Introduction to Python Full Stack Learning (II)
code annotation
Single-Line Comments
Single-line comments need only be preceded by #.
multiline comment
Hide multi-line comments with three single quotes or three double quotes
""" Note Content """ perhaps ''' Note Content '''
You can use multi-line annotations when writing long pieces of prompt information
Code example:
docs=""" print "I'm a Python developer" print "My blog URL: https://xxxxxxxx.me" print "Life is short, you need Pytho" """ """
String data type
Standard character escape codes

String Built-in Method
str='Life is short and bitter'print(len(str.encode())) #utf8 Each Chinese takes up 3 bytes and 12 bytes. print(len(str.encode("gbk"))) #gbk 2 bytes per Chinese string.expandtabs(tabsize=8) # tab Symbol to space #Default 8 spaces string.endswith(obj,beg=0,end=len(staring)) # Check whether the string has been obj End,If it is returned True #If beg or end specifies whether the detection range is obj-terminated string.count(str,beg=0,end=len(string)) # Detection of str occurrence in string F. count (' n', 0, len (f)) to determine the number of lines in the file string.find(str,beg=0,end=len(string)) # Detecting whether str is included in string string.index(str,beg=0,end=len(string)) # Detecting that str is not in string will report an exception string.isalnum() # Returns True if string has at least one character and all characters are letters or numbers string.isalpha() # Returns True if string has at least one character and all characters are alphabetic string.isnumeric() # If string contains only numeric characters, True is returned string.isspace() # If string Including spaces returns True string.capitalize() #Conversion of initials from lowercase to capitalization string.isupper() # Strings are capitalized to return True string.islower() # Strings are all lowercase to return True string.lower() # Convert all capitals in a string to lowercase string.upper() # Convert all lowercase to uppercase in a string string.strip() #Use to remove the character specified at the beginning and end of the string (default space) string.lstrip() # Remove the space on the left of string string.rstrip() # Remove the space at the end of the string character string.replace(str1,str2,num=string.count(str1)) # Replace str1 in string with str2. If num is specified, the substitution does not exceed num times. string.startswith(obj,beg=0,end=len(string)) # Detecting whether a string begins with obj string.zfill(width) # Returns a character whose length is width, aligned to the right of the original string, preceded by 0 string.isdigit() # Return True with only numbers string.split("Delimiter") # Slice string s into a list ":".join(string.split()) # With: as a separator, merge all elements into a new character string.swapcase() #The method is used to convert the upper and lower case letters of a string. The upper and lower case letters of a string are converted to lower case letters and upper case letters.
String splicing
bottles=99 base='' base +="hujianli staduy python3.6 " base +=str(bottles) base 'hujianli staduy python3.699' "hujianli" + " recover" + " Study python3.6" 'hujianli recover Study python3.6'
Use for escaping
speen = "today we honor our friend, the backslash :\\." print(speen) today we honor our friend, the backslash :\.
String formatting (% and format usage)
#!/usr/bin/env python #-*- coding:utf8 -*- print("I am %s stduy %s" %("hujianli","python")) print("I am {0} stduy {1}".format("hujianli","python") ) str = "I am {0} stduy {1}" name = ("hujianli","python") print(str.format(*name)) print("%d + %d = %d" % (2,3,2+3)) print("%d + %d = %d" % (3,7,3+7)) print(" Partition line ".center(100,"*")) template = 'number:%09d\t Corporate name:%s \t Official website: http://www.%s.com' arg1 = (7, "xxx square", "futong") print(template%arg1) template2 = "number:{:0>9s}\t Corporate name:{:s} \t Official website:http://www.{:s}.com " context1 = template2.format("7", "Baidu", "baidu") print(context1) print("".center(100, "*")) ## Print Floating Point number = 123 print("%f" % number) print("%.2f" % number) print("%.4f" % number) print() print("{:.2f}".format(number)) print("{:+.2f}".format(number)) print("Circumference PI The value is:%.2f" % 3.14) print("Circumference PI The value is:%10f" % 3.141593) #The field width is 10 print("Keep 2 decimal digits, circumference PI The value is:%10.2f" % 3.141593) #Field width is 10, string occupies 4 print("Keep 2 decimal digits, circumference PI The value is:%.2f" % 3.141593) #Output, no field width parameter print("String Accuracy Acquisition:%.5s " % ('hello world')) #Print the first five characters of a string # Specify placeholder width print("".center(100, "*")) number = "ABCDE" print("%6s" % number) print("%06s" % number) print("%8s" % number)
Code example:
#!/usr/bin/env python #-*- coding:utf8 -*- "abc" "123abc" "abc12*" "everybody" str2=''' This is function Return a tuple ''' print(str2) print("aaa\nbbb") #Newline character print("Tab character\t Tab character*2") #Tab character print("print \r") print("\\display\\") print("Single quotation mark\'") print('Double quotation marks\"') print("String operation".center(100,"#")) print("aaa" + "bbbb") print("aaa"*3) print("String Processing Function".center(100,'#')) str3 = "beautiful is batter ugly" print("source string is ",str3) print("String case interchange\n",str3.swapcase()) print("String capitalization\n",str3.upper()) print("String lowercase\n",str3.lower()) print("Capitalization of string initials\n",str3.title()) print("Whether the first letter of a string is capitalized\n",str3.istitle()) print("Is the string initials lowercase?\n",str3.islower()) print("Uppercase the first letter of a string\n",str3.capitalize()) print("Get string letters u subscripting of\n",str3.find("u")) print("Gets the number of letters in a string\n",str3.count("u")) print("Converting strings to lists, partitioned by spaces\n",str3.split(" ")) print("Stitching Strings with Spaces") print(" ".join("abcd")) print("Calculate the length of a string\n",len(str3))
String modification and substitution
Code examples
#!/usr/bin/env python #-*- coding:utf8 -*- s = 'spammy' S = s[:3] + 'xx' + s[5:] print(S) print(s.replace('mm','xx')) hu = 'aa$bb$cc$dd'.replace('$', 'SPAM') print(hu) S = 'xxxxSPAMxxxxSPAMxxxx' where = S.find("SPAM") S = S[:where] + 'EGGS' + S[(where+4):] print(S) S = 'xxxxSPAMxxxxSPAMxxxx' print(S.replace("SPAM","EGGS",1))
String formatted output
Code examples
#!/usr/bin/env python #-*- coding:utf8 -*- print("I am %s stduy %s" %("hujianli","python")) print("I am {0} stduy {1}".format("hujianli","python") ) str = "I am {0} stduy {1}" name = ("hujianli","python") print(str.format(*name)) print("%d + %d = %d" % (2,3,2+3)) print("%d + %d = %d" % (3,7,3+7)) print(" Partition line ".center(100,"*")) template = 'number:%09d\t Corporate name:%s \t Official website: http://www.%s.com' arg1 = (7, "xxx square", "futong") print(template%arg1) template2 = "number:{:0>9s}\t Corporate name:{:s} \t Official website:http://www.{:s}.com " context1 = template2.format("7", "Baidu", "baidu") print(context1)
//Placeholder description %s Character string(Use str()Display) %r Character string(Use repr()Display) %c Single character %b Binary integer %d Decimal integer %i Decimal integer %o Octal integer %x Hexadecimal integer %e index (The base is written as e) %E index (The base is written as E) %f Floating Point %F Floating point number, same as above %g index(e)Or floating point numbers (Depending on the display length) %G index(E)Or floating point numbers (Depending on the display length) print("hello,%s" % "world") print('Xiao Zhi this year %s Year old' % 18) print('Xiao Zhi this year %s Year old' % 19) print('Xiao Zhi this year %d Year old' % 20) print("Circumference PI The value is %.2f" % 3.14) # Output results like 1.23% print("Xiao Zhi's recognition ability is better than last year's.:%.2f" % 1.25+"%") print("Xiao Zhi's recognition ability is better than last year's.:%.2f%%" % 1.26 ) # Output Percentage print("Output Percentage:%s" % "%") # String formatting tuples print("This year is%s 2008 Olympic Games%s,China Acquired%d Gold Medal" % ('2016', '10', 20)) # Width and Accuracy print("Circumference PI The value is:%10f" % 3.1415926) print("Keep 2 decimal digits, circumference PI The value is:%10.2f " % 3.1415926) print("String Accuracy Acquisition:%.5s" % ("hello world") ) print ('Get string precision from tuples:%*.*s' % (10,5,'hello world')) print ('Get string precision from tuples:%.*s' % (5, 'hello world')) #Symbol, Alignment and 0 Fill print ('Circumference PI The value is:%010.2f' % 3.141593) #The minus sign (-) is used to align the values left print ('Circumference PI The value is:%10.2f' % 3.14) print ('Circumference PI The value is:%-10.2f' % 3.14) # The plus sign (+) denotes that both positive and negative numbers denote symbols. print(('Add a plus sign before the width:%+5d'%10)+'\n'+('Add a plus sign before the width:%+5d'%-10))
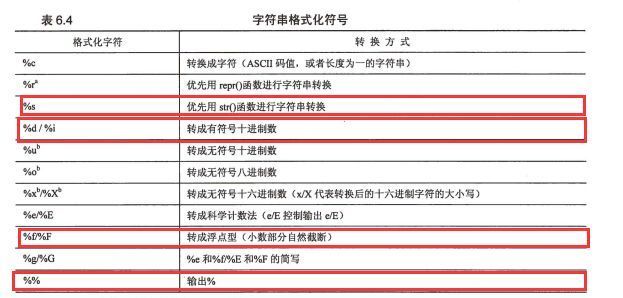
Example
In [2]: print("Suzhou is more than %d years. %s lives in here." % (2500, "qiwsir")) Suzhou is more than 2500 years. qiwsir lives in here.
python's highly advocated string.format() formatting method, where {index value} is the placeholder
In [3]: print("my name is {name}, age is {age}".format(name="hujianli",age="22")) my name is hujianli, age is 22 In [3]: print("my name is {name}, age is {age}".format(name="hujianli",age="22")) my name is hujianli, age is 22 In [6]: str="my name is {0}" In [7]: str.format("hu") Out[7]: 'my name is hu' #Dictionary Formatting In [8]: lang = "python" In [10]: print("I LOVE %(program)s" % {'program':lang}) I LOVE python In [1]: '{0:!^20s}'.format('BIG SALE') Out[1]: '!!!!!!BIG SALE!!!!!!'
text = "hello world" print(text.ljust(20)) print(text.rjust(20)) print(text.center(20)) print() print("Add Fill Fields") print() print(text.rjust(20, "-")) print(text.ljust(20, "-")) print(text.center(20, "-")) print() print("format Use") print() print(format(text, ">20")) print(format(text, "<20")) print(format(text, "^20")) print(format(text, "*>20")) print(format(text, "*<20")) print(format(text, "*^20")) print() print("Format multiple values") print() print("{:>10s} {:>10s}".format("hello", "world")) x = 1.2345 print(format(x, ">10")) print(format(x, "^10.2f")) # Use% for formatting, older format, not commonly used print("%-20s" % text) print("%20s" % text) template = "No. %09d \t Corporate name:%s \t Official website: http://www.%s.com" Definition Template print() context1 = (7, "Baidu", "baidu") context2 = (9, "Baidu 2", "baidu2") print(template % context1) print(template % context2) print() template2 = "No.{:0>9s}\t Corporate name: {:s}\t Official website: http://Www. {s}.com "# Definition Template context01 = template2.format("7", "Baidu 3", "baidu3") context02 = template2.format("8", "Baidu 4", "baidu4") print(context01) print(context02)
String inversion
def reverse(s): out = "" li = list(s) for i in range(len(li), 0, -1): out += "".join(li[i - 1]) return out print(reverse("Hu Jianli ah ah ah ah ah ha ha ha"))
Using the inversion of the list is simpler, as follows
def reverse2(s): li = list(s) li.reverse() s = "".join(li) return s print(reverse2("Hu Jianli ah ah ah ah ah ha ha ha"))
One line of code to invert strings
def reverse3(s): return s[::-1] # perhaps # Using lambda to implement lambda_str = lambda s: s[::-1] print(lambda_str("hujianlishuaige"))
List
list() #Create an empty list [] #Create an empty list
List type built-in functions
list.append(obj) # Add an object obj to the list list.count(obj) # Returns the number of times an object obj appears in the list list.extend(seq) # Add the contents of the sequence seq to the list list.index(obj,i=0,j=len(list)) # Returns the K value of list [k]== obj, and the range of K is i<=k<j; otherwise, the exception list.insert(index.obj) # Insert the object obj at the index location list.pop(index=-1) # Delete and return the object at the specified location, defaulting to the last object list.remove(obj) # Delete the object obj from the list list.reverse() # In-situ Flip List list.sot(func=None,key=None,reverse=False) # Sort the members of the list in a specified way. If the func and key parameters are specified, the elements are compared in the specified way. If the reverse flag is set to True, the list is arranged in reverse order. list.sort(reverse=True) #Descending order
del
In [16]: maxnum=["hu","jianli","xiaojian","yes"] In [17]: maxnum[-1] Out[17]: 'yes' In [18]: del maxnum[-1] In [19]: maxnum Out[19]: ['hu', 'jianli', 'xiaojian'] In [20]: del maxnum[2] In [21]: maxnum Out[21]: ['hu', 'jianli']
in
In [22]: maxnum=["hu","jianli","xiaojian","yes"] In [23]: "hu" in maxnum Out[23]: True In [24]: "hu1" in maxnum Out[24]: False
Code Example 1
#!/usr/bin/env python # -*- coding:utf8 -*- lsit1 = ["a", 1, "b", 2.0] print(lsit1[1]) #1 print(lsit1[2]) #b print(lsit1[-2]) #b print(lsit1[::-1]) # Inversion list [2.0,'b', 1,'a'] lsit2 = [3, 4, 5, 6] print(lsit1 + lsit2) #['a', 1, 'b', 2.0, 3, 4, 5, 6] lsit3 = ["python"] print(lsit3 * 3) #['python', 'python', 'python'] print("apped()".center(100, "#")) alst = [1, 2, 3, 4, 5] alst.append("hu") print(alst) # [1, 2, 3, 4, 5, 'hu'] print("count()".center(100, "#")) print(alst.count(1)) #1 print("Add another list after the list".center(100, "#")) alst.extend(["1", "Ha-ha"]) print(alst) # [1, 2, 3, 4, 5,'hu','1','haha'] print("Find the subscripts that appear in the list".center(100, "#")) print(alst.index(2)) # 1 print("Insert the element at the subscript".center(100, "#")) alst.insert(2, "hu") print(alst) #[1, 2,'hu', 3, 4, 5,'hu','1','haha'] print("Returns the deleted list element, the last".center(100, "#")) pop_num = alst.pop() print(pop_num) # Ha-ha print(alst) # [1, 2, 'hu', 3, 4, 5, 'hu', '1'] print("Delete element 2 of the list".center(100, "#")) alst.remove(2) print(alst) # [1, 'hu', 3, 4, 5, 'hu', '1'] print("Reverse List, Reverse List".center(100, "#")) alst.reverse() print(alst) # ['1', 'hu', 5, 4, 3, 'hu', 1] alst1 = [6, 2, 3, 4, 5] print("Sort lists".center(100, "#")) alst1.sort() print(alst1) #[2, 3, 4, 5, 6]
Slices of lists
Code Example 2
# The maximum number of list elements is 536870912 shoplist = ['apple', 'mango', 'carrot', 'banana'] marxes = ['Groucho', 'Chico', 'Harpo', 'Zeppo'] others = ['Gummo', 'Karl'] marxes.extend(others) #Merge List marxes += others #Merge List shoplist[2] = 'aa' del shoplist[0] shoplist.insert(4,'www') shoplist.append('aaa') ############ Slices of lists ########### shoplist[::-1] # Reverse printing is effective for character flip strings shoplist[2::3] # Print every three times starting from the second shoplist[:-1] # Exclude the last one '\t'.join(li) # Converting lists to strings and splitting them with alphabets sys.path[1:1]=[5] # Insert a value in the list before position 1 list(set(['qwe', 'as', '123', '123'])) # Repeat lists through collections {}.fromkeys(l).keys() #Method of list de-duplication (2) by converting to dictionary and then keying eval("['1','a']") # Evaluate a string as an expression to get a list # enumerate can get the corresponding position of each value for i, n in enumerate(['a','b','c']): print i,n #The same way as enumerate for i in range(len(list)): print(i,list[i])
Advanced features of lists
Code examples
#!/usr/bin/env python #-*- coding:utf8 -*- ''' import sys #Loading sys module if len(sys.argv) != 2: #Determine whether the input parameter is 2 print("Please supply a filename") raise SystemExit(1) f = open(sys.argv[1]) #File name of parameter 1 on the command line lines = f.readlines() #Read all rows into a list f.close() #Converting all input values from strings to floating-point numbers fvalues = [float(line) for line in lines] #Print minimum and maximum values print("The minimum value is ",min(fvalues)) print("The maximum value is ",max(fvalues)) ''' fruit1 = ['apple','orange'] fruit2 = ['pear','grape'] fruit1.extend(fruit2) print(fruit1) for i,v in enumerate(fruit1): print(i, v)
Looking up, sorting, inversion of lists
Code examples
#!/usr/bin/env python #-*- coding:utf-8 -*- __author__ = '18793' list = ["apple", "banana", "grape", "orange"] print(list.index("apple")) #Print the index of apple print(list.index("orange")) #Print the index of orange print("orange" in list) #Determine whether orange is in the list list.sort() #sort print("Sorted list :",list) list.reverse() #Reversal print("Reversed list:",list) 0 3 True Sorted list : ['apple', 'banana', 'grape', 'orange'] Reversed list: ['orange', 'grape', 'banana', 'apple']
Tuple, the ancestor of Yuan Dynasty
The tuple() function creates an empty element ancestor
Meta-ancestors are similar to lists, and the distinction is immutable
Code examples
# Similar to list operations, but not variable zoo = ('wolf', 'elephant', 'penguin') # The parentheses of Yuanzu are not necessary, as long as a group of numbers are separated by commas, python can think of it as Yuanzu. In [1]: tmp="aa","bb","cc" In [2]: type(tmp) Out[2]: tuple # Yuanzu can be combined with a + sign, similar to a list #!/usr/bin/env python #-*- coding:utf8 -*- # auther; 18793 # Date: 2019/4/15 20:09 # filename: Yuan Zu.py play1=("Messi","C Luo","Kakashi","Hu Ge") print("The primitive Yuan ancestors:{}".format(play1)) play2=play1+("Hu Jianli","Little cheap","Hu Xiaojian") print("After the combination, Yuan Zu:{}".format(play2)) # If only one ancestor is added, a comma is added after the ancestor. play3= play2+("Monkey D Luffy",) print("To add a meta-ancestor, when there is only one element, you need to add a comma after it:{}".format(play3))
Yuan Zu
Immutable sequence (Elements cannot be added, modified or deleted, and can be replaced as a whole) Support slicing operations (Only elements in meta-ancestors can be accessed) Yuanzu visits fast Yuan Zu can be used as the key of dictionary
Yuan Zu's one breath assignment (unpacking)
In [25]: marx_tuple = ("hu","jian","li") In [27]: a,b,c = marx_tuple In [28]: a Out[28]: 'hu' In [29]: b Out[29]: 'jian' In [30]: c Out[30]: 'li' //You can use tuples to exchange the values of multiple variables in a single statement without resorting to temporary variables.
The difference between list and meta-ancestor
Variable sequence (Modification or deletion can be added at any time) Support slicing operation (The total elements of the list can be accessed and modified) Slow List Access Can't be used as a dictionary key
Dictionary Dict
The dict() function creates an empty dictionary, which is out of order.
The built-in method of dictionary
dict.clear() # Delete all elements in a dictionary dict.copy() # Return a copy of the dictionary (shallow copy) dict.fromkeys(seq,val=None) # Create and return a new dictionary with elements in seq as keys and val as initial values for all key pairs in the dictionary dict.get(key,default=None) # For the key in dictionary dict, return its corresponding value value, and if the key does not exist in dictionary, return the default value. dict.has_key(key) # If the key exists in the dictionary, return True. In Python 3, in and not in are used instead. dict.items() # Returns a list of key and value pair tuples in the dictionary dict.keys() # Returns a list of keys in the dictionary dict.iter() # The methods iteritems(), iterkeys(), itervalues() are the same as their corresponding non-iterative methods, except that they return an iterator instead of a list. dict.pop(key[,default]) # Similar to the method get(). If the key key key exists in the dictionary, delete and return dict[key] dict.setdefault(key,default=None) # Similar to set(), but if the key key key does not exist in the dictionary, it is assigned by dict[key]=default dic[key] = [value] #Instead of setdefault, direct keys add dictionaries to corresponding values dict.update(dict2) # Add key-value pairs of dictionary dict2 to dictionary Dict dict.values() # Returns a list of all the worthwhile items in the dictionary dict([container]) # Factory functions that create dictionaries. Provide container classes and fill dictionaries with entries len(mapping) # Returns the length of the mapping (number of key-value pairs) hash(obj) # Returns the obj hash value to determine whether an object can be used as a dictionary key del dict["key"] # Delete elements with specified keys
Code Example 1
#!/usr/bin/env python #-*- coding:utf8 -*- ab = { 'Swaroop': 'swaroopch@byteofpython.info','Larry' : 'larry@wall.org'} ab['c'] = 80 print(ab) del ab['c'] print(ab) li = ["a","b","c"] print(dict(enumerate(li))) #Definition Dictionary word = {"che":"vehicle","chen":"Chen","cheng":"call","chi":"eat"} print(word) key = ["che","chen","cheng","chi"] #Define index list vlaue = ["vehicle", "Chen","call","eat"] #Define Chinese Character List zip1 = dict(zip(key,vlaue)) #Converting Objects into Dictionaries print(zip1) print(zip1["che"]) print(zip1.get("chen")) #Key exists, return value print(zip1.get("chenj")) #Key does not exist, return None print(zip1.get("chene","No one found this person.")) #The key does not exist and returns the default value dict1 = {} #dict1.fromkeys() name = ["hujianli","jianli","xiaojian","jianlihu"] dictionary = dict.fromkeys(name) #Create a keyless dictionary print(dictionary) In [5]: s = dict.fromkeys(("hujianli","xiaojian"),"goodboy") In [6]: s Out[6]: {'hujianli': 'goodboy', 'xiaojian': 'goodboy'} In [7]: s1 = dict.fromkeys((12,23)) In [8]: s1 Out[8]: {12: None, 23: None} In [9]: s2 = dict.fromkeys(("a","b")) In [10]: s2 Out[10]: {'a': None, 'b': None} #del dictionary #Delete dictionary dictionary.clear() #Clear up all the elements in the dictionary and turn it into an empty dictionary print(dictionary) #Traversing the keys and values of a dictionary dic2 = {"Yimeng":"Aquarius","Hu Jianli":"Cancer","Xiao Jian":"Leo"} """ dic2.items() """ #Traversal keys and values for key1, vlaue1 in dic2.items(): print(key1,'=====>',vlaue1) #Ergodic key for key1 in dic2.keys(): print("key is {}".format(key1)) #Ergodic value for vlaue in dic2.values(): print("value is {}".format(vlaue)) hu1 = list(zip(['a','b','c'],[1,2,3])) print(hu1) hu2 = dict(zip(['a','b','c'],[1,2,3])) print(hu2) stu1={'Student ID':'10001','Full name':'Zhang Xiaoguang','Gender':'male','Age':20} stu1['Age']=30 print(stu1['Gender']) print(stu1) # stu1 = {student number':'10001','name':'Zhang Xiaoguang','name':'Li San','age': 20} # print(stu1[1]) day={1:'Monday',2:'Tuesday',3:30,'Four':'Thursday'} print(day['Four']) print(day[2]) dict1={'Full name':'Zhang Xiaoguang','Age':20} print('1.All keys:',dict1.keys()) print('2.All values:',dict1.values()) print('3.All keys-Value:',dict1.items()) dict2=dict1 dict3=dict1.copy() print('4.Shallow and deep copies:',id(dict1),id(dict2),id(dict3)) score1=(1,2,3,4) dict4=dict1.fromkeys(score1) print('5.Create a dictionary through tuples:',dict4) print('6.get Age:',dict1.get('Age')) dict1.setdefault('Age',30) print('7.setdefault Age:',dict1) dict5={'achievement':'excellent'} dict1.update(dict5) print('8.update Achievements:',dict1) # Delete dictionary dict1={'Full name':'Zhang Xiaoguang','Age':20} str1=dict1.pop('Full name') print(str1) print(dict1) dict1={'Full name':'Zhang Xiaoguang','Age':20} if 'Full name' in dict1: print(dict1['Full name']) if 'Gender' not in dict1: dict1.setdefault('Gender','male') print(dict1)
Add/modify/delete dictionary elements
Code examples
#!/usr/bin/env python #-*- coding:utf8 -*- #Add elements to the dictionary dict1 = {"1":"hujianli","2":"xiaojian","3":"xiaojian3"} dict1["4"] = "xiaojian4" print(dict1) #Modifying Dictionary Elements dict1['1'] = "hujianli1" dict1['2'] = "hujianli2" print(dict1) #Delete elements del dict1['1'] del dict1['2'] #Judge whether the key is in the dictionary if "1" in dict1: del dict1['1'] print(dict1) >>> dict.fromkeys(['a', 'b'], 0) {'a': 0, 'b': 0}
Dictionary Derivation
#!/usr/bin/env python #-*- coding:utf8 -*- #Derivative formula can generate dictionary quickly ''' {Key Expressions: Value Expressions for loop} ''' import random #Generate a random number dictionary with keys ranging from 1 to 4 and values ranging from 10 to 100 randomdict = {i: random.randint(10,100) for i in range(1,5)} print(randomdict) name = ["Yimeng","Reluctance","Xiang Ling","Dylan"] sign = ["Water bottle","Shooter","Pisces","Gemini"] dict1 = {i:j for i,j in zip(name,sign)} print(dict1)
Re-access nesting of dictionaries
In [17]: rec = {"name":{"first":"Bob","hujianli":"smith","job":["dev","mgr"],"age":"22"}} In [19]: rec["name"] Out[19]: {'age': '22', 'first': 'Bob', 'hujianli': 'smith', 'job': ['dev', 'mgr']} In [20]: rec["name"]["job"] Out[20]: ['dev', 'mgr'] In [21]: rec["name"]["job"][1] Out[21]: 'mgr' In [22]: rec["name"]["job"][-1] Out[22]: 'mgr' In [24]: rec["name"]["job"].append("IT") In [25]: rec Out[25]: {'name': {'age': '22', 'first': 'Bob', 'hujianli': 'smith', 'job': ['dev', 'mgr', 'IT']}}
Dictionary formatting.py
temp = "The title of the book is:%(name)s,The price is:%(price)010.2f,The publishing house is:%(publish)s" book1 = {'name': "Insane python Handout", 'price': 88.9, 'publish': 'Electronic Society 1'} print(temp % book1) book2 = {'name': "Insane java Handout", 'price': 78.9, 'publish': 'Electronic Society 2'} print(temp % book2)
Building Programs with Dictionary Branches
#!/usr/bin/env python #-*- coding:utf8 -*- import random #Define three branch functions def print_a(): print("Path Branch A") def print_b(): print("Path Branch B") def print_c(): print("Path Branch C") if __name__ == '__main__': path_dict = {} path_dict['a'] = print_a path_dict['b'] = print_b path_dict['c'] = print_c paths = 'abc' for i in range(4): path = random.choice(paths) print("Choose the path:",path) path_dict[path]()
Output information
Path chosen: a Path branch A Path selected: b Path Branch B Path selected: b Path Branch B Path chosen: c Path branch C
Set()
The set() function converts lists to collections
Can be used to de-duplicate data
Method of Set
s.update(t) # Modify s with the elements in T. s now contains s or t members s |= t s.intersection_update(t) # Members in s share elements s &= t that belong to s and t s.difference_update(t) # The members in s are elements s -= t that belong to s but are not included in t s.symmetric_difference_update(t) # Members in s are updated to those elements included in s or t, but not shared by s and t s.add(obj) # Add object obj to collection s s.remove(obj) # Delete the object obj from collection s; if obj is not an element in collection s, a KeyError error is raised s.discard(obj) # If obj is an element in the set s, delete the object obj from the set s s.pop() # Delete any object in the collection s and return it s.clear() # Delete all elements in set s s.issubset(t) # If s is a subset of t, return True s <= t s.issuperset(t) # If t is a superset of s, return True >= t s.union(t) # Merge operation; returns a new collection, which is the union of S and t s | t s.intersection(t) # Intersection operation; returns a new set, which is the intersection of s and t s & t s.difference(t) # Returns a new collection, which is a member of s, but not a member of T s - t s.symmetric_difference(t) # Returns a new collection that is a member of s or t, but not a member s ^ t shared by s and t s.copy() # Returns a new collection, which is a shallow copy of set s obj in s # Membership tests; obj is the element in s that returns True obj not in s # Non-member test: obj is not an element in s that returns True s == t # Is Equivalence Testing the Same Element s != t # Unequal testing s < t # Subset test; s!=t and all elements in s are members of T s > t # Superset test; s!=t and all elements in T are members of S
Intersection, union, difference and symmetry difference sets
Code Example 1
#Set Creation set1 = {"Aquarius","Sagittarius","Pisces","Gemini"} #Define a set, which, like a dictionary, is disordered. print(set1) #Because it is out of order, it cannot be retrieved by index. set2 = {"Aquarius","Sagittarius","Pisces","Gemini","Aquarius"} #To repeat print(set2) python = {"hujianli1","hujianli2","hujianli3","hujianli4","xiaojian1"} C = {"xiaojian1","xiaojian2","xiaojian3","xiaojian4"} print(python | C) #Summation set print(python & C) #Find intersection
Code Example 2
#!/usr/bin/env python #-*- coding:utf8 -*- """ //Intersection& //Union| //Difference set- """ python = set(["hujianli1","hujianli2",'hujianli3','hujianli4','jianli4']) C = set(['hujianli1','jianli1','jianli2','jianli3','jianli4']) print("Choice python Student Name:", python) print("Choice C Names of students:", C) print("Intersection operation:",python & C) #Choose both python and C print("Union operation:",python | C) #Names of all the students participating in the course selection print("Difference set operation:",python - C) #The Difference Set of python Language and C Language
Modification and deletion of collections
Code Example 3
#!/usr/bin/env python #-*- coding:utf8 -*- mr = set(['Zero Foundation JAVA','Zero Foundation Android',"Zero Foundation PHP",'Zero Foundation C language']) #Define a collection mr.add("Zero Foundation python") #Adding elements to a collection automatically removes duplicate elements print(mr) mr.pop() #Random deletion of elements #print(mr) if "Zero Foundation JAVA" in mr: mr.remove("Zero Foundation JAVA") #Remove elements of a collection print(mr) mr.clear() #Clear the entire collection print(mr) # del mr #Delete the entire collection # print(mr) #------------------------------------------------- # python adds jianli3, C minus jianli3 #-------------------------------------------------- python = set(["hujianli","xiaojian","xiaojian2","xiaojian3"]) C = set(["jianli1","jianli2","jianli3","jianli4"]) python.add("jianli3") C.remove("jianli3") print(python) print(C)
Immutable set
student_set = frozenset({"Zhang San", "Li Si", "Wang Wu"}) print(student_set) print(type(student_set)) #Errors cannot be corrected # print(student_set.add("Hu Liu")
Differences among Lists, Meta-ancestors, Dictionaries, Collections
#!/usr/bin/env python
#-*- coding:utf8 -*-
list = []
tuple = ()
dict = {}
set = set()
# Is it changeable?
'''
Variable lists, dictionaries, collections
The ancestor of Yuan Dynasty is immutable
'''
# Whether to repeat or not
'''
Repeatable: list, meta-ancestor, dictionary
Unrepeatable: Sets
'''
# Is there order?
'''
List, meta-ancestor ordering
Dictionary, set disorder
'''
Python Data Type Conversion
The data types in python are: list, str, tuple, dict, set, float, int
Conversion between integers, floating-point numbers and strings
Code Example 1
#!/usr/bin/env python #-*- coding:utf8 -*- print("int('12.3')",int(12.3)) print("int('12.0002')",int(12.0002)) print("int('123')",int("123")) print('Converting integers to floating-point numbers',float(12)) print('strtod',float("123")) print("Converting integers and floating-point numbers to strings".center(100,"#")) print("str('123')",str(123)) print("str('123.001')",str(123.001)) input_number = input("please input int:") print(input_number)
String to list/list to string
String - > List Example
In [1]: hu = "abc" In [2]: list(hu) Out[2]: ['a', 'b', 'c'] In [3]: hu = "my name is 123" In [4]: hu.split() Out[4]: ['my', 'name', 'is', '123']
List - > String Example
In [7]: lst = ["1","2","3","4","hu"] In [8]: ",".join(lst) Out[8]: '1,2,3,4,hu' #Introduce learning a built-in function, join() function is a string operation function for string connection. There are two ways of splicing strings: + and join. #join has the function of splitting strings and listing them as strings, and the spllit() function of str in turn In [44]: list1 = ["1","2","3","4"] In [46]: "+".join(list1) Out[46]: '1+2+3+4' #Irregular categories, first converted to standard lists, then to strings In [13]: hu_list = [1,2,3,4,5,"jianli"] In [14]: hu_list1 = [str(hu) for hu in hu_list ] In [17]: ",".join(hu_list1) Out[17]: '1,2,3,4,5,jianli'
List to meta-ancestor/meta-ancestor to list
In [9]: lst Out[9]: ['1', '2', '3', '4', 'hu'] In [10]: tuple(lst) Out[10]: ('1', '2', '3', '4', 'hu') In [11]: hu_tuple = tuple(lst) In [12]: list(hu_tuple) Out[12]: ['1', '2', '3', '4', 'hu'] In [14]: a_tuple = ('ready','fire','aim') In [15]: list(a_tuple) Out[15]: ['ready', 'fire', 'aim']
Dictionary Format String - > Dictionary
#Mode I #Introducing Learning a Built-in Function #The eval() function treats strings as Python expressions In [38]: hu = 1 In [39]: eval('hu+1') Out[39]: 2 In [23]: s = '{"a": 1, "b": 2, "c": 3}' In [24]: type(s) Out[24]: str In [25]: d = eval(s) In [26]: type(d) Out[26]: dict In [27]: d Out[27]: {'a': 1, 'b': 2, 'c': 3} #Mode 2 In [32]: import json In [33]: s = '{"a": 1, "b": 2, "c": 3}' In [34]: type(s) Out[34]: str In [35]: d = json.loads(s) In [36]: type(d) Out[36]: dict In [37]: d Out[37]: {'a': 1, 'b': 2, 'c': 3}
Conversion of Binary bytes to Strings
# bytes to string mode 1 b=b'\xe9\x80\x86\xe7\x81\xab' string=str(b,'utf-8') print(string) # bytes to string mode 2 b=b'\xe9\x80\x86\xe7\x81\xab' string=b.decode() # The first parameter defaults to utf8, and the second parameter defaults to strict. print(string) # bytes to string mode 3 b=b'\xe9\x80\x86\xe7\x81haha\xab' string=b.decode('utf-8','ignore') # Ignoring illegal characters, strict throws exceptions print(string) # bytes to string mode 4 b=b'\xe9\x80\x86\xe7\x81haha\xab' string=b.decode('utf-8','replace') # Use? Replacing Illegal Characters print(string) # String bytes mode 1 str1='Backfire' b=bytes(str1, encoding='utf-8') print(b) # String bytes mode 2 b=str1.encode('utf-8') print(b)
Deep and shallow copies
Such a memory
Shallow copy: Copy only top-level objects, or parent objects Deep copy: Copy all objects, top-level objects and their nested objects. Or: parent objects and their children
Examples are given to illustrate:
""" //Both deep and shallow copies are replicates of source objects, occupying different memory spaces. //If the source object has only one level directory, any changes to the source will not affect the depth of the copy object. //If the source object has more than one level of directory, any changes to the source will affect the shallow copy, but not the deep copy. //Slices of sequential objects are actually shallow copies, that is, only top-level objects are copied. """ import copy d = {'name':'hujianli','age':'22'} c1 = copy.copy(d) #shallow copy c2 = copy.deepcopy(d) #deep copy print(id(d),id(c1),id(c2)) # Three different objects d["name"] = "hujianli" print(d,c1,c2) # Three different objects #deep copy print("deep copy".center(100,"=")) d1 = {'name':{'first':'hu','last':'jianli'}, 'job':['IT','HR']} c1 = copy.copy(d1) c2 = copy.deepcopy(d1) d1["job"][0] = "test" print(d1) print(c1) print(c2)
Built-in Constants and Logic Operators, Comparison Operators
Built-in constants
None means "nothing" and is often used to denote objects that have no value.
Logical falsehoods in python include: False, None, 0, empty string, () empty element ancestor, [] empty list, and {} empty dictionary. Any other values are considered true.
Boolean False
null type None
Integer 0
Floating-point 0.0
Empty string''
Empty list []
Empty tuple ()
Empty dictionary {}
Empty set()Code examples
In [2]: if 0: ...: print("None") ...: else: ...: print('True') ...: True In [9]: if {}: ...: print("None") ...: else: ...: print("true") ...: true In [12]: if "": ...: print("None") ...: else: ...: print("True") ...: True In [13]: if None: ...: print("None") ...: else: ...: print("True") ...: True
Logical operators in python
Operations of or operators
In [14]: [1,2] or 0 #The first operation is true and the result is true. Out[14]: [1, 2] In [15]: 0 or [1,2] #The first operation is false and the second operand is returned directly (1,2). The result is true. Out[15]: [1, 2] In [16]: [] or () #The first operation is false, directly returning the second operand, () null ancestor Out[16]: ()
and operator
In [17]: [1,2] and 3 #The first operation is true, the second operation is returned directly, and the result is true. Out[17]: 3 In [18]: [] and [1,2] #The first operation is false and returns directly to []. The result is false. Out[18]: [] In [19]: [] and () # The first operation is false and returns directly to []. The result is false. Out[19]: [] In [20]: 1 and 0 #The first operation is true, and the second operation 0 is returned directly. The result is false. Out[20]: 0 In [21]: 0 and True ## The first operation is false, returning 0 directly, and the result is false. Out[21]: 0
Comparison operators in python
The comparison operators in Python are shown in the table below. Equality== Not equal to!= Less than< Not more than<= Greater than > Not less than >= Belonging to in...

Is and is not
In [22]: x=3.14 In [23]: y=x In [24]: x is y Out[24]: True In [25]: x is not y Out[25]: False In [27]: x is None Out[27]: False In [28]: x = None In [29]: x is None Out[29]: True
In and not in
hujianli = [1,2,3] hujianli2 = ['a', 'b', 'v'] In [34]: hujianli Out[34]: [1, 2, 3] In [35]: 1 in hujianli Out[35]: True In [36]: 1 in hujianli2 Out[36]: False In [38]: 'a' in hujianli2 Out[38]: True In [39]: hujianli3 = {'a':1,'b':2} In [40]: 'a' in hujianli3 #Check whether'a'is in the dictionary key and return to True. In detects only the keys of the dictionary Out[40]: True In [41]: 1 in hujianli3 #Value undetected, return False Out[41]: False
Assignment Operators

Establishing Large Data Structure
Nested Lists in Yuanzu
In [31]: list1=["hujianli","leijun","hushiqiang","zhangyong"] In [32]: list2=["wuhan","caidian","xiaogan","yingcheng"] In [33]: list3=["21","22","23","24"] In [34]: tuple_of_list= list1,list2,list3 In [35]: tuple_of_list (['hujianli', 'leijun', 'hushiqiang', 'zhangyong'], ['wuhan', 'caidian', 'xiaogan', 'yingcheng'], ['21', '22', '23', '24']) In [36]: tuple_of_list[1] Out[36]: ['wuhan', 'caidian', 'xiaogan', 'yingcheng'] In [37]: tuple_of_list[2] Out[37]: ['21', '22', '23', '24']
Nested lists in lists
In [40]: list_of_list = [list1,list2,list3] In [41]: list_of_list Out[41]: [['hujianli', 'leijun', 'hushiqiang', 'zhangyong'], ['wuhan', 'caidian', 'xiaogan', 'yingcheng'], ['21', '22', '23', '24']] In [42]: list_of_list[0] Out[42]: ['hujianli', 'leijun', 'hushiqiang', 'zhangyong'] In [43]: list_of_list[1] Out[43]: ['wuhan', 'caidian', 'xiaogan', 'yingcheng']
Nested lists in dictionaries
In [44]: dict_of_list = { "dict1":list1,"dict2":list2,"dict3":list3 } In [45]: dict_of_list {'dict1': ['hujianli', 'leijun', 'hushiqiang', 'zhangyong'], 'dict2': ['wuhan', 'caidian', 'xiaogan', 'yingcheng'], 'dict3': ['21', '22', '23', '24']} In [47]: dict_of_list.keys() Out[47]: dict_keys(['dict1', 'dict2', 'dict3']) In [48]: dict_of_list.values() Out[48]: dict_values([['hujianli', 'leijun', 'hushiqiang', 'zhangyong'], ['wuhan', 'caidian', 'xiaogan', 'yingcheng'], ['21', '22', '23', '24']]) In [49]: dict_of_list.items() Out[49]: dict_items([('dict1', ['hujianli', 'leijun', 'hushiqiang', 'zhangyong']), ('dict2', ['wuhan', 'caidian', 'xiaogan', 'yingcheng']), ('dict3', ['21', '22', '23', '24'])]) # You can open the contents layer by layer and use in to judge the elements. In [59]: for i in dict_of_list.values(): ...: for j in i: ...: if "hujianli" in j: ...: print("find'hujianli'....") ...: ...: //Find'hujianli'....
note In fact, like trees, the more people yearn for the sunshine at high altitudes, the more their roots reach to the dark ground.