This article was first published in: Walker AI
In software testing, writing interface automation cases for the project has become the resident testing work of testers. Taking python as an example, this paper is based on three use case data reading methods used by the author: xlrd, pandas and yaml. Their usage methods and simple analysis are briefly introduced below.
1. Python third-party library xlrd
xlrd module can be used to read EXCEL documents. It is the most commonly used use case reading method. The usage is as follows. Taking the demonstration convention registration interface as an example, first create an excel document, in which the user-defined interface use case parameters are as follows:
(the following data are generated randomly and do not involve any system)
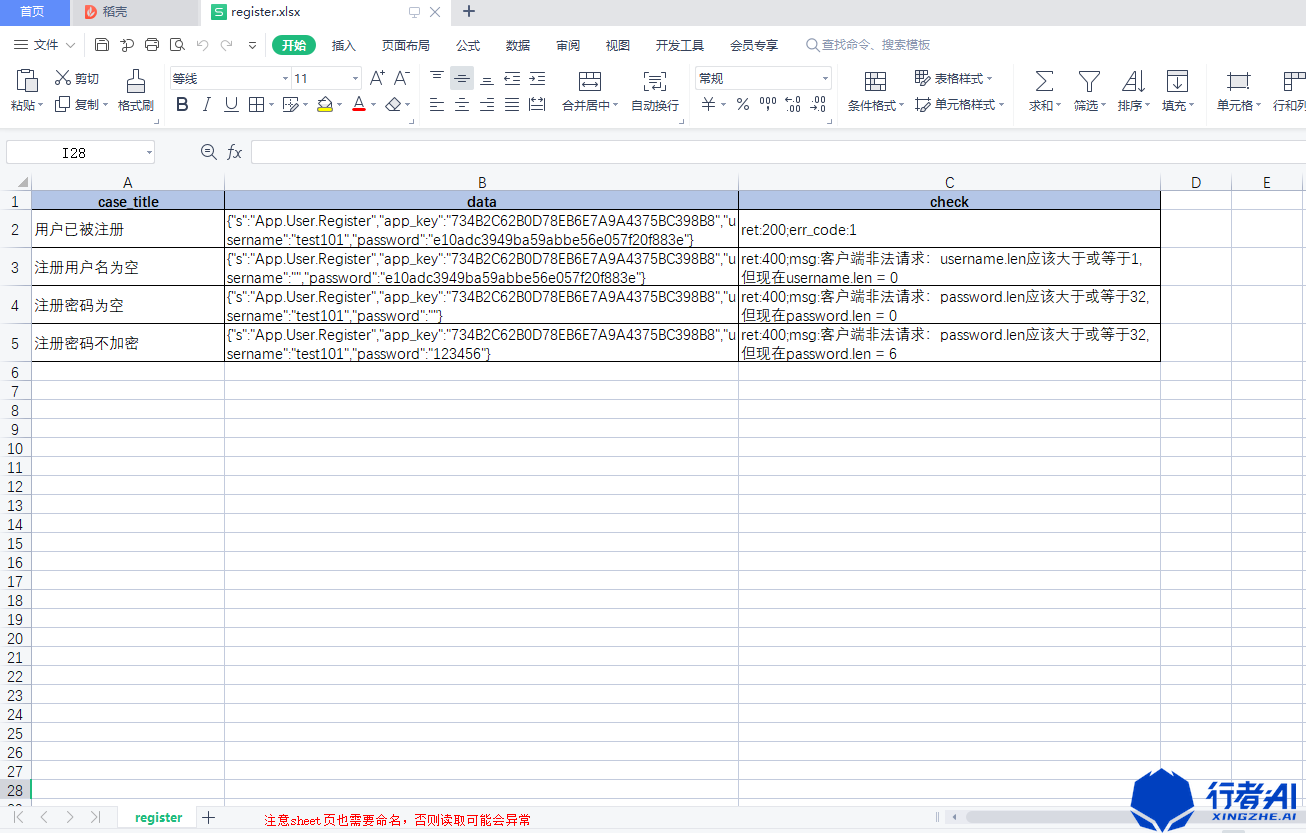
After python has installed the third-party library, start reading the interface use cases. For the convenience of demonstration, the method is not encapsulated.
xlrd code demonstration
The following is the example code:
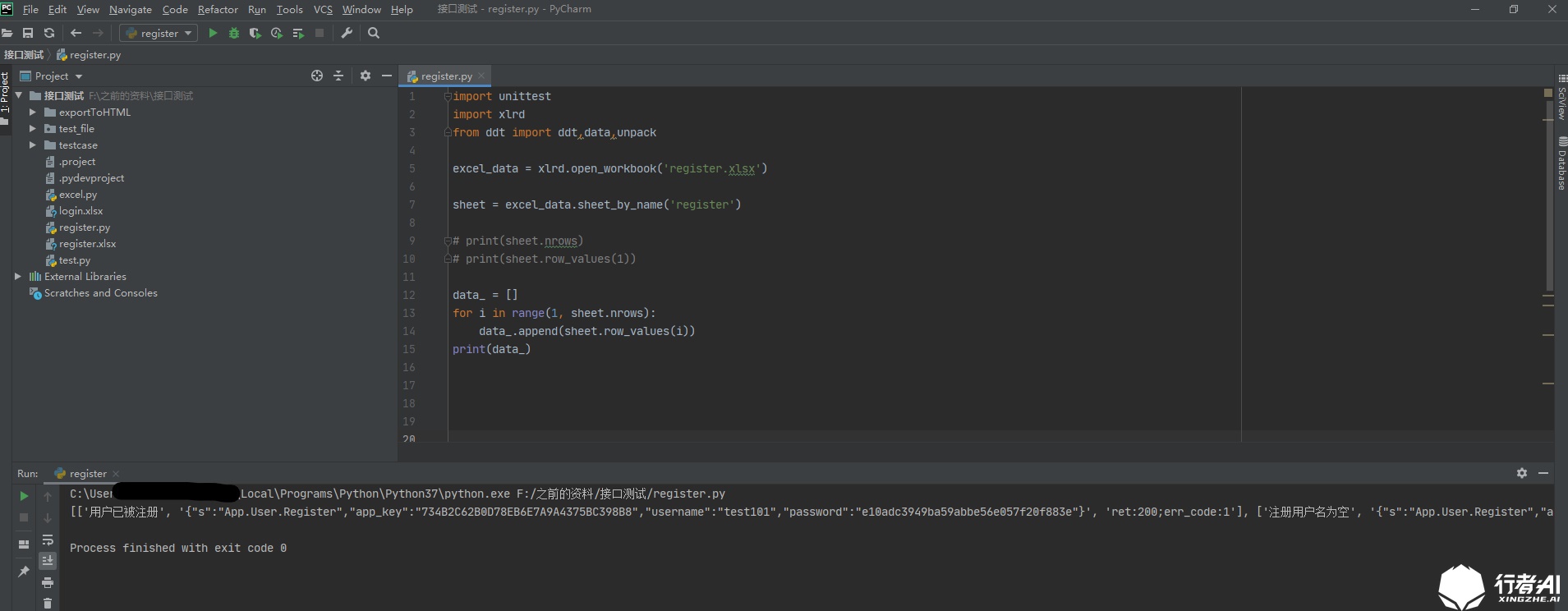
import unittest
import xlrd
# Open the interface case excel file
excel_data = xlrd.open_workbook('register.xlsx')
# Read the sheet page where the use case is stored in the excel file, and there is no requirement for naming
sheet = excel_data.sheet_by_name('register')
print(sheet.nrows)
print(sheet.row_values(1))
# Append all the read use cases to the data list
data = []
for i in range(1, sheet.nrows):
data.append(sheet.row_values(i))
print(data)
class register(unittest.TestCase):
def test_register_check(self):
pass
After executing the py file, print the read data list and successfully read the use case data in the excel file:
However, the above method will store all the use cases of the whole excel file in a list, which is not convenient for data access. Now we split the data and read the data in combination with ddt data-driven mode:
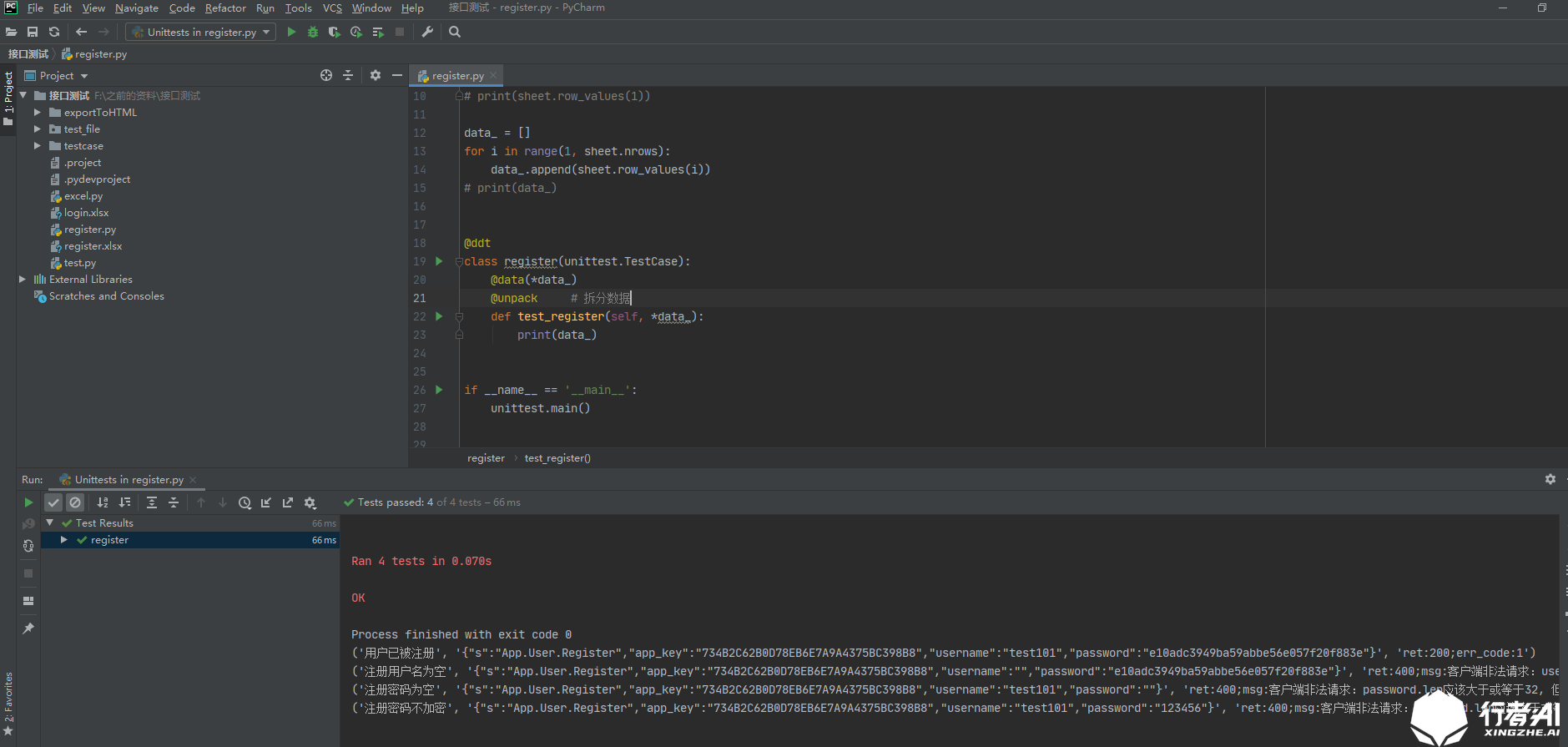
import unittest
import xlrd
from ddt import ddt,data,unpack
excel_data = xlrd.open_workbook('register.xlsx')
sheet = excel_data.sheet_by_name('register')
# print(sheet.nrows)
# print(sheet.row_values(1))
data_ = []
for i in range(1, sheet.nrows):
data_.append(sheet.row_values(i))
print(data_)
# Introduced decorator @ddt; @ data of imported data; @ unpack of split data
@ddt
class register(unittest.TestCase):
@data(*data_)
@unpack
def test_register(self, title, data, check):
print(data)
if __name__ == '__main__':
unittest.main()
Through the data and unpack methods in ddt, each data in excel file is a separate list, which is more convenient for interface test cases:
xlrd module is frequently used in interface automation, and the calling method is also very simple. After reading the excel test case, you can also use the decorator DDT to split the data to simplify the data.
xlrd is applicable to projects with few interface data and infrequent adjustment of interface fields. If there are a large number of interfaces in the project, the content of the excel file storing the use cases will continue to expand when writing the interface use cases. The readability and maintainability of test cases will become a difficult problem in the later test work and affect the test efficiency.
2. Python third-party library pandas
Pandas is a data analysis package of python, which can help users deal with large data sets. The test data in excel can be obtained by using the DataFrame (two-dimensional tabular data structure) method in pandas. Like xrld, pandas can read excel files.
First, create an excel file to store test data:

pandas code demonstration
Example code:
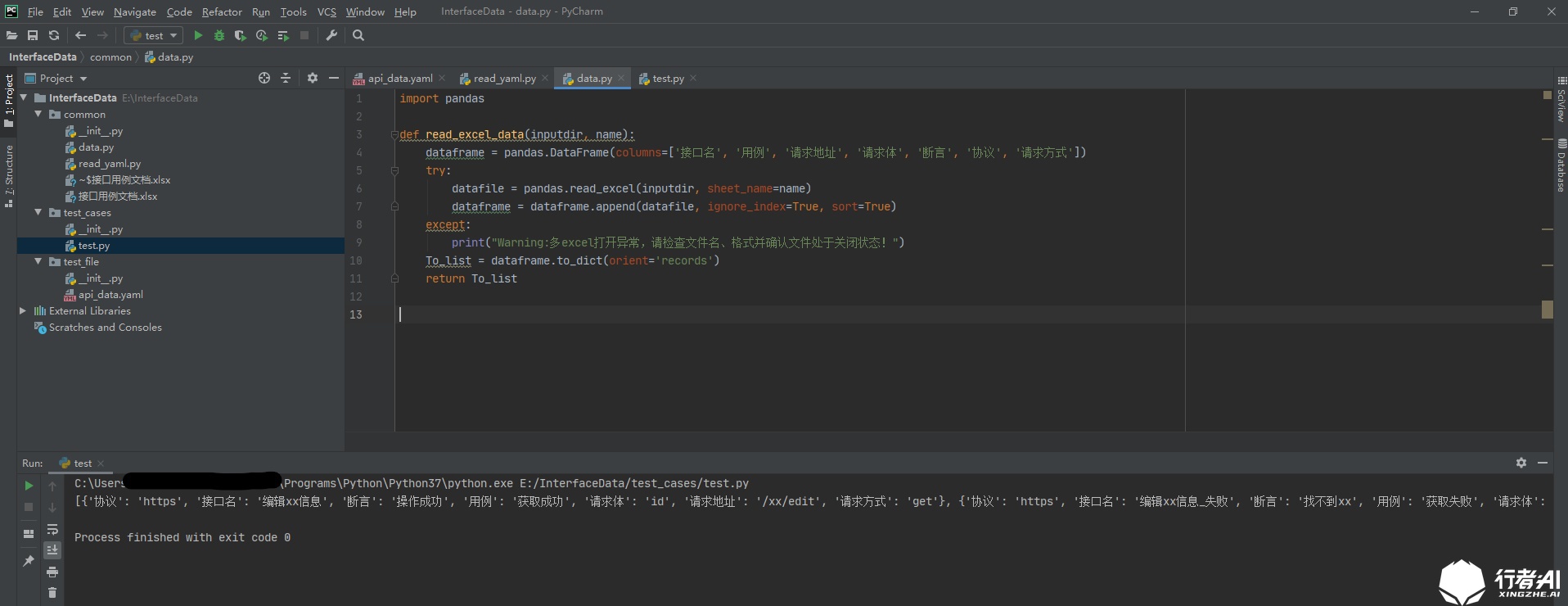
# Read the use case from the excel file. The name parameter is the sheet name
def read_excel_data(inputdir,name):
dataframe = pandas.DataFrame(columns=['Interface name','Use case','Request address','Request body','Assert','agreement','Request mode']) # The passed in parameter is the column name in the excel file
try:
datafile = pandas.read_excel(inputdir,sheet_name=name)
dataframe = dataframe.append(datafile, ignore_index=True, sort=True)
except:
print("Warning:excel File opening exception, please try again!")
To_list = dataframe.to_dict(orient='records') # When parameter = 'records', it is in the form of list after conversion
return To_list
from common.data import read_excel_data
import pytest
def getdata(path):
getdata = read_excel_data(path, 'edit xx')
print(getdata)
path = r'..\common\Interface use case document.xlsx' # The path of excel file is indicated according to the actual project structure
getdata(path)
Call the encapsulated method and successfully read all use case data in excel file:
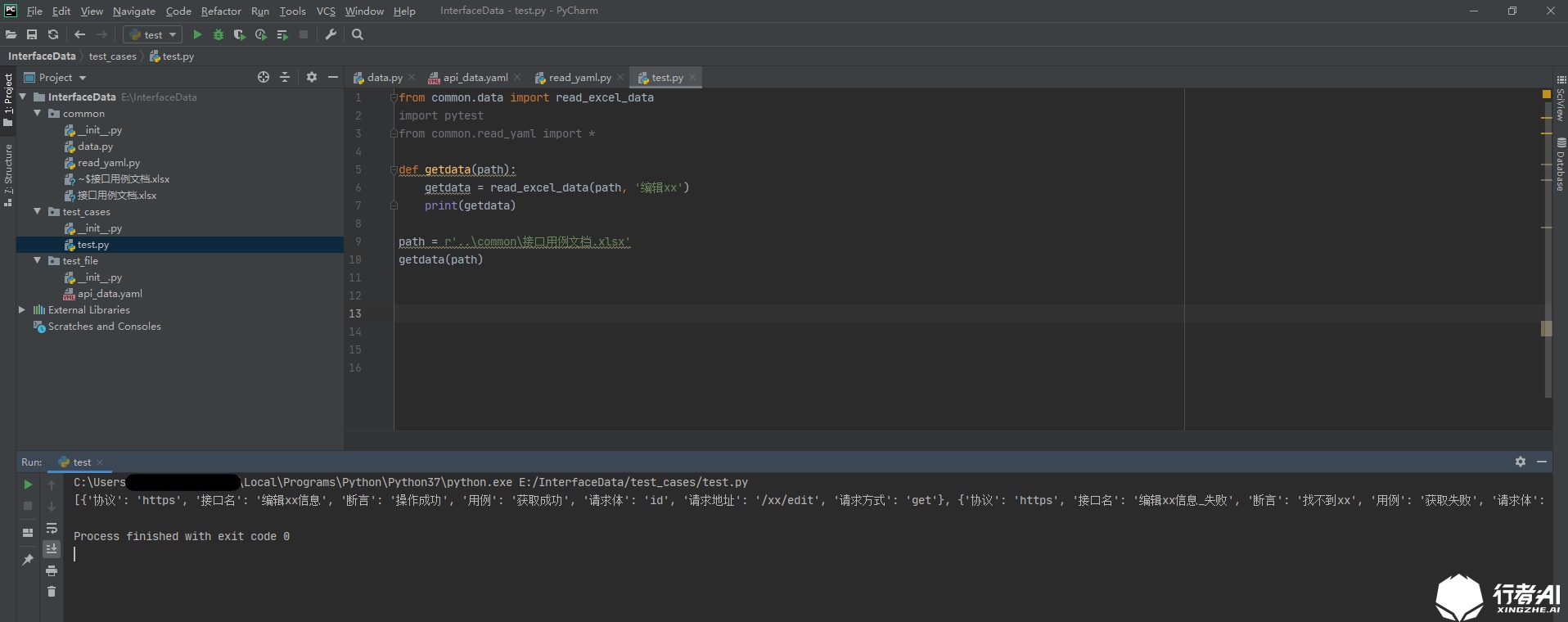
This method is similar to xlrd in that it obtains the interface use cases we need by reading the data in the two-dimensional table.
Reading test cases in excel files through xlrd is the mainstream data reading method in interface testing. However, through the case above, it can be found that if there are more and more data in excel files, the maintenance cost of post test is relatively high. At the same time, the table format is not easy to read in a large amount of data. This is also a drawback of such methods.
3. Python third-party library yaml
yaml is a serialization language used to write configuration files. The file format output can be list, dictionary or nesting. Hierarchical relationships are separated by spaces, but tab indentation is not supported.
Dashes and spaces ("-"): list format
# The following data will be read in the form of list - testapi - url - get
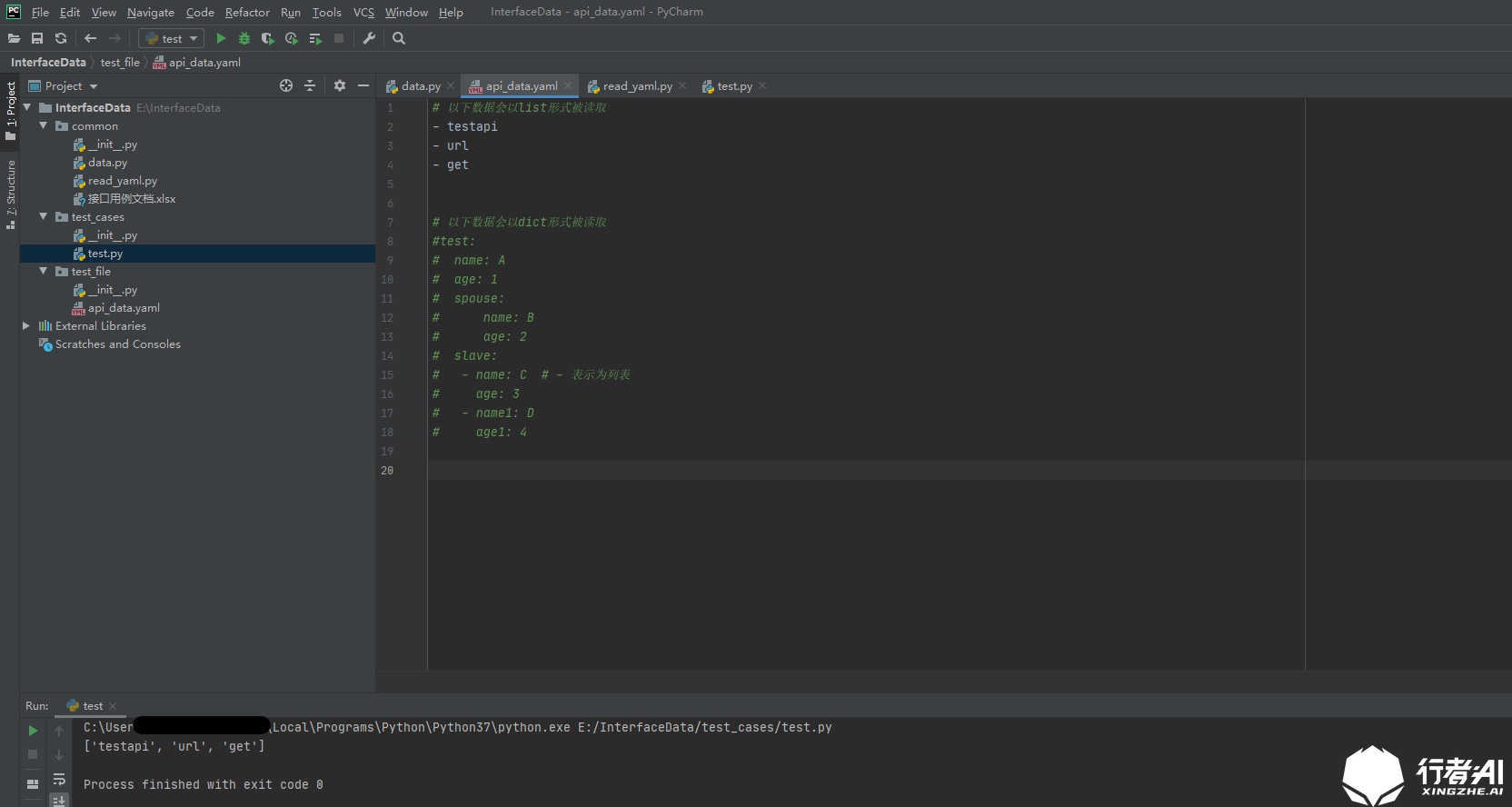
Common yaml formats:
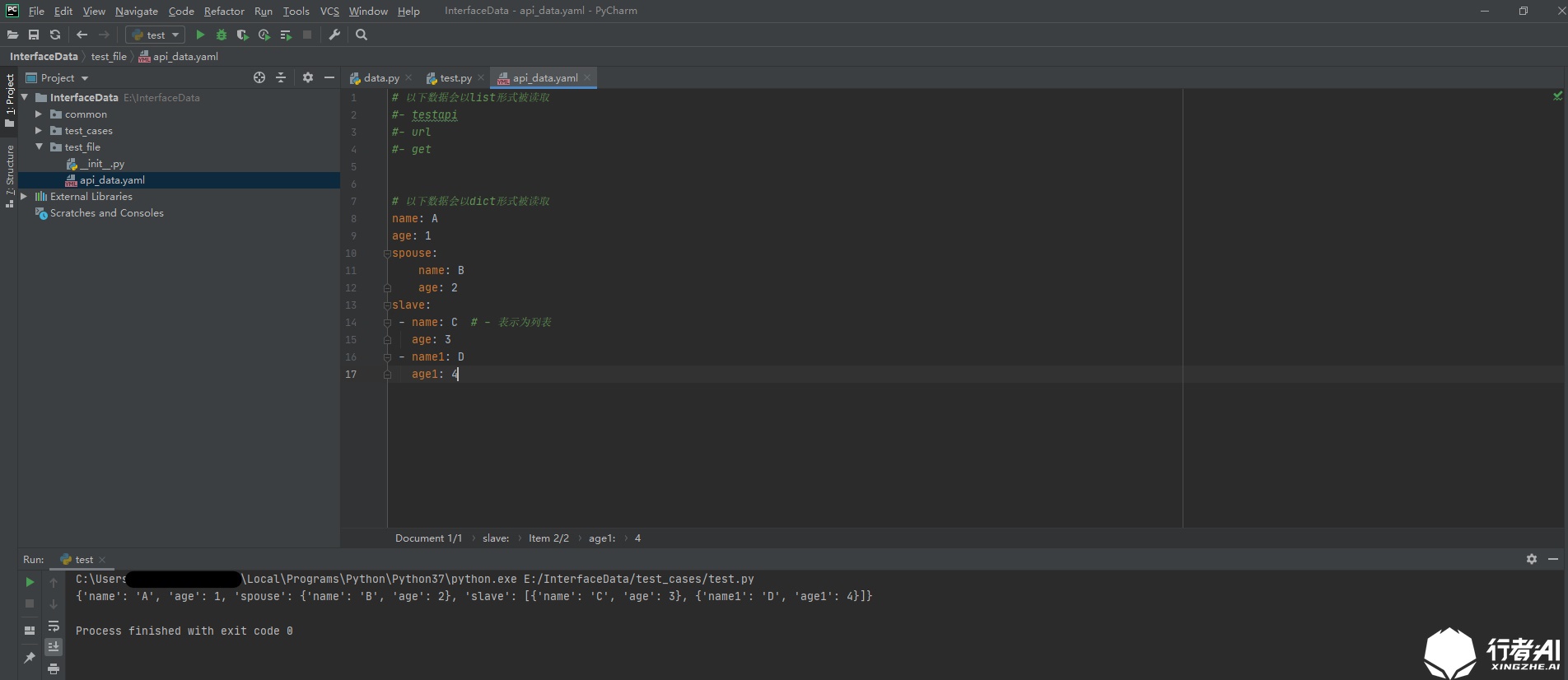
Colon and space (":"): dictionary format
# The following data will be read in the form of dict
name: A
age: 1
spouse:
name: B
age: 2
slave:
- name: C # -Represented as a list
age: 3
- name1: D
age1: 4
yaml code demonstration
Read the dict data in yaml file. The code is as follows:
import os
import yaml
class LoadTestData:
# Set the path to get yaml file data
def load_data(self, file_name):
yaml_path = os.path.join(os.path.join(os.path.dirname(os.path.dirname(os.path.abspath(__file__))),
'test_file'), file_name)
yaml_data = yaml.load(open(yaml_path), Loader=yaml.FullLoader)
# print(yaml_data)
return yaml_data
def get_yaml_data(api_file, api_name):
'''
obtain yaml in api_name Data
:param api_file: api file location
:param api_name: api File name
:return: file data
'''
data = LoadTestData().load_data(api_file)[api_name]
print(data)
return data
if __name__ == '__main__':
file_name = 'api_data.yaml'
api_name = 'test'
# LoadTestData().load_data(file_name)
get_yaml_data(file_name,api_name )
print('Read successful')
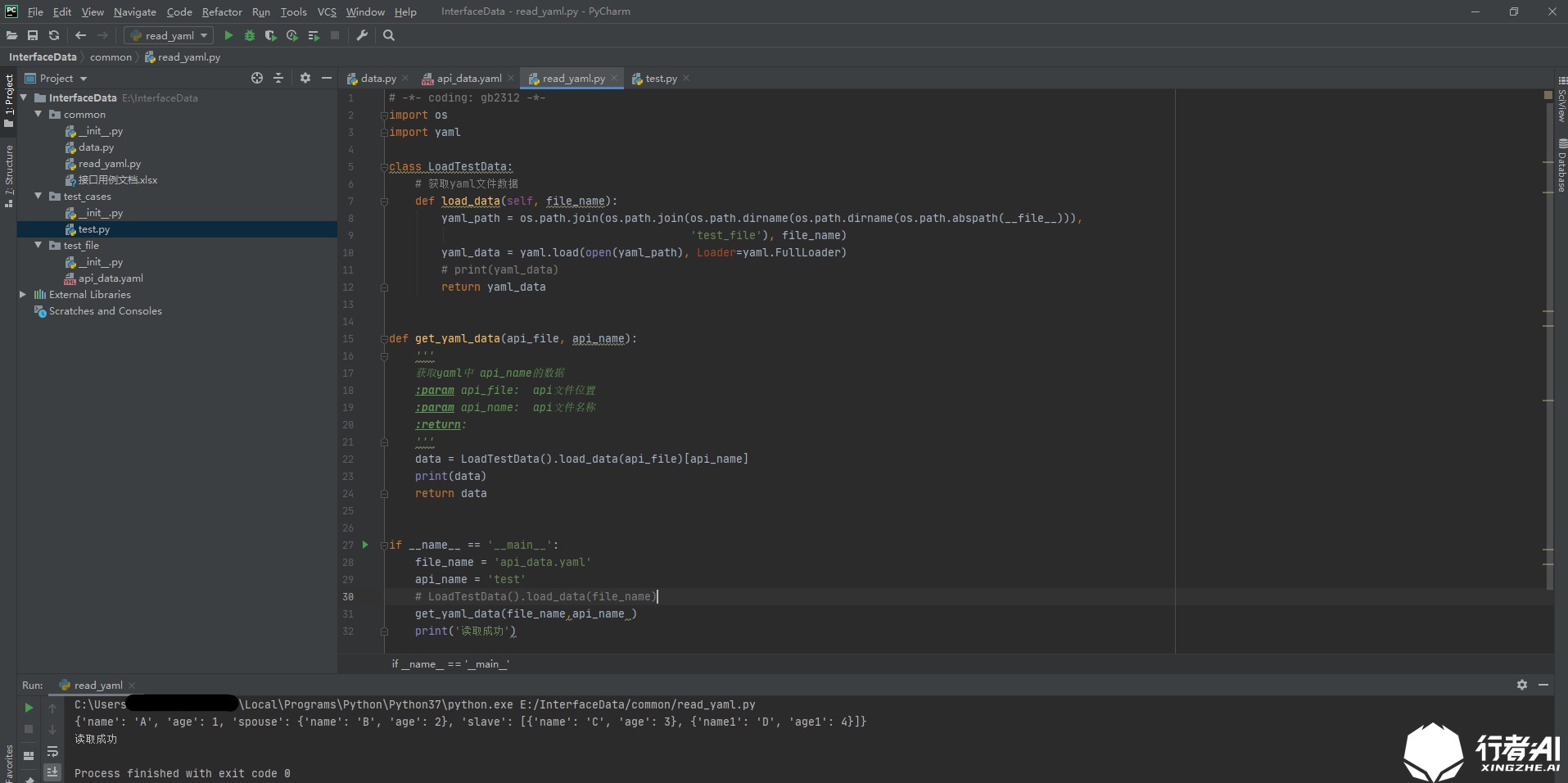
Notice yaml When load is called, an exception may be prompted because the yaml version is higher. Solution: specify loader = yaml Fullloader resolves the exception.
According to the practical application of yaml above, it can be found that compared with the data stored in excel, yaml is more readable, and python itself also supports the creation of new yaml files, which has better interaction with the script language. For different test modules, you can also create different yaml files to realize the test data isolation between functional modules.
summary
During the test, whether the data is stored in Excel or yaml file, the test data can be quickly integrated and assembled. However, when the data stored in excel is too large, there are some problems, such as reduced readability and long script execution time. Yaml has the advantages of simplicity, high interaction with python, and can isolate the test data of function templates from each other. However, we also need to have some understanding of the writing specification of yaml in order to use it correctly.
This article is just a simple sharing based on python test data reading. If there is anything inappropriate, you are welcome to correct.
PS: more technical dry cargo, pay close attention to the official account xingzhe_ai, discuss with the walkers.