The iterator pattern is defined by providing a way to sequentially access the elements in an aggregate object without exposing the internal representation in the aggregate object. The iterator pattern is designed for the "access" of aggregate objects (arrays, collections, linked lists). Aggregate objects are traversed by defining different traversal strategies.
Application scenario
- The iterator pattern can be used if you want to provide access to the content of an aggregate object without exposing its internal representation
- If you want multiple traversal methods, you can access the aggregate object.
- If you want to provide a unified interface for traversing different aggregate objects, you can use the iterator pattern (polymorphic iteration).
UML diagram
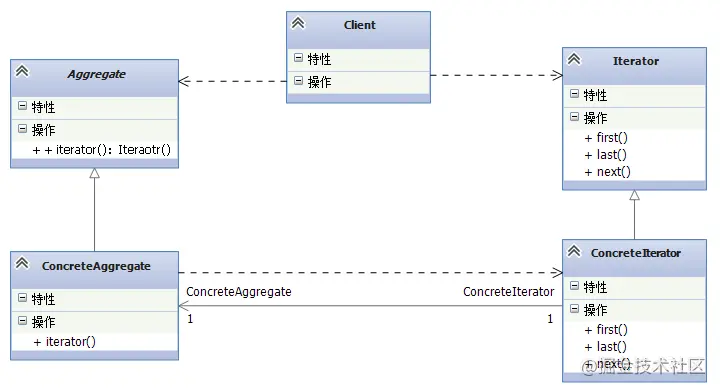
Roles involved in iterator pattern:
- Abstract Iterator role: this abstract role defines the interface method of traversing elements;
- Concrete Iterator role: implement specific iterative methods, inherit or implement Iterator.
- Aggregate role: defines the abstraction of the aggregate object, and defines the specific traversal interface to return the Iterator type
- ConcreteAggregate: implements the interface for creating iterator objects and returns an appropriate concrete iterator instance.
Case demonstration
First create the Iterator iterator interface
/**
* Define iterator roles
* @author Iflytek_dsw
*
*/
interface Iterator {
/**
* Get the first element
* @return
*/
String first();
/**
* Get the last element
* @return
*/
String last();
/**
* Determines whether there is a next element
* @return
*/
boolean hasNext();
/**
* Next element
* @return
*/
String next();
}The Iterator interface defines the traversal operation required by the aggregation object.
Define abstract aggregate objects
/**
* Aggregation role, which defines the interface of aggregation role
* @author Iflytek_dsw
*
*/
abstract class Aggregate {
abstract Iterator iterator();
}Define concrete aggregate objects
class ConcreteAggregate extends Aggregate{
private List<String> names;
public ConcreteAggregate(List<String> names) {
super();
this.names = names;
}
@Override
Iterator iterator() {
return new AggregateIterator(this);
}
public String first(){
return names == null ? null : names.get(0);
}
public String last(){
return names == null ? null : names.get(names.size() -1);
}
public String next(int index){
return names == null ? null : names.get(index);
}
/**
* Number of elements in the aggregate
* @return
*/
public int size(){
return names.size();
}
}In the above example, we can see that in the concrete aggregation, we have defined methods with Iterator objects to encapsulate specific operations. In order to call in the specific instance of Iterator, we also encapsulate a method to generate Iterator.
Concrete iterator
class AggregateIterator implements Iterator{
private ConcreteAggregate concreteAggregate;
private int index;
public AggregateIterator(ConcreteAggregate concreteAggregate) {
super();
this.concreteAggregate = concreteAggregate;
this.index = 0;
}
@Override
public String first() {
return concreteAggregate.first();
}
@Override
public String last() {
return concreteAggregate.last();
}
@Override
public String next() {
return concreteAggregate.next(index -1);
}
@Override
public boolean hasNext() {
if(index < concreteAggregate.size()){
index++;
return true;
}
return false;
}
}An instance containing an aggregate object is defined in a specific iterator, that is, the access to the aggregate object for corresponding operations.
client
public class Client {
/**
* @param args
*/
public static void main(String[] args) {
List<String> names = new ArrayList<>(Arrays.asList(new String[]{"James","Lucy","Jack"}));
Aggregate aggregate = new ConcreteAggregate(names);
Iterator iterator = aggregate.iterator();
System.out.println("The first element is:" + iterator.first());
System.out.println("The last element is:" + iterator.last());
while(iterator.hasNext()){
System.out.println("Traversal element:" + iterator.next());
}
}
}In the above client, we first create an instance of the aggregate class, then call the iterator method to get an iterator role, and get the iterator role, then we can carry out related traversal operation.
results of enforcement
The first element is: James The last element is: Jack Traversal element:James Traversal element:Lucy Traversal element:Jack
Through the above example demonstration, we can get the following points:
- The essence of iterators: control access to elements in aggregate objects. The iterator can realize the function of "accessing each element of the aggregate object without exposing the internal implementation of the aggregate object", so as to "transparently" access the elements in the aggregate object. Note that iterators have both "transparent" access and "controlled access" to aggregate objects.
- The key idea of iterator: separate the traversal access to the aggregate object from the aggregate object and put it into a separate iterator. In this way, the aggregate object will become simple, and the iterator and aggregate object can change and develop independently, so as to improve the flexibility of the system.
- Motivation of iterators: in the process of software construction, the internal structure of collection objects often changes differently. However, for these collection objects, we hope that the external client code can access the elements transparently without exposing their internal structure; At the same time, this "transparent traversal" also makes it possible for "the same algorithm to operate on multiple collection objects". Abstracting the traversal mechanism as "iterator object" provides an elegant way to "deal with changing collection objects"
In the above example, since the corresponding operation methods have been provided inside the aggregation, should we use the iterator pattern? Indeed, the client can perform traversal operations according to the interface provided by the aggregation. However, the iterator mode abstracts the iteration well and has better scalability. Because the internal structure of the collection object is changeable, the iterator mode can separate the responsibilities of the client and the aggregation, so that they can evolve independently. As an intermediate layer, the iterator mode can absorb the changing factors, Avoid client modifications.
Internal iteration VS external iteration
The external iterator refers to the step of iterating the next element controlled by the client. The client will explicitly call the iterator's next() and other iterative methods to move forward in the traversal process.
An internal iterator is a step in which the iterator itself controls the iteration of the next element. Therefore, if you want to complete the work during the iteration, the client needs to pass the operation to the iterator, which will perform this operation on each element during the iteration, which is similar to the JAVA callback mechanism.
In general, external iterators are more flexible than internal iterators, so most of our common implementations belong to active iterators.
If an aggregated interface does not provide a method to modify aggregated elements, such an interface is the so-called narrow interface.
Aggregate objects provide a wide interface for iterators and a narrow interface for other objects to access. That is, the aggregate object is properly exposed to the iterator so that the iterator has enough knowledge of the aggregate object to perform iterative operations. However, aggregation objects should avoid providing these methods to other objects. Other objects should complete these operations through iterators, and aggregation objects cannot be operated directly.
In Java, the way to implement this dual restriction interface is through the internal class, that is, the iterator object is set as the internal class of the aggregation class, so that the iterator object can have good access to the aggregation class and restrict external operations. This scheme that ensures the encapsulation of aggregation objects and the implementation of iterative sub functions at the same time is called black box implementation scheme. The iterator defined in this form is also called internal iterator.
As shown in the following example:
public class NameRepository implements Container {
public String names[] = {"Robert" , "John" ,"Julie" , "Lora"};
@Override
public Iterator getIterator() {
return new NameIterator();
}
private class NameIterator implements Iterator {
int index;
@Override
public boolean hasNext() {
if(index < names.length){
return true;
}
return false;
}
@Override
public Object next() {
if(this.hasNext()){
return names[index++];
}
return null;
}
}
}Supplementary knowledge -- Static iterators and dynamic iterators
The static iterator static iterator is created by the aggregate object and holds a snapshot of the aggregate object. After the snapshot is generated, the content of the snapshot will not change. The client can continue to modify the contents of the original aggregation, but the iterated sub objects will not reflect the new changes of the aggregation.
The advantage of static iterator is its security and simplicity. In other words, static iterator is easy to implement and not prone to errors. However, because the static iterator copies the original aggregation, its disadvantage is the consumption of time and memory resources.
The dynamic iterator dynamic iterator is completely opposite to the static iterator. After the iterator is generated, the iterator maintains the reference to the aggregation element. Therefore, any modification to the original aggregation content will be reflected on the iterator sub object.
The complete dynamic iterator is not easy to implement, but the simplified dynamic iterator is not difficult to implement. Most of the iterations encountered by JAVA designers are such simplified dynamic iterations. In order to explain what is a simplified dynamic iterator, we first need to introduce a new concept: Fail Fast.
If the computing environment of an algorithm changes after it starts, so that the algorithm cannot make necessary adjustments, the algorithm should send a fault signal immediately. This is what Fail Fast means.
If the elements of the aggregation object change in the iterative process of a dynamic iterator, the iterative process will be affected and cannot be self-adaptive. At this point, the iterator should immediately throw an exception. This iterator is the iterator that implements the Fail Fast function.
The application of Fail Fast in JAVA aggregation uses JAVA language to interface JAVA util. Iterator supports iterative sub mode. The Collection interface requires an iterator() method, which returns an iterator type object when called. As a subtype of the Collection interface, the internal member class Itr of the AbstractList class is the class that implements the iterator interface.
Advantages and disadvantages
advantage
- Better encapsulation, aggregation objects can be accessed without exposing the internal implementation;
- Each aggregation object can have one or more iteration sub objects, and the iteration state of each iteration sub object can be independent of each other. Therefore, an aggregate object can have several iterations in progress at the same time.
- The separation of aggregate content and iterator improves the scalability, that is, different iterators can be used to traverse the aggregate content.
shortcoming
- Too many types of iterators will increase the number of classes and improve the complexity of the system;
- Exceptions are easy to occur in dynamic iterators.
Finally
I've always wanted to sort out a perfect interview dictionary, but I can't spare time. This set of more than 1000 interview questions is sorted out in combination with the interview questions of gold, silver and four major factories this year, as well as the documents with star number exceeding 30K + on GitHub. After I uploaded it, it's no surprise that the praise amount reached 13k in just half an hour. To be honest, it's still a little incredible.
You need a full version of the little partner. You can click three times, click here !
1000 Internet Java Engineer Interview Questions
Content: Java, MyBatis, ZooKeeper, Dubbo, Elasticsearch, Memcached, Redis, MySQL, Spring, SpringBoot, SpringCloud, RabbitMQ, Kafka, Linux and other technology stacks (485 pages)
Collection of Java core knowledge points (page 283)
The content covers: Java foundation, JVM, high concurrency, multithreading, distribution, design pattern, Spring bucket, Java, MyBatis, ZooKeeper, Dubbo, Elasticsearch, Memcached, MongoDB, Redis, MySQL, RabbitMQ, Kafka, Linux, Netty, Tomcat, database, cloud computing, etc
Collection of advanced core knowledge points in Java (page 524)
Sorting out knowledge points of Java advanced architecture
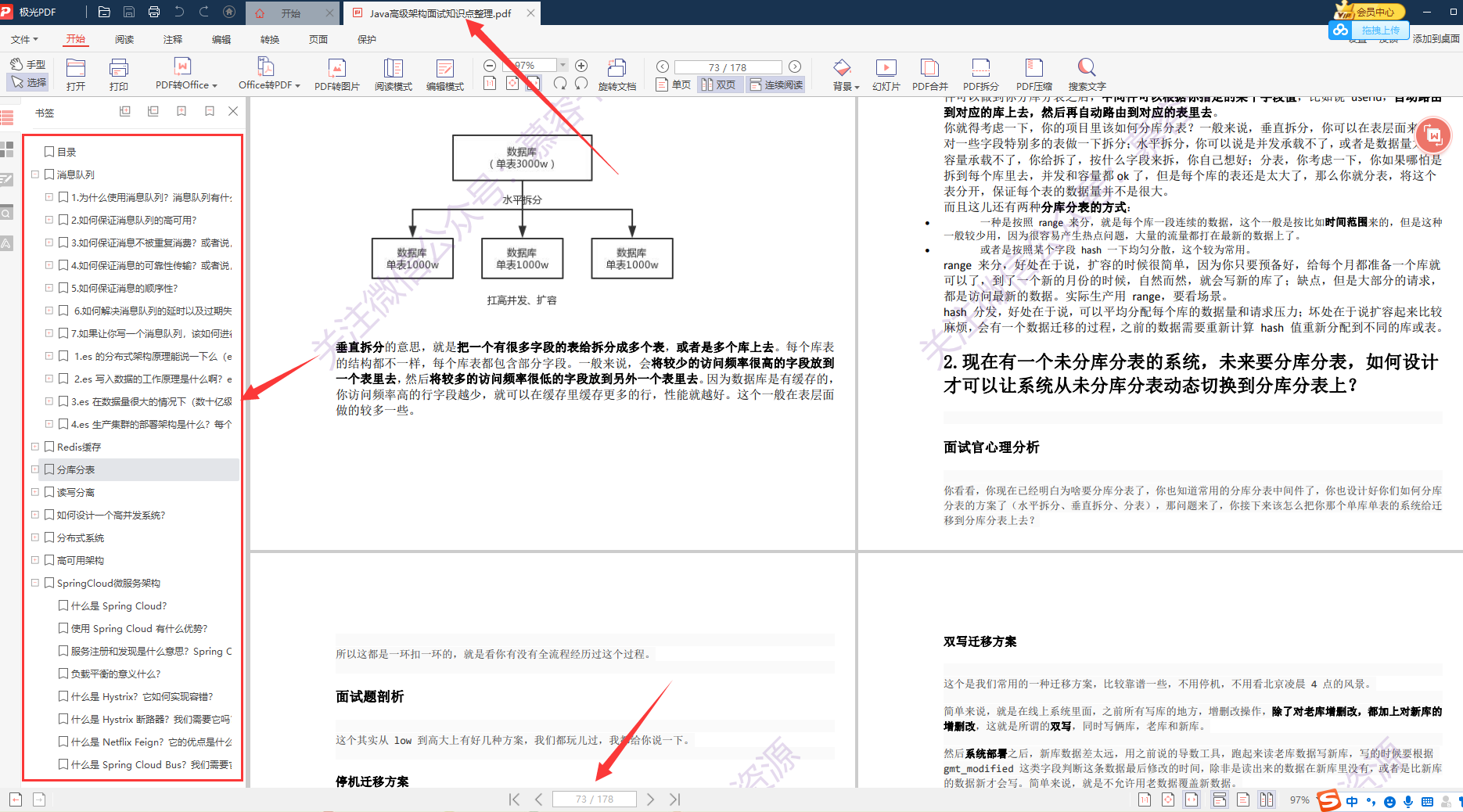

Due to space constraints, the detailed information is too comprehensive and there are too many details, so only the screenshots of some knowledge points are roughly introduced. There are more detailed contents in each small node!
You need a full version of the little partner. You can click three times, click here !