Spring Boot JPA
preface
The full name of JPA is Java Persistence API, that is, Java Persistence API. It is a set of ORM based specifications launched by SUN company. It is internally composed of a series of interfaces and abstract classes. JPA describes the mapping relationship between object and relational table through JDK 5.0 annotation, and persistes the entity object in runtime to the database.
Spring Boot Jpa is a set of Jpa application framework encapsulated by spring based on ORM framework and Jpa specification, which enables developers to access and operate data with minimal code.
1, Overview
JPA features:
- Standardization
JPA is one of the Java EE standards issued by JCP organization
- Support for container level features
The JPA framework supports container level transactions such as large data sets, transactions and concurrency
- Simple and convenient
One of the main goals of JPA is to provide a simpler programming model
- Query capability
JPA's query language is object-oriented rather than database oriented
- Advanced features
JPA can support advanced object-oriented features, such as inheritance between classes, polymorphism and complex relationships between classes
2, Spring datajpa uses
1 - Basic CRUD
Operation steps:
- Inherit JpaRepository
public interface UserMapper extends JpaRepository<User, Long> {
}
- Using dao operations
findOne(id) : according to id query save(customer):Save or update (basis: whether the transferred entity class object contains id Properties) delete(id) : according to id delete findAll() : Query all
2 - basic query
1. Query the method defined by the interface in spring data JPA
That is, the query method contained in the JpaRepository
Paging query
Spring Boot Jpa has helped us realize the function of paging. In the query method, we need to pass in the parameter Pageable.
Page<User> findALL(Pageable pageable); and Page<User> findByUserName(String userName,Pageable pageable);
Restricted query
Query the first N elements
User findTopByOrderByAgeDesc(); Page<User> queryFirst10ByLastname(String lastname, Pageable pageable);
2. Query by jpql
Query statement using jpql
//@Query uses jpql to query.? 1 represents the placeholder of the parameter, where 1 corresponds to the parameter index in the method
@Query(value="from Customer where custName = ?1") public Customer findCustomer(String custName);
3.SQL statement query
Use * * @ Query annotation on the Query method of SQL. If it involves deletion and modification, add @ Modifying You can also add @ Transactional support for transactions * * as needed.
/** * nativeQuery : Query using local sql */ @Query(value="select * from cst_customer",nativeQuery=true) public void findSql();
4. Method naming rule query
You can complete the query by defining the name of the method according to the method naming rules provided by Spring Data JPA. Spring Data JPA will resolve according to the method name during program execution, and automatically generate query statements for query.
According to the rules defined by Spring Data JPA, the query method starts with findBy. When conditional query is involved, the attributes of the condition are connected with conditional keywords. It should be noted that the initial letter of the condition attribute should be capitalized. When the framework resolves the method name, it first intercepts the redundant prefix of the method name, and then resolves the rest.
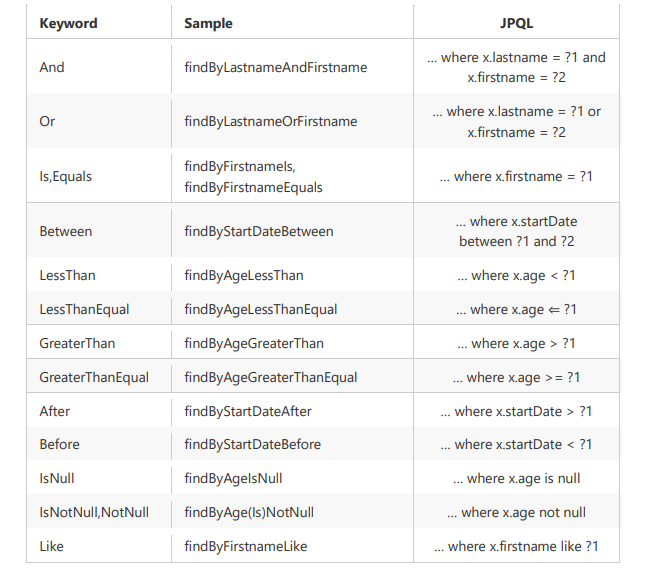
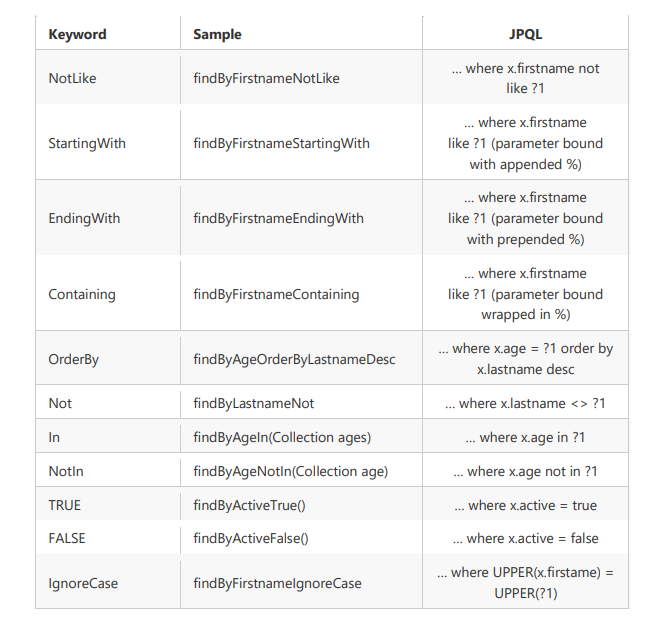
3- Specifications dynamic query
The DAO layer needs to inherit the JpaSpecificationExecutor interface and query through the method of this interface.
@Test
public void testSpecifications () {
//Using anonymous inner classes, create an implementation class of Specification and implement the toPredicate method
Specification<Customer> spec = new Specification<Customer>() {
public Predicate toPredicate(Root<Customer> root, CriteriaQuery<?> query,
CriteriaBuilder cb) {
//cb: build query and add query method like: fuzzy matching
// Represents a top-level query object, which is used to customize the query
//root: query from the entity Customer object according to the custName attribute
return cb.like(root.get("custName").as(String.class), "Intelligence Podcast%");
}
};
Customer customer = customerDao.findOne(spec);
System.out.println(customer);
}
4 - multi table query
There are three entity relationships in the system: many to many, one to many and one to one.
One to many
One to many relationship between customers and contacts
Customer (1) -- LinkMan (multiple)
Customer entity class:
//Configure one to many relationships between customers and contacts @OneToMany(targetEntity=LinkMan.class) @JoinColumn(name="lkm_cust_id",referencedColumnName="cust_id") private Set<LinkMan> linkmans = new HashSet<LinkMan>(0);
LinkMan entity class:
//Many to one relationship mapping: multiple contacts correspond to the customer @ manytoone (targetentity = customer. Class) @ joincolumn (name = "lkm_cust_id", referencedcolumnname = "cust_id") private customer;
@OneToMany:
- Function: establish one to many relationship mapping
- Properties:
- targetEntityClass: Specifies the bytecode of a multi-party class
- mappedBy: Specifies the name of the primary table object referenced from the table entity class.
- Cascade: Specifies the cascade operation to use
- fetch: Specifies whether to use deferred loading
- orphanRemoval: use orphan removal
@ManyToOne
- Function: establish many to one relationship
- Properties:
- targetEntityClass: Specifies the bytecode of one party's entity class
- Cascade: Specifies the cascade operation to use
- fetch: Specifies whether to use deferred loading
- Optional: whether the association is optional. If set to false, there must always be a non empty relationship.
@JoinColumn
- Function: used to define the correspondence between primary key fields and foreign key fields.
- Properties:
- Name: Specifies the name of the foreign key field
- referencedColumnName: Specifies the name of the primary key field that references the primary table
- Unique: whether it is unique. The default value is not unique
- nullable: whether null is allowed. The default value is allowed.
- insertable: whether to allow insertion. The default value is allowed.
- updatable: whether updates are allowed. The default value is allowed.
- columnDefinition: the definition information of the column.
Many to many
A user can have multiple roles
A role also has multiple users
user
//Many to many mapping @ manytomany (mappedby = "users") private set < sysrole > roles = new HashSet < sysrole > (0);
role
//Many to many relational mapping@ ManyToMany@JoinTable(name = "user_role_rel", / / the name of the intermediate table / / the user_role_rel field of the intermediate table is associated with the primary key field of sys_role table role_id joincolumns = {@ joincolumn (name = "role_id", referencedcolumnname = "role_id")}, / / the intermediate table user_ role_ Rel fields are associated with sys_ Primary key of user table user_ id inverseJoinColumns = {@JoinColumn(name = "user_id", referencedColumnName = "user_id")})private Set<SysUser> users = new HashSet<SysUser>(0);
@ManyToMany
- Function: used to map many to many relationships
- Properties:
- cascade: configure cascading operations.
- fetch: configure whether to use delayed loading.
- targetEntity: configure the entity class of the target. No need to write when mapping many to many.
@JoinTable
- Function: used to configure intermediate tables
- Properties:
- Name: the name of the configuration intermediate table
- joinColumns: the foreign key field of the intermediate table is associated with the primary key field of the table corresponding to the current entity class
- inverseJoinColumn: the foreign key field of the intermediate table is associated with the primary key field of the opposite table
3, Other
1 - support for multiple data sources
Multi source support of homologous database
Because of the distributed development mode used in daily projects, different services have different data sources, and it is often necessary to use multiple data sources in a project. Therefore, it is necessary to configure Spring Boot Jpa to use multiple data sources, which is generally divided into three steps:
- 1 configure multiple data sources
- 2. Put different entity classes into different package paths
- 3 declare that different data sources and transaction support are used under different package paths
Heterogeneous database multi-source support
For example, in our project, we need both mysql support and Mongodb query.
Entity class declares @ entity relational database support type and @ Document as Mongodb support type. Different data sources can use different entities
interface PersonRepository extends Repository<Person, Long> { ...}@Entitypublic class Person { ...}interface UserRepository extends Repository<User, Long> { ...}@Documentpublic class User { ...}
However, if the User uses both Mysql and Mongodb, it can also be mixed
interface JpaPersonRepository extends Repository<Person, Long> { ...}interface MongoDBPersonRepository extends Repository<Person, Long> { ...}@Entity@Documentpublic class Person { ...}
You can also declare different package paths, such as MySQL under package A and MongoDB under package B
@EnableJpaRepositories(basePackages = "com.neo.repositories.jpa")@EnableMongoRepositories(basePackages = "com.neo.repositories.mongo")interface Configuration { }
2 - use enumeration
When using enumeration, we want to store the string type corresponding to enumeration in the database instead of the index value of enumeration. We need to add @ Enumerated(EnumType.STRING) annotation on the attribute
@Enumerated(EnumType.STRING) @Column(nullable = true)private UserType type;
3 - attributes that do not need to be mapped to the database
Under normal circumstances, when we add the annotation @ Entity on the Entity class, we will associate the Entity class with the table. If one of the attributes does not need to be associated with the database, we only need to add the @ Transient attribute during display.
@Transientprivate String userName;
Reference or related articles
http://www.ityouknow.com/springboot/2016/08/20/spring-boot-jpa.html