What is Spark
The whole Hadoop ecosystem is divided into distributed file system HDFS, computing framework MapReduce and resource scheduling framework Yan. However, with the development of the times, MapReduce's high-intensity disk IO, network communication frequency and dead write make it seriously slow down the operation speed of the whole ecosystem. Spark was born.
First, let's talk about how the original MapReduce slows down the pace:
For a task of word frequency statistics, the map task will first disperse the word frequency information of the current node, then land the temporary information on the disk, and then the reduce task will read the data from the disk for shuffling. Shuffling will map the same key to the same node performing the reduce task, which will involve a lot of network communication. After the reduce task is executed, the data will be landed on the disk again.
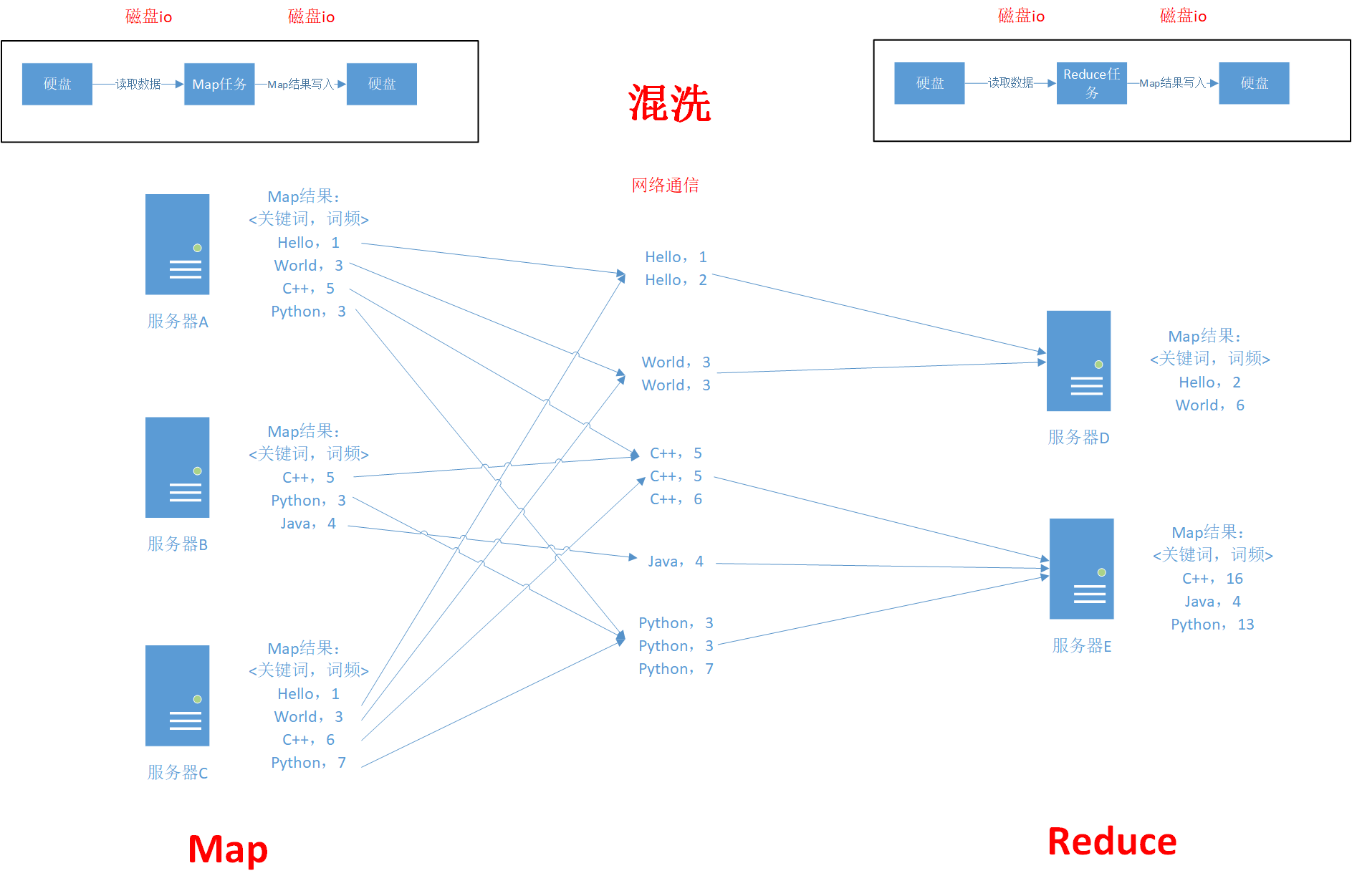
You can see that a MapReduce phase will go through at least two network IO+N network communications, which are also two main time-consuming tasks. Especially for neural network or graph computing, which requires frequent iteration, it will involve a lot of disk IO and network communication.
Spark improves this by using DAG graph and memory calculation.
DAG directed acyclic graph
When referring to DAG directed acyclic graph, we need to first mention its basic constituent element RDD, also known as elastic distributed data set. It will summarize and abstract the data files of all intermediate links in a unified way, so that all map s and reduce can be connected more smoothly. In the specific Spark development process, it is the description information of disk data. When an action operation is encountered, Spark will calculate the data according to the information in RDD.
There are two main operations in RDD: conversion and action. The transformation operation will start to build DAG directed acyclic graph between multiple RDDS, which describes the association relationship between RDDS. If so, we will read from the text file readme Read data from MD and create readme_rdd, this is the first node of a directed acyclic graph. Then we add a line to find the word "Python" in the file, and we will convert readme_rdd into python_rdd.
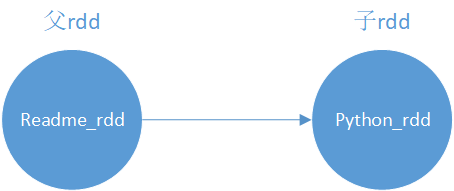
However, we should keep in mind that rdd is evaluated lazily. Transformation only records the operation relationship of data, and does not really perform operations. As for why, spark can combine some operations to reduce the steps of calculating data. If we start the action operation of rdd, spark will really execute according to the contents of this DAG.
Note:
However, MapReduce is not completely replaced by spark because of the memory capacity problem. Spark may not handle some problems properly
spark environment construction
Use the following command to download and build the spark environment
wget --no-check-certificate https://dlcdn.apache.org/spark/spark-3.2.0/spark-3.2.0-bin-hadoop3.2.tgz tar zxvf spark-3.2.0-bin-hadoop3.2.tgz
Then you can use it directly
Note:
spar k needs to run in the jvm environment, so jdk1.0 is required Above version 8
Spark Development
Using pyspark
We can directly call pyspark provided by spark to execute the statement, which will initialize a SparkContext object sc by default, and we can directly call its method to create rdd.
./bin/pyspark
lines = sc.textFile("README.md")
lines.count()
If we want to write a python script to operate spark, we need to use the spark submit component provided by spark:
./bin/spark-submit test.py
python
Spark initialization
To use Spark in python, you need to configure SparkConf, which mainly focuses on two parameters: the Url of the Spark cluster and the name of the driver service.
from pyspark import SparkConf, rdd
from pyspark.context import SparkContext
# spark configuration
conf = SparkConf().setMaster("local").setAppName("app")
Then you can create a SparkContext object based on this SparkConf. With this RDD, we can create an RDD and perform a series of operations.
sc = SparkContext(conf=conf)
Create RDD
There are three main input sources for RDD:
- Local file system
file = sc.textFile("file:[Absolute path]")
Alternatively, we can directly use relative paths to create RDD S as in the following example:
lines = sc.textFile("README.md")
- Amazon S3
To access S3 data in Spark, you must first set the S3 access credentials to AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY environment variable
file = sc.textFile("s3n:[Absolute path]")
- HDFS
file = sc.textFile("hdfs://[ip:port] / [absolute path] ")
Of course, in addition to reading from disk, it can also convert the data in memory into RDD:
memory_rdd = sc.parallelize(["pandas","china","Chinese","chinese food"])
Data reading and saving
The creation of RDD must be inseparable from data reading. It can be read in the following file formats:
- text file
- JSON
- SequenceFile
- protobuf
At present, only the first two common file formats are introduced.
text file
For local text files, we can directly use the just textFile. At the same time, pyspark also supports us to operate the entire folder. It will read the entire folder, then create it with the file name as the Key and the file content as the Value, and enter RDD. Here is an example:
Read directory,This will form key value pairs<file name,File content>
dir_rdd = sc.wholeTextFiles("file:///home/ik/software/spark/python_demo")
print(dir_rdd.keys().collect()) # Output key
The output is as follows:
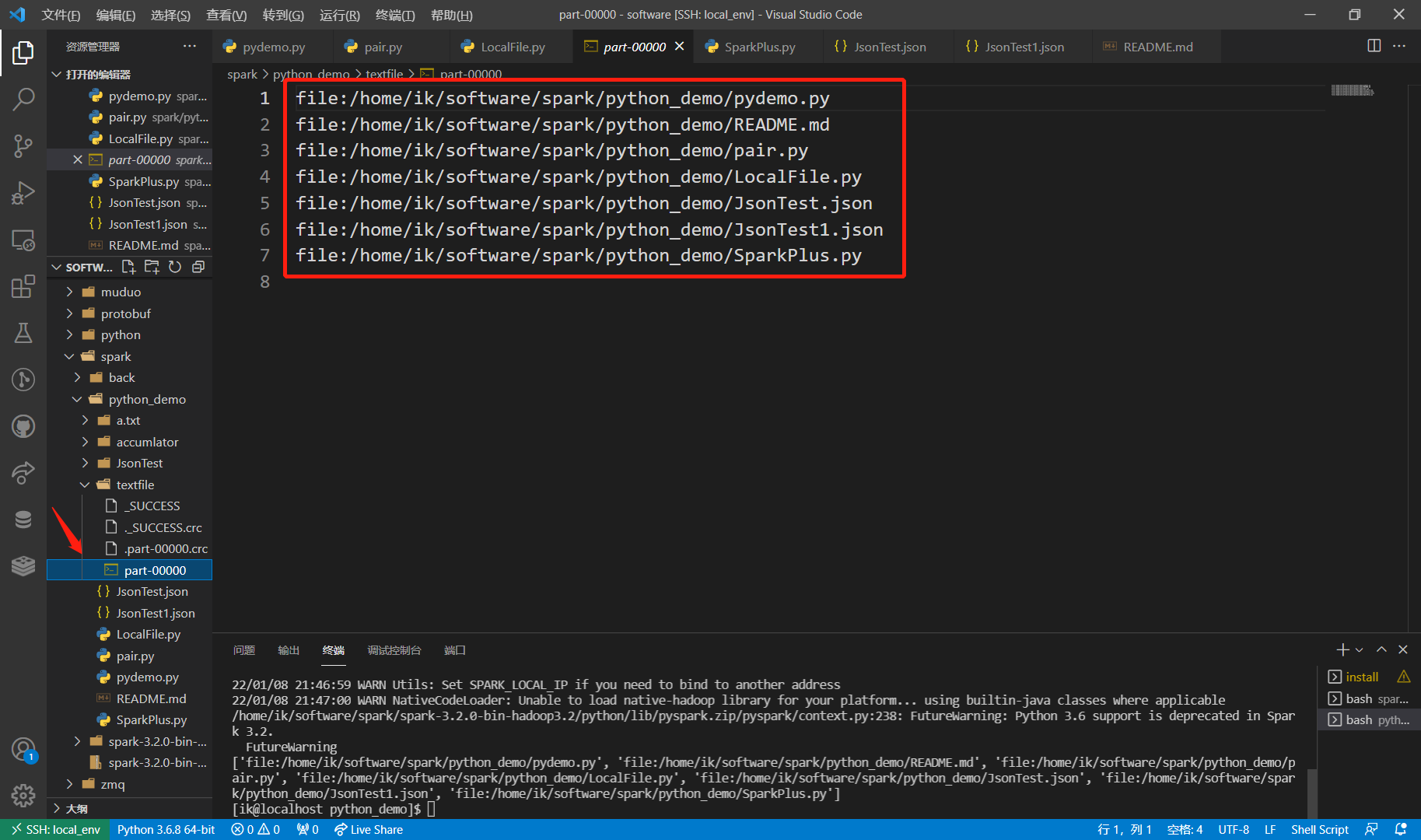
['file:/home/ik/software/spark/python_demo/pydemo.py', 'file:/home/ik/software/spark/python_demo/README.md', 'file:/home/ik/software/spark/python_demo/pair.py', 'file:/home/ik/software/spark/python_demo/LocalFile.py', 'file:/home/ik/software/spark/python_demo/JsonTest.json', 'file:/home/ik/software/spark/python_demo/JsonTest1.json', 'file:/home/ik/software/spark/python_demo/SparkPlus.py']
It is consistent with the following results, but it will not recursively read the contents of the folder.
To save a file is to call the saveAsTextFile method, which will create a directory under the path.
dir_rdd.keys().saveAsTextFile("file:///home/ik/software/spark/python_demo")
There will be four files in this directory, and the file indicated by the red arrow is the content of the file.
Json file
The interface of the Json file is essentially consistent with the text file, but we need to call the Python loader.
json_rdd = sc.textFile("file:///home/ik/software/spark/python_demo/JsonTest1.json")
data = json_rdd.map(lambda x:json.loads(x))
print(data.collect())
RDD conversion operation
RDD is read-only, so its conversion operation is actually to extract some data from the parent RDD and form a new RDD after conversion. This mainly involves two methods: map and filter.
- map: receive a function, use this function for each element of RDD, and take the return result of the function as the value of the element in RDD
nums = sc.parallelize([1,2,3,4,5])
for number in nums.map(lambda x:x*x).collect():
print(number)
- Filter: receive a function to filter the data in RDD
python_line = lines.filter(lambda line:"Python" in line) print(python_line.first())
- flatmap: it also receives a function, but it divides the original element into two elements according to the function rules
sentence = sc.parallelize(["hello world","hi world"])
words = sentence.flatMap(lambda line:line.split(" "))
print(words.collect()) # ['hello', 'world', 'hi', 'world']
RDD actions
Action operation will really trigger Spark operation, mainly through the following methods:
- Count: returns the count result
lines = sc.textFile("README.md")
print(lines.count())
- take: it receives an integer operation that represents extracting several elements from the RDD. Then we can print these elements
# take get 10 data
rdd_set = python_line.take(10)
for line in rdd_set:
print(line)
- collect: it will get all the elements in the RDD, but note that if the object is too large, the memory will explode
# Transfer function, mainly filter
def filter_func(lines):
return "Python" in lines
python_line2 = lines.filter(filter_func)
for line in python_line2.collect():
print(line)
Collection operation
Collection operations are mainly as follows, so I won't introduce them more:
rdd1 = sc.parallelize([1,3,5,7,9,1]) rdd2 = sc.parallelize([2,4,6,8,1]) # distinct de duplication print(rdd1.distinct().collect()) # The intersection runtime returns only duplicate elements print (rdd1.intersection(rdd2).collect()) # A subtract returns an element that exists only in the first rdd but not in the second rdd print(rdd1.subtract(rdd2).collect()) # cartesian calculation of cartesian product print(rdd1.cartesian(rdd2).collect())
mysql read
# mysql configuration (to be modified)
prop = {'user': 'xxx',
'password': 'xxx',
'driver': 'com.mysql.cj.jdbc.Driver'}
# database address (need to be modified)
url = 'jdbc:mysql://host:port/database'
# Read table
data = spark.read.jdbc(url=url, table='tb_newCity', properties=prop)
# Print data type
print(type(data))
# Display data
data.show()
# Close spark session
spark.stop()