CUDA is a parallel computing framework. It is used for computing acceleration. It is a product of nvidia. It is widely used in the current deep learning acceleration
In a word, cuda helps us to put operations from cpu to gpu, and gpu multithreads process operations at the same time to achieve accelerated effect
Let's start with a simple example:
#include <iostream> #include <math.h> // function to add the elements of two arrays void add(int n, float *x, float *y) { for (int i = 0; i < n; i++) y[i] = x[i] + y[i]; } int main(void) { int N = 1<<20; // 1M elements float *x = new float[N]; float *y = new float[N]; // initialize x and y arrays on the host for (int i = 0; i < N; i++) { x[i] = 1.0f; y[i] = 2.0f; } // Run kernel on 1M elements on the CPU add(N, x, y); // Check for errors (all values should be 3.0f) float maxError = 0.0f; for (int i = 0; i < N; i++) maxError = fmax(maxError, fabs(y[i]-3.0f)); std::cout << "Max error: " << maxError << std::endl; // Free memory delete [] x; delete [] y; return 0; }
This code is very simple. Add the corresponding position elements of two arrays. The array is very large, with 1 million elements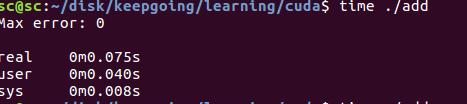
Code running time is 0.075s
Rewrite code to run on gpu
In cuda, we call it kernel. nvcc compiles it into a format that can run on GPU
#include <iostream> #include <math.h> // Kernel function to add the elements of two arrays __global__ void add(int n, float *x, float *y) { for (int i = 0; i < n; i++) y[i] = x[i] + y[i]; } int main(void) { int N = 1<<20; float *x, *y; // Allocate Unified Memory – accessible from CPU or GPU cudaMallocManaged(&x, N*sizeof(float)); cudaMallocManaged(&y, N*sizeof(float)); // initialize x and y arrays on the host for (int i = 0; i < N; i++) { x[i] = 1.0f; y[i] = 2.0f; } // Run kernel on 1M elements on the GPU add<<<1, 1>>>(N, x, y); // Wait for GPU to finish before accessing on host cudaDeviceSynchronize(); // Check for errors (all values should be 3.0f) float maxError = 0.0f; for (int i = 0; i < N; i++) maxError = fmax(maxError, fabs(y[i]-3.0f)); std::cout << "Max error: " << maxError << std::endl; // Free memory cudaFree(x); cudaFree(y); return 0; }
nvcc compiled files have a suffix of. cu
- It is OK to define kernel in cuda and add global declaration before function
- Use CUDA malloc managed to allocate memory on the display memory
- For example, 'add < < 1, 1 > > (n, x, y);' is used to call a function, and the meaning of the parameters will be explained later
- cudaDeviceSynchronize() is required to let the cpu wait for the calculation on gpu to finish before executing the operation on cpu
nvprof can be used for more detailed performance analysis
Pay attention to sudo or you may report an error sudo /usr/local/cuda/bin/nvprof ./add_cuda
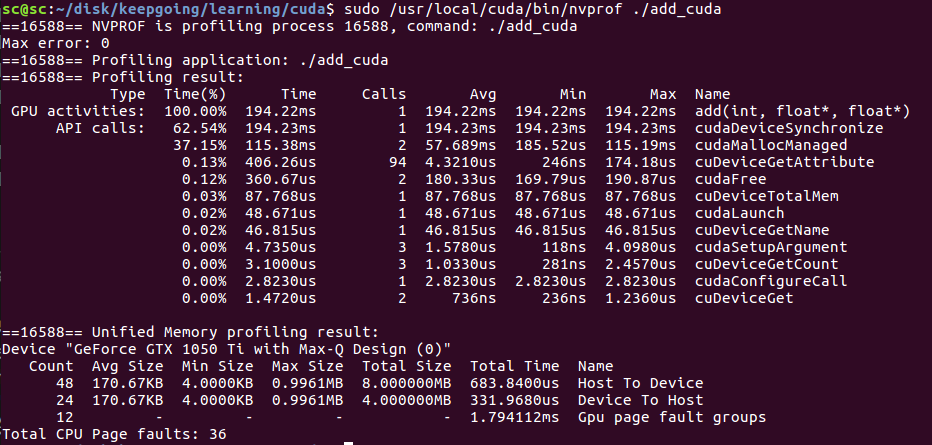
add on gpu uses 194ms
Here, we notice that running in gpu is slower than cpu, because our code 'add < < 1, 1 > > (n, x, y);' does not give full play to the advantages of gpu parallel operation, but because there are more CPUs interacting with gpu, the program slows down
Accelerating operation with GPU threads
The key is coming.
CUDA GPUS has multiple groups of streaming multiprocessors (SM). Each SM can run multiple thread blocks. Each thread block has multiple threads
As shown in the figure below: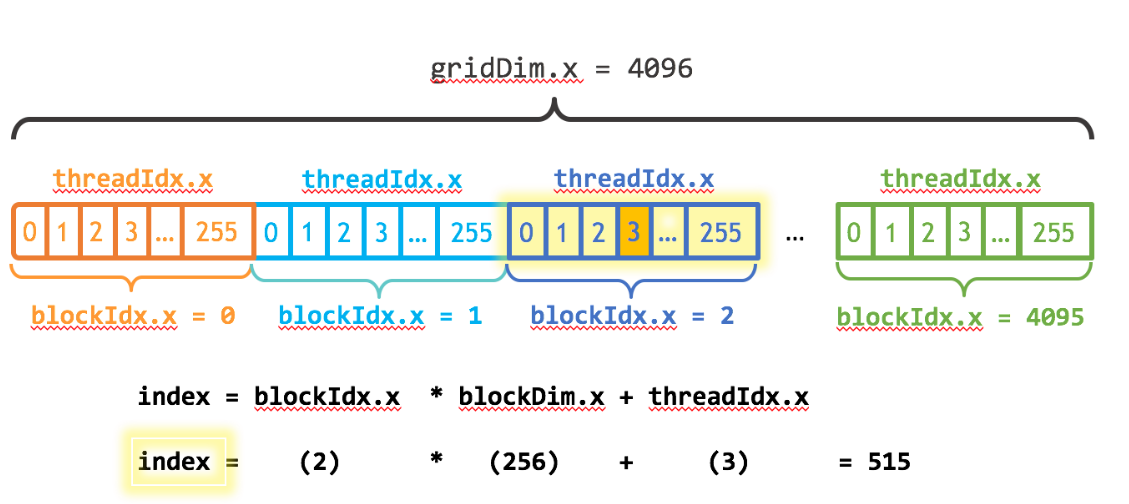
Note several key variables:
- blockDim.x shows how many threads a thread block contains
- threadIdx.x indicates the index of the current thread in the thread blcok
- blockIdx.x indicates the current thread block
All we have to do is to allocate the calculation to all threads. These threads do the operation in parallel, so as to achieve the purpose of acceleration
We mentioned earlier that the usage of calling a function (called kernel) in cuda is < < P1, P2 > >, such as' add < < 1, 1 > > (n, x, y); 'the first parameter means the number of thread block s, and the second parameter means the number of threads involved in the operation in the block
Now rewrite the code:
#include <iostream> #include <math.h> #include <stdio.h> // Kernel function to add the elements of two arrays __global__ void add(int n, float *x, float *y) { int index = threadIdx.x; int stride = blockDim.x; printf("index=%d,stride=%d\n",index,stride); for (int i = index; i < n; i+=stride) { y[i] = x[i] + y[i]; if(index == 0) { printf("i=%d,blockIdx.x=%d,thread.x=%d\n",i,blockIdx.x,threadIdx.x); } } } int main(void) { int N = 1<<20; float *x, *y; // Allocate Unified Memory – accessible from CPU or GPU cudaMallocManaged(&x, N*sizeof(float)); cudaMallocManaged(&y, N*sizeof(float)); // initialize x and y arrays on the host for (int i = 0; i < N; i++) { x[i] = 1.0f; y[i] = 2.0f; } // Run kernel on 1M elements on the GPU add<<<1, 256>>>(N, x, y); // Wait for GPU to finish before accessing on host cudaDeviceSynchronize(); // Check for errors (all values should be 3.0f) float maxError = 0.0f; for (int i = 0; i < N; i++) maxError = fmax(maxError, fabs(y[i]-3.0f)); std::cout << "Max error: " << maxError << std::endl; // Free memory cudaFree(x); cudaFree(y); return 0; }
Note the writing method of add. We put 0256512... Into thread1 calculation, 1257... Into thread2 calculation, and so on. When calling, add < < 1, 256 > > (n, x, y); it shows that we only allocate the calculation to 256 threads in thread block1
Compile this program (note that the printf in the code should be commented out, because the running time of the program should be counted): nvcc add ﹣ block.cu - O add ﹣ CUDA ﹣ blcok - I / usr / local / cuda-9.0/include/ - L / usr / local / cuda-9.0/lib64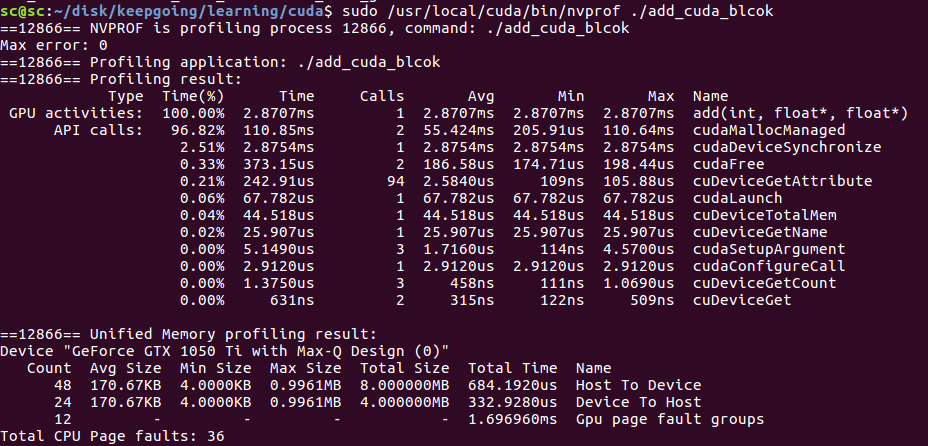
It can be seen that the gpu time of add is only 2.87ms
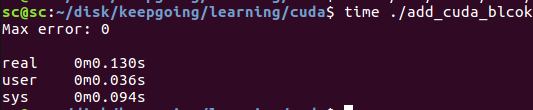
The overall running time of the program is 0.13s, mainly because CUDA malloc managed, CUDA device synchronize and other operations take a lot of time
Rewrite the code again
This time we use more thread block s
int blockSize = 256; int numBlocks = (N + blockSize - 1) / blockSize; add<<<numBlocks, blockSize>>>(N, x, y);
// Kernel function to add the elements of two arrays __global__ void add(int n, float *x, float *y) { int index = blockIdx.x * blockDim.x + threadIdx.x; int stride = blockDim.x * gridDim.x; for (int i = index; i < n; i+=stride) { y[i] = x[i] + y[i]; //printf("i=%d,blockIdx.x=%d\n",i,blockIdx.x); } }
Compiled by: nvcc add ABCD grid.cu - O add ABCD grid - I / usr / local / cuda-9.0/include/ - L / usr / local / cuda-9.0/lib64
Statistical performance: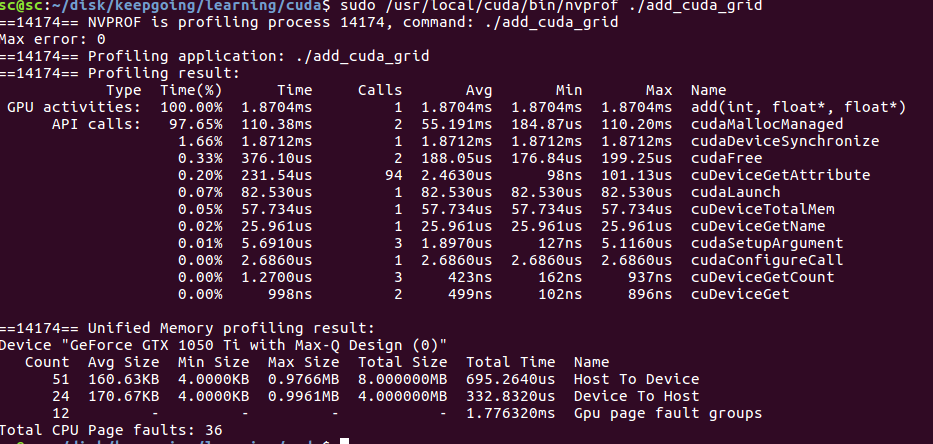
It can be seen that the time of add on gpu is further reduced to 1.8ms
Reference resources: https://devblogs.nvidia.com/even-easier-introduction-cuda/