1. Start a process instance
We have now created a process definition for our business process. From such a process definition, we can create process instances. In this case, a process instance corresponds to creating and validating a single financial report for a specific month. All process instances in any month share the same process definition.
In order to be able to create process instances from a given process definition, we must first deploy the process definition. Deploying a process definition means two things:
- The process definition will be stored in the persistent data store configured for the Flowable engine. Therefore, by deploying our business process, we ensure that the engine can find the process definition after the engine is restarted.
- BPMN 2.0 process XML will be parsed into an in memory object model that can be operated through the Flowable API.
For more information about deployment, see the dedicated section of deployment.
As described in this section, deployment can take place in a number of ways. One way is through the API as follows. Note that all interactions with the Flowable engine occur through its services.
Deployment deployment = repositoryService.createDeployment()
.addClasspathResource("FinancialReportProcess.bpmn20.xml")
.deploy();
Now we can use the id to define the new process instance in the process definition (see the process element in the XML). Note that this point in the id flow terminology is referred to as critical.
ProcessInstance processInstance = runtimeService.startProcessInstanceByKey("financialReport");
This will create a process instance that will start with the start event. After initiating the event, it follows all outgoing sequential processes (in this case, only one) and the first task (writing the monthly financial report). The Flowable engine now stores a task in a persistent database. At this time, the user or group assignment attached to the task is resolved and stored in the database. It should be noted that the Flowable engine will continue to execute processing steps until it reaches the waiting state, such as user tasks. In such a waiting state, the current state of the process instance is stored in the database. It is in this state until the user decides to complete the task. At this point, the engine will continue until the new waiting state or the end of the process. If the engine restarts or crashes during this period, the state of the process is safe and secure in the database.
After the task is created, the startProcessInstanceByKey method will return because the user task activity is in a waiting state. In our scenario, the task is assigned to a group, which means that each member of the group is a candidate to perform the task.
Now we can combine them all to create a simple Java program. Create a new Eclipse project and add the Flowable JAR and dependencies to its classpath (these can be found in the libs folder of the Flowable distribution). Before we can call the Flowable service, we must first construct a method of ProcessEngine to let us access the service. Here, we use the "standalone" configuration, which builds a database that is also used in the process engine demo setup.
You can download the process definition XML here. This file contains the XML shown above, but also contains the necessary BPMN diagram exchange information to visualize the process in the Flowable tool.
public static void main(String[] args) {
// Create Flowable process engine
ProcessEngine processEngine = ProcessEngineConfiguration
.createStandaloneProcessEngineConfiguration()
.buildProcessEngine();
// Get Flowable services
RepositoryService repositoryService = processEngine.getRepositoryService();
RuntimeService runtimeService = processEngine.getRuntimeService();
// Deploy the process definition
repositoryService.createDeployment()
.addClasspathResource("FinancialReportProcess.bpmn20.xml")
.deploy();
// Start a process instance
runtimeService.startProcessInstanceByKey("financialReport");
}
2. Task list
We can now retrieve the task by adding the following logic to the TaskService:
List<Task> tasks = taskService.createTaskQuery().taskCandidateUser("kermit").list();
Please note that the user we pass to this operation needs to be a member of the accounting group, as stated in the process definition:
<potentialOwner> <resourceAssignmentExpression> <formalExpression>accountancy</formalExpression> </resourceAssignmentExpression> </potentialOwner>
We can also use the task query API to get the same results using the name of the group. We can now add the following logic to our code:
TaskService taskService = processEngine.getTaskService();
List<Task> tasks = taskService.createTaskQuery().taskCandidateGroup("accountancy").list();
Just as we have configured the same database that our process engine uses for demonstration settings, we can now log in to the Flowable IDM. Log in as admin / test, create two new users kermit and fozzie, and give them two permissions to access the workflow application. Then create two new organization groups named accounting and management, add fozzie to the new accounting group, and add kermit to the management group. Now log in to the Flowable task application with fozzie, and we will find that we can start our business process processing by selecting the task application, then selecting the process page and selecting "monthly financial report".
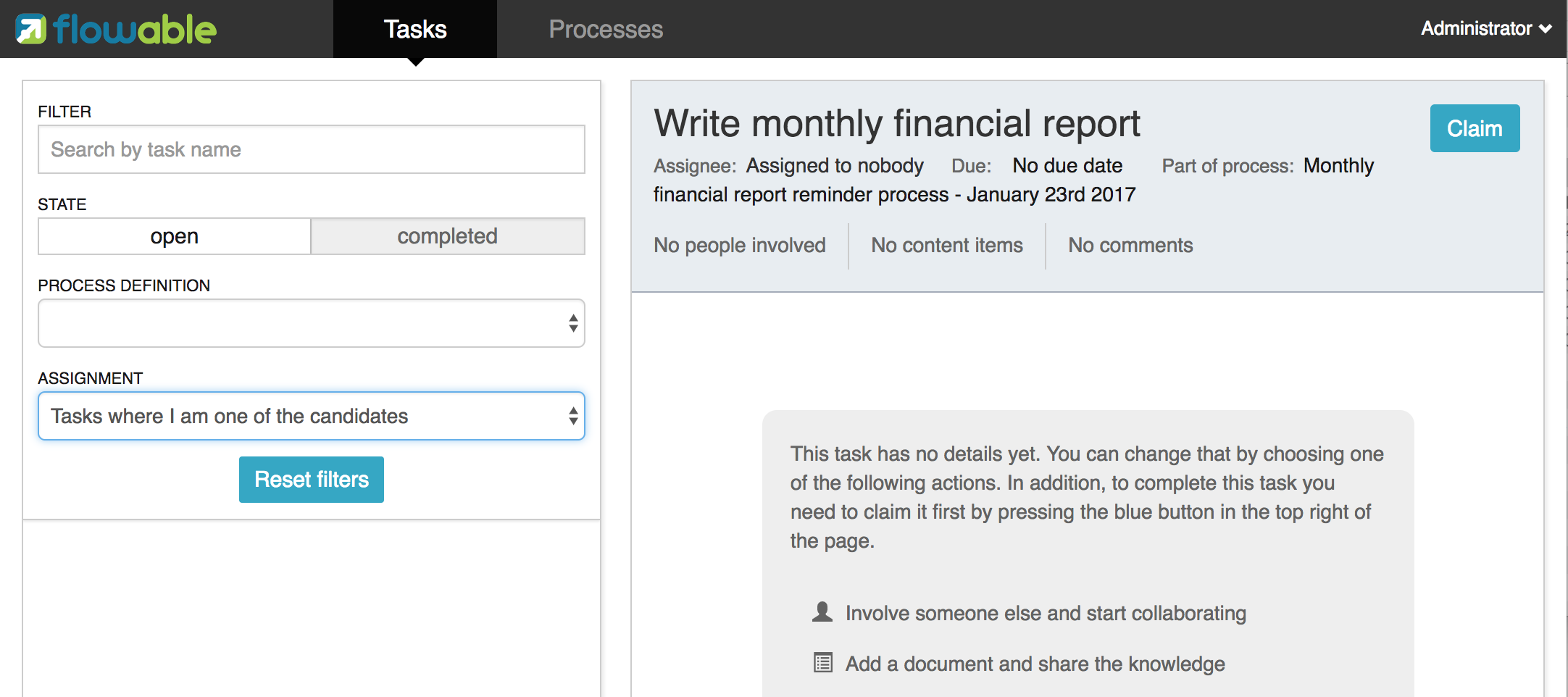
 This process will be performed until the first user task is reached. When we log in as fozzie, we can see that a new candidate task is available for him after starting the process instance. Select the task page to view this new task. Note that even if the process is started by someone else, the task is still visible to everyone in the accounting group as a candidate task.
This process will be performed until the first user task is reached. When we log in as fozzie, we can see that a new candidate task is available for him after starting the process instance. Select the task page to view this new task. Note that even if the process is started by someone else, the task is still visible to everyone in the accounting group as a candidate task.
The above article is from Pangu BPM Research Institute: http://vue.pangubpm.com/
Article translation submission: https://github.com/qiudaoke/flowable-userguide
For more articles, you can focus on WeChat official account:
