member a in namespace
return 0;
}
3, Use the using namespace namespace name to import
the last way is to introduce all the members in the namespace through the "using namespace namespace name". In this way, all the members in the namespace can be directly used in the code after the statement.
//Use the using namespace namespace name to import
#include <stdio.h>
namespace N
{
int a;
double b;
}
using namespace N;//Bring all members of namespace N into
int main()
{
a = 10;//Assign a value of 10 to the member a in the namespace
printf("%d\n", a);//Print member a in namespace
return 0;
}
Input and output in C + +
when we were learning C language, the first code we wrote was to output a "hello world" on the screen. According to the custom of learning computer language, now we should also use C + + to say hello to the world:
#include <iostream>
using namespace std;
int main()
{
cout << "hello world!" << endl;
return 0;
}
in C language, there are standard input and output functions scanf and printf, while in C + +, there are cin standard input and cout standard output. To use scanf and printf functions in C language, you need to include the header file stdio h. To use cin and cout in C + +, you need to include the header file iostream and std standard namespace.
the input and output mode of c + + is more convenient than that of c language, because the input and output of c + + does not need to add data format control, for example, the integer type is% d and the character type is% c.
#include <iostream>
using namespace std;
int main()
{
int i;
double d;
char arr[20];
cin >> i;//Read an integer
cin >> d;//Read a floating point
cin >> arr;//Read a string
cout << i << endl;//Print integer i
cout << d << endl;//Print floating point d
cout << arr << endl;//Print string arr
return 0;
}
Note: endl in the code means to output a newline character.
Default parameters
Concept of default parameters
default parameter refers to specifying a default value for the parameters of a function when declaring or defining a function. When calling this function, if no argument is specified, the default value is adopted; otherwise, the specified argument is used.
#include <iostream>
using namespace std;
void Print(int a = 0)
{
cout << a << endl;
}
int main()
{
Print();//No argument specified, use the default value of the parameter (print 0)
Print(10);//If an argument is specified, use the specified argument (print 10)
return 0;
}
Default parameter classification
All default parameters
All default parameters, that is, all formal parameters of the function are set as default parameters.
void Print(int a = 10, int b = 20, int c = 30)
{
cout << a << endl;
cout << b << endl;
cout << c << endl;
}
Semi default parameter
Semi default parameters, that is, the parameters of the function are not all default parameters.
void Print(int a, int b, int c = 30)
{
cout << a << endl;
cout << b << endl;
cout << c << endl;
}
be careful:
1. The semi default parameters must be given from right to left, and cannot be given at intervals.
//Error example
void Print(int a, int b = 20, int c)
{
cout << a << endl;
cout << b << endl;
cout << c << endl;
}
2. Default parameters cannot appear in function declaration and definition at the same time
//Error example
//test.h
void Print(int a, int b, int c = 30);
//test.c
void Print(int a, int b, int c = 30)
{
cout << a << endl;
cout << b << endl;
cout << c << endl;
}
The default parameter can only appear when the function is declared or when the function is defined (either is correct).
3. The default value must be a constant or a global variable.
//Correct example
int x = 30;//global variable
void Print(int a, int b = 20, int c = x)
{
cout << a << endl;
cout << b << endl;
cout << c << endl;
}
function overloading
Concept of function overloading
function overloading is a special case of functions. C + + allows to declare several functions with the same name in the same scope, and the formal parameter lists of these functions with the same name must be different. Function overloading is often used to deal with problems with similar implementation functions but different data types.
#include <iostream>
using namespace std;
int Add(int x, int y)
{
return x + y;
}
double Add(double x, double y)
{
return x + y;
}
int main()
{
cout << Add(1, 2) << endl;//Print 1 + 2 Results
cout << Add(1.1, 2.2) << endl;//Print the results of 1.1 + 2.2
return 0;
}
Note: different parameter lists refer to different parameter numbers, parameter types or parameter sequences. If only the return types are different, it cannot constitute an overload.
Principle of function overloading (name modification)
Why does C + + support function overloading, while C language does not support function overloading?
we know that a C/C + + program needs to go through the following stages to run: preprocessing, compiling, assembling and linking.
we know that in the compilation stage, the global variable symbols of each source file in the program will be summarized separately. In the assembly stage, each symbol summarized in the source file will be assigned an address (if the symbol is only a declaration, it will be assigned a meaningless address), and then a symbol table will be generated respectively. Finally, the symbol table of each source file will be merged during the link. If the same symbol appears in the symbol table of different source files, the legal address will be taken as the merged address (relocation).
in C language, when symbols are summarized in the assembly stage, the symbol after the summary of a function is its function name. Therefore, when multiple identical function symbols are found during the summary, the compiler will report an error. When C + + performs symbol summary, it changes the modification of the name of the function. The symbol summarized by the function is no longer just the function name of the function, but a symbol summarized through the type, number and order of its parameters. In this way, even for functions with the same function name, as long as the type of parameters or the number of parameters or the order of parameters are different, Then the symbols summarized are different.
Note: under different compilers, the modification of function names is different, but they are the same.
Summary:
1. C language cannot support overloading because functions with the same name cannot be distinguished. C + + is distinguished by function modification rules. As long as the formal parameter list of the function is different, the modified name is different, and overloading is supported.
2. In addition, we also understand why function overloading requires different parameters, and the root return value doesn't matter.
extern "C"
sometimes in C + + projects, it may be necessary to compile some functions in the style of C. add "extern C" before the function, which means to tell the compiler to compile the function according to the rules of C language.
Note: after adding "extern C" before the function, the function cannot support overloading.
quote
Referenced concepts
a reference does not define a variable, but takes an alias for an existing variable. The compiler will not open up memory space for the referenced variable. It shares the same memory space with the variable it references.
Its basic form is: Type & reference variable name (object name) = reference entity.
#include <iostream>
using namespace std;
int main()
{
int a = 10;
int& b = a;//Gave variable a an alias called b
cout << "a = " << a << endl;//a the print result is 10
cout << "b = " << b << endl;//b the print result is also 10
b = 20;//Changing b means changing a
cout << "a = " << a << endl;//a the print result is 20
cout << "b = " << b << endl;//b the print result is also 20
return 0;
}
Note: the reference type must be the same type as the reference entity.
Referenced properties
1, References must be initialized when defined
Correct example:
int a = 10; int& b = a;//References must be initialized when defined
Examples of errors:
int c = 10; int &d;//Not initialized when defining d = c;
2, A variable can have multiple references
For example:
int a = 10; int& b = a; int& c = a; int& d = a;
At this time, b, c and d are all references to variable a.
3, Once a reference refers to an entity, it can no longer refer to other entities
For example:
int a = 10; int& b = a;
At this point, b is already a reference of a, and b can no longer reference other entities. If you write the following code, you want b to refer to another variable c instead:
int a = 10; int& b = a; int c = 20; b = c;//Your idea: let b quote c instead
But the code doesn't follow your mind. The code means: assign the entity referenced by b to c, that is, change the content of variable a to 20.
Often cited
as mentioned above, the reference type must be of the same type as the reference entity. However, only the same type cannot guarantee successful reference. If we use a common reference type to reference its corresponding type, but the type is modified by const, the reference will not succeed.
int main()
{
const int a = 10;
//int& ra = a; // There will be an error when compiling this statement. A is a constant
const int& ra = a;//correct
//int& b = 10; // An error will occur when compiling this statement. 10 is a constant
const int& b = 10;//correct
return 0;
}
we can understand a type modified by const as a safe type because it cannot be modified. If we give a safe type to an unsafe type (which can be modified), we will not succeed.
Referenced usage scenarios
1, Reference as parameter
I still remember the exchange function in C language. When learning C language, I often use the exchange function to explain the difference between value transmission and address transmission. Now that we have learned about references, we can use pointers as formal parameters:
//Exchange function
void Swap(int& a, int& b)
{
int tmp = a;
a = b;
b = tmp;
}
because here a and b are references to the incoming arguments, we exchange the values of a and b, which is equivalent to exchanging the two incoming arguments.
2, Reference as return value
of course, references can also be used as return values, but we should pay special attention to that the data we return cannot be ordinary local variables created inside the function, because ordinary local variables defined inside the function will be destroyed with the end of the function call. The data we return must be static modified, dynamically developed, or global variables that will not be destroyed with the end of the function call.
int& Add(int a, int b)
{
static int c = a + b;
return c;
}
Note: if the function scope is given when the function returns, and the returned object has not been returned to the system, you can use reference return; If it has been returned to the system, it must be returned by value passing.
The difference between reference and pointer
in terms of syntax, a reference is an alias. There is no independent space. It shares the same space with the reference entity.
int main()
{
int a = 10;
//Grammatically, there is no new space for a
int& ra = a;
ra = 20;
//Grammatically, a pa pointer is defined here, which opens up a space of 4 bytes (32-bit platform) for storing the address of A
int* pa = &a;
*pa = 20;
return 0;
}
However, in the underlying implementation, the reference actually has space:

From the perspective of assembly, the underlying implementation of reference is also handled in a way similar to pointer storage address.
Difference between reference and pointer (important):
1. The reference must be initialized when defined, and the pointer is not required.
2. After a reference references an entity during initialization, it can no longer reference other entities, and the pointer can point to any entity of the same type at any time.
3. There is no NULL reference, but there is a NULL pointer.
4. Different meanings in sizeof: the reference result is the size of the reference type, but the pointer is always the number of bytes in the address space (4 bytes in 32-bit platform).
5. The self increment operation of the reference is equivalent to the increase of the entity by 1, and the self increment operation of the pointer is the backward offset of the pointer by one type.
6. There are multi-level pointers, but there are no multi-level references.
7. There are different ways to access entities. The pointer needs to show dereference, and the reference is handled by the compiler itself.
8. References are relatively safer to use than pointers.
Inline function
Concept of inline function
functions decorated with inline are called inline functions. During compilation, the C + + compiler will expand where the inline functions are called. There is no overhead of function stack pressing. The use of inline functions can improve the running efficiency of the program.
we can further see its advantages by observing the assembly code calling ordinary functions and inline functions:
int Add(int a, int b)
{
return a + b;
}
int main()
{
int ret = Add(1, 2);
return 0;
}
The left of the figure below is the assembly code of the above code, and the right of the figure below is the assembly code of the function Add plus inline:

It can be seen from the assembly code that there is no assembly instruction to call the function when calling the inline function.
Characteristics of inline functions
1. Inline is a method of exchanging space for time, which saves the extra cost of calling functions. Because the inline function will expand at the calling position, the code is very long or recursive functions are not suitable for inline functions. Small functions that are frequently called are suggested to be defined as inline functions.
2. Inline is only a suggestion for the compiler. The compiler will optimize automatically. If there is recursion in the function defined as inline, the compiler will ignore inline during optimization.
3. Inline does not recommend the separation of declaration and definition, which will lead to link errors. Because the inline is expanded, there will be no function address, and the link will not be found.
auto keyword (C++11)
Introduction to auto
in the early C/C + +, the meaning of auto is that the variable modified by auto is a local variable with automatic memory, but unfortunately, no one has used it.
in C++11, the standards committee gives a new meaning to Auto: Auto is no longer a storage type indicator, but as a new type indicator to indicate the compiler. The variables declared by auto must be derived by the compiler at compile time.
#include <iostream>
using namespace std;
double Fun()
{
return 3.14;
}
int main()
{
int a = 10;
auto b = a;
auto c = 'A';
auto d = Fun();
//Print the types of variables b,c,d
cout << typeid(b).name() << endl;//The print result is int
cout << typeid(c).name() << endl;//The print result is char
cout << typeid(d).name() << endl;//The print result is double
return 0;
}
Note: when using auto variable, it must be initialized. In the compilation stage, the compiler needs to deduce the actual type of auto according to the initialization expression. Therefore, auto is not a "type" declaration, but a "placeholder" of type declaration. The compiler will replace Auto with the actual type of variable at compile time.
Usage rules of auto
1, auto is used in conjunction with pointers and references
when declaring pointer type with auto, there is no difference between auto and auto *, but when declaring reference type with auto, you must add &.
#include <iostream>
using namespace std;
int main()
{
int a = 10;
auto b = &a; //It is automatically deduced that the type of b is int*
auto* c = &a; //Automatically deduces that the type of c is int*
auto& d = a; //Automatically deduces that the type of d is int
//Print the types of variables b,c,d
cout << typeid(b).name() << endl;//The print result is int*
cout << typeid(c).name() << endl;//The print result is int*
cout << typeid(d).name() << endl;//The print result is int
return 0;
}
Note: when declaring references with auto, you must add &, otherwise you will only create ordinary variables with the same entity type.
2, Define multiple variables on the same line
when multiple variables are declared on the same line, these variables must be of the same type, otherwise the compiler will report an error, because the compiler actually deduces only the first type, and then uses the derived type to define other variables.
int main()
{
auto a = 1, b = 2; //correct
auto c = 3, d = 4.0; //Compiler error: 'auto' must always be derived to the same type
return 0;
}
Scenes that cannot be deduced by auto
1, auto cannot be an argument to a function
the following code compilation failed. auto cannot be used as a formal parameter type because the compiler cannot deduce the actual type of x.
void TestAuto(auto x)
{}
2, auto cannot be used directly to declare arrays
int main()
{
int a[] = { 1, 2, 3 };
auto b[] = { 4, 5, 6 };//error
return 0;
}
Range based for loop (C++11)
Syntax for scope
if we want to traverse an array in C++98, we can do it in the following way:
int arr[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
//Multiply all array element values by 2
for (int i = 0; i < sizeof(arr) / sizeof(arr[0]); i++)
{
arr[i] *= 2;
}
//Print all elements in the array
for (int i = 0; i < sizeof(arr) / sizeof(arr[0]); i++)
{
cout << arr[i] << " ";
}
cout << endl;
the above method is also the method of traversing arrays used in our c language, but for a set with a range, loops are redundant and sometimes easy to make mistakes. Therefore, a range based for loop is introduced in C++11. The parentheses after the for loop are divided into two parts by colons: the first part is the variables used for iteration in the range, and the second part represents the range to be iterated.
int arr[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
//Multiply all array element values by 2
for (auto& e : arr)
{
e *= 2;
}
//Print all elements in the array
for (auto e : arr)
{
cout << e << " ";
}
cout << endl;
Note: similar to ordinary loops, you can use continue to end this loop or break to jump out of the whole loop.
Conditions for use of the scope
1, The scope of the for loop iteration must be determined
for an array, it is the range of the first element and the last element in the array; For classes, methods of begin and end should be provided. Begin and end are the scope of for loop iteration.
2, Iterative objects should implement + + and = = operations
this is about iterators. Let's learn about them first.
Pointer null nullptr
Pointer null value in C++98
in good C/C + + programming habits, it is best to give a suitable initial value to a variable while declaring it, otherwise unexpected errors may occur. For example, for uninitialized pointers, if a pointer has no legal point, we basically initialize it in the following way:
int* p1 = NULL; int* p2 = 0;
NULL is actually a macro. You can see the following code in the traditional C header file (stddef.h):
/* Define NULL pointer value */ #ifndef NULL #ifdef __cplusplus #define NULL 0 #else /* __cplusplus */ #define NULL ((void *)0) #endif /* __cplusplus */ #endif /* NULL */
you can see that NULL may be defined as literal constant 0 or as a constant of typeless pointer (void *). However, no matter what definition is adopted, some troubles will inevitably be encountered when using NULL pointers, such as:
#include <iostream>
using namespace std;
void Fun(int p)
{
cout << "Fun(int)" << endl;
}
void Fun(int* p)
{
cout << "Fun(int*)" << endl;
}
int main()
{
Fun(0); //The print result is Fun(int)
Fun(NULL); //The print result is Fun(int)
Fun((int*)NULL); //The print result is Fun(int *)
return 0;
}
the original intention of the program is to call the pointer version of Fun(int* p) function through Fun(NULL), but since NULL is defined as 0, Fun(NULL) finally calls the Fun(int p) function.
Note: in C++98, the literal constant 0 can be either an integer number or an untyped pointer (void *) constant, but the compiler regards it as an integer constant by default. If you want to use it as a pointer, you must cast it.
Pointer null value in C++11
for the problem in C++98, C++11 introduces the keyword nullptr.
be careful:
1. When nullptr is used to represent the null value of the pointer, it is not necessary to include the header file, because nullptr is introduced by C++11 as a keyword.
2. In C++11, sizeof(nullptr) and sizeof((void*)0) occupy the same number of bytes.
3. In order to improve the robustness of the code, it is recommended to use nullptr when representing the null value of the pointer in the following order.