1, IO flow and system
IO technology is an extremely complex module in JDK. One of the key reasons for its complexity is the correlation between IO operation and system kernel. In addition, network programming and file management all rely on Io technology, which is a programming difficulty. To understand IO flow as a whole, start with Linux operating system.
Linux space isolation
Linux is used to distinguish users, which is a basic common sense. Its bottom layer also distinguishes between users and kernel modules:
- User space: user space
- Kernel space: kernel space
The common sense user space permissions are much weaker than the kernel space operation permissions, which involves the interaction between the user and the kernel modules. At this time, if the application deployed on the service needs to request system resources, the interaction is more complex:
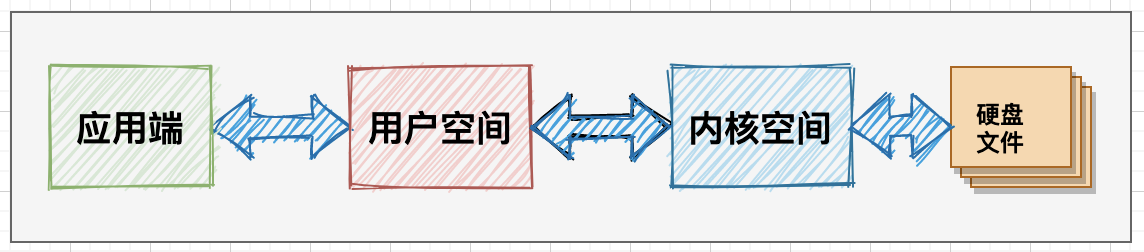
The user space itself cannot directly issue scheduling instructions to the system. It must pass through the kernel. For the operation of data in the kernel, it also needs to be copied to the user space first. This isolation mechanism can effectively protect the security and stability of the system.
Parameter view
You can dynamically view various data analysis through the Top command, and the status of resources occupied by the process:
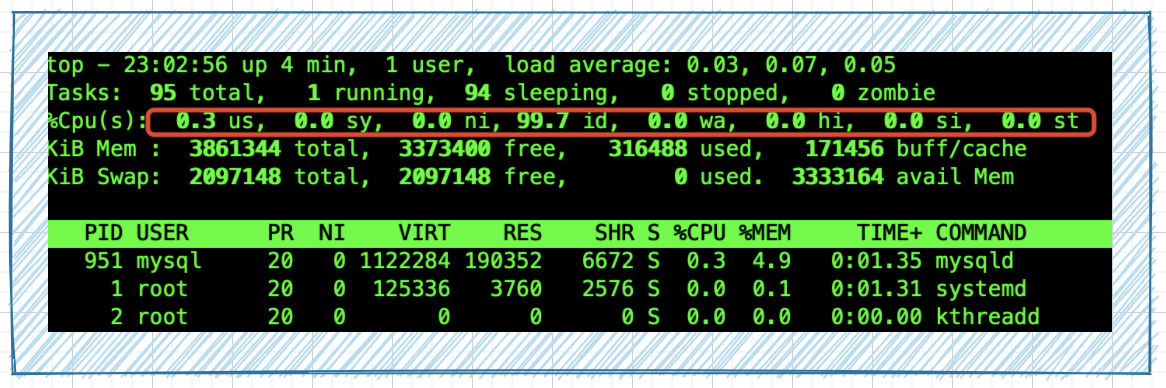
- us: percentage of CPU occupied by user space;
- sy: percentage of CPU occupied by kernel space;
- id: percentage of CPU occupied by idle processes;
- wa: percentage of CPU occupied by IO waiting;
wa indicator is one of the core items of monitoring in large-scale document task flow.
IO collaboration process
At this time, look at the flow in figure [1] above. When the application side initiates an IO operation request, the request flows along each node on the link. There are two core concepts:
- Node interaction mode: synchronous and asynchronous;
- IO data operation: blocking and non blocking;
This is what is often said in the file stream: [synchronous / asynchronous] IO and [blocking / non blocking] io. See the details below.
2, IO model analysis
1. Synchronous blocking
The interaction mode between the user thread and the kernel. The request of the application side is processed by one thread. In the whole process, the accept and read methods will be blocked until the whole action is completed:
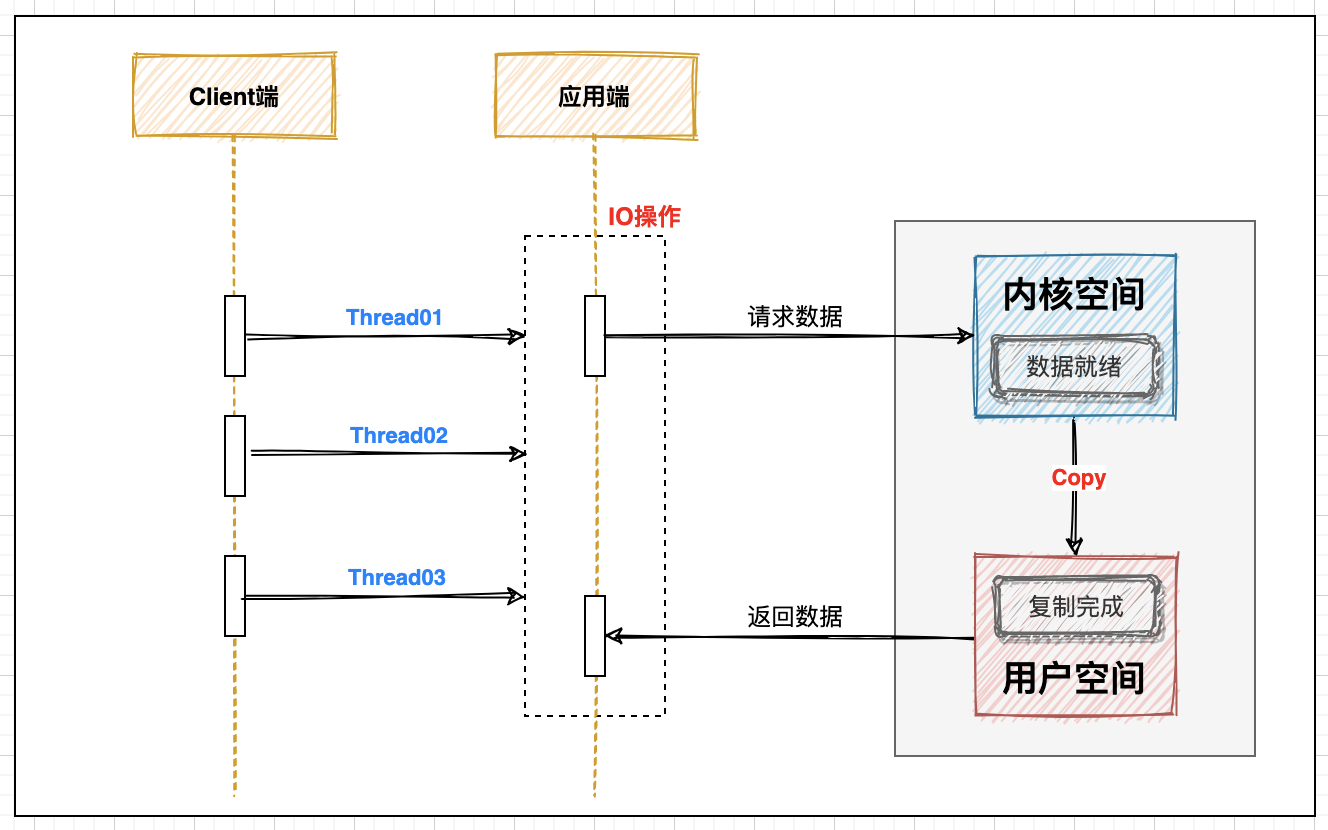
In the conventional CS architecture mode, this is the basic process of an IO operation. In this mode, in the scenario of high concurrency, the request response of the client will have serious performance problems and occupy too many resources.
2. Synchronous non blocking
Based on synchronous blocking IO, the current thread will not wait for data to be ready until replication is completed:
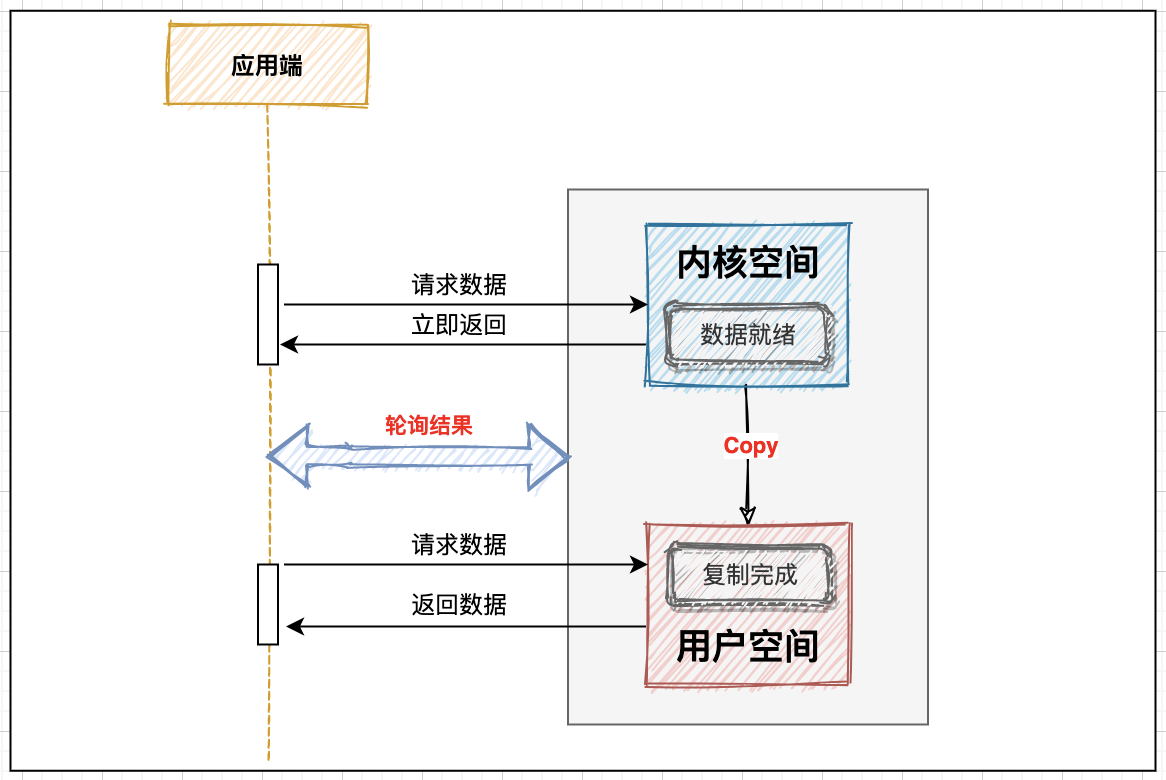
The thread will return immediately after the request, and will continue to poll until it gets the data. The defect of this mode is also obvious. If the data is ready, notify the thread to complete the follow-up action, which can save a lot of intermediate interaction.
3. Asynchronous notification mode
In the asynchronous mode, the blocking mechanism is completely abandoned and the process is interactive in segments, which is very similar to the conventional third-party docking mode. When a local service requests a third-party service, if the request process takes a lot of time, it will be executed asynchronously. The third party will call back for the first time to confirm that the request can be executed; The second callback is the result of push processing. This idea can greatly improve the performance and save resources when dealing with complex problems:
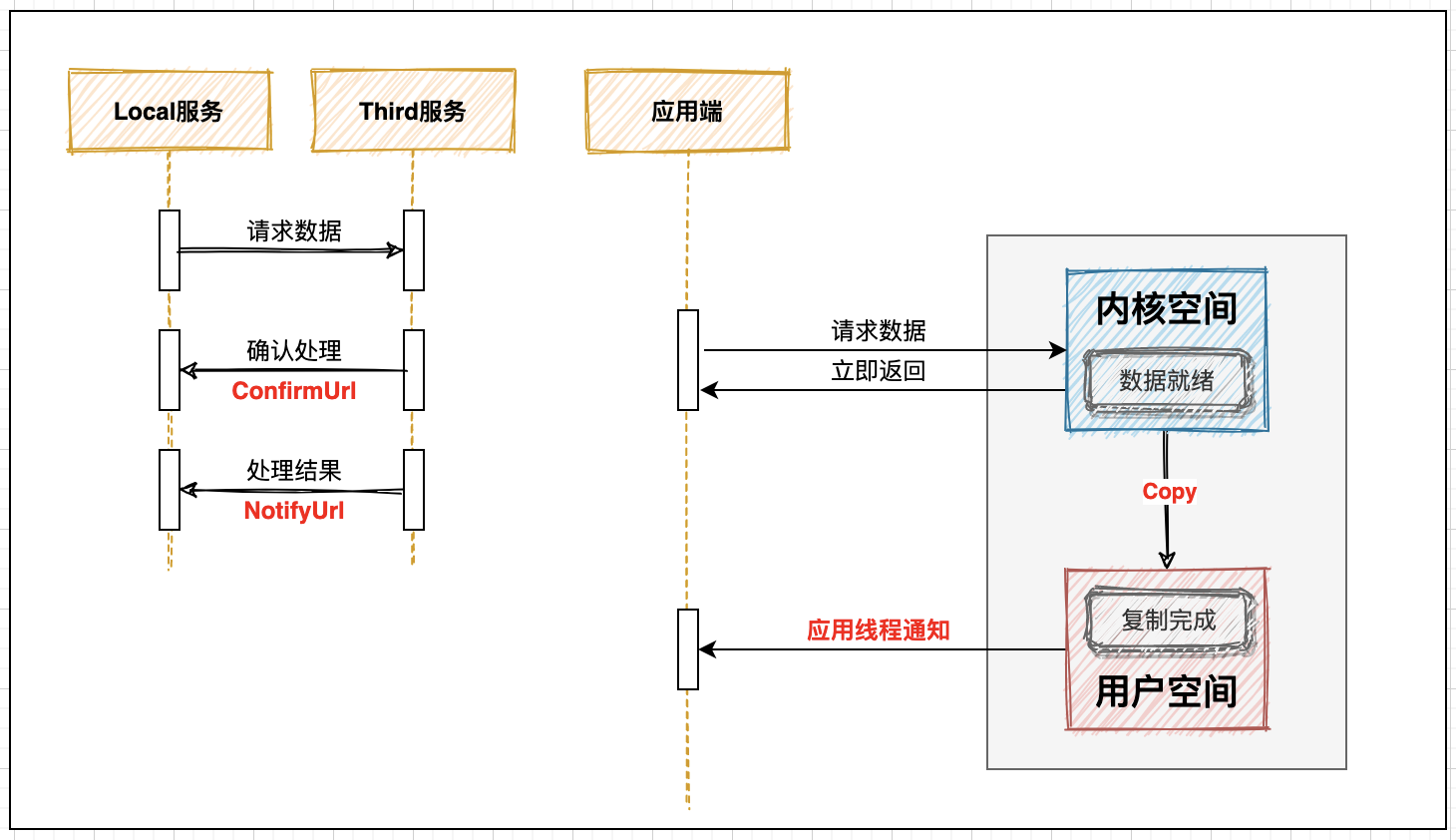
Asynchronous mode can greatly improve the performance. Of course, its corresponding processing mechanism is more complex. The iteration and optimization of the program are endless. The IO flow mode is optimized again in NIO mode.
3, File file class
1. Basic description
As an abstract representation of File and directory path names, File class is used to obtain relevant metadata information of disk files, such as File name, size, modification time, permission judgment, etc.
Note: File does not operate the data content carried by the File. The File content is called data, and the File's own information is called metadata.
public class File01 {
public static void main(String[] args) throws Exception {
// 1. Read the specified file
File speFile = new File(IoParam.BASE_PATH+"fileio-03.text") ;
if (!speFile.exists()){
boolean creFlag = speFile.createNewFile() ;
System.out.println("establish:"+speFile.getName()+"; result:"+creFlag);
}
// 2. Read the specified location
File dirFile = new File(IoParam.BASE_PATH) ;
// Determine whether the directory
boolean dirFlag = dirFile.isDirectory() ;
if (dirFlag){
File[] dirFiles = dirFile.listFiles() ;
printFileArr(dirFiles);
}
// 3. Delete specified file
if (speFile.exists()){
boolean delFlag = speFile.delete() ;
System.out.println("Delete:"+speFile.getName()+"; result:"+delFlag);
}
}
private static void printFileArr (File[] fileArr){
if (fileArr != null && fileArr.length>0){
for (File file : fileArr) {
printFileInfo(file) ;
}
}
}
private static void printFileInfo (File file) {
System.out.println("name:"+file.getName());
System.out.println("Length:"+file.length());
System.out.println("route:"+file.getPath());
System.out.println("Document judgment:"+file.isFile());
System.out.println("Directory judgment:"+file.isDirectory());
System.out.println("Last modification:"+new Date(file.lastModified()));
System.out.println();
}
}
The above case uses the basic structure and common methods (read, judge, create and delete) in the File class. The JDK source code is constantly updated and iterated. Judging the basic functions of the class through the class constructor, method and annotation is a necessary ability for developers.
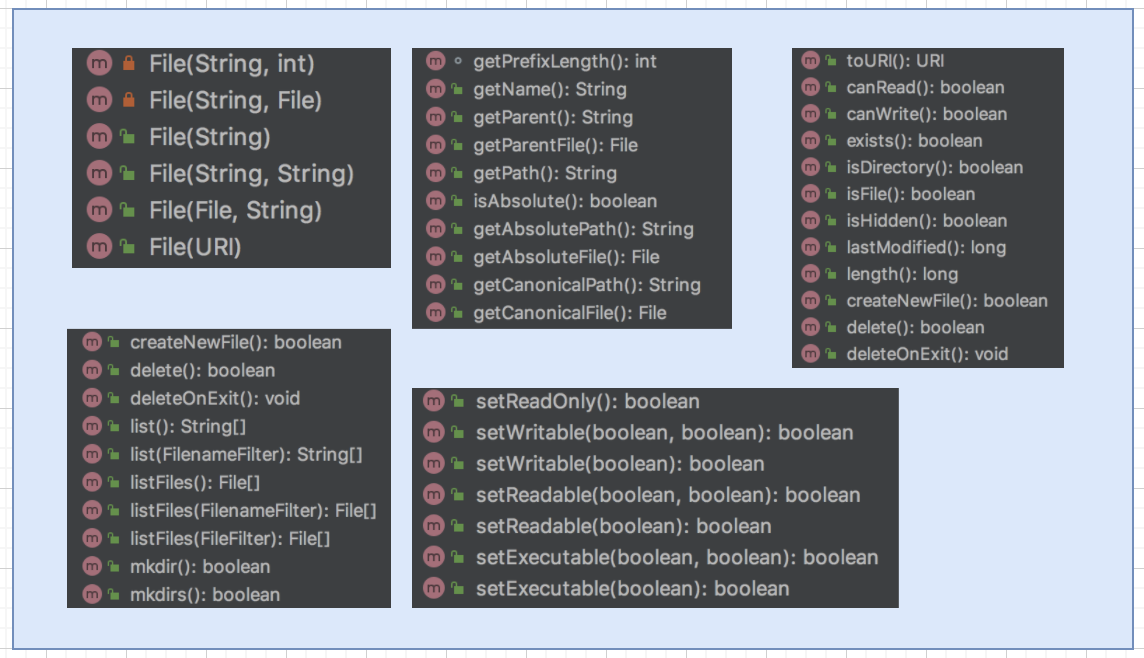
The File class lacks two key information descriptions: type and code. If you often develop the requirements of the File module, you know that these are two extremely complex points, which are prone to problems. Let's see how to deal with them from the perspective of actual development.
2. File business scenario
As shown in the figure, three basic forms of [file, stream and data] conversion will be involved in the conventional file flow task:
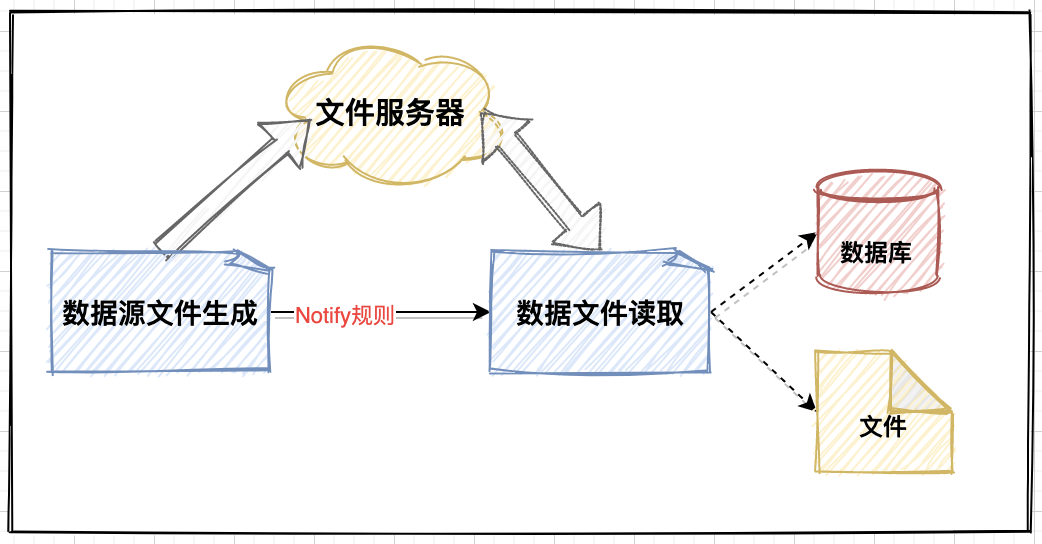
Basic process description:
- Generate source files and push them to the file center;
- Notify the business user node to obtain the file;
- The business node performs logical processing;
Obviously, no node can adapt to all file processing strategies, such as type and coding. In the face of problems in complex scenarios, rule constraints are a common solution strategy, that is, things within the agreed rules can be handled.
In the above process, the data subject description when the source file node notifies the business node:
public class BizFile {
/**
* Document task batch number
*/
private String taskId ;
/**
* Compress
*/
private Boolean zipFlag ;
/**
* File address
*/
private String fileUrl ;
/**
* file type
*/
private String fileType ;
/**
* Document code
*/
private String fileCode ;
/**
* Business Association: Database
*/
private String bizDataBase ;
/**
* Business Association: data table
*/
private String bizTableName ;
}
The whole process is encapsulated as a task, that is, task batch, file information, service library table routing, etc. of course, these information can also be directly marked on the file naming strategy, and the processing methods are similar:
/**
* Read information based on agreed policy
*/
public class File02 {
public static void main(String[] args) {
BizFile bizFile = new BizFile("IN001",Boolean.FALSE, IoParam.BASE_PATH,
"csv","utf8","model","score");
bizFileInfo(bizFile) ;
/*
* Business verification
*/
File file = new File(bizFile.getFileUrl());
if (!file.getName().endsWith(bizFile.getFileType())){
System.out.println(file.getName()+": Description error...");
}
}
private static void bizFileInfo (BizFile bizFile){
logInfo("task ID",bizFile.getTaskId());
logInfo("Unzip",bizFile.getZipFlag());
logInfo("File address",bizFile.getFileUrl());
logInfo("file type",bizFile.getFileType());
logInfo("Document code",bizFile.getFileCode());
logInfo("Business Library",bizFile.getBizDataBase());
logInfo("Business table",bizFile.getBizTableName());
}
}
Based on the information described by the subject, it can also be transformed into naming rules: Naming Strategy: numbering_ Compress_ Excel_ Code_ Storehouse_ In this way, non-conforming files are directly excluded during business processing, so as to reduce the data problems caused by file exceptions.
4, Basic flow mode
1. Overall overview
IO flow direction
Basic coding logic: source file - > input stream - > logic processing - > output stream - > target file;
From different perspectives, flow can be divided into many modes:
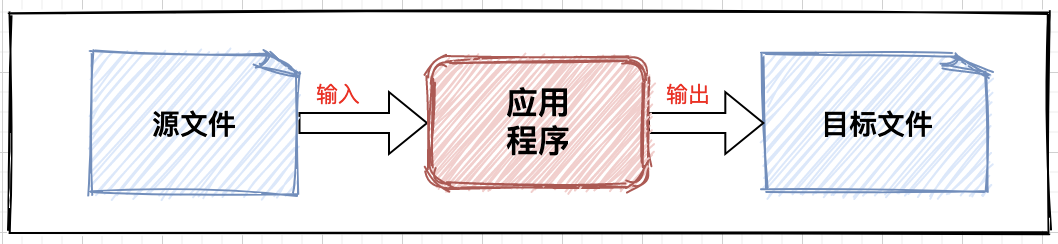
- Flow direction: input flow and output flow;
- Stream data type: byte stream and character stream;
There are many modes of IO flow, and the corresponding API design is also very complex. Generally, complex APIs should grasp the core interface and common implementation classes and principles.
Basic API
-
Byte stream: InputStream input, OutputStream output; The basic unit of data transmission is byte;
- read(): the next byte of read data in the input stream;
- read(byte b []): cache read data into byte array;
- write(int b): write the specified byte to the output stream;
- write(byte b []): write array bytes to the output stream;
-
Character stream: read by Reader and write by Writer; The basic unit of data transmission is character;
- read(): read a single character;
- read(char cbuf []): read the character array;
- write(int c): write a specified character;
- write(char cbuf []): write a character array;
Buffer mode
The IO stream is in the conventional read-write mode, that is, read the data and then write it out. There is also a buffer mode, that is, load the data into the buffer array first, and judge whether to fill the buffer again when reading:
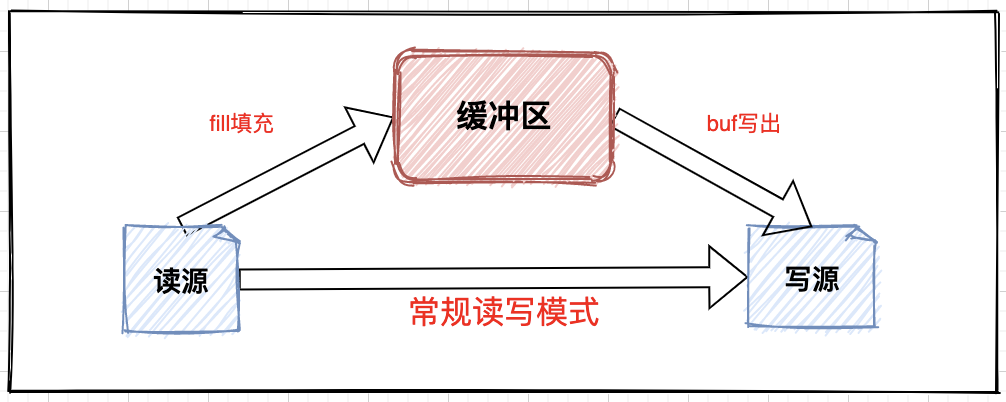
The advantages of buffer mode are very obvious. It ensures the high efficiency of the read-write process and is executed separately from the data filling process. It is a concrete implementation of buffer logic in BufferedInputStream and BufferedReader classes.
2. Byte stream
API diagram:
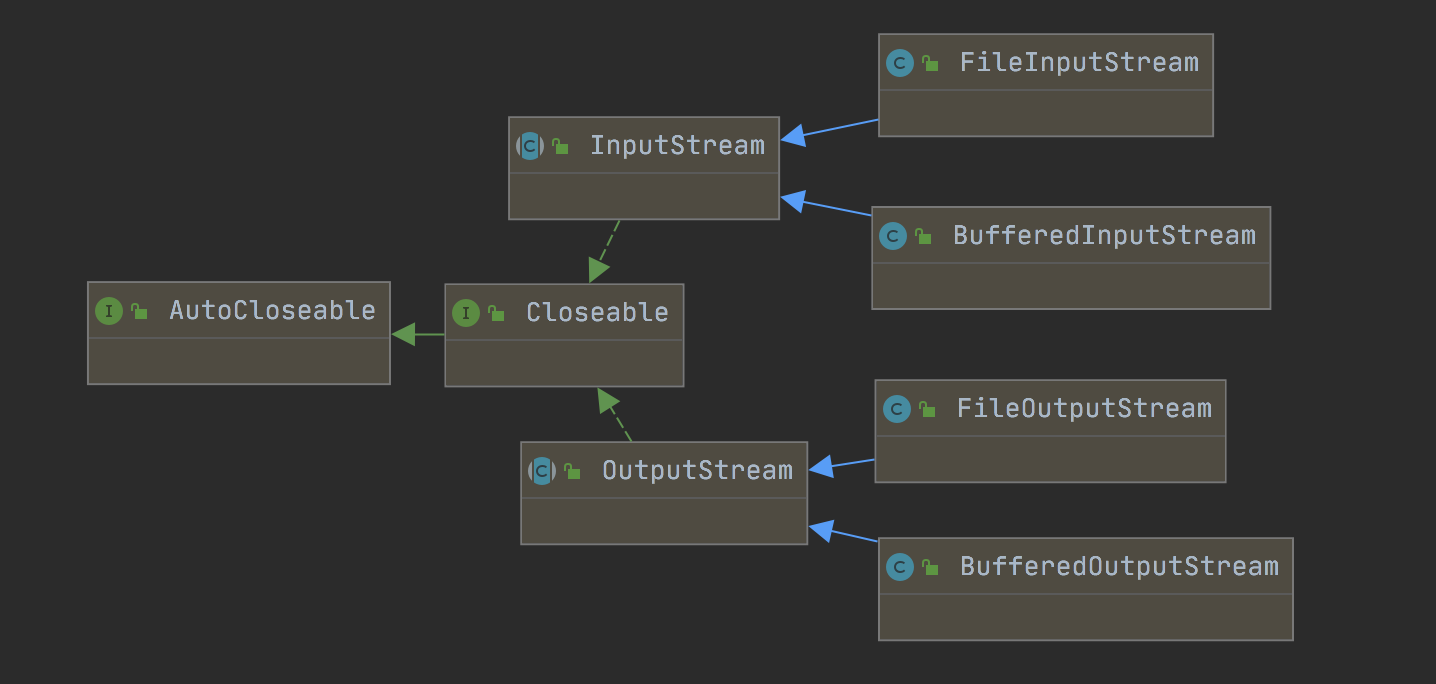
Byte stream base API:
public class IoByte01 {
public static void main(String[] args) throws Exception {
// Source file destination file
File source = new File(IoParam.BASE_PATH+"fileio-01.png") ;
File target = new File(IoParam.BASE_PATH+"copy-"+source.getName()) ;
// Input stream output stream
InputStream inStream = new FileInputStream(source) ;
OutputStream outStream = new FileOutputStream(target) ;
// Read in write out
byte[] byteArr = new byte[1024];
int readSign ;
while ((readSign=inStream.read(byteArr)) != -1){
outStream.write(byteArr);
}
// Close input and output streams
outStream.close();
inStream.close();
}
}
Byte stream buffer API:
public class IoByte02 {
public static void main(String[] args) throws Exception {
// Source file destination file
File source = new File(IoParam.BASE_PATH+"fileio-02.png") ;
File target = new File(IoParam.BASE_PATH+"backup-"+source.getName()) ;
// Buffering: input stream output stream
InputStream bufInStream = new BufferedInputStream(new FileInputStream(source));
OutputStream bufOutStream = new BufferedOutputStream(new FileOutputStream(target));
// Read in write out
int readSign ;
while ((readSign=bufInStream.read()) != -1){
bufOutStream.write(readSign);
}
// Close input and output streams
bufOutStream.close();
bufInStream.close();
}
}
Byte stream application scenario: data is the file itself, such as picture, video, audio, etc.
3. Character stream
API diagram:
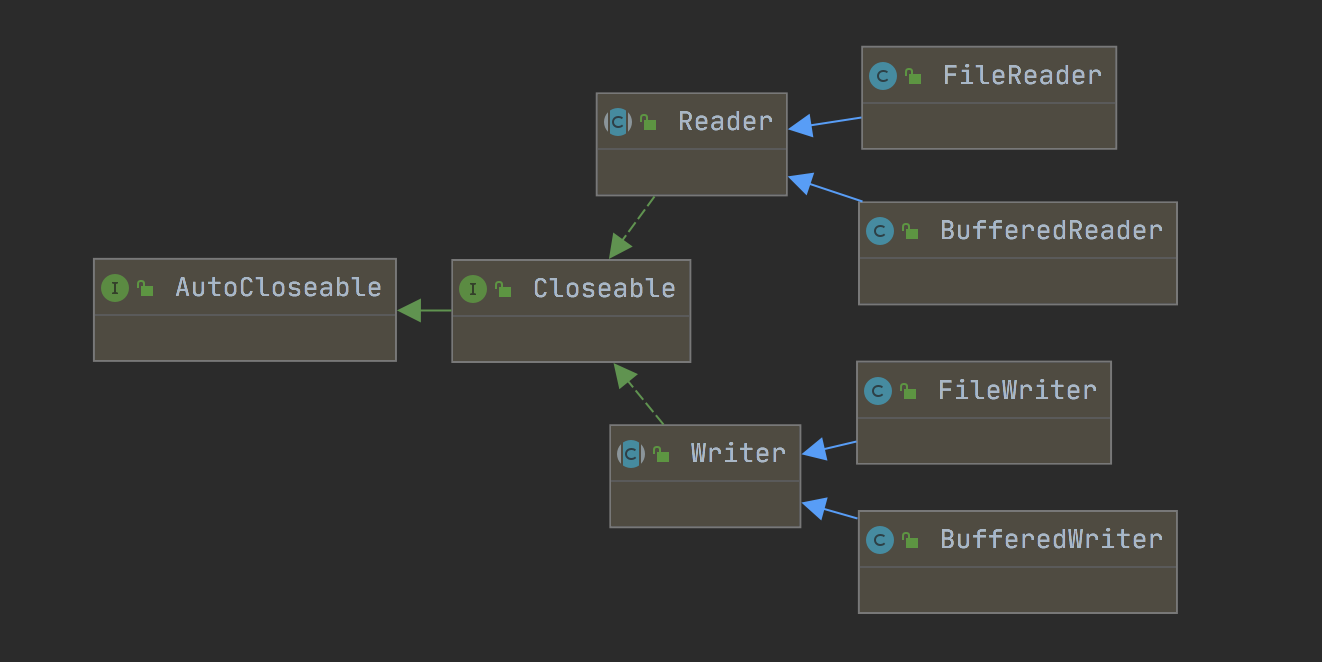
Character stream base API:
public class IoChar01 {
public static void main(String[] args) throws Exception {
// Read text write text
File readerFile = new File(IoParam.BASE_PATH+"io-text.txt") ;
File writerFile = new File(IoParam.BASE_PATH+"copy-"+readerFile.getName()) ;
// Character input / output stream
Reader reader = new FileReader(readerFile) ;
Writer writer = new FileWriter(writerFile) ;
// Character reading and writing
int readSign ;
while ((readSign = reader.read()) != -1){
writer.write(readSign);
}
writer.flush();
// Close flow
writer.close();
reader.close();
}
}
Character stream buffer API:
public class IoChar02 {
public static void main(String[] args) throws Exception {
// Read text write text
File readerFile = new File(IoParam.BASE_PATH+"io-text.txt") ;
File writerFile = new File(IoParam.BASE_PATH+"line-"+readerFile.getName()) ;
// Buffered character input / output stream
BufferedReader bufReader = new BufferedReader(new FileReader(readerFile)) ;
BufferedWriter bufWriter = new BufferedWriter(new FileWriter(writerFile)) ;
// Character reading and writing
String line;
while ((line = bufReader.readLine()) != null){
bufWriter.write(line);
bufWriter.newLine();
}
bufWriter.flush();
// Close flow
bufWriter.close();
bufReader.close();
}
}
Character stream application scenario: files are used as data carriers, such as Excel, CSV, TXT, etc.
4. Encoding and decoding
- Encoding: character conversion to byte;
- Decoding: converting bytes into characters;
public class EnDeCode {
public static void main(String[] args) throws Exception {
String var = "IO flow" ;
// code
byte[] enVar = var.getBytes(StandardCharsets.UTF_8) ;
for (byte encode:enVar){
System.out.println(encode);
}
// decode
String deVar = new String(enVar,StandardCharsets.UTF_8) ;
System.out.println(deVar);
// Garbled code
String messyVar = new String(enVar,StandardCharsets.ISO_8859_1) ;
System.out.println(messyVar);
}
}
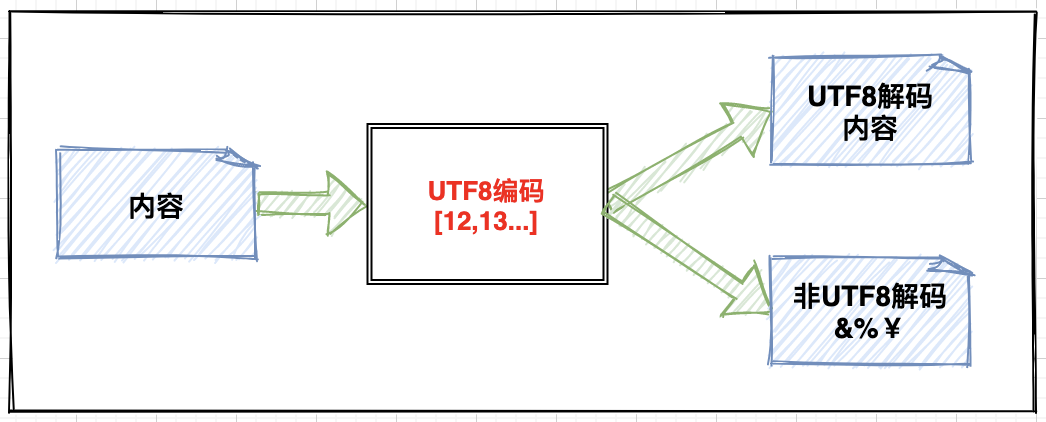
The root cause of garbled code is the different coding types used in the two stages of coding and decoding.
5. Serialization
- Serialization: the process of converting an object into a stream;
- Deserialization: the process of converting a stream into an object;
public class SerEntity implements Serializable {
private Integer id ;
private String name ;
}
public class Seriali01 {
public static void main(String[] args) throws Exception {
// serialized objects
OutputStream outStream = new FileOutputStream("SerEntity.txt") ;
ObjectOutputStream objOutStream = new ObjectOutputStream(outStream);
objOutStream.writeObject(new SerEntity(1,"Cicada"));
objOutStream.close();
// Deserialize object
InputStream inStream = new FileInputStream("SerEntity.txt");
ObjectInputStream objInStream = new ObjectInputStream(inStream) ;
SerEntity serEntity = (SerEntity) objInStream.readObject();
System.out.println(serEntity);
inStream.close();
}
}
Note: the member object of reference type must also be serializable, otherwise NotSerializableException will be thrown.
5, NIO mode
1. Basic concepts
NIO (nonblocking IO), a data block oriented processing mechanism and a synchronous non blocking model. A single thread on the server can process multiple client requests, which greatly improves the processing speed of IO streams. There are three core components:
- Buffer: the underlying maintenance array stores data;
- Channel: supports two-way read-write operations;
- Selector: provides multi Channel registration and polling capabilities;
API use cases
public class IoNew01 {
public static void main(String[] args) throws Exception {
// Source file destination file
File source = new File(IoParam.BASE_PATH+"fileio-02.png") ;
File target = new File(IoParam.BASE_PATH+"channel-"+source.getName()) ;
// Input byte stream channel
FileInputStream inStream = new FileInputStream(source);
FileChannel inChannel = inStream.getChannel();
// Output byte stream channel
FileOutputStream outStream = new FileOutputStream(target);
FileChannel outChannel = outStream.getChannel();
// Direct channel replication
// outChannel.transferFrom(inChannel, 0, inChannel.size());
// Buffer read-write mechanism
ByteBuffer buffer = ByteBuffer.allocateDirect(1024);
while (true) {
// Read data from channel to buffer
int in = inChannel.read(buffer);
if (in == -1) {
break;
}
// Read write switching
buffer.flip();
// Write buffer data
outChannel.write(buffer);
// Empty buffer
buffer.clear();
}
outChannel.close();
inChannel.close();
}
}
The above case is only the most basic file replication capability of NIO. In network communication, NIO mode has a wide space to play.
2. Network communication
The single thread of the server can process multiple client requests and check whether there are IO requests by polling the multiplexer. In this way, the concurrency of the server is greatly improved and the resource consumption is significantly reduced.
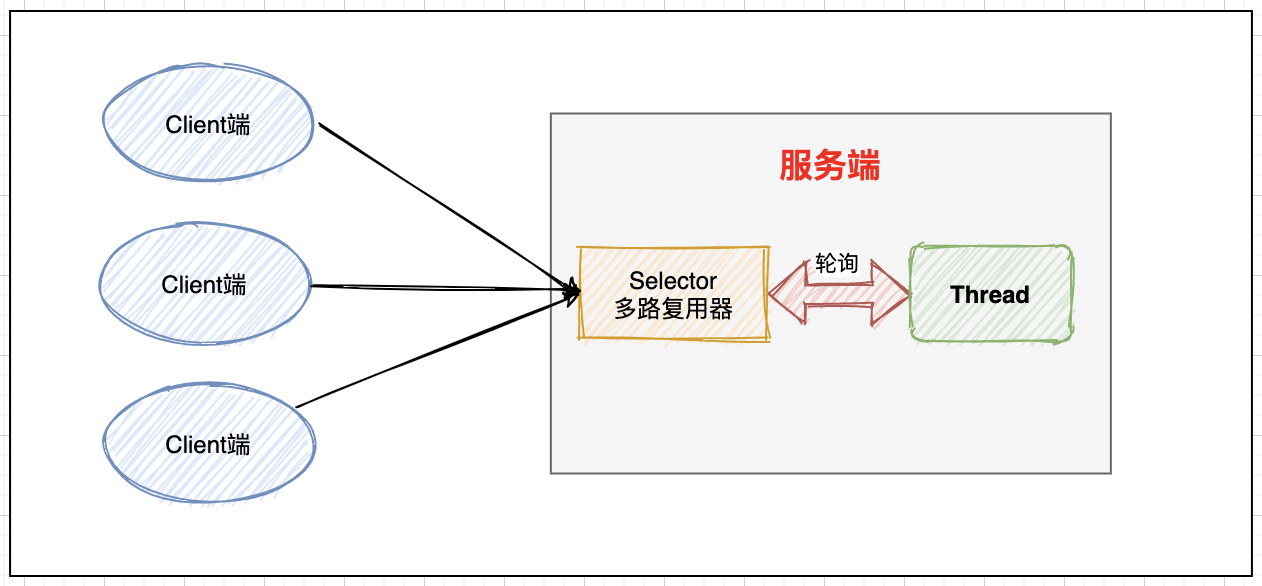
API case: server simulation
public class SecServer {
public static void main(String[] args) {
try {
//Start the service and enable listening
ServerSocketChannel socketChannel = ServerSocketChannel.open();
socketChannel.socket().bind(new InetSocketAddress("127.0.0.1", 8089));
// Set non blocking, accept clients
socketChannel.configureBlocking(false);
// Turn on the multiplexer
Selector selector = Selector.open();
// The server Socket registers with the multiplexer and specifies interest events
socketChannel.register(selector, SelectionKey.OP_ACCEPT);
// Multiplexer polling
ByteBuffer buffer = ByteBuffer.allocateDirect(1024);
while (selector.select() > 0){
Set<SelectionKey> selectionKeys = selector.selectedKeys();
Iterator<SelectionKey> selectionKeyIter = selectionKeys.iterator();
while (selectionKeyIter.hasNext()){
SelectionKey selectionKey = selectionKeyIter.next() ;
selectionKeyIter.remove();
if(selectionKey.isAcceptable()) {
// Accept new connections
SocketChannel client = socketChannel.accept();
// Set read nonblocking
client.configureBlocking(false);
// Register to multiplexer
client.register(selector, SelectionKey.OP_READ);
} else if (selectionKey.isReadable()) {
// Channel readable
SocketChannel client = (SocketChannel) selectionKey.channel();
int len = client.read(buffer);
if (len > 0){
buffer.flip();
byte[] readArr = new byte[buffer.limit()];
buffer.get(readArr);
System.out.println(client.socket().getPort() + "Port data:" + new String(readArr));
buffer.clear();
}
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
API case: client simulation
public class SecClient {
public static void main(String[] args) {
try {
// Connect server
SocketChannel socketChannel = SocketChannel.open();
socketChannel.connect(new InetSocketAddress("127.0.0.1", 8089));
ByteBuffer writeBuffer = ByteBuffer.allocate(1024);
String conVar = "[hello-8089]";
writeBuffer.put(conVar.getBytes());
writeBuffer.flip();
// Send data every 5S
while (true) {
Thread.sleep(5000);
writeBuffer.rewind();
socketChannel.write(writeBuffer);
writeBuffer.clear();
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
SelectionKey binds the association between Selector and Channel, and can obtain the Channel collection in ready state.
The IO stream is the same as the series of articles:
| IO stream overview | MinIO Middleware | FastDFS Middleware | Xml and CSV files | Excel and PDF files | File upload logic |
6, Source code address
GitHub·address https://github.com/cicadasmile/java-base-parent GitEE·address https://gitee.com/cicadasmile/java-base-parent

Reading labels
[Java Foundation][Design pattern][Structure and algorithm][Linux system][database]
[Distributed architecture][Microservices][Big data component][SpringBoot advanced][Spring & Boot Foundation]