Multimodal emotion analysis -- Introduction to text classification
Environment: Python 3.8
CSDN training data address: still under review.
gitee address: https://gitee.com/huadeng863/text-classification-practice
There are two versions. One has not been run. You can run it for experience. Generally, a py file needs to run for 5-6 minutes.
Another is to complete the preprocessing. You can understand the actual operation of natural language processing according to the screenshot of the article.
For convenience, the article is immediately divided into several parts to explain.
Step 1: divide the training set and test set (chosen. Py)
All the data has been put into the data folder. There are nine categories of news text under the data folder,

In each news category, there are all his news samples. A news is a separate txt file, and the files are marked with serial numbers.

Through statistics of all data samples:
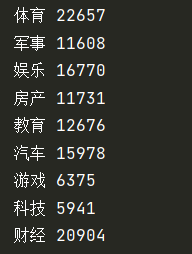
It can be found that the samples are unevenly distributed. In order to ensure that the training model will not bias to a certain classification, it is necessary to ensure that the number of training samples of different classifications is the same. Therefore, finally, 5000 samples are randomly selected from each classification. Finally, the training set and test set are divided by 8:2.
The implementation code and comments are as follows:
import os
import random
import shutil
path='./data/'
cate_list = os.listdir(path) # Get all categories in unclassified word library
for mydir in cate_list:
train_dir = './train_corpus/' + mydir + "/" # Spell out the corresponding directory path of training set storage, such as train_corpus / Sports/
if not os.path.exists(train_dir): # Whether there is a word segmentation directory. If not, create it
os.makedirs(train_dir)
test_dir = './test_corpus/' + mydir+'/' # Spell out the corresponding directory path of test storage, such as test_corpus / Sports/
if not os.path.exists(test_dir):
os.makedirs(test_dir)
class_path=path+mydir+'/' # Generate a directory of the current category, such as data / sports/
file_list=os.listdir(class_path) # Generate text name list under category
length=len(file_list)
print(mydir,length)
res = random.sample(range(1, length+1), 5000) #Randomly select 5000 from all files to generate an index list in disorder
train=res[0:4000]#Training sets account for 80%, 4000
test=res[4000:5000]#Test sets account for 20%, 1000
#print(len(train),len(test))
for file_path in file_list:
fullname = class_path + file_path # Spell out the full path of the file name, such as data / sports / 21.txt
#print(file_path)
x=int(file_path.split('.')[0].split('_')[1])#Remove the serial number from the file name
if x in train:
shutil.copyfile(fullname, train_dir+file_path)#Copy the previous file to the following directory
if x in test:
shutil.copyfile(fullname, test_dir + file_path)
Before executing the selected.py file partition:

After partition, the data file is divided into two parts (training set and test set):
Step 2: corpus_segment.py
The jieba Library of word segmentation has been introduced before, so you can start directly.
The implementation code and comments are as follows:
import os
import jieba
from Tools import savefile, readfile
def corpus_segment(corpus_path, seg_path):
catelist = os.listdir(corpus_path) # Get all subdirectories under corpus_path
#print(catelist)
'''
The name of the subdirectory is the class alias, for example:
train_corpus/Sports/21.txt In,'train_corpus/'yes corpus_path,'Sports'yes catelist A member of
'''
# Get all files under each directory (category)
for mydir in catelist:
class_path = corpus_path + mydir + "/" # Spell out the path of the classification subdirectory, such as train_corpus / sports/
seg_dir = seg_path + mydir + "/" # Spell out the path of the classification and segmentation directory, such as train_seg / sports/
if not os.path.exists(seg_dir): # Is there a word segmentation directory
os.makedirs(seg_dir) #If not, create the directory
file_list = os.listdir(class_path) # Get all text in a category in the unclassified word library
for file_path in file_list: # Traverse all files in the category directory
fullname = class_path + file_path # Spell out the full path of the file name, such as train_corpus/art/21.txt
content = readfile(fullname) # Read file contents
'''At this point, content It stores all the characters of the original text, such as redundant spaces, empty lines, carriage return, etc,
Next, we need to remove all these irrelevant characters and turn them into compact text content separated by punctuation
In order to ensure the reading speed of a large number of texts, Tools Encapsulated readfiles by rb Method, that is, binary reading and writing, so it needs to be converted to'utf-8'code
'''
content = content.replace('\r\n'.encode('utf-8'), ''.encode('utf-8')).strip() # Delete newline
content = content.replace(' '.encode('utf-8'), ''.encode('utf-8')).strip() # Delete empty lines and extra spaces
content_seg =jieba.cut(content) # Word segmentation for file content
savefile(seg_dir + file_path, ' '.join(content_seg).encode('utf-8')) # Save the processed file to the corpus directory after word segmentation
if __name__ == "__main__":
seg_path = "./train_corpus_seg/"#Corpus storage path after word segmentation
corpus_path = "./train_corpus/"#Corpus path requiring word segmentation
corpus_segment(corpus_path, seg_path)
print("Training corpus word segmentation is over!!!")
seg_path = "./test_corpus_seg/" # Corpus storage path after word segmentation
corpus_path = "./test_corpus/" # Corpus path requiring word segmentation
corpus_segment(corpus_path, seg_path)
print("Test corpus word segmentation ends!!!")
Before word segmentation of corpus_segment.py.py file:
After word segmentation (put the training and test corpus into seg folder after word segmentation):
Step 3: bunch operation (corpus2Bunch.py)
In essence, the data type of Bunch is dict dictionary type. Here, in order to facilitate processing, the classification category, file name, path and file content (segmented words) of each text are converted into dictionary types for subsequent processing.
The implementation code and comments are as follows:
import os
import pickle
from sklearn.datasets._base import Bunch
from Tools import readfile
def corpus2Bunch(wordbag_path, seg_path):
catelist = os.listdir(seg_path) # Get all subdirectories under seg_path, that is, classification information
# Create a Bunch instance
bunch = Bunch(target_name=[], label=[], filenames=[], contents=[])
bunch.target_name.extend(catelist)
'''
extend(addlist)yes python list The function in means to use the new list(addlist)To expand
customary list
'''
# Get all files in each directory
for mydir in catelist:
class_path = seg_path + mydir + "/" # Spell out the path of the classification subdirectory
file_list = os.listdir(class_path) # Get all files under class_path
for file_path in file_list: # Traverse files under category directory
fullname = class_path + file_path # Spell out the full path of the file name
bunch.label.append(mydir)
bunch.filenames.append(fullname)
bunch.contents.append(readfile(fullname)) # Read file contents
'''append(element)yes python list The function in means to the original list Add in element,Attention and extend()Difference between functions'''
# Store bunch in wordbag_path
with open(wordbag_path, "wb") as file_obj:
pickle.dump(bunch, file_obj)
print("End of building text object!!!")
if __name__ == "__main__":
# Bunch the training set:
wordbag_path = "train_word_bag/train_set.dat" # Bundle storage path
if not os.path.exists("train_word_bag"): # Whether there is a word segmentation directory. If not, create it
os.makedirs("train_word_bag")
seg_path = "train_corpus_seg/" # Corpus path after word segmentation
corpus2Bunch(wordbag_path, seg_path)
# Bunch the test set:
wordbag_path = "test_word_bag/test_set.dat" # Bundle storage path
if not os.path.exists("test_word_bag"): # Whether there is a word segmentation directory. If not, create it
os.makedirs("test_word_bag")
seg_path = "test_corpus_seg/" # Corpus path after word segmentation
corpus2Bunch(wordbag_path, seg_path)
Before executing corpus2Bunch.py:

After bunch, there are two more word bag folders, in which all training sets and test sets are stored in one dat file, which is convenient for subsequent processing
Step 4: build TF-IDF vector space (TFIDF_space.py)
This step includes de stop words, feature engineering and feature selection. The theory of this part was briefly introduced in the previous article, and this method has been encapsulated in python's sklearn.
The implementation code and comments are as follows:
from sklearn.datasets._base import Bunch
from sklearn.feature_extraction.text import TfidfVectorizer
from Tools import readfile, readbunchobj, writebunchobj
def vector_space(stopword_path, bunch_path, space_path, train_tfidf_path=None):
stpwrdlst = readfile(stopword_path).splitlines()
bunch = readbunchobj(bunch_path)
tfidfspace = Bunch(target_name=bunch.target_name, label=bunch.label, filenames=bunch.filenames, tdm=[],
vocabulary={})
if train_tfidf_path is not None:
trainbunch = readbunchobj(train_tfidf_path)
tfidfspace.vocabulary = trainbunch.vocabulary
vectorizer = TfidfVectorizer(stop_words=stpwrdlst, sublinear_tf=True, max_df=0.5,
vocabulary=trainbunch.vocabulary)
'''
#. stop_words=list type, filter the specified stop words directly.
# sublinear_tf: the sublinear strategy is used to calculate TF. For example, we used to calculate TF as word frequency, but now we use 1+log(tf) as word frequency.
#Max_df, filter the words that appear in sentences with a proportion of more than max_df=0.5. When the frequency of their appearance in the full-text file is more than 50%, we think they are too common and unrepresentative
# . vocabulary: dict type. Only specific words are used. In order to avoid trouble caused by words that do not appear in the training set in the test set, this is generally used, but it can not be used if the training set is large enough
'''
tfidfspace.tdm = vectorizer.fit_transform(bunch.contents)
else:
vectorizer = TfidfVectorizer(stop_words=stpwrdlst, sublinear_tf=True, max_df=0.5)
'''
#. stop_words=list type, filter the specified stop words directly.
# sublinear_tf: the sublinear strategy is used to calculate TF. For example, we used to calculate TF as word frequency, but now we use 1+log(tf) as word frequency.
# Max_df, filter the words that appear in sentences with a proportion of more than max_df=0.5. When the frequency of their appearance in the full-text file is more than 50%, we think they are too common and unrepresentative
'''
tfidfspace.tdm = vectorizer.fit_transform(bunch.contents)
tfidfspace.vocabulary = vectorizer.vocabulary_
writebunchobj(space_path, tfidfspace)
print("if-idf Word vector space instance created successfully!!!")
if __name__ == '__main__':
stopword_path = "hit_stopwords.txt"
bunch_path = "train_word_bag/train_set.dat"
space_path = "train_word_bag/tfdifspace.dat"
vector_space(stopword_path, bunch_path, space_path)
bunch_path = "test_word_bag/test_set.dat"
space_path = "test_word_bag/testspace.dat"
train_tfidf_path = "train_word_bag/tfdifspace.dat"
vector_space(stopword_path, bunch_path, space_path, train_tfidf_path)
After execution, TF-IDF vector space instances will be generated in the corresponding word bag file, which will not be displayed if it is too troublesome.
Step 5: Training Model
The encapsulated Library in sklearn can be called directly.
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import MultinomialNB # Polynomial Bayesian algorithm
from sklearn import metrics
from Tools import readbunchobj
import os
# Import training set
trainpath = "train_word_bag/tfdifspace.dat"
train_set = readbunchobj(trainpath)
# Import test set
testpath = "test_word_bag/testspace.dat"
test_set = readbunchobj(testpath)
# Training classifier: input word bag vector and classification label. Alpha: 0.001. The smaller the alpha, the more iterations and the higher the accuracy
clf = MultinomialNB(alpha=0.001).fit(train_set.tdm, train_set.label)
#clf = LogisticRegression(C=1000.0).fit(train_set.tdm, train_set.label)
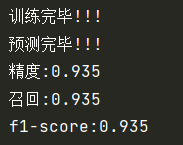
print("Training completed!!!")
# Forecast classification results
predicted = clf.predict(test_set.tdm)
print("Prediction completed!!!")
# Calculation classification accuracy:
def metrics_result(actual, predict):
print('accuracy:{0:.3f}'.format(metrics.precision_score(actual, predict, average='weighted')))
print('recall:{0:0.3f}'.format(metrics.recall_score(actual, predict, average='weighted')))
print('f1-score:{0:.3f}'.format(metrics.f1_score(actual, predict, average='weighted')))
metrics_result(test_set.label, predicted)
The previous theory introduced naive Bayes model, but at this step, it is found that the compatibility between naive Bayes and TF-IDF is not good, at least logistic regression is more suitable than him. But at this point, I don't want to change the model. Try the Bayesian effect first.

Let's look at the effect of logistic regression:
A complete failure in accuracy. But you will find that Bayesian runs much faster than logistic regression, although accuracy is the king.