Recently, many insertBatch codes have been written in new projects. It has been said that batch insertion is much more efficient than circular insertion. This paper will experiment. Is it true?
Test environment:
- SpringBoot 2.5
- Mysql 8
- JDK 8
- Docker
First, insert multiple pieces of data. Options:
- foreach loop insert
- Splicing sql, one execution
- Insert using batch function
Build test environment`
sql file:
drop database IF EXISTS test; CREATE DATABASE test; use test; DROP TABLE IF EXISTS `user`; CREATE TABLE `user` ( `id` int(11) NOT NULL, `name` varchar(255) DEFAULT "", `age` int(11) DEFAULT 0, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
Applied profile:
server:
port: 8081
spring:
#Database connection configuration
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/test?characterEncoding=utf-8&useSSL=false&allowPublicKeyRetrieval=true&&serverTimezone=UTC&setUnicode=true&characterEncoding=utf8&&nullCatalogMeansCurrent=true&&autoReconnect=true&&allowMultiQueries=true
username: root
password: 123456
#Configuration of mybatis
mybatis:
#mapper profile
mapper-locations: classpath:mapper/*.xml
type-aliases-package: com.aphysia.spingbootdemo.model
#Open hump naming
configuration:
map-underscore-to-camel-case: true
logging:
level:
root: error
Start the file and configure the path of Mapper file scanning:
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.EnableAutoConfiguration;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
@MapperScan("com.aphysia.springdemo.mapper")
public class SpringdemoApplication {
public static void main(String[] args) {
SpringApplication.run(SpringdemoApplication.class, args);
}
}
Mapper file prepares several methods, including inserting a single object, deleting all objects, splicing and inserting multiple objects:
import com.aphysia.springdemo.model.User;
import org.apache.ibatis.annotations.Param;
import java.util.List;
public interface UserMapper {
int insertUser(User user);
int deleteAllUsers();
int insertBatch(@Param("users") List<User>users);
}
Mapper. The XML file is as follows:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="com.aphysia.springdemo.mapper.UserMapper">
<insert id="insertUser" parameterType="com.aphysia.springdemo.model.User">
insert into user(id,age) values(#{id},#{age})
</insert>
<delete id="deleteAllUsers">
delete from user where id>0;
</delete>
<insert id="insertBatch" parameterType="java.util.List">
insert into user(id,age) VALUES
<foreach collection="users" item="model" index="index" separator=",">
(#{model.id}, #{model.age})
</foreach>
</insert>
</mapper>
During the test, we delete all data for each operation to ensure that the test is objective and not affected by the previous data.
Different tests
1. foreach insertion
First obtain the list, and then perform a database operation for each piece of data to insert data:
@SpringBootTest
@MapperScan("com.aphysia.springdemo.mapper")
class SpringdemoApplicationTests {
@Autowired
SqlSessionFactory sqlSessionFactory;
@Resource
UserMapper userMapper;
static int num = 100000;
static int id = 1;
@Test
void insertForEachTest() {
List<User> users = getRandomUsers();
long start = System.currentTimeMillis();
for (int i = 0; i < users.size(); i++) {
userMapper.insertUser(users.get(i));
}
long end = System.currentTimeMillis();
System.out.println("time:" + (end - start));
}
}
2. Splicing and inserting
In fact, you insert data in the following way:
INSERT INTO `user` (`id`, `age`) VALUES (1, 11), (2, 12), (3, 13), (4, 14), (5, 15);
@Test
void insertSplicingTest() {
List<User> users = getRandomUsers();
long start = System.currentTimeMillis();
userMapper.insertBatch(users);
long end = System.currentTimeMillis();
System.out.println("time:" + (end - start));
}
3. Batch insert using batch
Set the executor type of MyBatis session to Batch, use sqlSessionFactory to set the execution mode to Batch, and set automatic submission to false. After all are inserted, submit at one time:
@Test
public void insertBatch(){
SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.BATCH, false);
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
List<User> users = getRandomUsers();
long start = System.currentTimeMillis();
for(int i=0;i<users.size();i++){
mapper.insertUser(users.get(i));
}
sqlSession.commit();
sqlSession.close();
long end = System.currentTimeMillis();
System.out.println("time:" + (end - start));
}
4. Batch processing + batch submission
On the basis of batch processing, submit every 1000 pieces of data first, that is, submit in batches.
@Test
public void insertBatchForEachTest(){
SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.BATCH, false);
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
List<User> users = getRandomUsers();
long start = System.currentTimeMillis();
for(int i=0;i<users.size();i++){
mapper.insertUser(users.get(i));
if (i % 1000 == 0 || i == num - 1) {
sqlSession.commit();
sqlSession.clearCache();
}
}
sqlSession.close();
long end = System.currentTimeMillis();
System.out.println("time:" + (end - start));
}
The first result, obviously wrong?
Running the above code, we can get the following results. The efficiency of for loop insertion is really poor, and the efficiency of spliced sql is relatively high. I see some data that spliced sql may be limited by mysql, but I only see heap memory overflow when I execute to 1000w.
The following is the incorrect result!!!
| Insertion mode | 10 | 100 | 1000 | 1w | 10w | 100w | 1000w |
|---|---|---|---|---|---|---|---|
| for loop insertion | 387 | 1150 | 7907 | 70026 | 635984 | Too long... | Too long... |
| Splicing sql insert | 308 | 320 | 392 | 838 | 3156 | 24948 | OutOfMemoryError: heap memory overflow |
| Batch processing | 392 | 917 | 5442 | 51647 | 470666 | Too long... | Too long... |
| Batch + batch submission | 359 | 893 | 5275 | 50270 | 472462 | Too long... | Too long... |
The spliced sql does not exceed memory
Let's take a look at the limitations of mysql:
mysql> show VARIABLES like '%max_allowed_packet%'; +---------------------------+------------+ | Variable_name | Value | +---------------------------+------------+ | max_allowed_packet | 67108864 | | mysqlx_max_allowed_packet | 67108864 | | slave_max_allowed_packet | 1073741824 | +---------------------------+------------+ 3 rows in set (0.12 sec)
This 67108864 is more than 600 M, which is too large. No wonder it won't report an error. Let's change it and retest after the change:
- First, when starting mysql, enter the container, or directly click the Cli icon in the Docker desktop version:
docker exec -it mysql bash
- Enter the / etc/mysql directory to modify my CNF file:
cd /etc/mysql
- Follow vim first, or you can't edit the file:
apt-get update apt-get install vim
- Modify my cnf
vim my.cnf
- Add Max on the last line_ allowed_ Packet = 20M (press i to edit, press esc after editing, enter: wq to exit)
[mysqld] pid-file = /var/run/mysqld/mysqld.pid socket = /var/run/mysqld/mysqld.sock datadir = /var/lib/mysql secure-file-priv= NULL # Disabling symbolic-links is recommended to prevent assorted security risks symbolic-links=0 # Custom config should go here !includedir /etc/mysql/conf.d/ max_allowed_packet=2M
- Exit container
# exit
- View mysql container id
docker ps -a

- Restart mysql
docker restart c178e8998e68
View the maximum Max after successful restart_ allowed_ Pact, it is found that it has been modified successfully:
mysql> show VARIABLES like '%max_allowed_packet%'; +---------------------------+------------+ | Variable_name | Value | +---------------------------+------------+ | max_allowed_packet | 2097152 | | mysqlx_max_allowed_packet | 67108864 | | slave_max_allowed_packet | 1073741824 | +---------------------------+------------+
We executed the splicing sql again and found that when 100w, the sql reached about 3.6M, exceeding the 2M we set. The successful demonstration threw an error:
org.springframework.dao.TransientDataAccessResourceException: ### Cause: com.mysql.cj.jdbc.exceptions.PacketTooBigException: Packet for query is too large (36,788,583 > 2,097,152). You can change this value on the server by setting the 'max_allowed_packet' variable. ; Packet for query is too large (36,788,583 > 2,097,152). You can change this value on the server by setting the 'max_allowed_packet' variable.; nested exception is com.mysql.cj.jdbc.exceptions.PacketTooBigException: Packet for query is too large (36,788,583 > 2,097,152). You can change this value on the server by setting the 'max_allowed_packet' variable.
Why is batch processing so slow?
However, if you look carefully, you will find that the above method, how to batch processing, does not show an advantage, and is no different from the for loop? Is that right?
This is definitely wrong. From the official documents, we can see that it will be updated in batches and will not create preprocessing statements every time. The theory is faster.
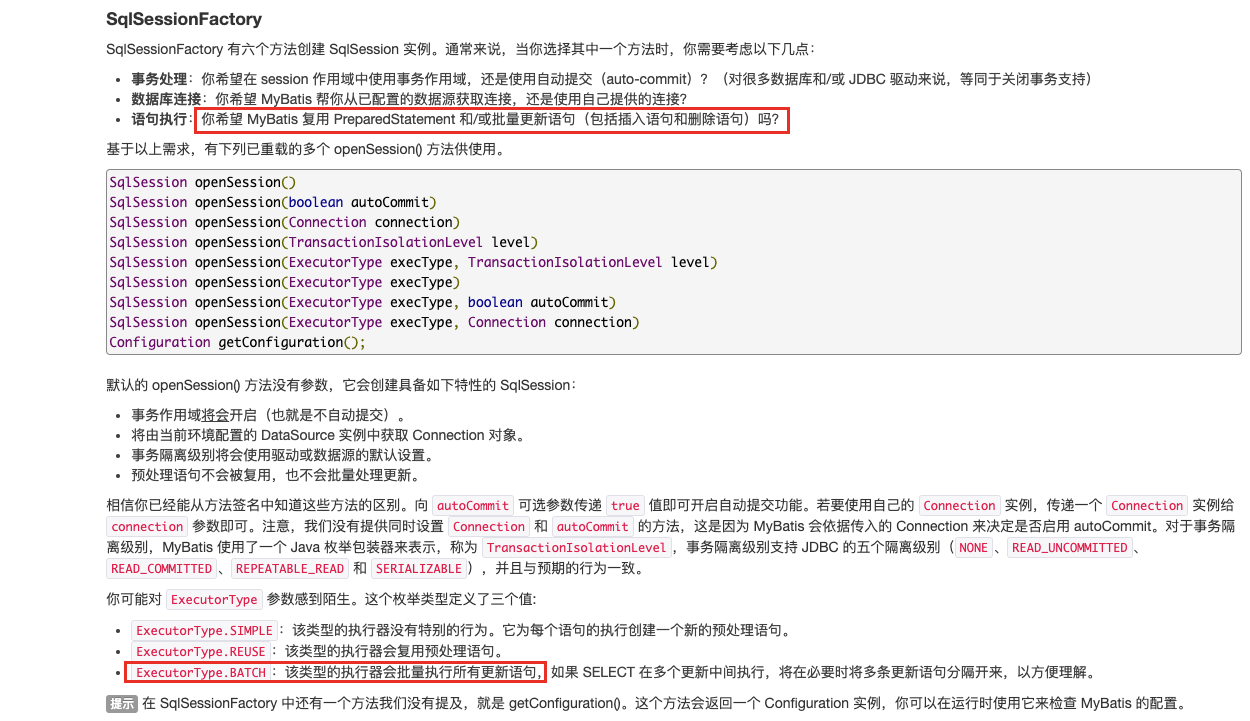
Then I found one of my most important problems: the database connection URL address is missing. Rewritebackedstatements = true
If we don't write, the MySQL JDBC driver will ignore the executeBatch() statement by default. We expect a group of sql statements executed in batches to be broken up, but when executed, they are sent to the MySQL database one by one. In fact, it is a single insert, which directly leads to low performance. I said that the performance is similar to that of looping to insert data.
Only when the rewritebackedstatements parameter is set to true will the database driver help us execute SQL in batches.
Correct database connection:
jdbc:mysql://127.0.0.1:3306/test?characterEncoding=utf-8&useSSL=false&allowPublicKeyRetrieval=true&&serverTimezone=UTC&setUnicode=true&characterEncoding=utf8&&nullCatalogMeansCurrent=true&&autoReconnect=true&&allowMultiQueries=true&&&rewriteBatchedStatements=true
After finding the problem, we retest the batch test, and the final results are as follows:
| Insertion mode | 10 | 100 | 1000 | 1w | 10w | 100w | 1000w |
|---|---|---|---|---|---|---|---|
| for loop insertion | 387 | 1150 | 7907 | 70026 | 635984 | Too long... | Too long... |
| Splicing sql insert | 308 | 320 | 392 | 838 | 3156 | 24948 (probably exceeding the sql length limit) | OutOfMemoryError: heap memory overflow |
| Batch processing (key) | 333 | 323 | 362 | 636 | 1638 | 8978 | OutOfMemoryError: heap memory overflow |
| Batch + batch submission | 359 | 313 | 394 | 630 | 2907 | 18631 | OutOfMemoryError: heap memory overflow |
From the above results, batch processing is indeed much faster. When the order of magnitude is too large, it will actually exceed the memory overflow. Batch processing and batch submission do not become faster, which is similar to batch processing, but slower. They are submitted too many times. When the number of sql splicing schemes is relatively small, they are not much different from batch processing, The worst solution is to insert data into the for loop, which is really time-consuming. It already needs 1s when there are 100 articles. You can't choose this scheme.
At first, when I found that batch processing was slow, I really doubted myself. Later, I found that there was a parameter, which felt like clearing the clouds. The more I knew, the more I didn't know.
[about the author]:
Qin Huai, the official account of Qin Huai grocery store, is not in the right place for a long time.