- Cache Basics
At present, general CPU s have three levels of memory (L1, L2, L3), as shown in the figure below.
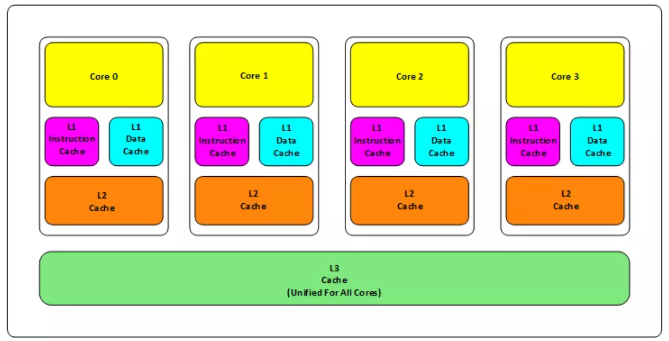
Of which:
- L1 cache is divided into two types: instruction cache and data cache. L2 and L3 caches are independent of instructions and data.
- L1 and L2 are cached in each CPU core, and L3 is the memory shared by all CPU cores.
- The closer L1, L2 and L3 are to the CPU, the faster, but also the smaller; The farther away from the CPU, the slower and larger the speed.
Then there is the memory, and behind the memory is the hard disk.
The access speed is as follows:
- L1 access speed: 4 CPU clock cycles
- L2 access speed: 11 CPU clock cycles
- L3 access speed: 39 CPU clock cycles
- RAM memory access speed: 107 CPU clock cycles
Creating such a multi-level cache will introduce two important problems:
- One is the cache hit rate
- The second is the consistency of cache updates
In particular, the second problem is that under multi-core technology, it is like a distributed system, which needs to update multiple places.
For example, Intel Core i7-8700K is a 6-core CPU. L1 on each core is 64KB (32KB for data and instruction respectively), L2 is 256K, and L3 has 2MB
- Term: Cache Line
The CPU loads one piece of data at a time, which is called cache line
The Cache Line of mainstream CPUs is 64 Bytes (some CPUs use 32 and 128 Bytes), which is the minimum data unit for the CPU to retrieve data from memory.
Because the Cache Line is the smallest unit (64Bytes), first distribute the Cache to multiple Cache lines. For example, if L1 has 32KB, then 32KB/64B = 512 Cache lines.
- Cache consistency and False Sharing
If a data x is updated in the cache of CPU core 0, the value of this data x on other CPU cores will also be updated, which is the problem of cache consistency. (this is transparent to the upper level code)
Look at a program. In this program, there is an array with 16M elements, and the value of each element is random. We use this program to count how many odd numbers the entire array contains.
A total of three methods are listed in the program, and the execution time of each method is counted. The details are as follows:
#include <chrono>
#include <iostream>
#include <thread>
#include <vector>
using namespace std;
const int total_size = 16*1024*1024;
int * test_data = new int [total_size];
const int thread_num = 6;
int result[thread_num];
void thread_func_for_multi_thread(int id) {
result[id] = 0;
int chunk_size = total_size / thread_num + 1;
int start = id * chunk_size;
int end = min(start + chunk_size, total_size);
for (int i=start; i<end; i++) {
if (test_data[i] % 2) result[id] ++;
}
}
void thread_func_for_multi_thread_improved(int id) {
int count = 0;
int chunk_size = total_size / thread_num + 1;
int start = id * chunk_size;
int end = min(start + chunk_size, total_size);
for (int i=start; i<end; i++) {
if (test_data[i] % 2) count ++;
}
result[id] = count;
}
void thread_func_for_one_thread() {
int count = 0;
for (int i=0; i<total_size; i++) {
if (test_data[i] % 2) count ++;
}
cout << "One thread: count = " << count << endl;
}
void test() {
// init test_data array
for (int i=0; i<total_size; i++) test_data[i] = rand();
for (int i=0; i<thread_num; i++) result[i] = 0;
// Method-1: multithreading
vector<thread> vec_thr;
auto beg = std::chrono::system_clock::now();
for (int i=0; i<thread_num; i++) {
vec_thr.emplace_back(thread_func_for_multi_thread, i);
}
for (int i=0; i<thread_num; i++) {
vec_thr[i].join();
}
int sum = 0;
for (int i=0; i<thread_num; i++) {
sum += result[i];
}
cout << "sum = " << sum << endl;
auto end = std::chrono::system_clock::now();
auto time_cost = std::chrono::duration_cast<std::chrono::milliseconds>(end - beg).count();
cout << "Elapsed time: " << time_cost << " ms" << endl;
// Method-2: single threaded processing
beg = std::chrono::system_clock::now();
thread one_thrd(thread_func_for_one_thread);
one_thrd.join();
end = std::chrono::system_clock::now();
time_cost = std::chrono::duration_cast<std::chrono::milliseconds>(end - beg).count();
cout << "Elapsed time: " << time_cost << " ms" << endl;
// Method-3: multithreading to avoid False Sharing
vector<thread> vec_thr_2;
beg = std::chrono::system_clock::now();
for (int i=0; i<thread_num; i++) {
vec_thr_2.emplace_back(thread_func_for_multi_thread_improved, i);
}
for (int i=0; i<thread_num; i++) {
vec_thr_2[i].join();
}
sum = 0;
for (int i=0; i<thread_num; i++) {
sum += result[i];
}
cout << "Improved Multi Thread: sum = " << sum << endl;
end = std::chrono::system_clock::now();
time_cost = std::chrono::duration_cast<std::chrono::milliseconds>(end - beg).count();
cout << "Elapsed time: " << time_cost << " ms" << endl;
}
int main()
{
test();
return 0;
}
The operation results are as follows:
$g++ 2.cpp -lpthread -O3 $./a.out sum = 8387609 Elapsed time: 27 ms One thread: count = 8387609 Elapsed time: 6 ms Improved Multi Thread: sum = 8387609 Elapsed time: 1 ms
Visible from above:
Method -1 is a multi-threaded method, which takes 30ms;
Method -2 is a single thread and takes 11ms;
Method -3 is multi-threaded and takes only 2ms;
Why is the multithreading of method-1 slower than the single thread of method-2?
Because the data in the result [] array exists in the same Cache Line, and all threads will write to the Cache Line, all threads are constantly resynchronizing the Cache Line where result [] is located. Therefore, 12 threads can't run one thread. This is called False Sharing
So what is the improvement of method-3 compared with method-1?
It is to record the count value with a local variable and assign it to result[i] at the end This prevents all threads from constantly updating the same cache line.
This program is of great significance for Performance improvement in multithreaded programming. It's worth recording.
reference:
CPU Cache
(end)