1, Download and install ElaticSearch
1. ElaticSearch download address
https://www.elastic.co/cn/downloads/elasticsearch
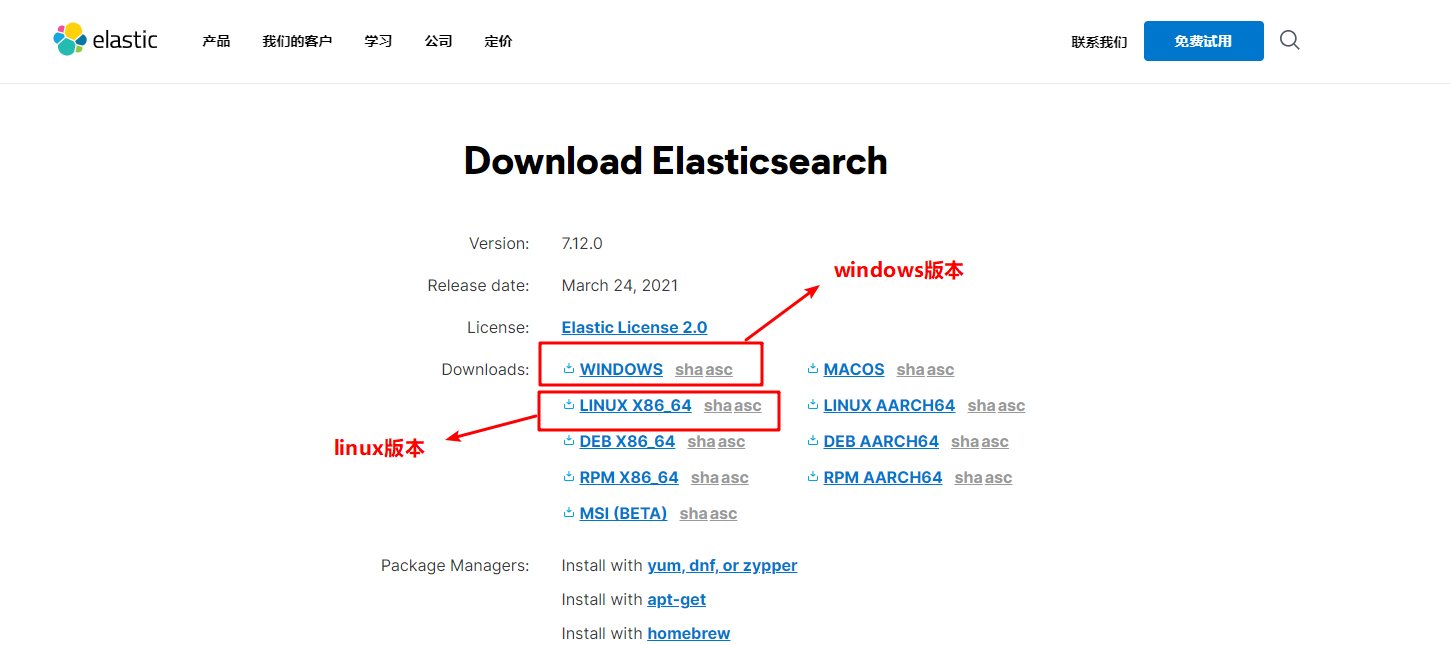
2. Installation method of windows version
Unzip for immediate use. The directory structure after unzip is as follows:

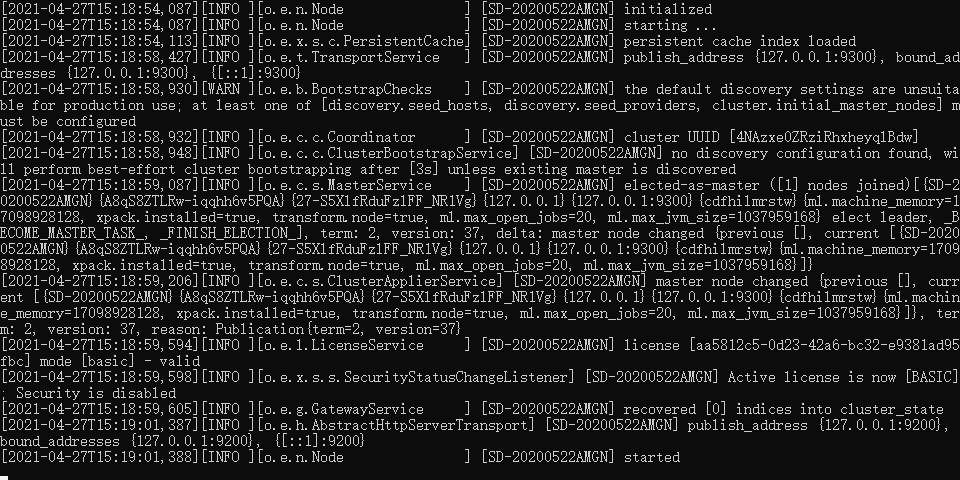
3. Start ElasticSearch
Enter the bin directory and click elastic search Bat file

4. Solve cross domain access problems
Enter the config folder and open elaticsearch YML file, add the following two configurations.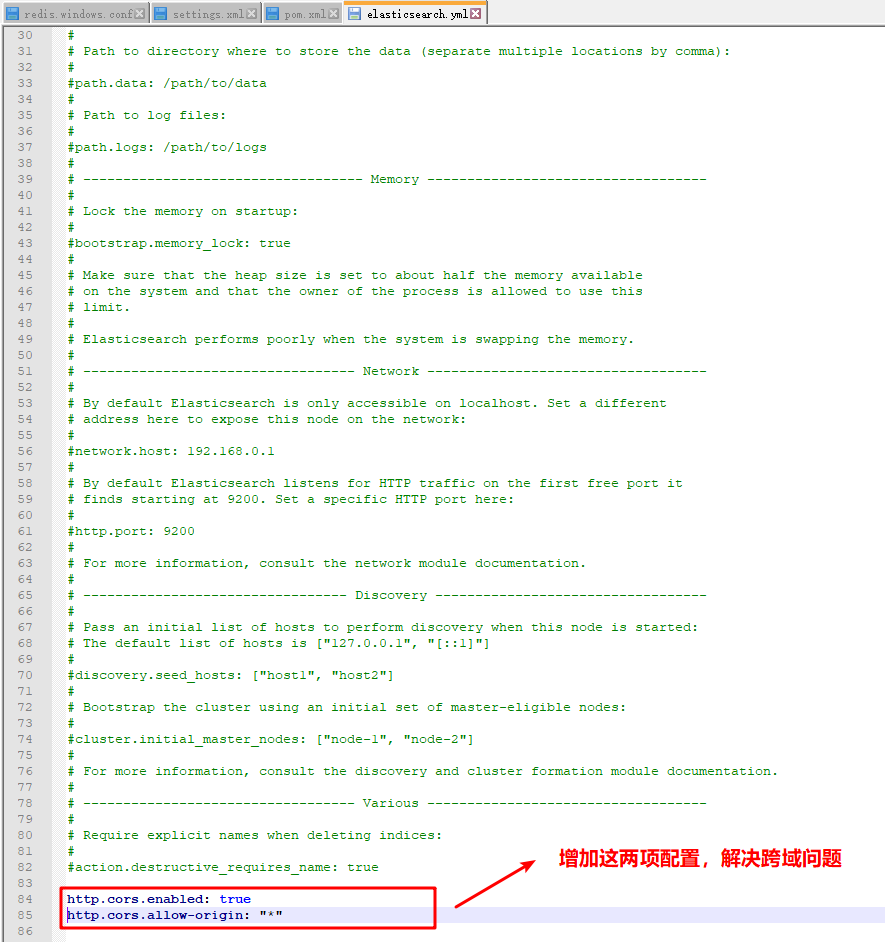
2, Download and install elasticsearch head visualization plug-in
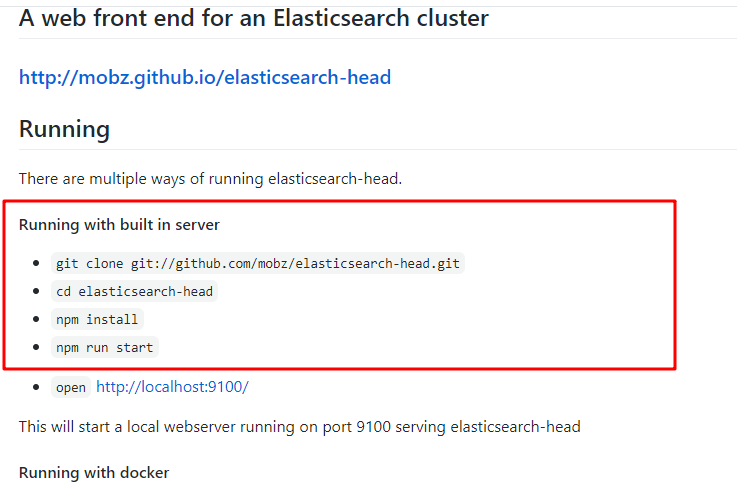
1. Download and install elaticsearch head
Download address: https://github.com/mobz/elasticsearch-head
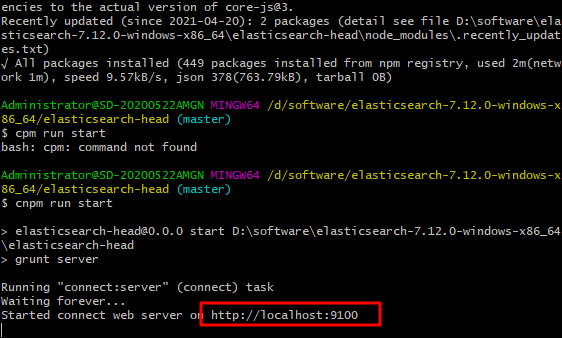
2. Enter the visualization interface
Address: http://localhost:9100/
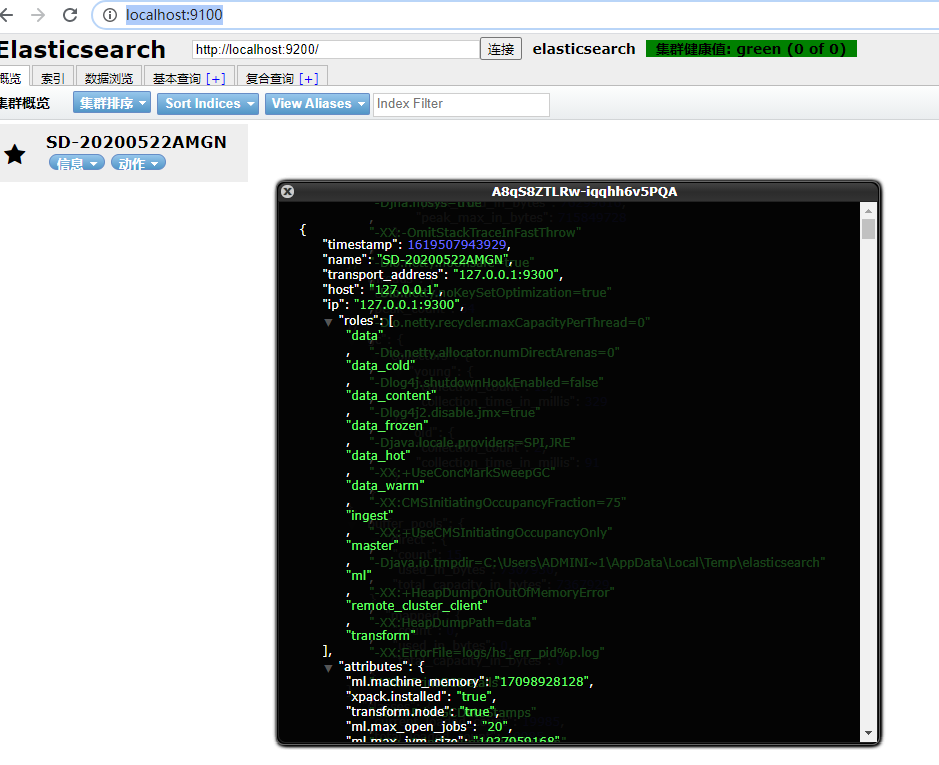
Connect elasticsearch after login: http://localhost:9200/
3, Download and install kibana
1. Download and install
Download address: https://www.elastic.co/cn/downloads/kibana
Unzip it and you can use it. Click kibana.com in the bin directory Bat start
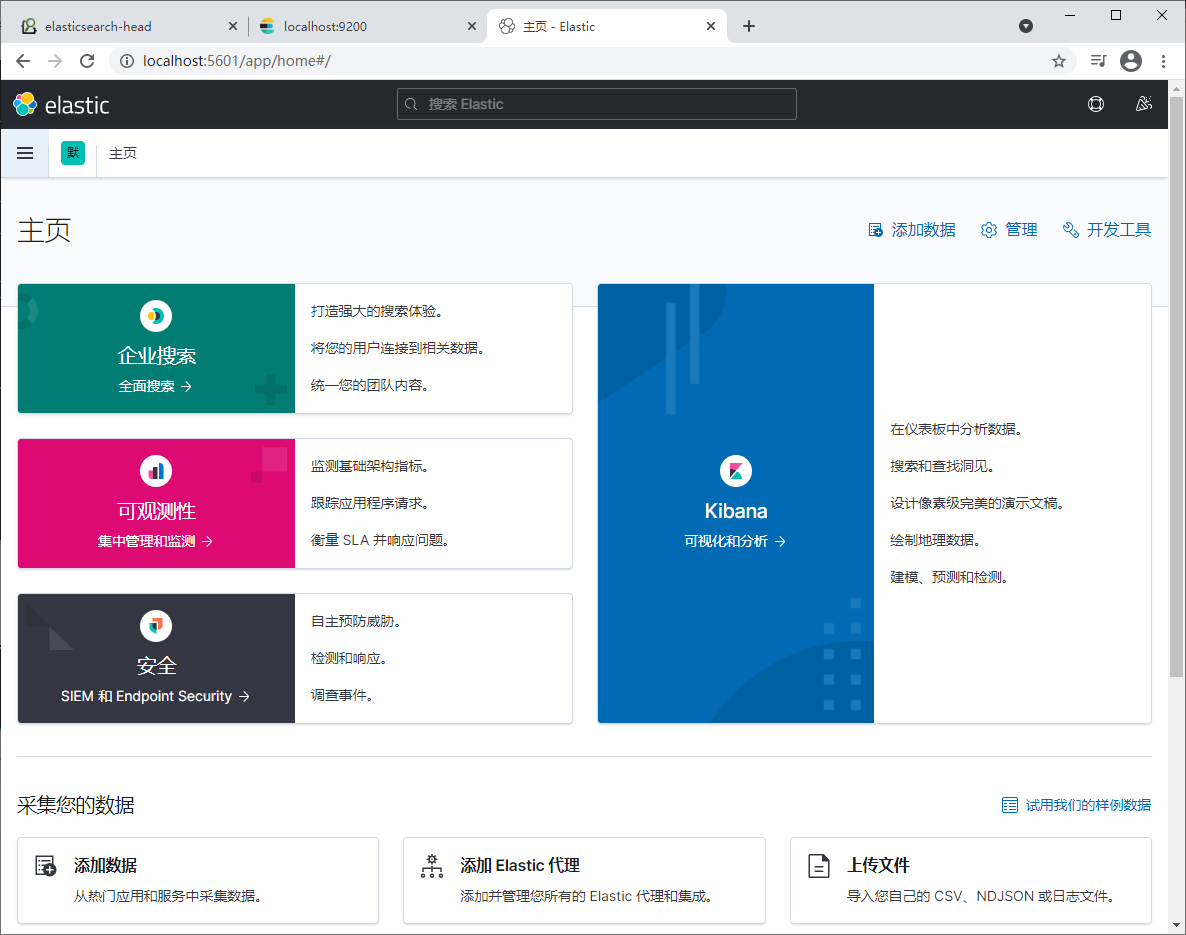
2. Enter the visual interface
Address: http://localhost:5601
4, IK word breaker plug-in
1. Install IK word breaker
Download address: https://github.com/medcl/elasticsearch-analysis-ik
After downloading, unzip it and put it in the plugins folder under the elasticsearch directory. As shown below:
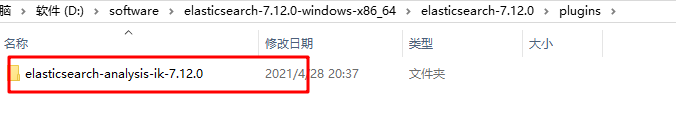
2. Use IK word breaker
IK provides two word segmentation algorithms: ik_smart and ik_max_word, where ik_smart is the least segmentation, ik_max_word is the most fine-grained division!
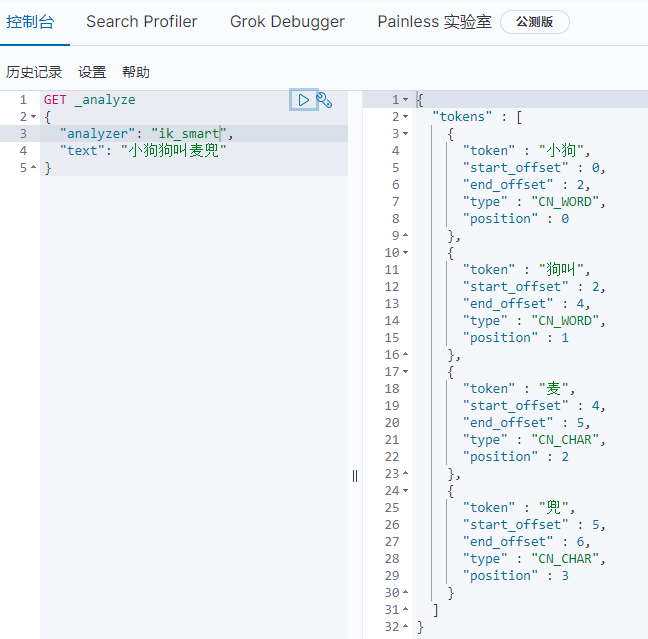
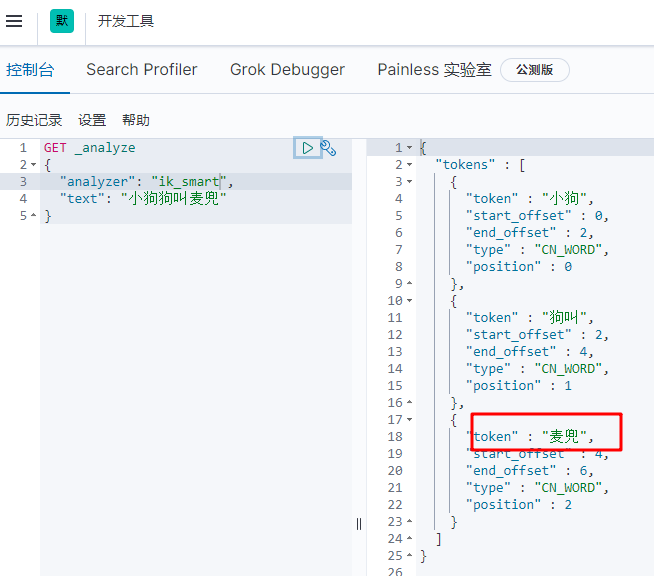
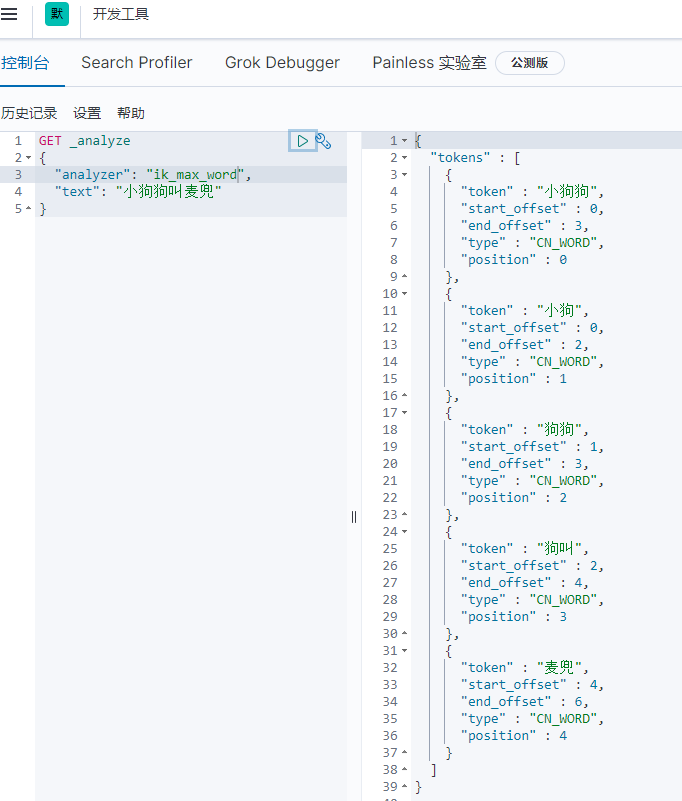
Split the "little dog's name is McDull"
ik_smart split results are as follows:
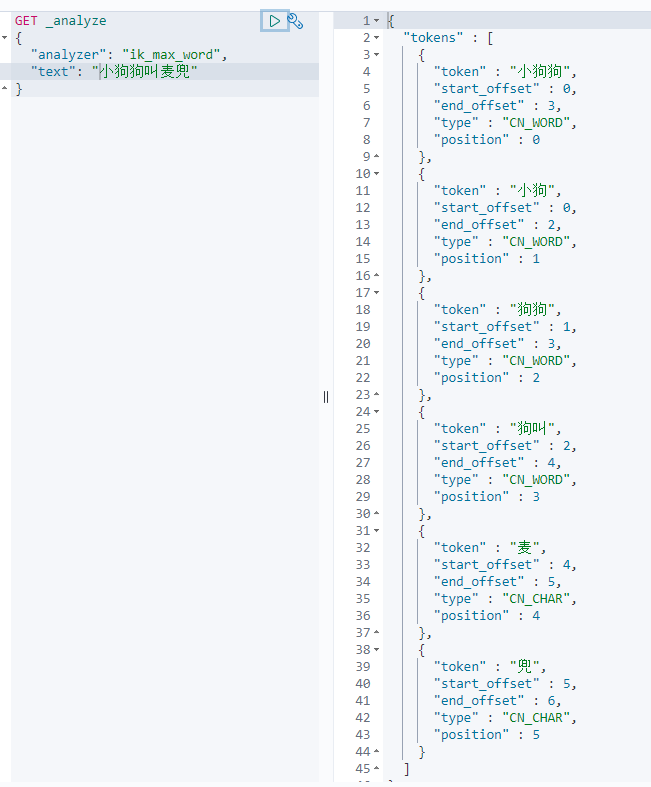
ik_ max_ The result of word splitting is as follows:
3. Create your own word segmentation dictionary
I want to combine the word "McDull" into one word when splitting. How do you do it?
Step 1: enter the config folder of the ik word splitter plug-in directory, add the dictionary "mydic.txt", and add "McDull" to the dictionary.
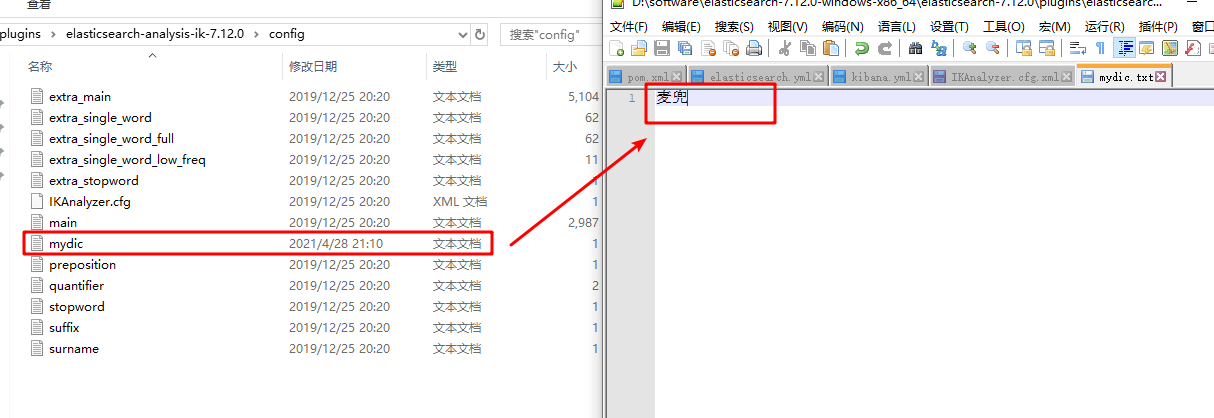
Step 2: open ikanalyzer Cfg file, add the dictionary name to the configuration file, as shown in the following figure:
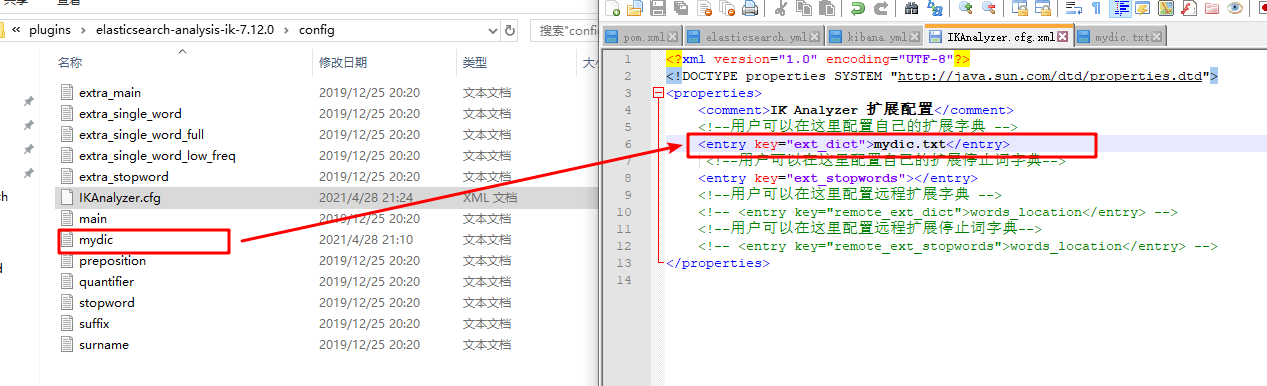
Step 3: restart elasticsearch
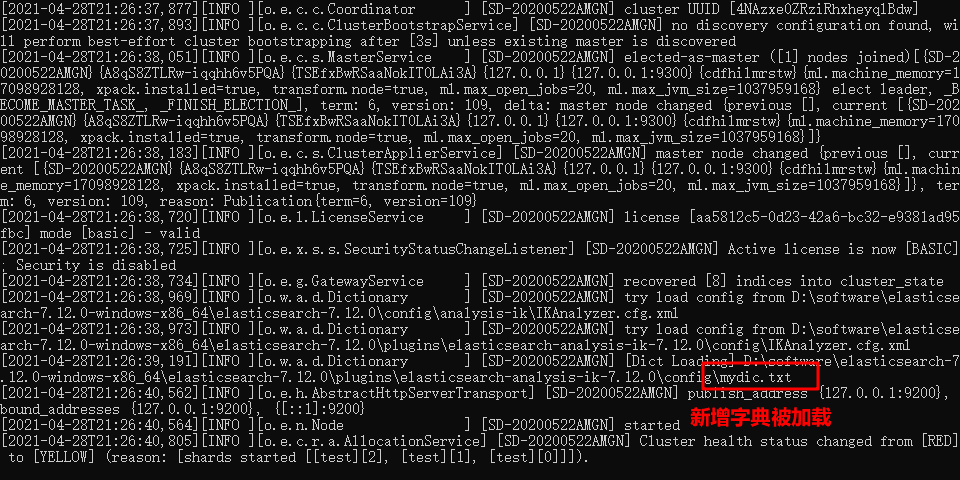
Step 4: check the effect of word segmentation
ik_smart algorithm word segmentation effect
ik_max_word segmentation effect of word algorithm
5, Restful Basic test
1. Create an index
PUT / index name / type name / document id
{request body}
Operation with kibana:
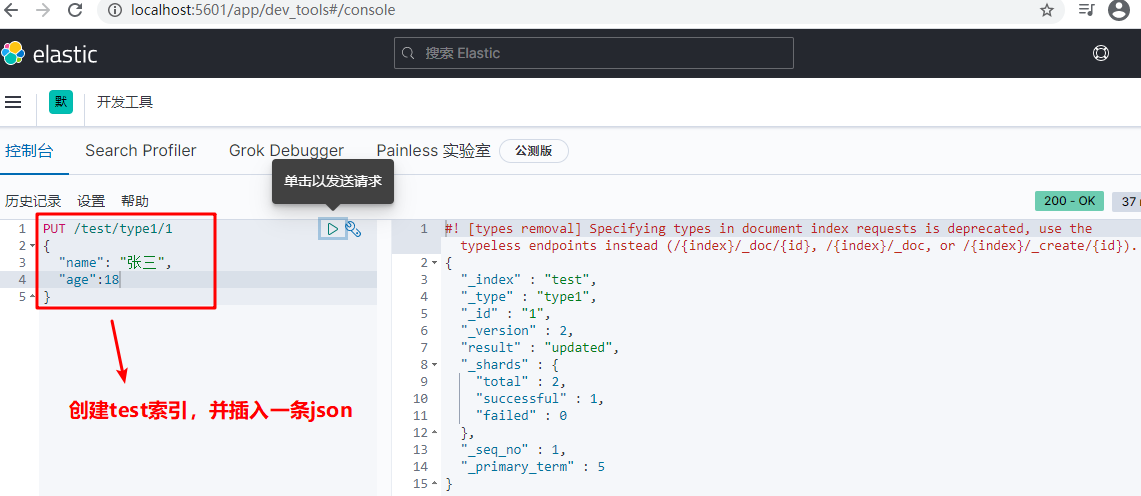
Use elasticsearch head to view:
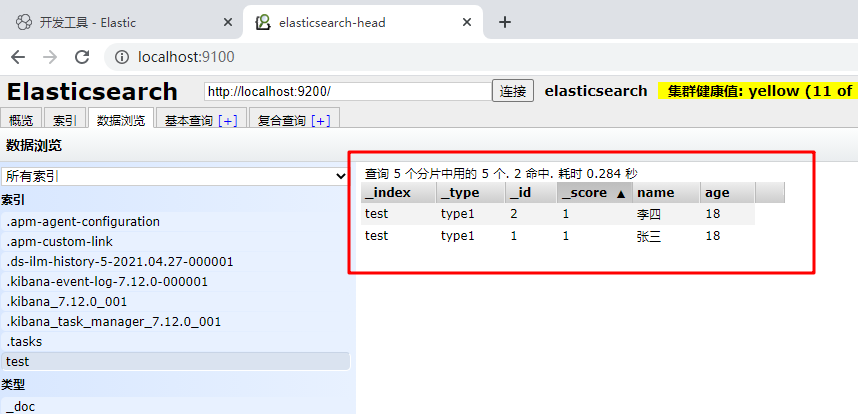
What are the elasticsearch index data types?
String type
text,keyword
value type
long,integer,short,byte,double,float,half float,scaled float
Date type
date
Boolean type
boolean
Binary type
binary
wait
Create an index for single storage and specify the field type
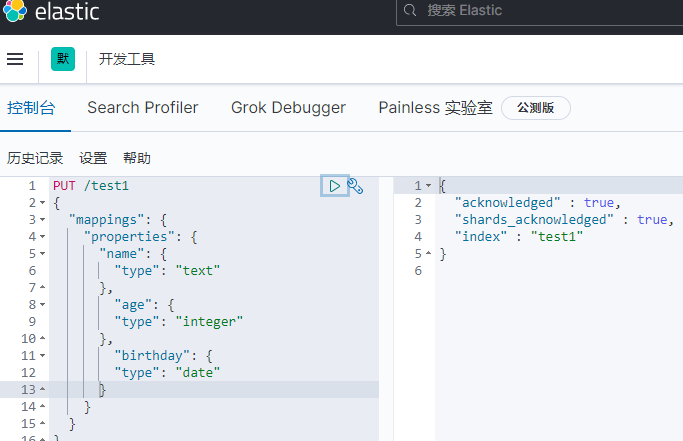
You can obtain the specific information of the index through the GET request:
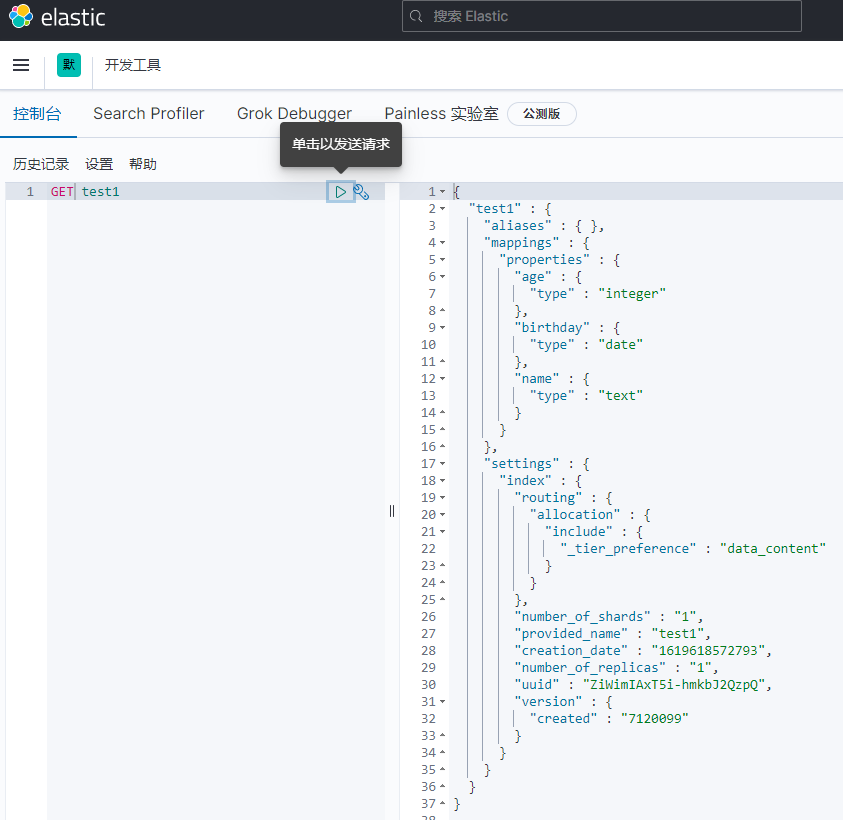
If no type is specified for the document field, es will set the type for each field by default
2. Delete index
DELETE index: DELETE index name
DELETE a single document under the index: DELETE / index name / type name / id
6, Document operation
1. Add data PUT
PUT /renyao/user/2
{
"name": "Zhang San",
"age": 18,
"desc": "Outlaw maniac",
"tags":["Travel","gambling","handsome"]
}
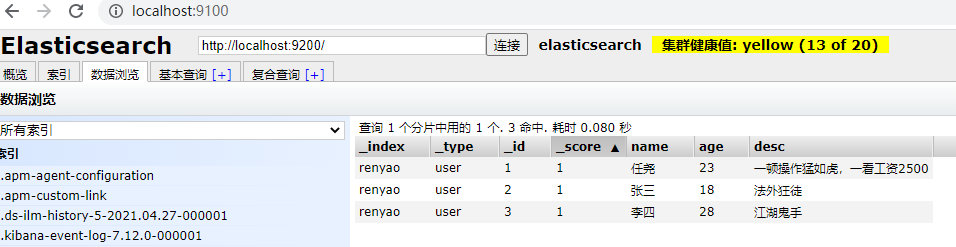
2. GET data GET
GET /renyao/user/1
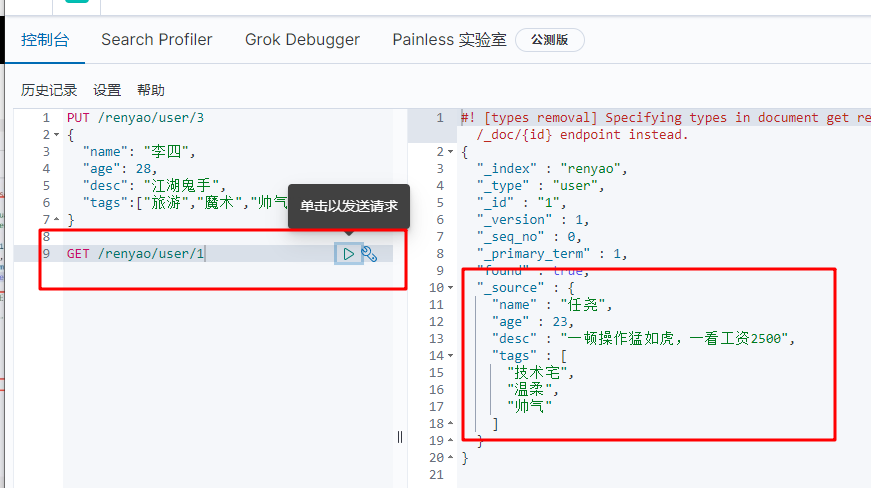
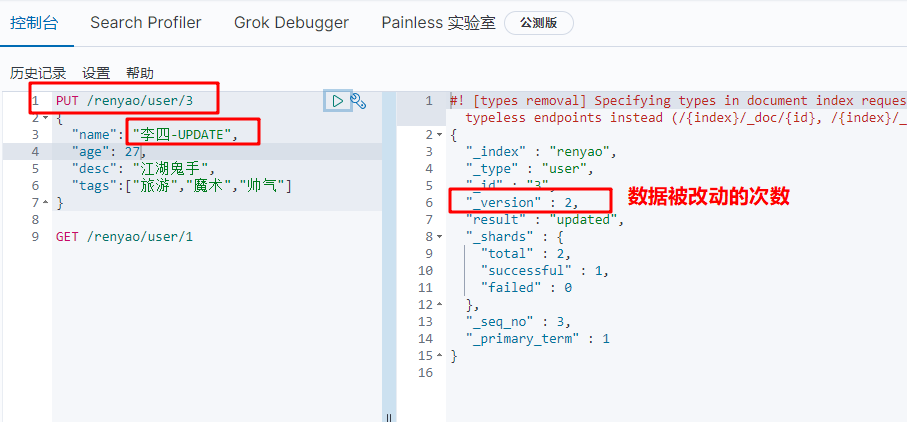
3. Update data PUT or POST
put to modify the whole data, as shown in the following figure:
POST /xxx/xxx/xxx/_update can modify a single field of a document,
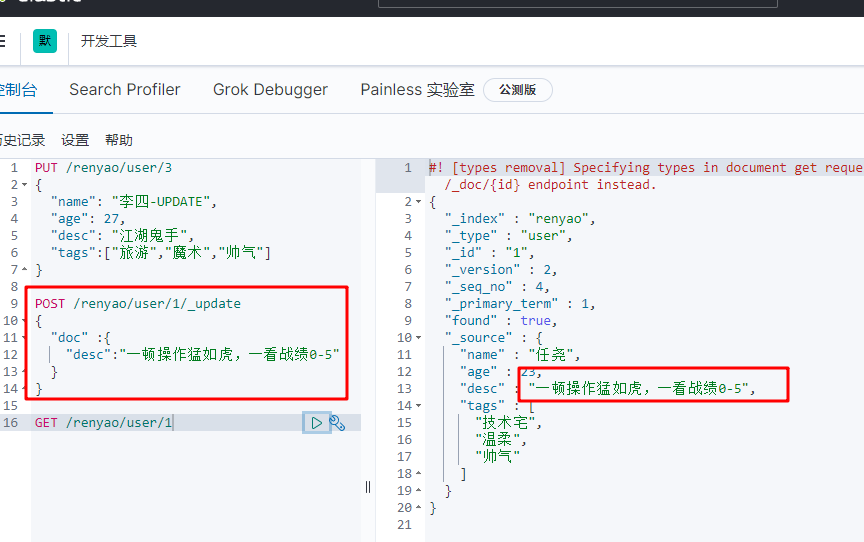
4. Query data GET search
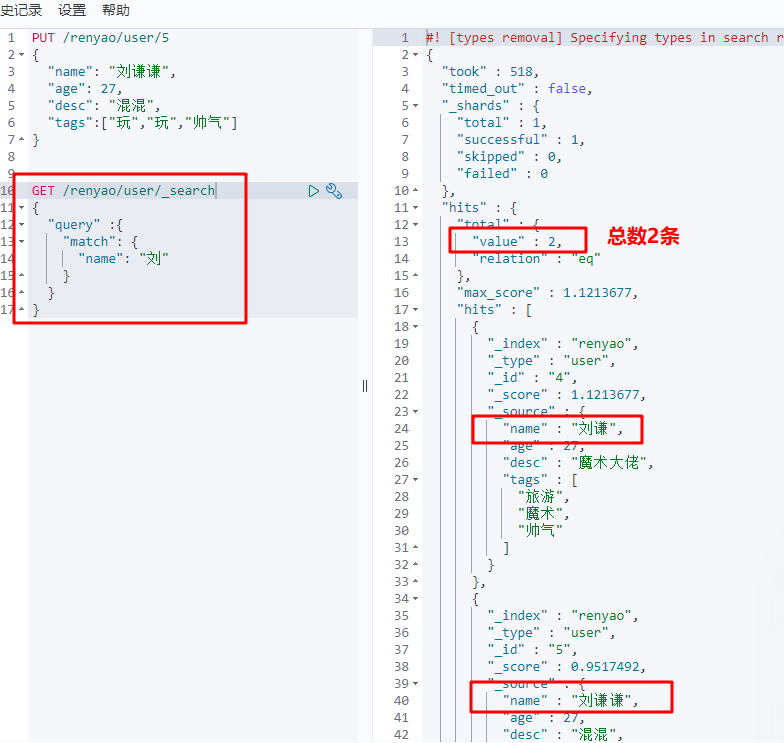
(1) Single condition query
GET / index / type/_ search?q=key:value, as shown below. Value is a fuzzy query
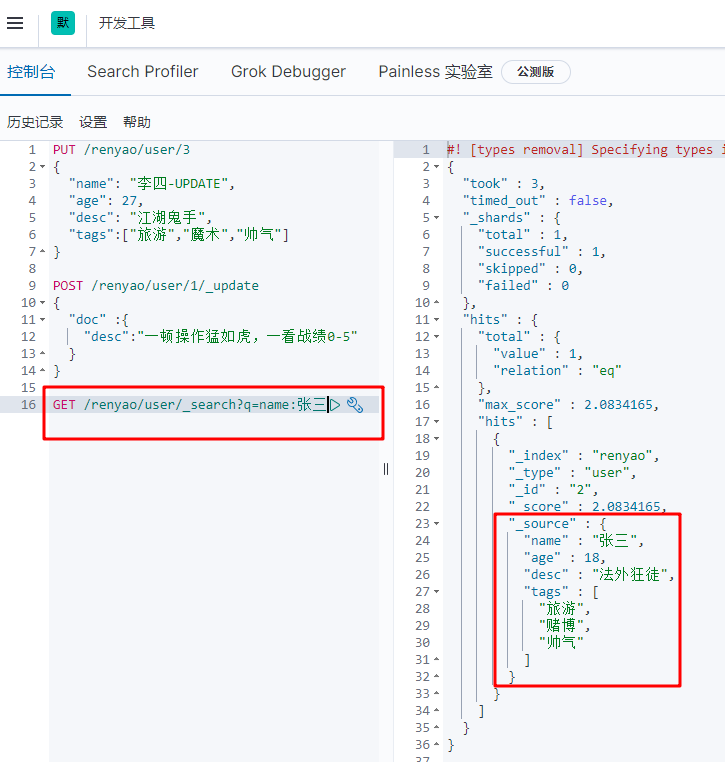
There is a score value in the query result, which is the matching degree. The larger the value, the higher the matching degree.
GET /renyao/user/_search
{
"query" :{
"match": {
"name": "Liu"
}
}
}
(2) Query result filter field
GET /renyao/user/_search
{
"query" :{
"match": {
"name": "Liu"
}
}
}
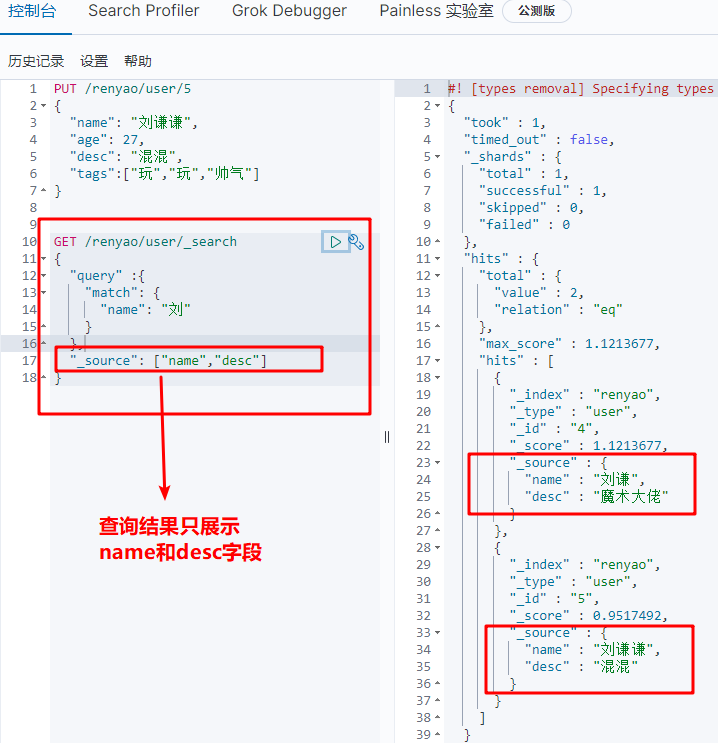
(3) Query result sorting
GET /renyao/user/_search
{
"query" :{
"match": {
"name": "Liu"
}
},
"_source": ["name","age"],
"sort":[
{
"age" : {
"order": "asc"
}
}
]
}
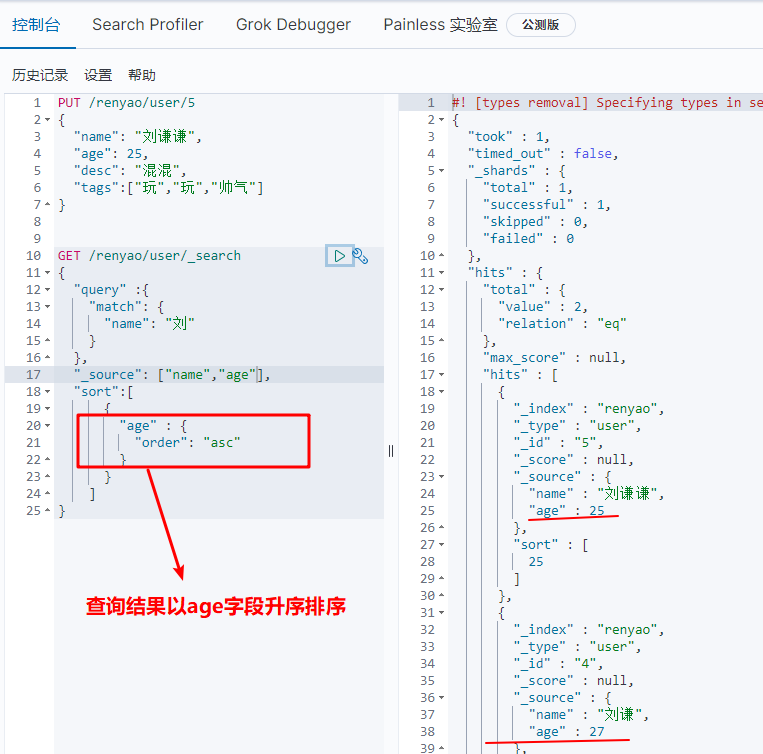
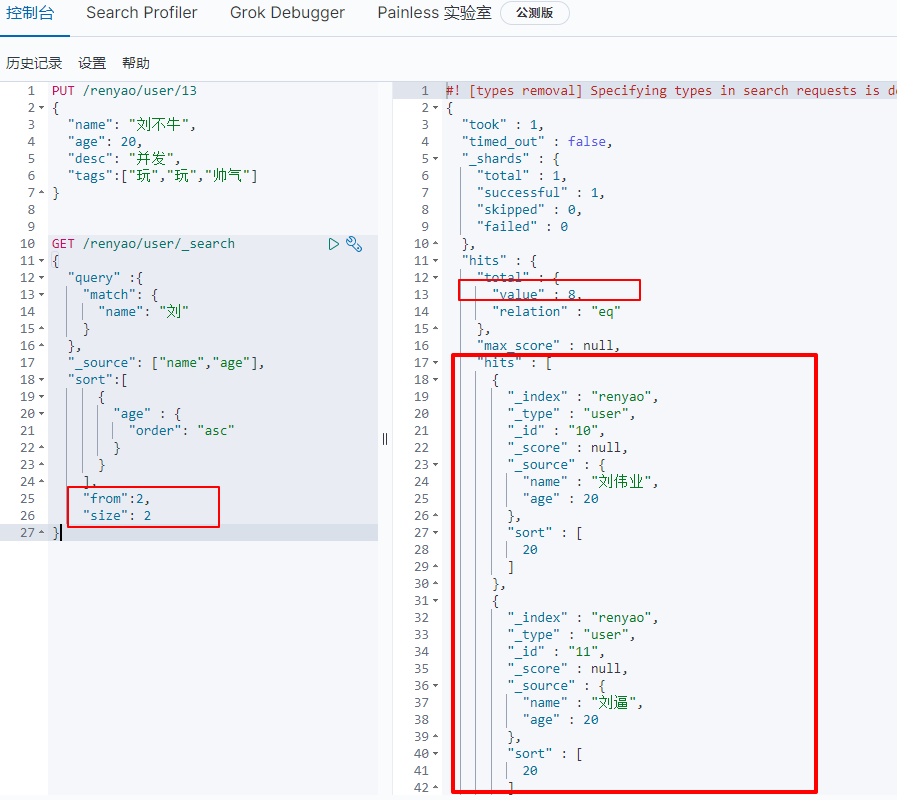
(4) Query result limit
GET /renyao/user/_search
{
"query" :{
"match": {
"name": "Liu"
}
},
"_source": ["name","age"],
"sort":[
{
"age" : {
"order": "asc"
}
}
],
"from":2, //The result of the query starts from item 2
"size": 2 //Only two pieces of data are limited, that is, the third to fourth pieces of data in the query results
}
(5) Multi condition query
must is equivalent to (and)
should is equivalent to (or)
must_not is equivalent to (not)
GET /renyao/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "Liu"
}
},
{
"match": {
"age": 16
}
}
]
}
}
}
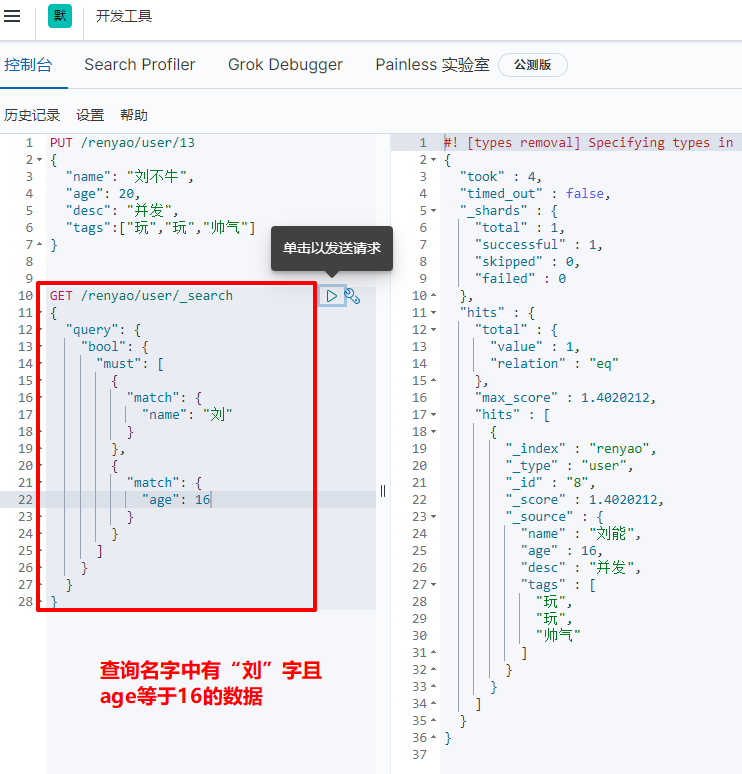
(6) Query filtering
GET /renyao/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "Liu"
}
}
],
"filter": {
"range": {
"age": {
"gt": 20
}
}
}
}
}
}
gt is greater than, lt is less than, gte is greater than or equal to, lte is less than or equal to.
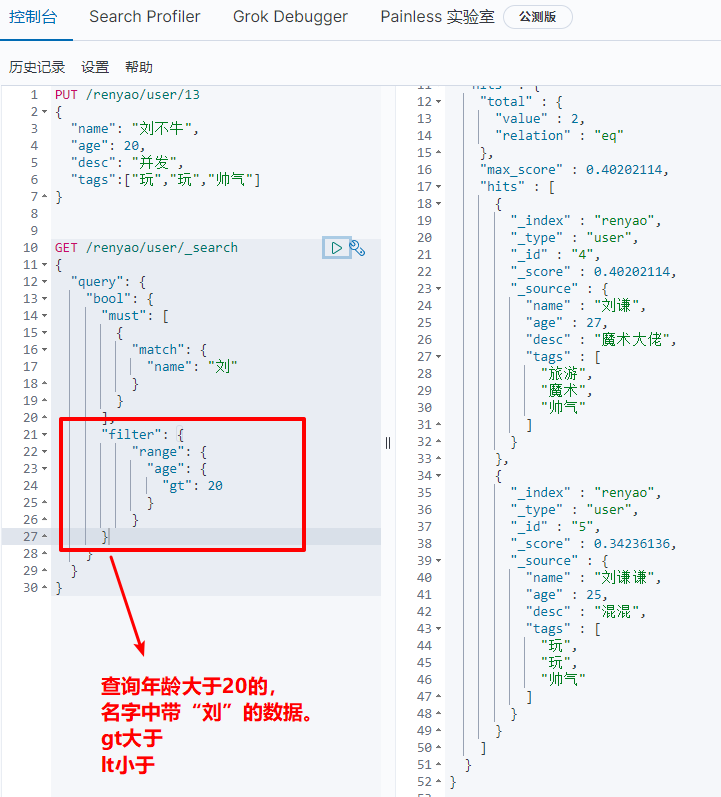
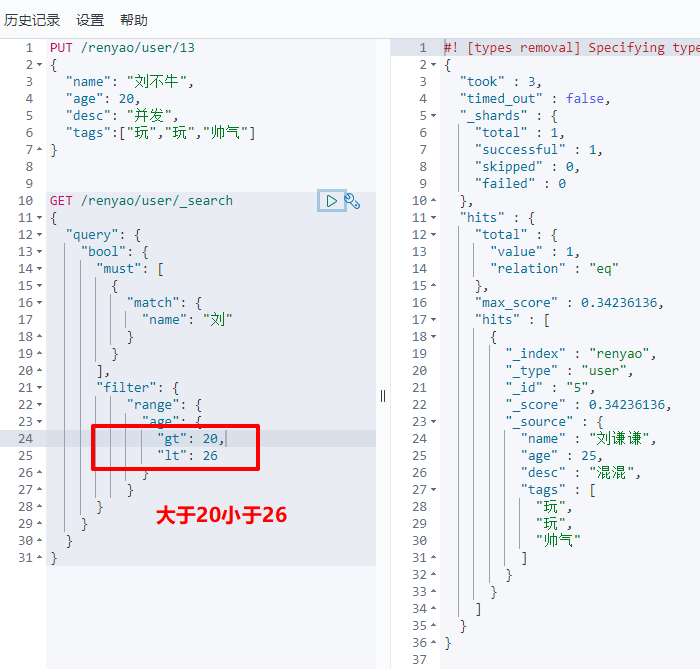
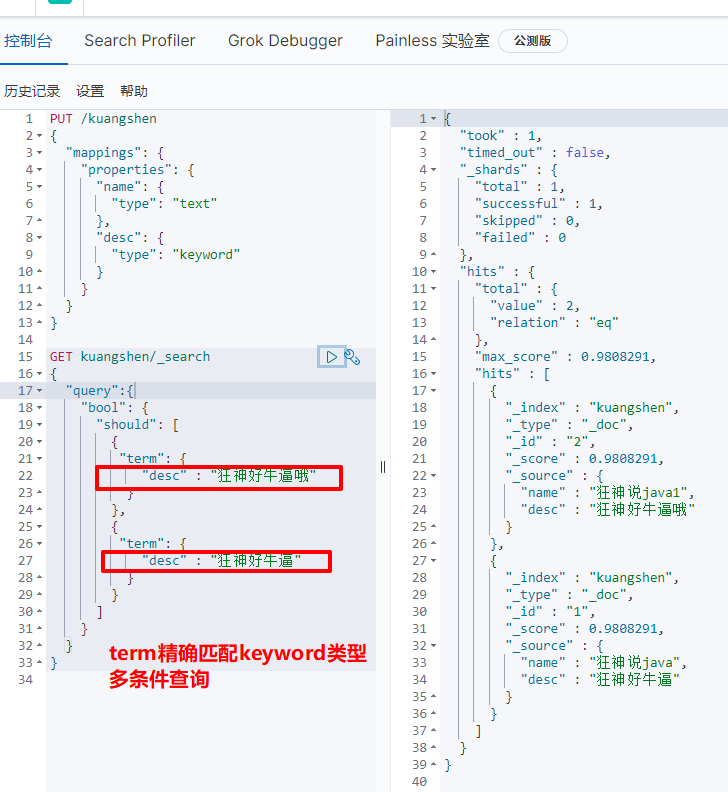
(7) Precise query
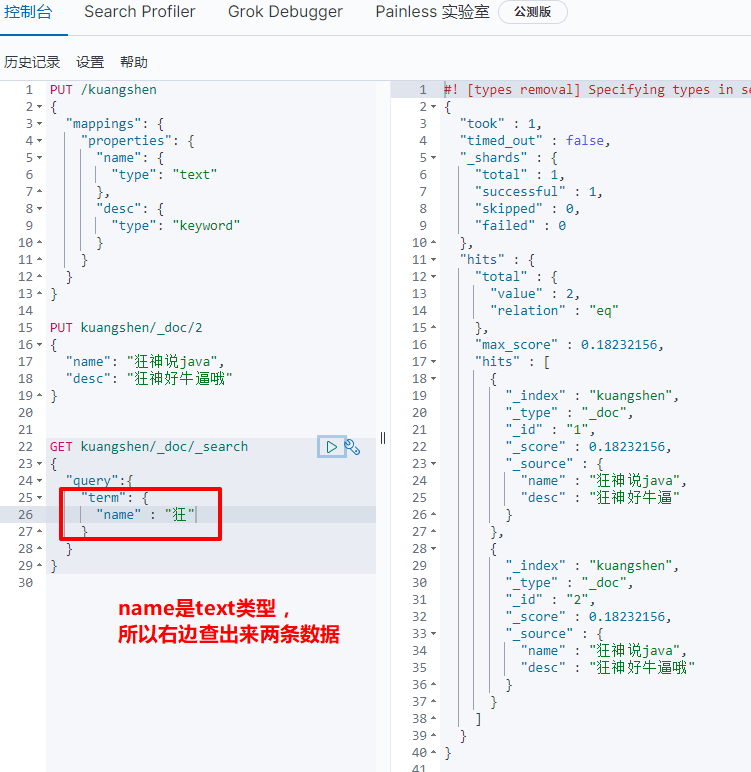
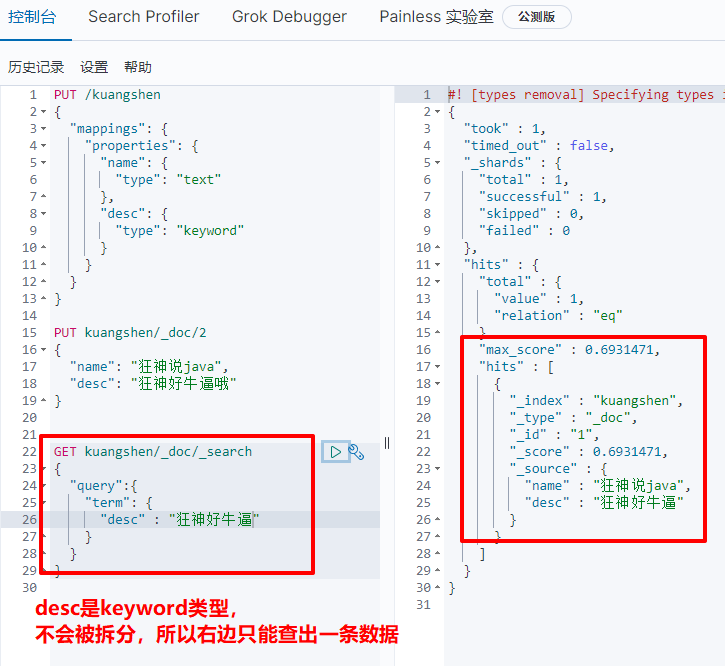
- term, exact query
- match, fuzzy query, can use word segmentation parser!
The text data type will be parsed by the word splitter, and the keyword type will not be parsed by the word splitter.
Create an index:
PUT /kuangshen
{
"mappings": {
"properties": {
"name": {
"type": "text" //Texttype field
},
"desc": {
"type": "keyword" //keyword type field
}
}
}
}
Insert two pieces of data:
term query name field (text type)
term query desc field (keyword type)
Exact matching of multiple values
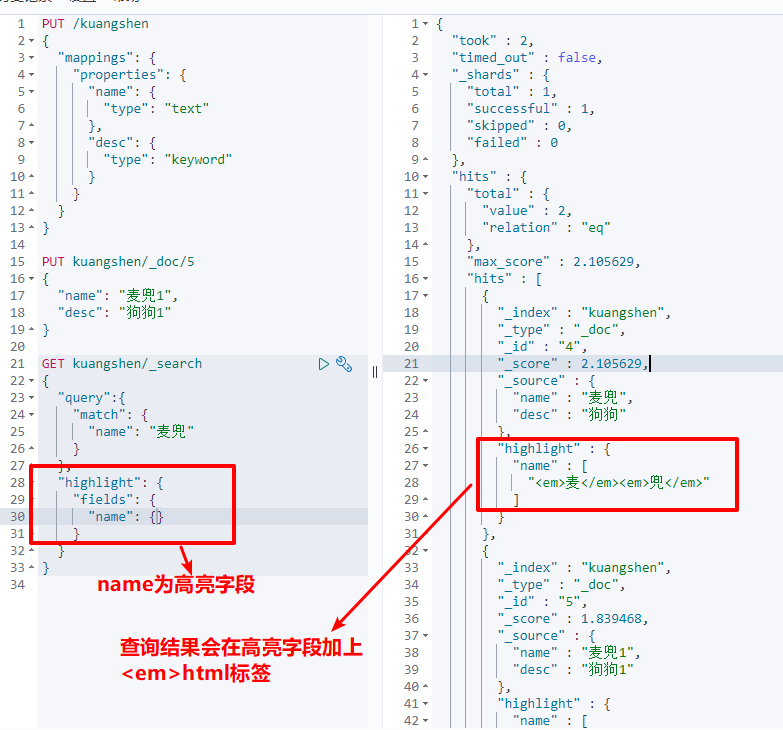
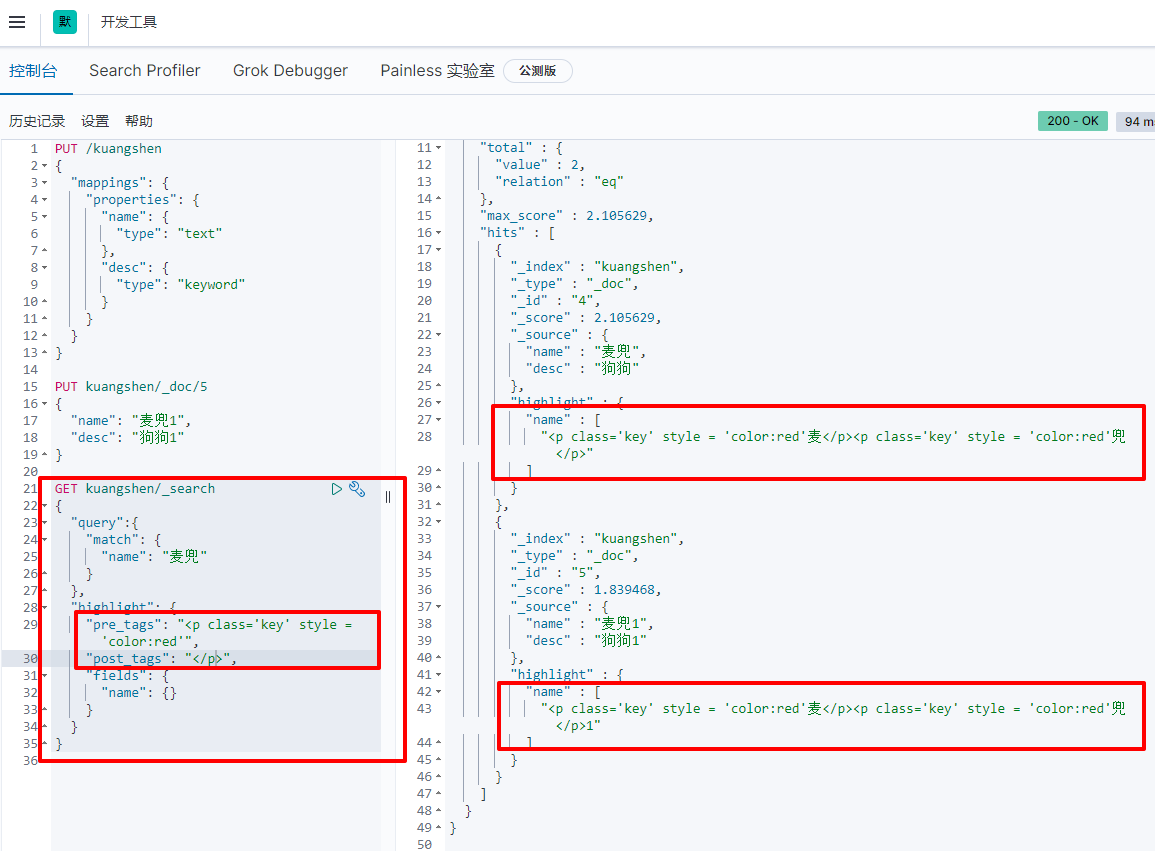
(8) Highlight query
GET kuangshen/_search
{
"query":{
"match": {
"name": "McDull"
}
},
"highlight": {
"fields": {
"name": {}
}
}
}
You can customize the highlighted label:
GET kuangshen/_search
{
"query":{
"match": {
"name": "McDull"
}
},
"highlight": {
"pre_tags": "<p class='key' style = 'color:red'", //Highlight label prefix
"post_tags": "</p>", //Highlight label suffix
"fields": {
"name": {}
}
}
}
7, Combination of springboot and elasticsearch
Find Java API on official website
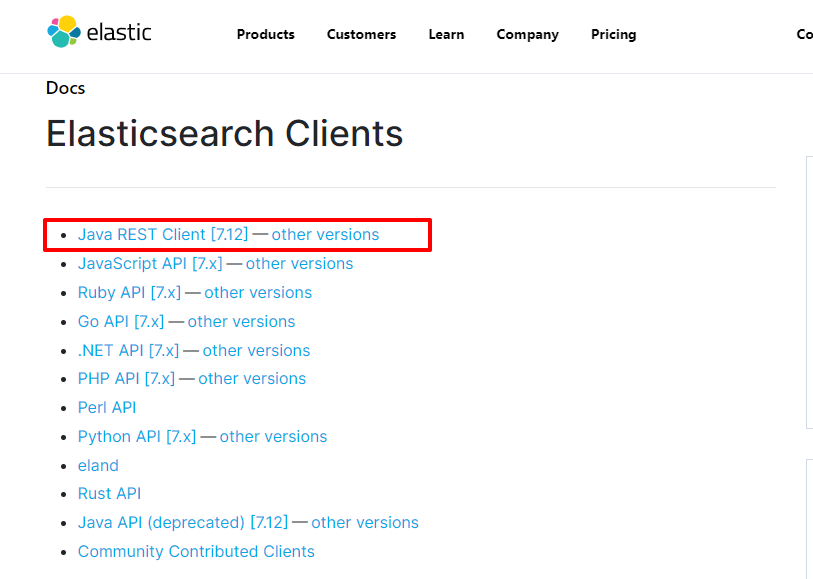
Dependency:
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>7.12.1</version>
</dependency>
Steps to integrate springboot:
1. Create configuration class
@Configuration
public class ElasticSearchClientConfig {
@Bean
public RestHighLevelClient restHighLevelClient() {
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("localhost", 9200, "http")));
return client;
}
}
2. Test API
(1) Create index
@SpringBootTest
class ElasticsearchApplicationTests {
@Autowired
private RestHighLevelClient restHighLevelClient;
@Test
void testAPI() throws IOException {
//1. Create index Request
CreateIndexRequest kuang_index = new CreateIndexRequest("kuang_index");
//2. Execute create request
CreateIndexResponse createIndexResponse = restHighLevelClient.indices().create(kuang_index, RequestOptions.DEFAULT);
}
}
(2) Get index
@Test
void testGetIndex() throws IOException {
GetIndexRequest kuang_index = new GetIndexRequest("kuang_index");
boolean exists = restHighLevelClient.indices().exists(kuang_index, RequestOptions.DEFAULT);
System.out.println(exists);
}
(3) Delete index
@Test
void testDeleteIndex() throws IOException {
DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest("kuang_index");
AcknowledgedResponse delete = restHighLevelClient.indices().delete(deleteIndexRequest, RequestOptions.DEFAULT);
System.out.println(delete.isAcknowledged());
}
(4) Add document
@Test
void testAddDoc() throws IOException {
User user = new User("javaTest1",3);
//Create request
IndexRequest indexRequest = new IndexRequest("kuang_index");
//Rule put /indexRequest/_doc/1
indexRequest.id("1");
indexRequest.timeout(TimeValue.timeValueSeconds(1));
indexRequest.timeout("1s");
//Put data
indexRequest.source(JSON.toJSONString(user), XContentType.JSON);
//client poke request
IndexResponse indexResponse = restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT);
System.out.println(indexResponse.toString());
System.out.println(indexResponse.status());
}
(5) Determine whether a document exists in the index
@Test
void testIsExistDoc() throws IOException {
GetRequest getRequest = new GetRequest("kuang_index", "1");
// Do not get returned_ source context
getRequest.fetchSourceContext(new FetchSourceContext(false));
getRequest.storedFields("_none_");
boolean exists = restHighLevelClient.exists(getRequest, RequestOptions.DEFAULT);
System.out.println(exists);
}
(6) Gets the content of a document in the index
@Test
void testGetDoc() throws IOException {
GetRequest getRequest = new GetRequest("kuang_index", "1");
GetResponse documentFields = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT);
System.out.println(documentFields.getSourceAsString());
System.out.println(documentFields);//The content returned is the same as that returned by the command
}
(7) Update the contents of a document in the index
@Test
void testUpdateDoc() throws IOException {
UpdateRequest updateRequest = new UpdateRequest("kuang_index","1");
updateRequest.timeout("1s");
User user = new User("Madness theory java",23);
updateRequest.doc(JSON.toJSONString(user),XContentType.JSON);
UpdateResponse updateResponse = restHighLevelClient.update(updateRequest, RequestOptions.DEFAULT);
System.out.println(updateResponse.status());
}
(8) Delete a document in the index
@Test
void testDeleteDoc() throws IOException {
DeleteRequest request = new DeleteRequest("kuang_index","2");
request.timeout("1s");
DeleteResponse deleteResponse = restHighLevelClient.delete(request, RequestOptions.DEFAULT);
System.out.println(deleteResponse.status());
}
(9) Query documents in index
@Test
void testSearch() throws IOException {
SearchRequest searchRequest = new SearchRequest("kuang_index");
//Build query criteria
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("name","java");
//MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("name", "java");
sourceBuilder.query(termQueryBuilder);
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
searchRequest.source(sourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
System.out.println(JSON.toJSONString(searchResponse.getHits()));
for (SearchHit hit : searchResponse.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
}