python crawler batch download pictures
preface
This article takes downloading coin pictures in Bing as an example to realize python crawler search and batch downloading pictures.
The following is the main body of this article.
1, Specific process
1. Search for pictures with Bing
Like the novel download in the previous article, first we need to view the HTML of the search page. As shown on the right side of the figure below, 'murl' is the URL corresponding to the first figure.
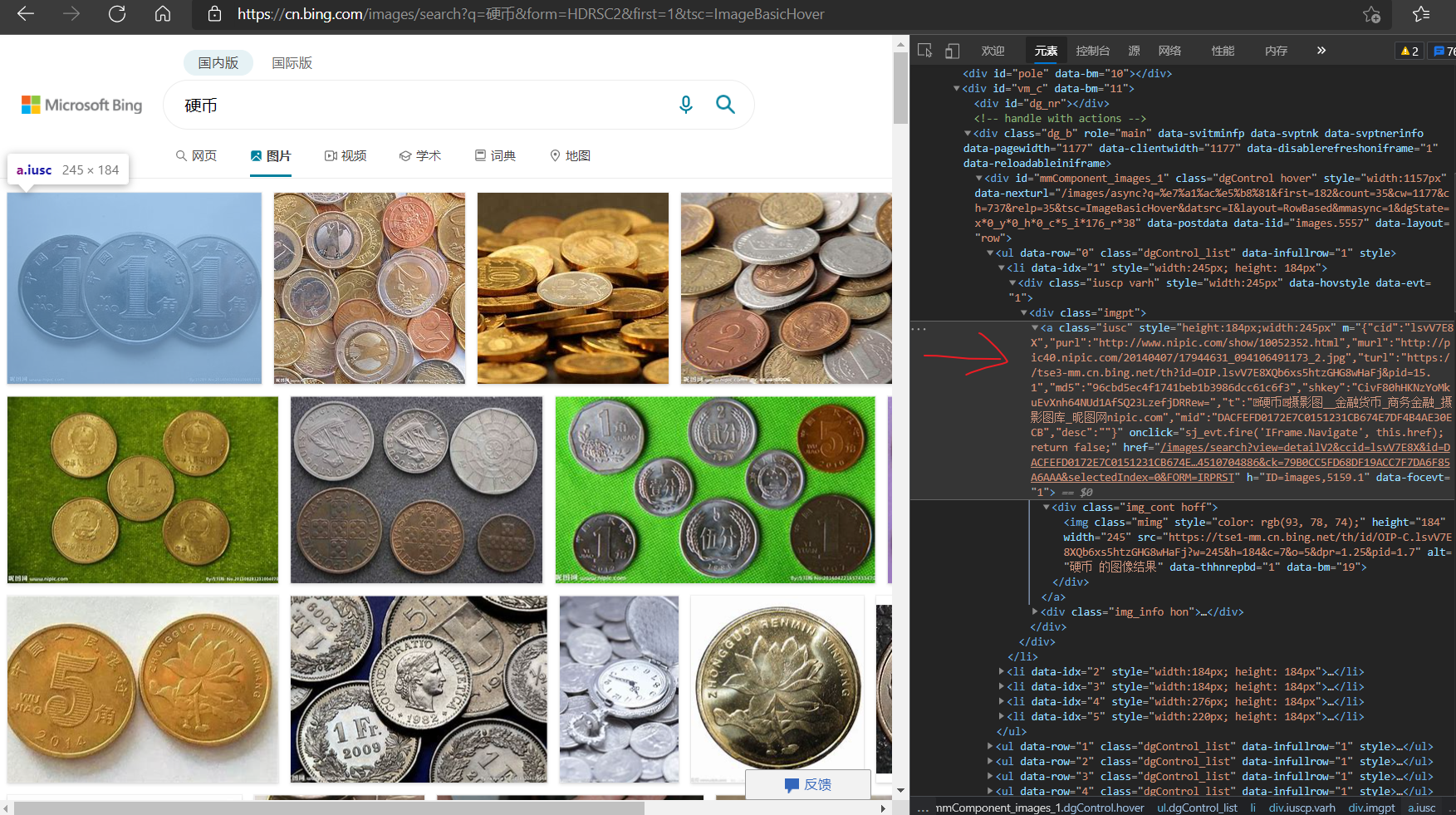
However, when we pull down the page, we can find that the web address in the content has changed from the content in the position shown in the figure below to the above figure.

Copy the URL and prefix it https://cn.bing.com , after entering the website, we can try to delete some things we don't need (we can delete them one by one, and judge whether they can be deleted according to the changes of the deleted page)“ https://cn.bing.com/images/async?q= Coin & first = 292 & count = 35 & CW = 1177 & ch = 737 & RELP = 35 & TSC = imagebasichover & datsrc = I & layout = rowbased & mmasync = 1 & dgstate = x440_ y1152_ h180_ c2_ i281_ R60 "becomes“ https://cn.bing.com/images/async?q= Coin & first = 1 & count = 35 & CW = 1177 & ch = 737 & RELP = 35 & TSC = imagebasichover & datsrc = I & layout = rowbased & mmasync = 1 ". The change is shown in the figure below. It can also be found that the page can be switched by changing first.

On this page, we can still find the URL corresponding to the picture. Then, similar to the method of downloading novels before, you can download pictures in batches.

2. Implementation method
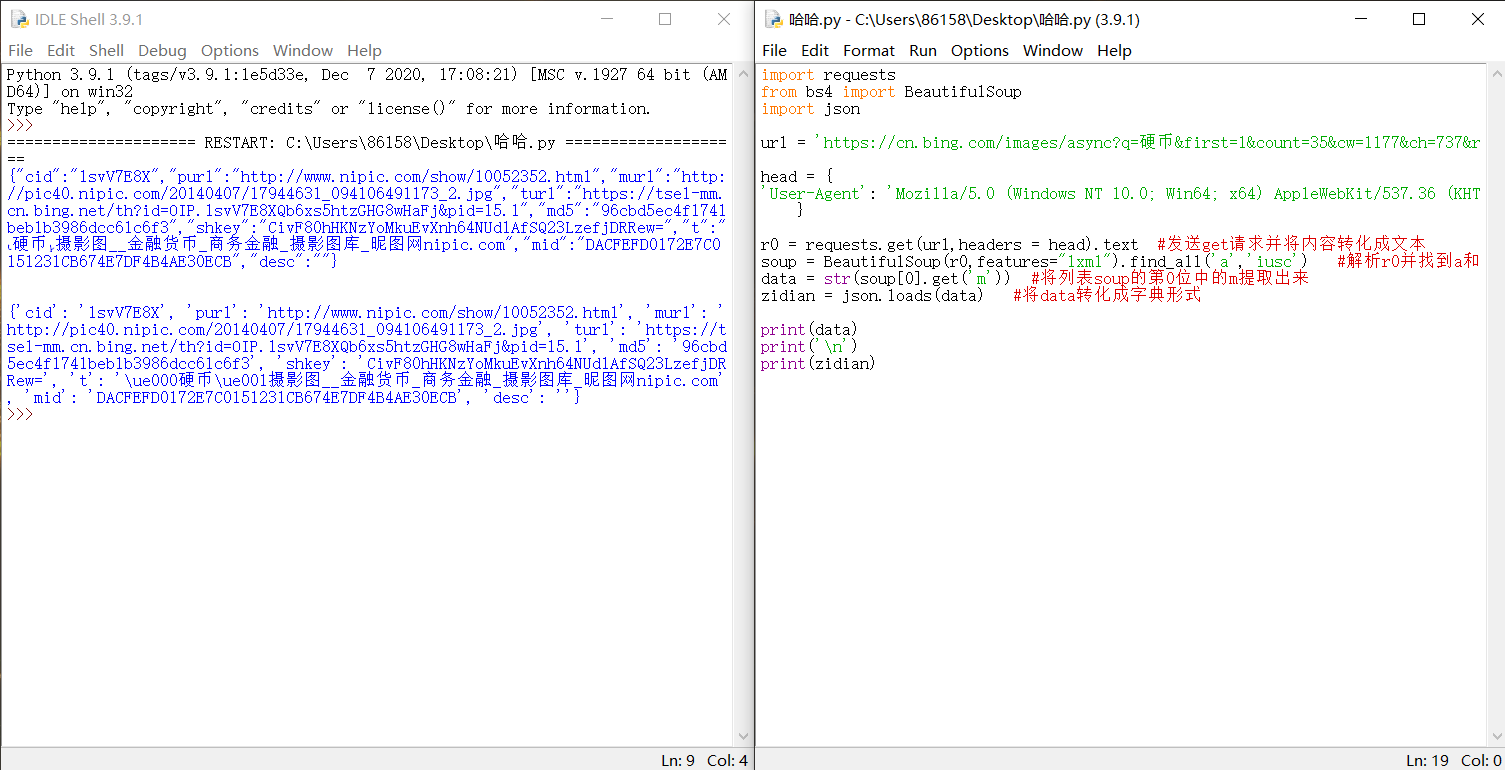
Overall idea: first, send get requests and use find through the requests and beautiful soup modules used in the previous article_ All find the method of the corresponding label, get the content of the label where the picture URL is located in the URL above, and then extract the "m =..." in it. Then extract the "murl" of the corresponding picture URL from the extracted content, and then send a get request and write its binary data to XX Jpg.
The implementation method of the first half is similar to that of the previous article. The "murl" in the second half is the content in the json string, which can be transformed into dictionary form through the json module.
import requests
from bs4 import BeautifulSoup
import json
url = 'https://cn.bing.com/images/async?q = Coin & first = 1 & count = 35 & CW = 1177 & ch = 737 & RELP = 35 & TSC = imagebasichover & datsrc = I & layout = rowbased & mmasync = 1 '
head = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.64'
}
r0 = requests.get(url,headers = head).text #Send a get request and convert the content to text
soup = BeautifulSoup(r0,features="lxml").find_all('a','iusc') #Parse r0 and find the tags for a and class=iusc
data = str(soup[0].get('m')) #Extract the m in bit 0 of the list soup
zidian = json.loads(data) #Convert data into dictionary form
print(data)
print('\n')
print(zidian)
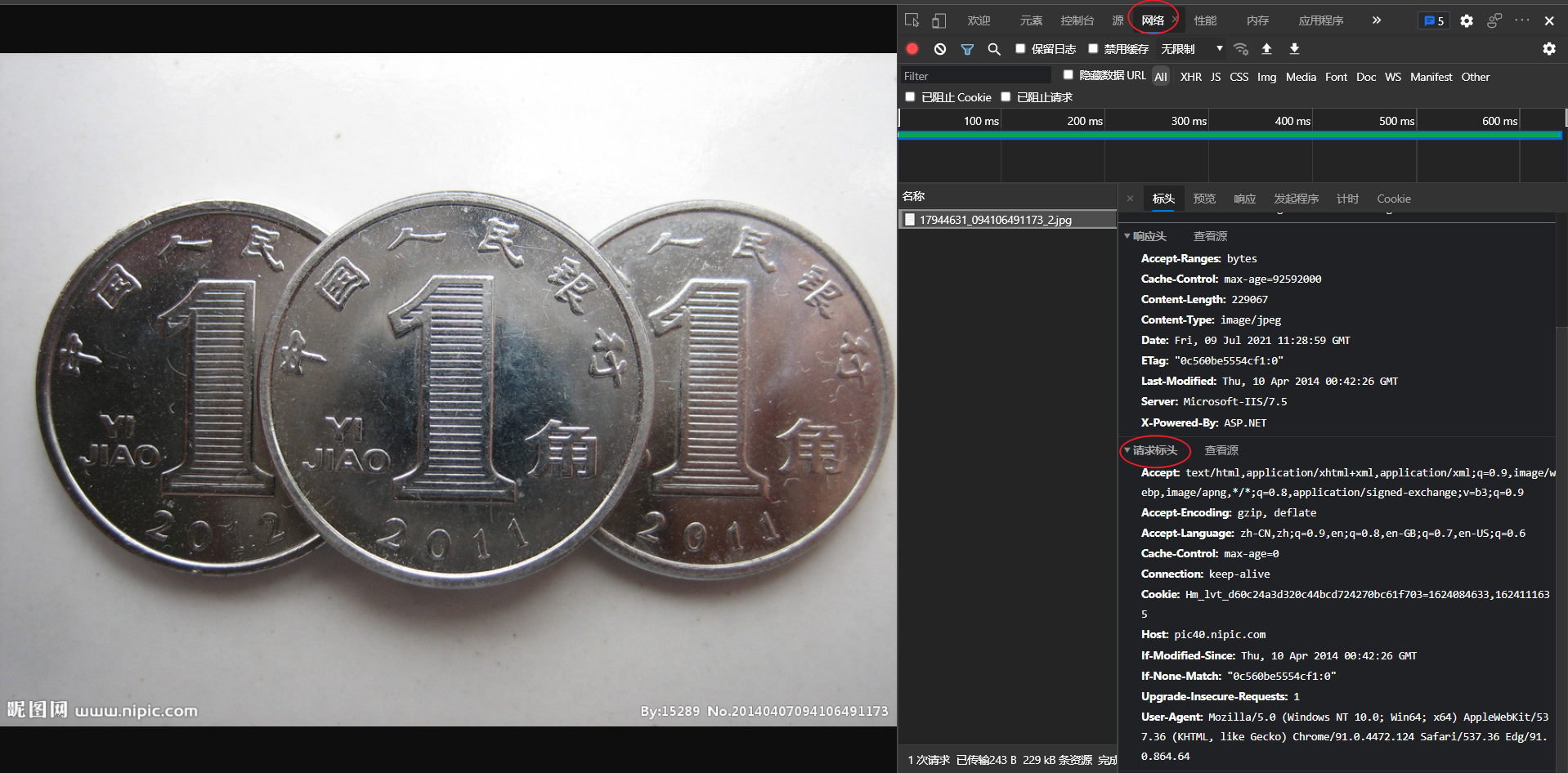
Where head is the request header content of the web address. Similarly, the URL corresponding to the following image also has its corresponding request header. Right click to check, click the network, and then refresh the page to see the request header shown in the figure below. The murl corresponding website is“ http://pic40.nipic.com/20140407/17944631_094106491173_2.jpg "(although the binary data of the picture can also be obtained without the request header here)
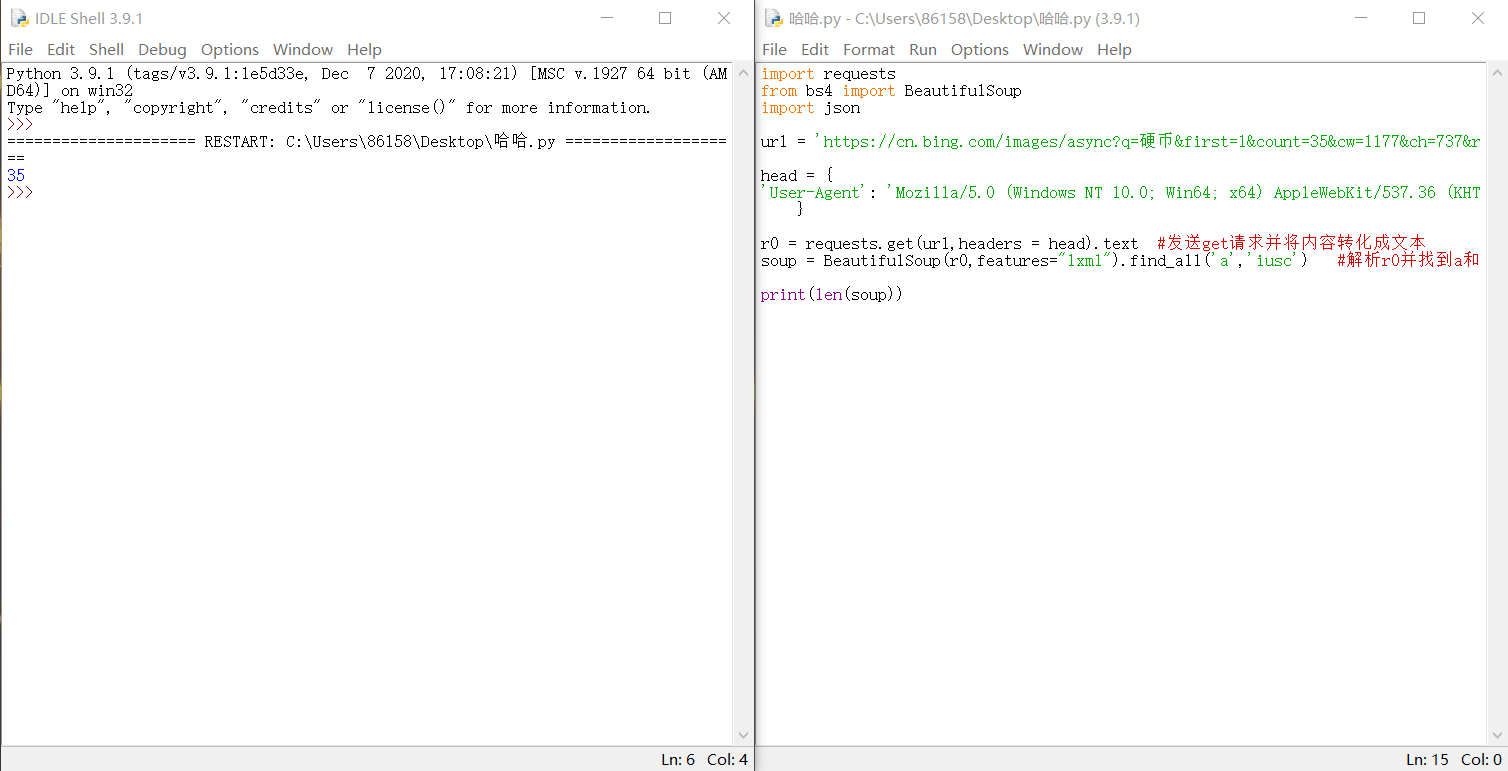
There are 35 picture pages. You can judge the number of pictures by len (). Of course, you can also count them one by one. The effect is the same.
Import module
import requests from bs4 import BeautifulSoup import json import eventlet import os
You can use the pip method to install the corresponding library before importing
pip install xxx
The eventlet module is used to determine whether the access timed out, as shown below
with eventlet.Timeout(1,False): #Set the timeout judgment of 1 second
try:
picture = requests.get(url).content
except:
print('Picture timeout exception') #Description picture exception
If it exceeds 1 second, the content of except will be run.
Specific code
The specific code is as follows. This code will create a folder named "pictures" in its directory, and then download the corresponding content and number of pictures to the "pictures" folder through the search content and number of search pictures entered by the user. (provided that there is no folder named "pictures" in this directory)
import requests
from bs4 import BeautifulSoup
import json
import eventlet
import os
urlshu = 1 #first = urlshu in url
pictureshu = 1 #The name of the picture when downloading (plus the first picture of the abnormal picture)
soupshu = 0 #The soupshu in every 35 soups list
whileshu = 35 #Number of while loops (because there are 35 pictures per page)
os.mkdir('C:/tu/picture') #Create folder 'pictures'
url1 = 'https://cn.bing.com/images/async?q='
url2 = '&first=%d&count=35&cw=1177&ch=737&relp=35&tsc=ImageBasicHover&datsrc=I&layout=RowBased&mmasync=1'
head1 = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.64'
}
#Request header for a web page with 35 pictures
head2 = {
'Cookie': 'Hm_lvt_d60c24a3d320c44bcd724270bc61f703=1624084633,1624111635',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.64'
}
#The request header of the page for the specific picture
print('Please enter the search content:')
content = input()
print('Please enter the number of pictures to find:')
number = int(input())
url = url1 + content + url2 #Merge into a website with 35 pictures
while whileshu:
r0 = requests.get(url%urlshu,headers = head1).text #Send a get request and convert the content to text
soup = BeautifulSoup(r0,features="lxml").find_all('a','iusc') #Parse r0 and find the tags for a and class=iusc
data = str(soup[soupshu].get('m')) #Extract the m in the soupshu bit of the list soup
zidian = json.loads(data) #Convert data to dictionary form
ifopen = 1 #It is used to determine whether to download pictures below
with eventlet.Timeout(1,False): #Set the timeout judgment of 1 second
try:
picture = requests.get(zidian['murl'],headers = head2).content #Send get request and return binary data
except:
print('picture%d Timeout exception'%pictureshu) #Description picture exception
ifopen = 0 #Cancel downloading this picture, otherwise it will be stuck all the time and an error will be reported
while ifopen == 1:
text = open('picture/' + '%d'%pictureshu + '.jpg','wb') #Download pictures to the folder 'pictures'
text.write(picture) #'wb' in the uplink code is written binary data
text.close()
ifopen = 0
number = number - 1
pictureshu = pictureshu + 1
soupshu = soupshu + 1
whileshu = whileshu - 1
if whileshu == 0: #After downloading the first page image, enter the first of the website into 1
urlshu = urlshu + 1
whileshu = 35
soupshu = 0
if number == 0: #If the number of downloaded pictures reaches the standard, exit the cycle
break
2, Effect demonstration
python crawler batch download pictures
I am a student and am currently studying. This article is also my study note. Please correct me if there are any mistakes.