J2WEB course design example
I found a good article about database query display error: Analysis of mysql coding errors.
And then I have a crack free version navicat . extraction code: dv6k
catalog
- Project Name: xixijiaxiang online e-book City
- Project background: (if I think about it myself, I won't talk about it.)
- Project team members: Cai Xibei, Wang Mushi
Question 1: how to print and output e-book documents
Since it's an online e-book, you need to know how to print it out
Step 1: we need to print a document, such as: test.doc . We need to know the path of this file, so we need to establish a connection with this file
File file = new File(path); //To establish a connection with a file is to get the path of the file
Step 2: get the input bytes from a file in the file system, that is to say, we change the characters in this file into byte streams
Step 3: we read characters into byte stream, but what we get can't be displayed directly, right? So we need to take this byte stream out and store it in byte array byte []FileInputStream reader = new FileInputStream(file); //Get input bytes from a file in the file system
Step 4: when we get the output byte of this file, we can print it directlybyte[] b = new byte[reader.available()]; //Read byte stream saved to byte array int len = reader.read(b); //Bytes read
System.out.println(new String(b,0,len)); reader.close();
Complete case:
public class ReadFile { public static void main(String[] args) throws Exception { //File printout readerFile(); } static void readerFile() throws Exception { //If we want to output the content of a file, we need to know where the file is first File file = new File("C:\\Users\\Administrator\\Desktop\\file\\test.xml"); //We found the document, but how can we print it out FileInputStream reader = new FileInputStream(file); byte[] b = new byte[reader.available()]; int len = reader.read(b); //Bytes read System.out.println(new String(b,0,len)); reader.close(); } }
Running screenshot:
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {//read abc.docx Content and output to web page response.setContentType("text/html;charset=utf-8"); //Establish a connection File filePath = new File("C:\\Users\\Administrator\\eclipse-workspace\\day0505\\src\\abc.txt"); if(!filePath.exists()) {//If the file does not exist, tell someone that the resource is missing response.getWriter().println("The resources you need have been lost....."); }else {//File exists InputStream is = new FileInputStream(filePath); InputStreamReader isr = new InputStreamReader(is, "GBK"); //Set the coding mode to prevent garbled code BufferedReader reader = new BufferedReader(isr); String line = null; while((line=reader.readLine())!=null) {//If the read row is not empty, continue reading 3 response.getWriter().println(" "+line+"<br/>"); } reader.close(); isr.close(); is.close(); } }
Running screenshot: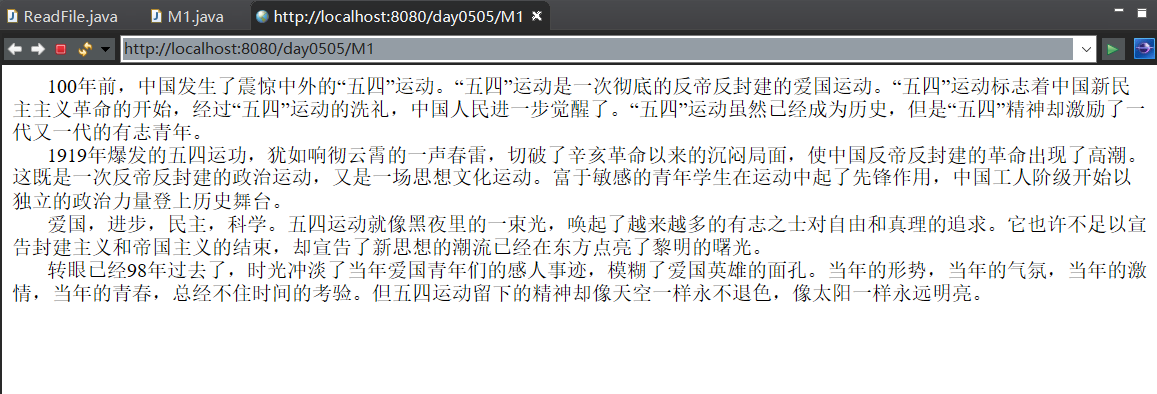
Step 1: let's assume that there is a folder test, and then there are two folders test1 and test2 in this folder. How do we traverse to print all the files in test1 and test2. So we need to establish a connection with the file test, that is to find the path, right. Let's implement traversal first, and link the database later when the project needs to be used
Step 2: use recursive algorithm to traverse the fileFile file = new File(path:xxx.doc); //Create a connection to a file recursionFiles( file); //Call the recursive algorithm in step 2
//Traverse a specified file directory static void recursionFiles(File file) { //Get all the files in this directory File[] listFiles = file.listFiles(); //List all files in the file for(File files:listFiles) { //Loop through the listed files if(files.isDirectory()) { //The traversal file is a directory (folder), so you need to recursively traverse the folder again System.out.println("\n This is a folder"+files.getName()+":"); recursionFiles(files); //Call recursive method again System.out.println(files.getName()+"End of file traversal in\n"); }else { //Traversal file is not a folder, direct printout System.out.println(files.getName()); } } }
Complete example:
public class RecursionFile { public static void main(String[] args) { //Establish a connection File file = new File("C:\\Users\\Administrator\\Desktop\\file"); recursionFiles(file); } //Traverse a specified file directory static void recursionFiles(File file) { //Get all the files in this directory File[] listFiles = file.listFiles(); for(File files:listFiles) { if(files.isDirectory()) { System.out.println("\n This is a folder"+files.getName()+":"); recursionFiles(files); System.out.println(files.getName()+"End of file traversal in\n"); }else { System.out.println(files.getName()); } } } }
Running screenshot:
Path:
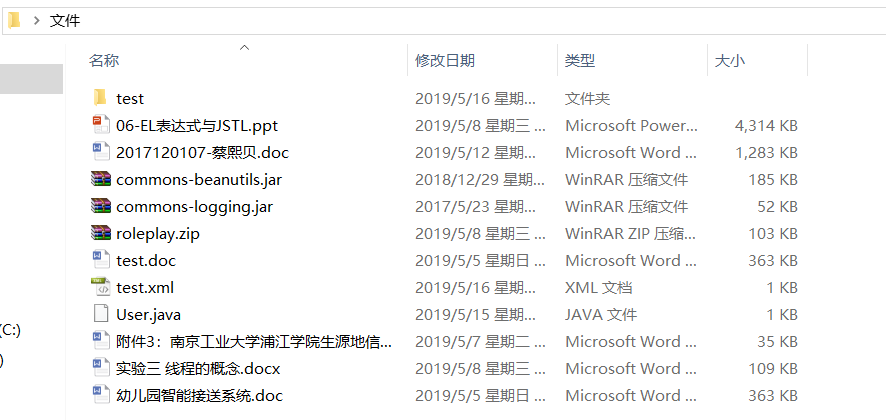
Traverse output screenshot: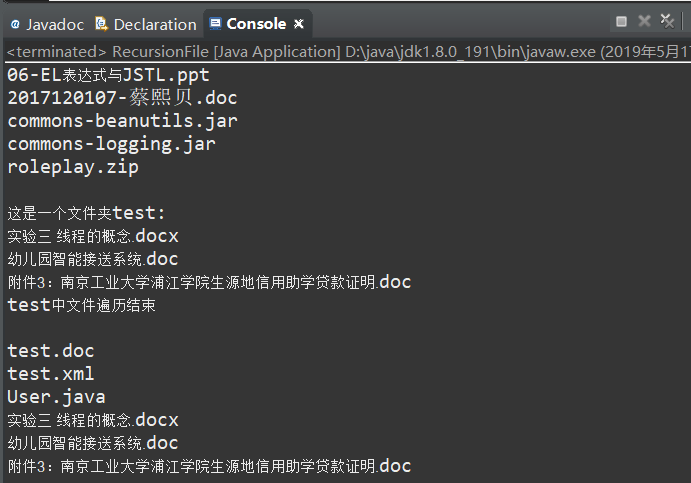
Now that we've solved the problem, we're making our online bookstore:
emmmmm… Too much, contact me directly for source code! Effect website: Book city
About setting up the server, please contact me to teach you. QQ: 2584163016, please explain the purpose of the verification information