Introduction to python crawler (1)
Getting started with Requests Library
I Requests Library
1. Installation
Enter pip install requests on the cmd command line 🆗 Yes
Test code
#Climb Baidu home page
import requests
r= requests.get("http://www.baidu.com")
print(r.status_code)
r.encoding='utf-8'
print(r.text)
Operation results:
200
(A status code of 200 indicates successful access)
<!DOCTYPE html>
<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=http://s1. bdstatic. com/r/www/cache/bdorz/baidu. Min.css > < title > Baidu, you will know < / Title > < / head > < body link = #0000cc > < div id = wrapper > < div id = head > < div class = head_ wrapper> <div class=s_ form> <div class=s_ form_ wrapper> <div id=lg> <img hidefocus=true src=//www.baidu. com/img/bd_ logo1. png width=270 height=129> </div> <form id=form name=f action=//www.baidu. com/s class=fm> <input type=hidden name=bdorz_ come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_ bp value=1> <input type=hidden name=rsv_ idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ IPT value MaxLength = 255 autocomplete = off autofocus > < / span > < span class = "BG s_btn_wr" > < input type = submit id = Su value = Baidu class = "BG s_btn" > < / span > < / form > < / div > < div id = U1 > < a href= http://news.baidu.com name=tj_ Trnews class = mnav > News < / a > < a href= http://www.hao123.com name=tj_ trhao123 class=mnav>hao123</a> <a href= http://map.baidu.com name=tj_ TRMAP class = mnav > map < / a > < a href= http://v.baidu.com name=tj_ Trvideo class = mnav > Video < / a > < a href= http://tieba.baidu.com name=tj_ Trtieba class = mnav > Post Bar < / a > < noscript > < a href= http://www.baidu.com/bdorz/login.gif?login& ; tpl=mn& u=http%3A%2F%2Fwww. baidu. com%2f%3fbdorz_ come%3d1 name=tj_ Login class = LB > log in to < / a > < / noscript > < script > document write('<a href=" http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u= '+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ '" name="tj_ Login "class =" LB "> login < / a > '; < / script > < a href = / / www.baidu. COM / more / name = tj_briicon class = bri style =" display: block; "> more products < / a > < / div > < / div > < / div > < div id = ftcon > < div id = ftconw > < p id = LH > < a href= http://home.baidu.com >About Baidu < / a > < a href= http://ir.baidu.com >About Baidu</a> </p> <p id=cp>© 2017 Baidu < a href= http://www.baidu.com/duty/ >Must read < / a > & nbsp; before using Baidu< a href= http://jianyi.baidu.com/ Class = CP feedback > feedback < / a > & nbsp; Beijing ICP Certificate No. 030173 & nbsp< img src=//www.baidu. com/img/gs. gif> </p> </div> </div> </div> </body> </html>
2. Methods of requests Library

Various methods are actually implemented by calling the request() method
requests.get(),requests.put() and other methods are encapsulated based on the request() method
① Most commonly used: requests get()
#Get the simplest code for web pages r=requests.get(url) #Complete parameters r=requests.get(url,params=None,**Kwargs) #url: get page url link #params: additional parameters in url, dictionary or byte stream format, optional #**kwargs: 12 parameters controlling access
r=requests.get(url) constructs a Request object that requests resources from the server through the get method and url
requests.get returns a Response object containing server resources. The Response object contains all the contents returned by the crawler
·Reponse object
Properties of the Reponse object

The most commonly used properties for accessing web pages
Use requests Get() process of accessing web pages:
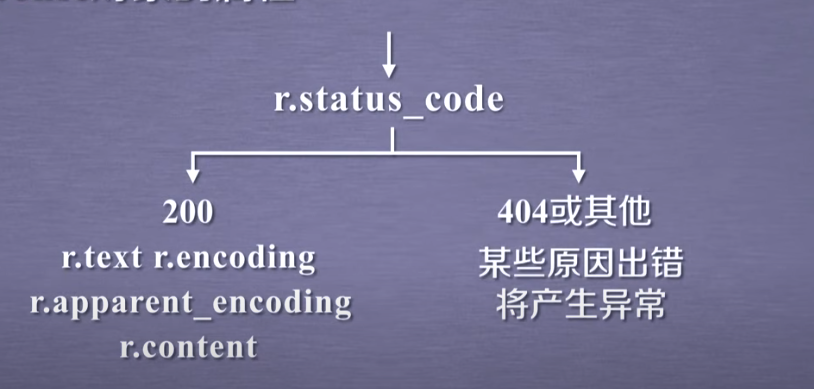
If the status code is 200, r.encoding can be used to parse the returned content
e.g.
import requests
r = requests.get("http://www.baidu.com")
print(r.status_code)
print(r.text)
Operation results:
200
<!DOCTYPE html>
<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=http://s1.bdstatic.com/r/www/cache/bdorz/baidu.min.css><title>ç™¾åº¦ä¸€ä¸‹ï¼Œä½ å°±çŸ¥é"</title></head> <body link=#0000cc> <div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form> <div class=s_form_wrapper> <div id=lg> <img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129> </div> <form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus></span><span class="bg s_btn_wr"><input type=submit id=su value=百度一下 class="bg s_btn"></span> </form> </div> </div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>æ–°é—»</a> <a href=http://www.hao123.com name=tj_trhao123 class=mnav>hao123</a> <a href=http://map.baidu.com name=tj_trmap class=mnav>地图</a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>视é¢'</a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>è´´å§</a> <noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>登录</a> </noscript> <script>document.write('<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u='+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ '" name="tj_login" class="lb">登录</a>');</script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;">更多产å"</a> </div> </div> </div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>å
³äºŽç™¾åº¦</a> <a href=http://ir.baidu.com>About Baidu</a> </p> <p id=cp>©2017 Baidu <a href=http://www.baidu.com/duty/>使ç"¨ç™¾åº¦å‰å¿
读</a> <a href=http://jianyi.baidu.com/ class=cp-feedback>æ„è§å馈</a> 京ICPè¯030173å· <img src=//www.baidu.com/img/gs.gif> </p> </div> </div> </div> </body> </html>
A pile of random code!
Now let's take a look at the coding method
print(r.encoding)
Results obtained: ISO-8859-1
print(r.apparent_encoding)
The result is utf-8
If the current code is replaced with an alternative code, then output r.text
r.encoding= 'utf-8' print(r.text)
Operation results:
<!DOCTYPE html>
<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=http://s1. bdstatic. com/r/www/cache/bdorz/baidu. Min.css > < title > Baidu, you will know < / Title > < / head > < body link = #0000cc > < div id = wrapper > < div id = head > < div class = head_ wrapper> <div class=s_ form> <div class=s_ form_ wrapper> <div id=lg> <img hidefocus=true src=//www.baidu. com/img/bd_ logo1. png width=270 height=129> </div> <form id=form name=f action=//www.baidu. com/s class=fm> <input type=hidden name=bdorz_ come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_ bp value=1> <input type=hidden name=rsv_ idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ IPT value MaxLength = 255 autocomplete = off autofocus > < / span > < span class = "BG s_btn_wr" > < input type = submit id = Su value = Baidu class = "BG s_btn" > < / span > < / form > < / div > < div id = U1 > < a href= http://news.baidu.com name=tj_ Trnews class = mnav > News < / a > < a href= http://www.hao123.com name=tj_ trhao123 class=mnav>hao123</a> <a href= http://map.baidu.com name=tj_ TRMAP class = mnav > map < / a > < a href= http://v.baidu.com name=tj_ Trvideo class = mnav > Video < / a > < a href= http://tieba.baidu.com name=tj_ Trtieba class = mnav > Post Bar < / a > < noscript > < a href= http://www.baidu.com/bdorz/login.gif?login& ; tpl=mn& u=http%3A%2F%2Fwww. baidu. com%2f%3fbdorz_ come%3d1 name=tj_ Login class = LB > login < / a > < / noscript > < script > document write('<a href=" http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u= '+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ '" name="tj_ Login "class =" LB "> login < / a > '; < / script > < a href = / / www.baidu. COM / more / name = tj_briicon class = bri style =" display: block; "> more products < / a > < / div > < / div > < / div > < div id = ftcon > < div id = ftconw > < p id = LH > < a href= http://home.baidu.com >About Baidu < / a > < a href= http://ir.baidu.com >About Baidu</a> </p> <p id=cp>© 2017 Baidu < a href= http://www.baidu.com/duty/ >Must read < / a > & nbsp; before using Baidu< a href= http://jianyi.baidu.com/ Class = CP feedback > feedback < / a > & nbsp; Beijing ICP Certificate No. 030173 & nbsp< img src=//www.baidu. com/img/gs. gif> </p> </div> </div> </div> </body> </html>
It's normal!
Explanation:

r.encoding is obtained from the charset field in the HTTP header. If there is such a field in the HTTP header, it means that the accessed server has requirements for resource coding, but not all servers have relevant requirements for coding

However, ISO-8859-1 cannot parse Chinese. When r.encoding cannot parse correctly, r.apprent should be used_ encoding

·General code framework for crawling web pages
Climbing is not necessarily safe!

The Response object has an exception handling method:

The following is the general code framework for crawling web pages:
import requests
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status() #Judge the network connection status. If the status is not 200, an HTTPError exception will be thrown
r.encoding = r.apparent_encoding
return r.text
except:
return "raise an exception"
if __name__ == "__main__":
url = "http://www.baidu.com"
print(getHTMLText(url))
In python, try except ion statement blocks are used to catch and handle exceptions. The basic syntax is:
try:
Code blocks that may cause exceptions
except [ (Error1, Error2, ... ) [as e] ]:
Code block 1 for handling exceptions
except [ (Error3, Error4, ... ) [as e] ]:
Code block 2 for handling exceptions
except [Exception]:
Handle other exceptions
For details, click here 👉 link
② HTTP protocol

"Stateless" means that there is no association between the first request and the second request



Six methods corresponding to requses Library

HTTP locates resources through URL s and manages resources through these common methods
Each operation is independent and stateless
In HTTP protocol, it only knows URL and URL related operations
·The difference between PATCH and PUT

·HTTP protocol and methods of requests Library

head() method
There have been twists and turns here, and there are 18 twists and turns in the mountain road. However, although the mountains and rivers are heavy and there is no doubt, fortunately, there is another village. See the problems encountered later in this article, the proxy server
import requests
r = requests.get('http://httpbin.org/get')
print(r.headers)
Operation results
{'Date': 'Sat, 26 Jun 2021 17:14:44 GMT', 'Content-Type': 'application/json', 'Content-Length': '306', 'Connection': 'keep-alive', 'Server': 'gunicorn/19.9.0', 'Access-Control-Allow-Origin': '*', 'Access-Control-Allow-Credentials': 'true'}
post() method
import requests
payload = {'key1':'value1','key2':'value2'}
r = requests.post('http://httpbin.org/post',data = payload)
print(r.text)
Operation results
{
"args": {},
"data": "",
"files": {},
"form": {
"key1": "value1",
"key2": "value2"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "23",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.25.1",
"X-Amzn-Trace-Id": "Root=1-60d7de2b-06bb43e603a8ac9a3634140e"
},
"json": null,
"origin": "221.2.164.53",
"url": "http://httpbin.org/post"
}
The post method submits new data to the server. Different data submitted by users will be sorted on the server
As shown in the above code, post a dictionary to the URL and automatically code it as form
import requests
r = requests.post('http://httpbin.org/post',data = 'ABC')
print(r.text)
Operation results:
{
"args": {},
"data": "ABC",
"files": {},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "3",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.25.1",
"X-Amzn-Trace-Id": "Root=1-60d7df9d-3a4a65b23c8495b8099b29c3"
},
"json": null,
"origin": "222.175.198.25",
"url": "http://httpbin.org/post"
}
Here, post a string to the URL, which is automatically encoded as data
put() method
import requests
payload = {'key1':'value1','key2':'value2'}
r = requests.put('http://httpbin.org/put',data = payload)
print(r.text)
Operation results
{
"args": {},
"data": "",
"files": {},
"form": {
"key1": "value1",
"key2": "value2"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "23",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.25.1",
"X-Amzn-Trace-Id": "Root=1-60d7e0d4-58c32fb859f344447214fff0"
},
"json": null,
"origin": "222.175.198.25",
"url": "http://httpbin.org/put"
}
It is similar to the post() method, but the put() method will overwrite the original data
③ Analysis of 7 main methods of Requests Library
request() method
requests.request(method,url,**kwargs)
Method: request method, corresponding to 7 types such as get/put/post

(OPTION uses less)
url: the url link of the page to be obtained
**kwargs: 13 parameters controlling access

Here are 13 parameters:

Through this parameter, some key value pairs can be added to the URL, so that when the URL is accessed again, it will not only access the resource, but also bring in some parameters. The server can accept these parameters and filter some resources back according to these parameters

data is mainly used when submitting resources to the server

As part of the content, it can be submitted to the server




If the request content is not returned within the timeout time, a timeout exception will be thrown
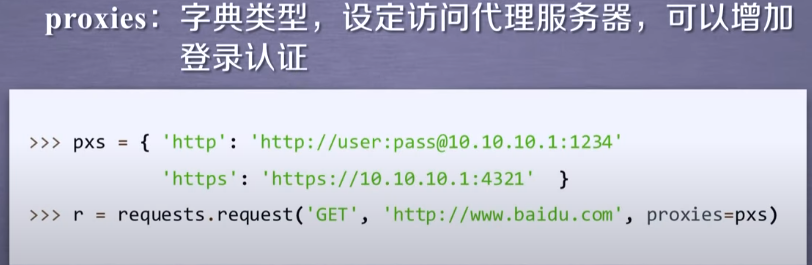
In the above example, there are two proxies. One is the proxy used for http access. In this proxy, you can add user name and password settings, and the other is https proxy server
When accessing Baidu, the IP address is the IP address of the proxy server. Use this field to hide the user's source IP address and effectively prevent crawler reverse tracking

requests.get()

The 12 parameters here are the 13 parameters of the request. There are parameters other than param
requests.head()

requests.post()

11 are in addition to data and json
requests.put()

requests.patch()

requests.delete()

As mentioned earlier, various methods are actually implemented by calling the request() method
requests.get(),requests.put() and other methods are encapsulated based on the request() method
Then why do you design it alone?
Because the latter six methods will involve some common access control parameters, such parameters are put into the function design as an explicitly defined parameter quantity, while those less commonly used parameters are put into the optional parameters
As mentioned earlier, the get method is the most commonly used method, because submitting resources to the server involves network security issues and is strictly controlled, while the use of the get method for crawling is not so limited
II Problems encountered
1.import requests
After pycharm creates a new project, build a virtual environment, enter import requests, and then I install requests, which always shows Install packages failed
Then I changed the Python Interpreter to the Interpreter where I installed python in File → Settings → Python Interpreter. That's good

I don't know why
Comment area for a wave of answers!
2. Proxy server?
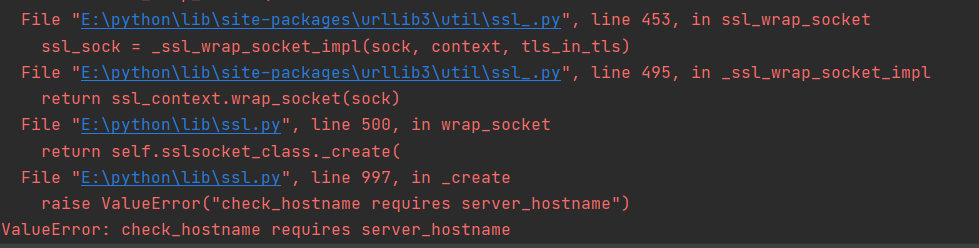
- As mentioned above in the head() method, there are twists and turns. At first, the code is allowed to display the error message, and then I search the crawler and encounter valueerror: check_ hostname requires server_ What's the reason for hostname, and then I saw the big man's name article , he said he would downgrade requests or urlib3
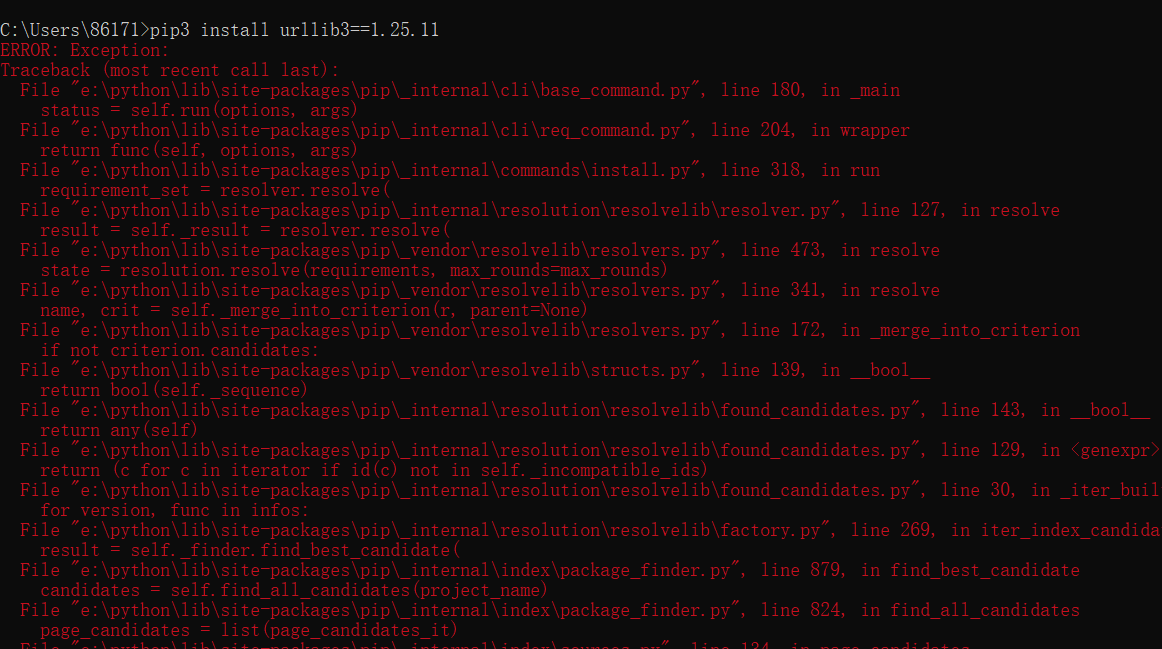
- Then I rushed to the cmd to PIP install urlib3 = = 1.25.11
As a result
- Then I went to Baidu and saw this article Q & a post , the great God inside said to turn off the agent
After I shut down the agent
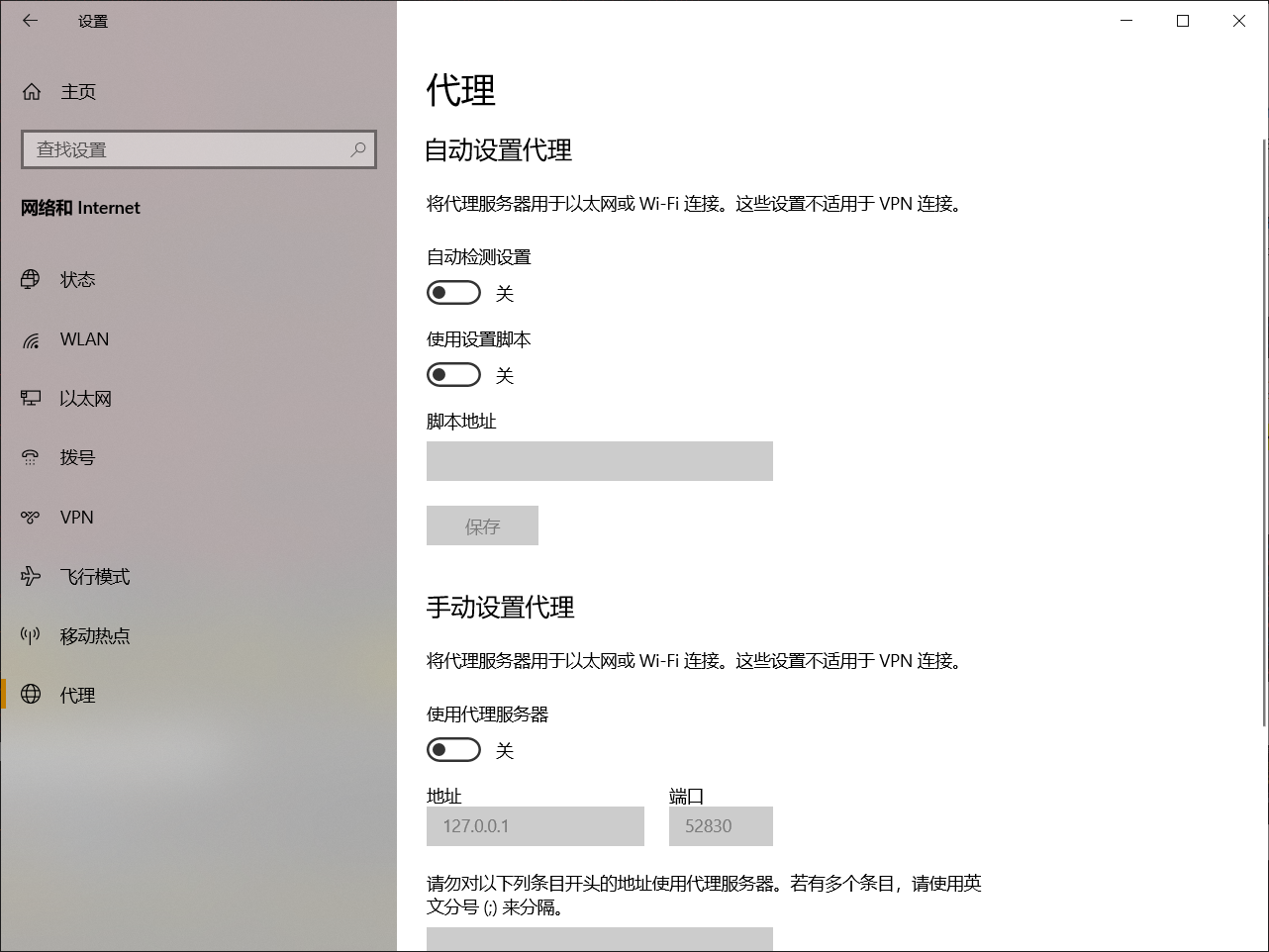
Then you can successfully climb!

However, after the agent is opened, it can't crawl. Considering that the previous article said that it was still a version problem, we still have to downgrade the version
However, pip install reports an error!
- Then I had an idea 🤔🤔🤔, Whether the downgrade is unsuccessful is also a problem of opening the agent. First turn off the agent and then go to pip install,
succeed!!!!! ✌️💪

- 😭 After reducing the url version, I can still crawl successfully when I open the proxy 😢
Now I wonder if the first one to install the requests library is also the problem of the proxy server 😿
If pip install makes another error, come back and try to see if it's the problem
emm, I crawl with the server agent open http://httpbin.org/post Although the result didn't report red, it still failed to crawl
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 3.2 Final//EN"> <title>405 Method Not Allowed</title> <h1>Method Not Allowed</h1> <p>The method is not allowed for the requested URL.</p>
Then I shut down the proxy server and it succeeded
Then I'd better turn it off first. I'll just
Comment area for a wave of answers!