Recently, I want to find a few e-books to see, turn around, and then, I found a website called Weekly Reading. The website is very good, simple and refreshing, there are many books, and open all Baidu disks can be downloaded directly, update speed is also OK, so I climbed. This article can be learned, such a good sharing website, try not to climb, affect the speed of access is not good http://www.ireadweek.com/, want data, you can comment below my blog, I send you, QQ, mailbox, whatever.

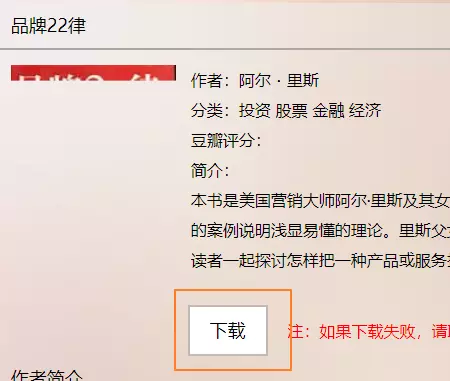
This website page logic is very simple, I flipped through the book details page, which is like the following, we just need to cycle to generate links to these pages, and then to climb, in order to speed, I used multi-threading, you can try, want to crawl after the data, just under this blog. Face-to-face comments, don't spoil other people's servers.
http://www.ireadweek.com/index.php/bookInfo/11393.html http://www.ireadweek.com/index.php/bookInfo/11.html ....
Multi-threaded crawling of e-books on the line-line-net-the code of __________
Code is very simple, with our previous tutorials as the foundation, very few code can achieve the complete function, and finally the collected content is written into the CSV file, (csv is what, you know Baidu once) this code is IO-intensive operation, we use aiohttp module to write.
Step 1
Splice the URL and open the thread.
import requests
# Import the Cooperative Module
import asyncio
import aiohttp
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36",
"Host": "www.ireadweek.com",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8"}
async def get_content(url):
print("Operating:{}".format(url))
# Create a session to get data
async with aiohttp.ClientSession() as session:
async with session.get(url,headers=headers,timeout=3) as res:
if res.status == 200:
source = await res.text() # Waiting to get text
print(source)
if __name__ == '__main__':
url_format = "http://www.ireadweek.com/index.php/bookInfo/{}.html"
full_urllist = [url_format.format(i) for i in range(1,11394)] # 11394
loop = asyncio.get_event_loop()
tasks = [get_content(url) for url in full_urllist]
results = loop.run_until_complete(asyncio.wait(tasks))
The above code can open N threads synchronously, but this can easily cause other people's servers to paralyse, so we must limit the number of concurrent times, the following code, you try to put it in the designated location.
sema = asyncio.Semaphore(5)
# To avoid crawlers having too many one-time requests, control them.
async def x_get_source(url):
with(await sema):
await get_content(url)
Step 2
Processing the source code of the captured web page and extracting the elements we want, I added a new method, using lxml for data extraction.
def async_content(tree):
title = tree.xpath("//div[@class='hanghang-za-title']")[0].text
# If there is no information on the page, just return it directly.
if title == '':
return
else:
try:
description = tree.xpath("//div[@class='hanghang-shu-content-font']")
author = description[0].xpath("p[1]/text()")[0].replace("Authors:","") if description[0].xpath("p[1]/text()")[0] is not None else None
cate = description[0].xpath("p[2]/text()")[0].replace("Classification:","") if description[0].xpath("p[2]/text()")[0] is not None else None
douban = description[0].xpath("p[3]/text()")[0].replace("Douban score:","") if description[0].xpath("p[3]/text()")[0] is not None else None
# This part is not clear and does not record.
#des = description[0].xpath("p[5]/text()")[0] if description[0].xpath("p[5]/text()")[0] is not None else None
download = tree.xpath("//a[@class='downloads']")
except Exception as e:
print(title)
return
ls = [
title,author,cate,douban,download[0].get('href')
]
return ls
Step 3
After data formatting, save to csv file, finish work!
print(data)
with open('hang.csv', 'a+', encoding='utf-8') as fw:
writer = csv.writer(fw)
writer.writerow(data)
print("Insertion success!")
Python Resource sharing qun 784758214 ,Installation packages are included. PDF,Learning videos, here is Python The gathering place of learners, zero foundation and advanced level are all welcomed.
Multi-threaded crawl-run code for online e-books to view the results
