This paper mainly introduces the common locks and the underlying analysis of synchronized, NSLock, recursive lock and conditional lock
lock
Refer to the performance data comparison diagram of a lock, as shown below
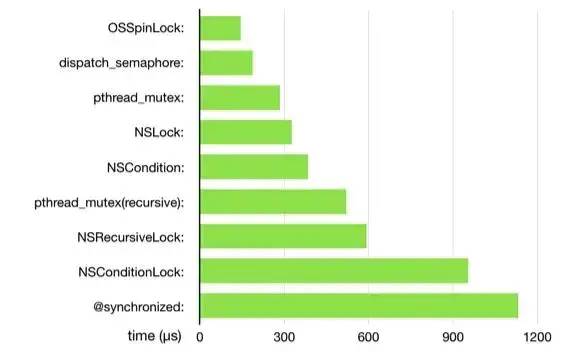
Lock performance comparison
It can be seen that the lock performance in the figure is from high to low: osspinlock - > dispatch_ Semaphone - > pthread_ Mutex - > nslock - > nscondition - > pthread_ Mutex - > ns recursive lock - > nsconditionlock - > synchronized
Locks in the figure are roughly divided into the following categories:
-
[1. Spin lock]: in spin lock, the thread will repeatedly check whether the variable is available. Because the thread keeps executing consistently in this process, it is a busy wait. Once the spin lock is acquired, the thread holds the lock until the spin lock is explicitly released. Spin locking avoids the scheduling overhead of process context, so it is effective when threads will only block for a short time. For the modifier atomic of iOS attribute, it comes with a spin lock
-
OSSpinLock
-
atomic
-
-
[2. Mutex]: mutex is a mechanism used in multithreaded programming to prevent two threads from reading and writing the same common resource (such as global variable) at the same time. This purpose is achieved by cutting the code into critical areas
-
@synchronized
-
NSLock
-
pthread_mutex
-
-
[3. Condition lock]: condition lock is a condition variable. When some resource requirements of the process are not met, it enters sleep, that is, it is locked. When resources are allocated, the condition lock is opened and the process continues to run
-
NSCondition
-
NSConditionLock
-
-
[4. Recursive lock]: recursive lock means that the same thread can be locked N times without causing deadlock. Recursive lock is a special mutex, that is, a mutex with recursive nature
-
pthread_mutex(recursive)
-
NSRecursiveLock
-
-
[5. Semaphore]: semaphore is a more advanced synchronization mechanism. Mutex lock can be said to be a special case of semaphore when it only takes 0 / 1. Semaphore can have more value space to realize more complex synchronization, not just mutex between threads
-
dispatch_semaphore
-
-
[6. Read / write lock]: read / write lock is actually a special spin lock. The access to shared resources is divided into readers and writers. Readers only read and access shared resources, while writers need to write to shared resources. This phase lock can improve the concurrency of spin lock
-
A read-write lock can only have one writer or multiple readers at the same time, but it cannot have both readers and writers. It is also preemptive and invalid during the retention of the read-write lock
-
If the read-write lock currently has no reader or writer, the writer can obtain the read-write lock immediately, otherwise it must spin there until there is no writer or reader. If there is no writer in the read-write lock, the reader can stand
-
In fact, the basic locks include three types: spin lock, mutex lock and read-write lock. Other locks, such as conditional lock, recursive lock and semaphore, are encapsulated and implemented by the upper layer.
1. OSSpinLock (spin lock)
Since there was a security problem with OSSpinLock, it was abandoned after iOS10. The reason why spin locks are unsafe is that after obtaining the lock, the thread will always be busy waiting, resulting in the reversal of the priority of the task.
The busy waiting mechanism may cause high priority tasks to be running and waiting all the time, occupying time slices, while low priority tasks cannot seize time slices, resulting in failure to complete all the time and the lock is not released
After OSS pinlock is discarded, its alternative is to internally encapsulate the os_unfair_lock, and os_unfair_lock will be in the sleep state when locking, rather than the busy state of spin lock
2. Atomic (atomic lock)
atomic is applicable to the modifier of attributes in OC. It comes with a spin lock, but it is generally not used. It is nonatomic
In the previous article, we mentioned that the setter method will call different methods according to the modifier. Finally, the reallySetProperty method will be called uniformly, including atomic and non atomic operations
static inline void reallySetProperty(id self, SEL _cmd, id newValue, ptrdiff_t offset, bool atomic, bool copy, bool mutableCopy)
{
...
id *slot = (id*) ((char*)self + offset);
...
if (!atomic) {//Unlocked
oldValue = *slot;
*slot = newValue;
} else {//Lock
spinlock_t& slotlock = PropertyLocks[slot];
slotlock.lock();
oldValue = *slot;
*slot = newValue;
slotlock.unlock();
}
...
}
As can be seen from the source code, spinlock is used for the attributes modified by atomic_ T lock processing, but the OSSpinLock mentioned earlier has been abandoned. Here is spinlock_t at the bottom is through os_unfair_lock replaces the locking implemented by OSSpinLock. At the same time, in order to prevent hash conflict, salt adding operation is used
using spinlock_t = mutex_tt<LOCKDEBUG>;
class mutex_tt : nocopy_t {
os_unfair_lock mLock;
...
}
The processing of atomic in getter method is roughly the same as that of setter
id objc_getProperty(id self, SEL _cmd, ptrdiff_t offset, BOOL atomic) {
if (offset == 0) {
return object_getClass(self);
}
// Retain release world
id *slot = (id*) ((char*)self + offset);
if (!atomic) return *slot;
// Atomic retain release world
spinlock_t& slotlock = PropertyLocks[slot];
slotlock.lock();//Lock
id value = objc_retain(*slot);
slotlock.unlock();//Unlock
// for performance, we (safely) issue the autorelease OUTSIDE of the spinlock.
return objc_autoreleaseReturnValue(value);
}
3. synchronized (mutually exclusive recursive lock)
-
Start assembly debugging and find that @ synchronized will use the underlying objc during execution_ sync_ enter and objc_sync_exit method
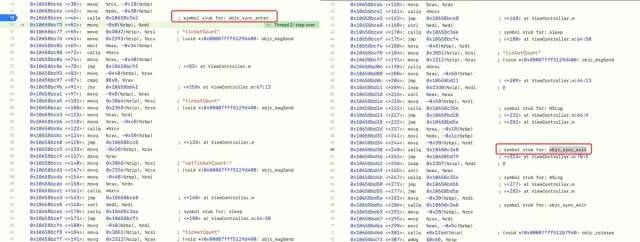
-
You can also view the underlying compiled code through clang
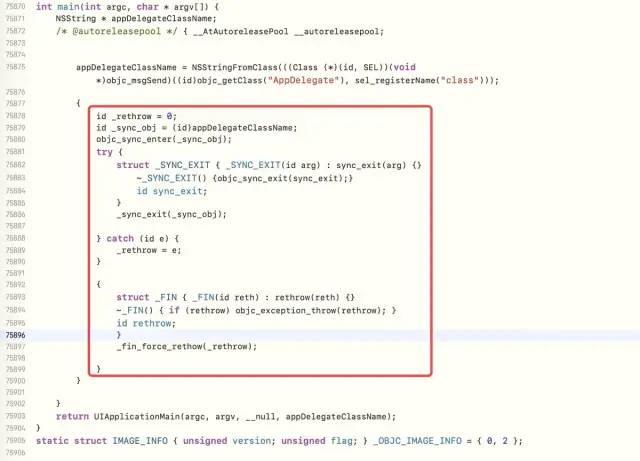
Through objc_sync_enter method symbol breakpoints, check the source code library where the underlying layer is located, and find the breakpoints in the objc source code, namely libobjc.A.dylib
objc_ sync_ enter & objc_ sync_ Exit analysis
-
Enter objc_ sync_ Implementation of enter source code
-
If obj exists, obtain the corresponding SyncData through id2data method and increment threadCount and lockCount
-
If obj does not exist, call objc_sync_nil, you can know from the symbolic breakpoint that nothing has been done in this method. You can return it directly
-
int objc_sync_enter(id obj)
{
int result = OBJC_SYNC_SUCCESS;
if (obj) {//Incoming is not nil
SyncData* data = id2data(obj, ACQUIRE);//a key
ASSERT(data);
data->mutex.lock();//Lock
} else {//Incoming nil
// @synchronized(nil) does nothing
if (DebugNilSync) {
_objc_inform("NIL SYNC DEBUG: @synchronized(nil); set a breakpoint on objc_sync_nil to debug");
}
objc_sync_nil();
}
return result;
}
-
Enter objc_sync_exit source code implementation
-
If obj exists, call id2data method to obtain the corresponding SyncData and decrement threadCount and lockCount
-
If obj is nil, do nothing
-
// End synchronizing on 'obj'
// Returns OBJC_SYNC_SUCCESS or OBJC_SYNC_NOT_OWNING_THREAD_ERROR
int objc_sync_exit(id obj)
{
int result = OBJC_SYNC_SUCCESS;
if (obj) {//obj is not nil
SyncData* data = id2data(obj, RELEASE);
if (!data) {
result = OBJC_SYNC_NOT_OWNING_THREAD_ERROR;
} else {
bool okay = data->mutex.tryUnlock();//Unlock
if (!okay) {
result = OBJC_SYNC_NOT_OWNING_THREAD_ERROR;
}
}
} else {//When obj is nil, do nothing
// @synchronized(nil) does nothing
}
return result;
}
Through the comparison of the above two implementation logics, it is found that they have one thing in common. When obj exists, they will obtain SyncData through id2data method
-
The definition of SyncData is a structure, which is mainly used to represent a thread data. It is similar to a linked list structure, has a next point, and encapsulates recursive_mutex_t attribute, you can confirm that @ synchronized is indeed a recursive mutex
typedef struct alignas(CacheLineSize) SyncData {
struct SyncData* nextData;//Similar to linked list structure
DisguisedPtr<objc_object> object;
int32_t threadCount; // number of THREADS using this block
recursive_mutex_t mutex;//Recursive lock
} SyncData;
-
Entering the definition of SyncCache is also a structure used to store threads, where list[0] represents the linked list data of the current thread, which is mainly used to store SyncData and lockCount
typedef struct {
SyncData *data;
unsigned int lockCount; // number of times THIS THREAD locked this block
} SyncCacheItem;
typedef struct SyncCache {
unsigned int allocated;
unsigned int used;
SyncCacheItem list[0];
} SyncCache;
id2data analysis
-
Enter the id2data source code. From the above analysis, it can be seen that this method is a reuse method of locking and unlocking
static SyncData* id2data(id object, enum usage why)
{
spinlock_t *lockp = &LOCK_FOR_OBJ(object);
SyncData **listp = &LIST_FOR_OBJ(object);
SyncData* result = NULL;
#if SUPPORT_DIRECT_THREAD_KEYS //tls (Thread Local Storage)
// Check per-thread single-entry fast cache for matching object
bool fastCacheOccupied = NO;
//Get the data bound by the thread through KVC
SyncData *data = (SyncData *)tls_get_direct(SYNC_DATA_DIRECT_KEY);
//If there is data in the thread cache, execute the if process
if (data) {
fastCacheOccupied = YES;
//If data is found in thread space
if (data->object == object) {
// Found a match in fast cache.
uintptr_t lockCount;
result = data;
//Obtain lockCount through KVC. lockCount is used to record how many times the lock has been locked, that is, the lock can be nested
lockCount = (uintptr_t)tls_get_direct(SYNC_COUNT_DIRECT_KEY);
if (result->threadCount <= 0 || lockCount <= 0) {
_objc_fatal("id2data fastcache is buggy");
}
switch(why) {
case ACQUIRE: {
//objc_sync_enter goes here, and the incoming is ACQUIRE -- get
lockCount++;//It is judged by lockCount that it has been locked several times, which means that it is reentrant (recursive lock will deadlock if it is reentrant)
tls_set_direct(SYNC_COUNT_DIRECT_KEY, (void*)lockCount);//set up
break;
}
case RELEASE:
//objc_sync_exit go here, and the incoming why is RELEASE -- RELEASE
lockCount--;
tls_set_direct(SYNC_COUNT_DIRECT_KEY, (void*)lockCount);
if (lockCount == 0) {
// remove from fast cache
tls_set_direct(SYNC_DATA_DIRECT_KEY, NULL);
// atomic because may collide with concurrent ACQUIRE
OSAtomicDecrement32Barrier(&result->threadCount);
}
break;
case CHECK:
// do nothing
break;
}
return result;
}
}
#endif
// Check per-thread cache of already-owned locks for matching object
SyncCache *cache = fetch_cache(NO);//Determine whether the thread exists in the cache
//If there is in the cache, the method is consistent with the thread cache
if (cache) {
unsigned int i;
for (i = 0; i < cache->used; i++) {//Traversal summary
SyncCacheItem *item = &cache->list[i];
if (item->data->object != object) continue;
// Found a match.
result = item->data;
if (result->threadCount <= 0 || item->lockCount <= 0) {
_objc_fatal("id2data cache is buggy");
}
switch(why) {
case ACQUIRE://Lock
item->lockCount++;
break;
case RELEASE://Unlock
item->lockCount--;
if (item->lockCount == 0) {
// Remove from per thread cache clears the usage mark from the cache
cache->list[i] = cache->list[--cache->used];
// atomic because may collide with concurrent ACQUIRE
OSAtomicDecrement32Barrier(&result->threadCount);
}
break;
case CHECK:
// do nothing
break;
}
return result;
}
}
// Thread cache didn't find anything.
// Walk in-use list looking for matching object
// Spinlock prevents multiple threads from creating multiple
// locks for the same new object.
// We could keep the nodes in some hash table if we find that there are
// more than 20 or so distinct locks active, but we don't do that now.
//The first time I came in, all the caches couldn't be found
lockp->lock();
{
SyncData* p;
SyncData* firstUnused = NULL;
for (p = *listp; p != NULL; p = p->nextData) {//Found in cache
if ( p->object == object ) {//If it is not equal to null and is similar to object
result = p;//assignment
// atomic because may collide with concurrent RELEASE
OSAtomicIncrement32Barrier(&result->threadCount);//For threadCount++
goto done;
}
if ( (firstUnused == NULL) && (p->threadCount == 0) )
firstUnused = p;
}
// no SyncData currently associated with object there is no SyncData associated with the current object
if ( (why == RELEASE) || (why == CHECK) )
goto done;
// an unused one was found, use it
if ( firstUnused != NULL ) {
result = firstUnused;
result->object = (objc_object *)object;
result->threadCount = 1;
goto done;
}
}
// Allocate a new SyncData and add to list.
// XXX allocating memory with a global lock held is bad practice,
// might be worth releasing the lock, allocating, and searching again.
// But since we never free these guys we won't be stuck in allocation very often.
posix_memalign((void **)&result, alignof(SyncData), sizeof(SyncData));//Create assignment
result->object = (objc_object *)object;
result->threadCount = 1;
new (&result->mutex) recursive_mutex_t(fork_unsafe_lock);
result->nextData = *listp;
*listp = result;
done:
lockp->unlock();
if (result) {
// Only new ACQUIRE should get here.
// All RELEASE and CHECK and recursive ACQUIRE are
// handled by the per-thread caches above.
if (why == RELEASE) {
// Probably some thread is incorrectly exiting
// while the object is held by another thread.
return nil;
}
if (why != ACQUIRE) _objc_fatal("id2data is buggy");
if (result->object != object) _objc_fatal("id2data is buggy");
#if SUPPORT_DIRECT_THREAD_KEYS
if (!fastCacheOccupied) { //Judge whether stack cache is supported. If yes, assign values in the form of KVC and store them in tls
// Save in fast thread cache
tls_set_direct(SYNC_DATA_DIRECT_KEY, result);
tls_set_direct(SYNC_COUNT_DIRECT_KEY, (void*)1);//lockCount = 1
} else
#endif
{
// Save in thread cache
if (!cache) cache = fetch_cache(YES);//The thread is bound the first time it is stored
cache->list[cache->used].data = result;
cache->list[cache->used].lockCount = 1;
cache->used++;
}
}
return result;
}
-
[step 1] first search in tls, i.e. thread cache.
-
If ACQUIRE indicates locking, lockCount + + is performed and saved to the tls cache
-
If RELEASE indicates RELEASE, lockCount -- is performed and saved to the tls cache. If lockCount be equal to 0, remove thread data from tls
-
If it is CHECK, do nothing
-
In tls_ get_ The direct method takes the thread as the key and obtains the SyncData bound to it through KVC, that is, thread data. tls () represents the local thread cache,
-
Judge whether the obtained data exists and whether the corresponding object can be found in the data
-
If it's all found, in TLS_ get_ In the direct method, the lockCount is obtained in the form of KVC to record how many times the object is locked (that is, the number of nested locks)
-
If threadCount in data Less than or equal to 0, or lockCount When less than or equal to 0, it will crash directly
-
Determine the operation type through the passed in why
-
-
Step 2: if there is no in the tls, look it up in the cache
-
Via fetch_ The cache method looks for threads in the cache
-
If so, traverse the cache master table and read out the SyncCacheItem corresponding to the thread
-
Take out data from SyncCacheItem, and the subsequent steps are consistent with the matching of tls
-
-
Step 3: if there is no SyncData in the cache, that is, if it comes in for the first time, create SyncData and store it in the corresponding cache
-
If a thread is found in the cache and is equal to the object, assign a value and threadCount++
-
If not found in the cache, threadCount is equal to 1
-
Therefore, the id2data method is mainly divided into three cases
-
[first time in, no lock]:
-
threadCount = 1
-
lockCount = 1
-
Store to tls
-
-
[it's not the first time to come in, and it's the same thread]
-
If there is data in tls, lockCount++
-
Store to tls
-
-
[it's not the first time to come in, and it's a different thread]
-
Find threads in global thread space
-
threadCount++
-
lockCount++
-
Store to cache
-
tls and cache table structure
For tls and cache caching, the underlying table structure is as follows
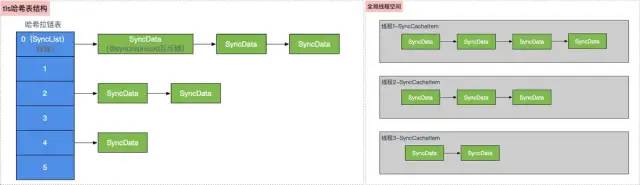
tls and cache structure
-
In the hash table structure, multithreading is assembled through the SyncList structure
-
SyncData assembles the current reentrant situation in the form of a linked list
-
The lower layer processes through tls thread cache and cache cache
-
There are two main things in the bottom layer: lockCount and threadCount, which solve the recursive mutual exclusion and nesting reentry
@synchronized pit
What's wrong with the following code?
- (void)cjl_testSync{
_testArray = [NSMutableArray array];
for (int i = 0; i < 200000; i++) {
dispatch_async(dispatch_get_global_queue(0, 0), ^{
@synchronized (self.testArray) {
self.testArray = [NSMutableArray array];
}
});
}
}
The running result shows that the running will crash
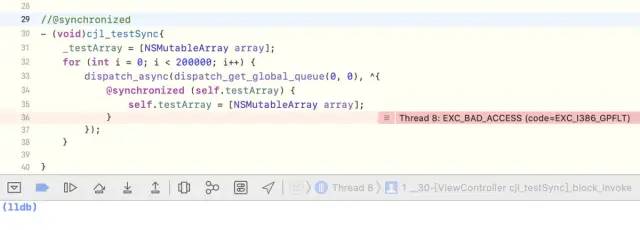
The main reason for the crash is that testArray becomes nil at a certain moment. According to the @ synchronized underlying process, if the locked object becomes nil, it cannot be locked. This is equivalent to the following situation. The non-stop retain and release inside the block will not be released at one moment and the next will be ready for release, which will lead to the generation of wild pointers
_testArray = [NSMutableArray array];
for (int i = 0; i < 200000; i++) {
dispatch_async(dispatch_get_global_queue(0, 0), ^{
_testArray = [NSMutableArray array];
});
}
According to the above code, open edit scheme - > Run - > diagnostics and check Zombie Objects , To see if it is a zombie object, the results are as follows
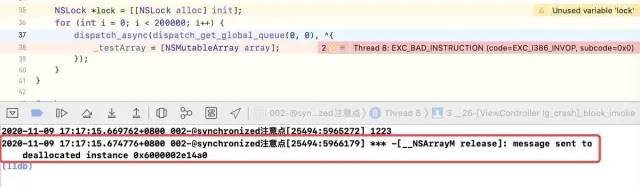
We generally use @ synchronized (self) because_ The holder of testArray is self
Note: Wild pointer vs transition release
-
Wild pointer: refers to the pointer still operating due to transition release
-
Transition release: retain and release each time
summary
-
@synchronized encapsulates a recursive lock at the bottom, so this lock is a recursive mutex
-
@synchronized reentrant can be nested, mainly due to lockCount and Collocation of threadCount
-
@The reason why synchronized uses the linked list is that the linked list facilitates the insertion of the next data,
-
However, the linked list query, cache lookup and recursion in the bottom layer consume a lot of memory and performance, resulting in low performance. Therefore, in the previous article, the lock ranks last
-
However, at present, the use frequency of the lock is still very high, mainly because it is convenient and simple without unlocking
-
A non OC object cannot be used as a locked object because its object parameter is id
-
@synchronized (self) is suitable for scenes with less nesting times. The locked object here is not always self, which needs readers' attention
-
If the number of lock nesting is too many, that is, the lock self is too much, it will lead to very troublesome searching at the bottom. Because the bottom layer is a linked list, it will be relatively troublesome. Therefore, NSLock and semaphore can be used at this time
4,NSLock
NSLock is for the underlying pthread_ The package of mutex is as follows
NSLock *lock = [[NSLock alloc] init]; [lock lock]; [lock unlock];
Go directly to the NSLock definition, which follows the NSLocking protocol. Let's explore the underlying implementation of NSLock
NSLock underlying analysis
-
Through the symbolic breakpoint lock analysis, it is found that its source code is in the Foundation framework,
Since the Foundation framework of OC is not open source, the underlying implementation of NSLock is analyzed with the help of Swift's open source framework Foundation, and its principle is roughly the same as that of OC
Through the source code implementation, we can see that the bottom layer is through pthread_mutex mutex. In addition, some other operations are done in the init method, so init initialization is required when using NSLock
Returning to the previous performance chart, we can see that the performance of NSLock is second only to pthread_mutex, very close
Abuse of use
What are the problems in the following nested block code?
for (int i= 0; i<100; i++) {
dispatch_async(dispatch_get_global_queue(0, 0), ^{
static void (^testMethod)(int);
testMethod = ^(int value){
if (value > 0) {
NSLog(@"current value = %d",value);
testMethod(value - 1);
}
};
testMethod(10);
});
}
-
Before locking, there are many items of current=9 and 10, resulting in data confusion, mainly due to multithreading
-
What's the problem if you lock it like this?
NSLock *lock = [[NSLock alloc] init];
for (int i= 0; i<100; i++) {
dispatch_async(dispatch_get_global_queue(0, 0), ^{
static void (^testMethod)(int);
testMethod = ^(int value){
[lock lock];
if (value > 0) {
NSLog(@"current value = %d",value);
testMethod(value - 1);
}
};
testMethod(10);
[lock unlock];
});
}
The operation results are as follows

This is mainly because of the recursion used in nesting and the use of NSLock (simple mutex lock. If you don't come back, you will sleep and wait all the time), that is, there will be a blocking situation of adding lock and waiting for unlock
Therefore, the following methods can be used to solve this situation
-
Use @ synchronized
for (int i= 0; i<100; i++) {
dispatch_async(dispatch_get_global_queue(0, 0), ^{
static void (^testMethod)(int);
testMethod = ^(int value){
@synchronized (self) {
if (value > 0) {
NSLog(@"current value = %d",value);
testMethod(value - 1);
}
}
};
testMethod(10);
});
}
-
Use recursive lock NSRecursiveLock
NSRecursiveLock *recursiveLock = [[NSRecursiveLock alloc] init];
for (int i= 0; i<100; i++) {
dispatch_async(dispatch_get_global_queue(0, 0), ^{
static void (^testMethod)(int);
[recursiveLock lock];
testMethod = ^(int value){
if (value > 0) {
NSLog(@"current value = %d",value);
testMethod(value - 1);
}
[recursiveLock unlock];
};
testMethod(10);
});
}
5,pthread_mutex
pthread_mutex is the mutex itself. When the lock is occupied and other threads apply for the lock, they will not be busy waiting, but block the thread and sleep
// Import header file #import <pthread.h> // Global declaration mutex pthread_mutex_t _lock; // Initialize mutex pthread_mutex_init(&_lock, NULL); // Lock pthread_mutex_lock(&_lock); // Thread safe operations are required here // Unlock pthread_mutex_unlock(&_lock); // Release lock pthread_mutex_destroy(&_lock);
6,NSRecursiveLock
NSRecursiveLock is also used for pthread at the bottom_ Mutex encapsulation can be viewed through the Foundation source code of swift
Compare NSLock and NSRecursiveLock, as like as two peas, is implemented at the bottom of the init. When the NSRecursiveLock is different, NSRecursiveLock has a logo. MUTEX_ Recursive, and NSLock is the default
Recursive lock is mainly used to solve a nested form, in which loop nesting is most common
7,NSCondition
NSCondition It is a condition lock, which is rarely used in daily development. It is somewhat similar to semaphores: thread 1 needs to meet condition 1 before going down, otherwise it will block and wait until the condition is met. The classic model is the production consumer model
The object of NSCondition actually acts as a lock And a Thread Checker
-
Lock is mainly used to protect the data source when detecting conditions and perform tasks caused by conditions
-
The Thread Checker mainly determines whether to continue running the thread according to conditions, that is, whether the thread is blocked
use
//initialization NSCondition *condition = [[NSCondition alloc] init] //It is generally used for multiple threads to access and modify the same data source at the same time to ensure that the data source is accessed and modified only once at the same time. The commands of other threads need to wait outside the lock and can only be accessed when they are unlock ed [condition lock]; //Use with lock [condition unlock]; //Keep the current thread waiting [condition wait]; //The CPU signals the thread to continue execution without waiting [condition signal];
Bottom analysis
View the underlying implementation of NSCondition through the Foundation source code of swift
open class NSCondition: NSObject, NSLocking {
internal var mutex = _MutexPointer.allocate(capacity: 1)
internal var cond = _ConditionVariablePointer.allocate(capacity: 1)
//initialization
public override init() {
pthread_mutex_init(mutex, nil)
pthread_cond_init(cond, nil)
}
//Deconstruction
deinit {
pthread_mutex_destroy(mutex)
pthread_cond_destroy(cond)
mutex.deinitialize(count: 1)
cond.deinitialize(count: 1)
mutex.deallocate()
cond.deallocate()
}
//Lock
open func lock() {
pthread_mutex_lock(mutex)
}
//Unlock
open func unlock() {
pthread_mutex_unlock(mutex)
}
//wait for
open func wait() {
pthread_cond_wait(cond, mutex)
}
//wait for
open func wait(until limit: Date) -> Bool {
guard var timeout = timeSpecFrom(date: limit) else {
return false
}
return pthread_cond_timedwait(cond, mutex, &timeout) == 0
}
//Signal indicating that the waiting can be executed
open func signal() {
pthread_cond_signal(cond)
}
//radio broadcast
open func broadcast() {
// Assembly analysis - guess (see more and play more)
pthread_cond_broadcast(cond) // wait signal
}
open var name: String?
}
The bottom layer is also the pthread of the lower layer_ Mutex packaging
-
NSCondition is an encapsulation of mutex and cond (cond is a pointer used to access and manipulate specific types of data)
-
The wait operation blocks the thread and puts it into sleep until it times out
-
The signal operation wakes up a dormant waiting thread
-
broadcast wakes up all waiting threads
8,NSConditionLock
NSConditionLock is a conditional lock. Once one thread obtains the lock, other threads must wait
Compared with NSConditionLock, the use of NSConditionLock is more troublesome, so it is recommended to use NSConditionLock as follows
//initialization NSConditionLock *conditionLock = [[NSConditionLock alloc] initWithCondition:2]; //Indicates that conditionLock expects to obtain the lock. If no other thread obtains the lock (it is not necessary to judge the internal condition), it can execute the following code in this line. If another thread already obtains the lock (it may be a conditional lock or an unconditional lock), it will wait until other threads unlock it [conditionLock lock]; //Indicates that if no other thread obtains the lock, but the condition inside the lock is not equal to condition A, it still cannot obtain the lock and still waits. If the internal condition is equal to condition A and no other thread obtains the lock, enter the code area and set it to obtain the lock. Any other thread will wait for the completion of its code until it is unlocked. [conditionLock lockWhenCondition:A condition]; //It means to release the lock and set the internal condition to A condition [conditionLock unlockWithCondition:A condition]; // Indicates that if it is locked (NO lock is obtained) and exceeds this time, the thread will NO longer be blocked. But note: the returned value is NO, which does not change the lock state. The purpose of this function is to realize the processing in two states return = [conditionLock lockWhenCondition:A condition beforeDate:A time]; //The so-called condition is an integer, which internally compares conditions through integers
NSConditionLock is essentially NSCondition + Lock. The following is the underlying implementation of its swift,
open class NSConditionLock : NSObject, NSLocking {
internal var _cond = NSCondition()
internal var _value: Int
internal var _thread: _swift_CFThreadRef?
public convenience override init() {
self.init(condition: 0)
}
public init(condition: Int) {
_value = condition
}
open func lock() {
let _ = lock(before: Date.distantFuture)
}
open func unlock() {
_cond.lock()
_thread = nil
_cond.broadcast()
_cond.unlock()
}
open var condition: Int {
return _value
}
open func lock(whenCondition condition: Int) {
let _ = lock(whenCondition: condition, before: Date.distantFuture)
}
open func `try`() -> Bool {
return lock(before: Date.distantPast)
}
open func tryLock(whenCondition condition: Int) -> Bool {
return lock(whenCondition: condition, before: Date.distantPast)
}
open func unlock(withCondition condition: Int) {
_cond.lock()
_thread = nil
_value = condition
_cond.broadcast()
_cond.unlock()
}
open func lock(before limit: Date) -> Bool {
_cond.lock()
while _thread != nil {
if !_cond.wait(until: limit) {
_cond.unlock()
return false
}
}
_thread = pthread_self()
_cond.unlock()
return true
}
open func lock(whenCondition condition: Int, before limit: Date) -> Bool {
_cond.lock()
while _thread != nil || _value != condition {
if !_cond.wait(until: limit) {
_cond.unlock()
return false
}
}
_thread = pthread_self()
_cond.unlock()
return true
}
open var name: String?
}
As can be seen from the source code
-
NSConditionLock is the encapsulation of NSCondition
-
NSConditionLock can set the lock condition, that is, the condition value, while NSCondition is only a signal notification
Debugging verification
Take the following code as an example to debug the underlying process of NSConditionLock
- (void)cjl_testConditonLock{
// Semaphore
NSConditionLock *conditionLock = [[NSConditionLock alloc] initWithCondition:2];
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_HIGH, 0), ^{
[conditionLock lockWhenCondition:1]; // Conditionoion = 1 internal Condition matching
// -[NSConditionLock lockWhenCondition: beforeDate:]
NSLog(@"Thread 1");
[conditionLock unlockWithCondition:0];
});
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_LOW, 0), ^{
[conditionLock lockWhenCondition:2];
sleep(0.1);
NSLog(@"Thread 2");
// self.myLock.value = 1;
[conditionLock unlockWithCondition:1]; // _value = 2 -> 1
});
dispatch_async(dispatch_get_global_queue(0, 0), ^{
[conditionLock lock];
NSLog(@"Thread 3");
[conditionLock unlock];
});
}
-
Set the response breakpoint in the conditionLock part and run it (it needs to be run on the real machine: Intel instructions are running on the simulator, and arm instructions are running on the real machine)
-
Disconnect and start assembly debugging
-
register read Read register, where x0 is the recipient self , x1 is cmd
-
In objc_ Add a breakpoint at msgsend and read register x0 again-- register read x0, and [conditionLock lockWhenCondition:2] is executed;
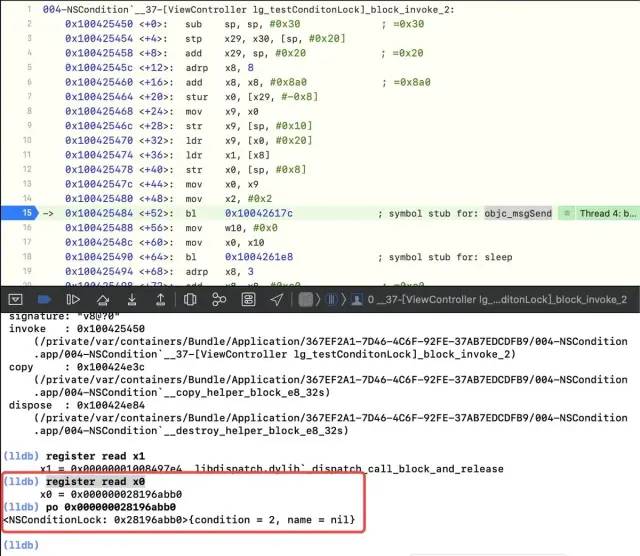
-
Read x1, i.e register read x1 , Then it is found that it cannot be read, because X1 stores SEL, not an object type, which can be read by forcibly converting to sel
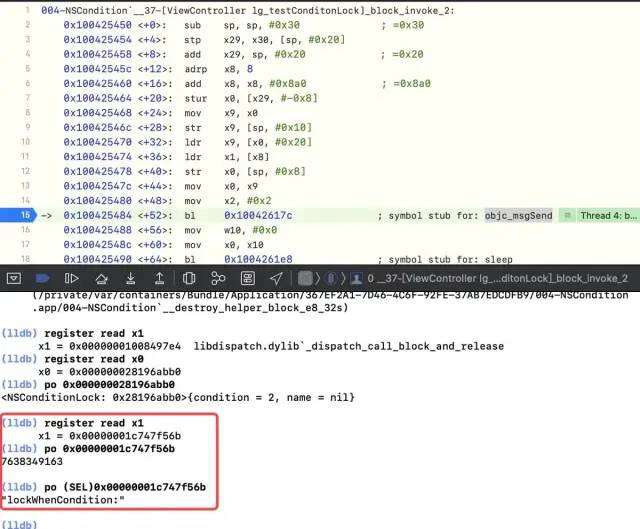
-
Sign breakpoints - [NSConditionLock lockWhenCondition:], - [NSConditionLock lockWhenCondition:beforeDate:], and then check the jump of bl, b, etc
-
The read registers x0 and x2 are the parameters of the current lockWhenCondition:beforeDate:, and the actual path is [conditionLock lockWhenCondition:1];
-
According to the compilation, x2 is moved to x21
After arriving here, we have two main debugging purposes: NSCondition + lock And condition matches the value of value
-
NSCondition + lock validation
-
Continue execution, disconnect at bl and read the register x0 , This is a jump to NSCondition
-
Read x1, i.e po (SEL)0x00000001c746e484
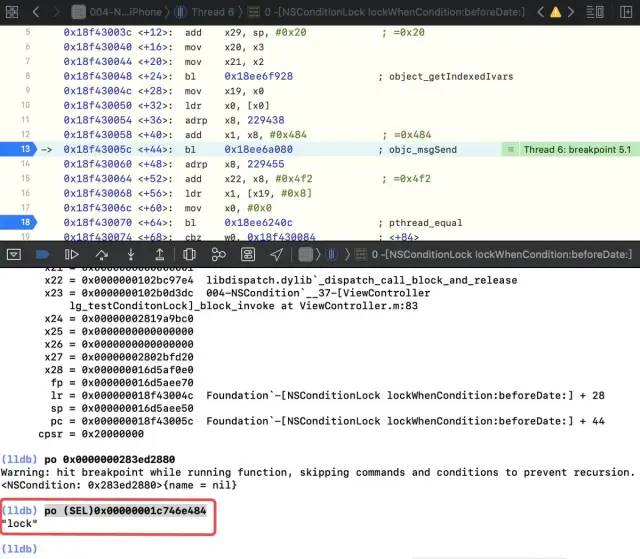
Therefore, it can be verified that NSConditionLock calls the lock method of NSCondition at the bottom
condition matches the value of value
-
Continue and skip to ldr , That is, the attribute value of condition 2 is obtained through a method and stored in x8
-
register read x19
-
Po (SEL) 0x0000000283d0d220 -- address of X19 + 0x10
-
register read x8. At this time, 2 is stored in x8
-
cmp x8, x21, which means that x8 and x21 are matched, that is, 2 and 1 are matched, but not matched
-
-
The second time you come to CMP x8 and x21, x8 and x21 are matched, that is [conditionLock lockWhenCondition:2];
 At this point, x8 and x21 match
At this point, x8 and x21 match
demo analysis summary
-
Thread 1 Call [NSConditionLock lockWhenCondition:] because the current condition is not met, it will enter the waiting state. When it enters the waiting state, it will release the current mutex.
-
At this time, the current thread 3 calls [NSConditionLock lock:], which essentially calls [NSConditionLock lockBeforeDate:]. There is no need to compare the condition values, so thread 3 will print
-
Next, thread 2 executes [NSConditionLock lockWhenCondition:] because the condition value is met, thread 2 will print. After printing, thread 2 will call [NSConditionLock unlockWithCondition:] at this time, set the value to 1 and send boradcast. At this time, thread 1 receives the current signal, wakes up execution and prints.
-
Currently printed as Thread 3 - > thread 2 - > thread 1
-
[NSConditionLock lockWhenCondition:]; Here will be based on the incoming Compare the condition value with the value value. If they are not equal, they will be blocked and enter the thread pool. Otherwise, continue code execution [NSConditionLock unlockWithCondition:]: change the current value first, and then broadcast to wake up the current thread
Performance summary
-
Because of security problems, the OSSpinLock spin lock has been abandoned after iOS10, and its underlying implementation uses os_unfair_lock substitution
-
When you use OSSpinLock and as shown in, you will be in a busy waiting state
-
And os_unfair_lock is dormant
-
-
Atomic atomic lock comes with a spin lock, which can only ensure thread safety when setter and getter are used. In daily development, nonatomic modification attributes are used more
-
atomic: when a property calls setter and getter methods, a spin lock osspinlock is added to ensure that only one thread can call the property to read or write at the same time, avoiding the problem of asynchronous property reading and writing. Because it is the mutex code automatically generated by the underlying compiler, it will lead to relatively low efficiency
-
nonatomic: when the property calls setter and getter methods, it will not add spin lock, that is, the thread is unsafe. Because the compiler does not automatically generate mutex code, it can improve efficiency
-
-
@synchronized maintains a hash table at the bottom to store thread data. It represents the reentrant (i.e. nested) feature through a linked list. Although the performance is low, it is easy to use and used frequently
-
The underlying layer of NSLock and NSRecursiveLock is pthread_mutex packaging
-
NSCondition and NSConditionLock are conditional locks, and the underlying layer is pthread_ The encapsulation of mutex, which can be operated only when a certain condition is met, and semaphore dispatch_ Similar to semaphore
Lock usage scenario
-
For simple use, such as thread safety, use NSLock
-
If it is circular nesting, @ synchronized is recommended, mainly because the performance of using recursive locks is not as good as that of using @ synchronized (because no matter how reentrant in synchronized, it doesn't matter, and NSRecursiveLock may crash)
-
In loop nesting, if you have a good grasp of recursive locks, it is recommended to use recursive locks because of good performance
-
In case of loop nesting and multithreading effects, such as waiting and deadlock, it is recommended to use @ synchronized