This is a record of the whole back-end development of a real landing project, recording the process from 0 to 1 of the projects I saw and participated in.
catalogue
2, Project development process level
3, Development technology level
4, Reading notes during the project
1, Project overview
Let's talk about what this project does and the part I participate in.
This project is a platform for placing and receiving orders. The administrator realizes order entry, user management, platform attachment function management and platform resource management in the background; Registered users can browse, query, apply for receiving orders and evaluate orders.
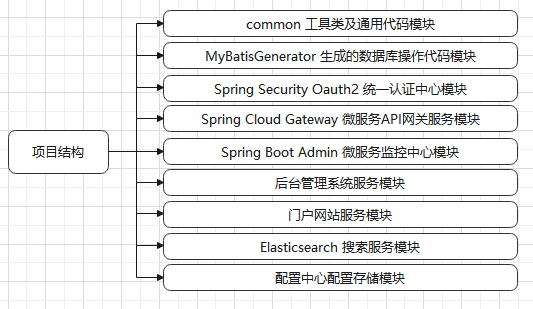
The background includes: common tool class and general code module, database operation code module generated by MyBatisGenerator, Oauth2 certification center module, Gateway gateway service module, monitor micro service monitoring center module, background management system module, portal service module, Elasticsearch search service module and configuration center module.
Development environment: JDK 8, Mysql 5.7, Redis 5.0, elasticsearch 7.6 2,Logstash 7.6.2,Kibana 7.6.2,Gitee
Technical architecture: SpringBoot, mybatis plus, Spring Security Oauth2, Redis, ElasticSearch, MinIO
Participation:
1. Business level: responsible for user management (registration / login, personal information management), administrator management (account information management, role authority management); this part is based on RBAC, including establishing data tables and implementing specific business codes.
2. Technical level: responsible for the implementation of database master-slave replication + multiple data sources + Redis cache.
2, Project development process level
Because it is the first time to participate in a real project, there is no concept of the development process of the whole project. Therefore, the process of developing and learning from 0 to 1 is as important as learning a specific technology. The following is a process I summarized for project development:
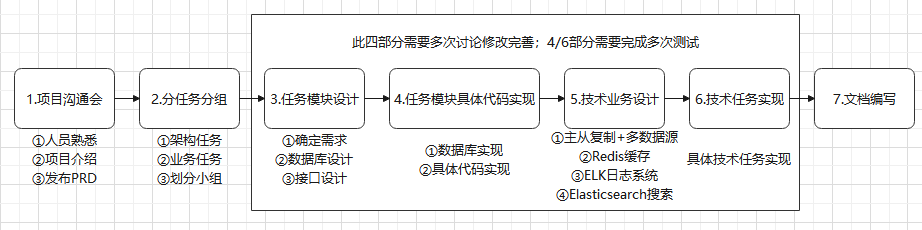
1. Project communication meeting:
The first plenary meeting before the project starts. The contents of this meeting include:
① Mutual familiarity of developers
② The project leader introduces the overview of project functional requirements formulated in the early stage, and introduces the overall project architecture, project development structure and project development cycle planned in the early stage, so that developers can have a preliminary understanding and positioning of the project
③ Release PRD documents to enable developers to further understand the specific contents of the project
2. Sub task grouping:
In essence, this step is to divide the project into small implementation modules, which is an important step in project implementation.
① It is divided into architecture tasks and business tasks according to the specific content
② Select tasks, groups and groups according to previous project understanding and personal direction
3. Task module design
① According to the task module, determine the specific requirements according to the PRD document
② Design database according to requirements (data field, data type, data table structure)
③ Design the interface of Controller layer according to specific requirements (interface address, interface parameters and interface results)
4. Specific code implementation of task module
According to the previous module design, create a data table and write specific code (domain, dao, service, controller, confing)
5. Project technical business design
The previous implementation is the specific business level. After the business level development is completed, the technical level development of the overall project needs to be completed.
① Master slave replication + multiple data sources to achieve read-write separation
② Redis cache enables access acceleration
③ ELK: Elasticsearch+ Logstash+ Kibana implements the log system
④ Elasticsearch implements project search business
6. Realization of project technology and business
Complete the specific implementation according to the previous technical design (such as finishing the configuration process of database master-slave replication)
7. Document preparation
After the completion of the project, it is necessary to document all the design and development in the whole project development process
3, Development technology level
This part mainly records some technologies used in specific development that have not been used before, including:
①RBAC;
② Database related: index, type, non empty;
③ swagger annotation;
④ @ Validation annotation parameter verification;
⑤ mybatis plus lamda expression;
⑥ Use of tool class: objectutil Isnotempty ();
⑦ Everything should be standardized;
⑧ IDEA + Gitee;
⑨ Master slave replication + multiple data sources + read write separation
1.RBAC
A platform has account management requirements such as user login and registration. The most popular is RBAC model: role-based access control. This model is to separate user data, role data and permission data into different data tables, so as to achieve the flexible management of user access based on role Association permissions. RBAC model can be divided into RBAC0, RBAC1, RBAC2 and RBAC3 according to the scale. RBAC0 (user, role and permission) can be used for this project. The specific implementation is as follows:
① Create: five data tables: user table, role table, user_role, permission table and role_permi;
#User table CREATE TABLE `user` ( `id` bigint unsigned NOT NULL AUTO_INCREMENT COMMENT 'User table primary key id', `name` varchar(20) NOT NULL DEFAULT '' COMMENT 'full name', `phone_number` char(11) NOT NULL DEFAULT '' COMMENT 'cell-phone number', `password` varchar(64) NOT NULL DEFAULT '' COMMENT 'password', `is_deleted` bigint unsigned NOT NULL DEFAULT 0 COMMENT 'Is it logically deleted id Represents the deleted user id 0 Means No', `update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT 'Last update time', `create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT 'Creation time', PRIMARY KEY (`id`), UNIQUE KEY `uk_phone_number` (`phone_number`), KEY `idx_name` (`name`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='User table';
-
When creating a data table, important data such as user information should be deleted logically. That is, when deleting the business code, the data will not be deleted from the database. Although the user cannot view it, the administrator can see the data through the background.
-
Each row of data in the data table should record the creation and modification time to support subsequent management analysis. Therefore, fields of creation and modification time are required. (the method built in the database is used here to automatically fill in the time when inserting and modifying data)
#Role table CREATE TABLE `role` ( `id` bigint unsigned NOT NULL AUTO_INCREMENT COMMENT 'Role table primary key id', `name` varchar(20) NOT NULL DEFAULT '' COMMENT 'Role name', `role_description` varchar(64) NOT NULL DEFAULT '' COMMENT 'Role description', `is_deleted` tinyint(1) unsigned NOT NULL DEFAULT 0 COMMENT 'Is it logically deleted? 1 means yes, 0 means No', `update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT 'Last update time', `create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT 'Creation time', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='Role table';
#User role association table CREATE TABLE `user_role` ( `id` bigint unsigned NOT NULL AUTO_INCREMENT COMMENT 'User role association table PK id', `user_id` bigint unsigned NOT NULL DEFAULT 0 COMMENT 'user id', `role_id` bigint unsigned NOT NULL DEFAULT 0 COMMENT 'role id', `is_deleted` tinyint(1) unsigned NOT NULL DEFAULT 0 COMMENT 'Is it logically deleted? 1 means yes, 0 means No', `update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT 'Last update time', `create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT 'Creation time', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='User role association table';
#Authority details CREATE TABLE `permission` ( `id` bigint unsigned NOT NULL AUTO_INCREMENT COMMENT 'Permission details table PK id', `name` varchar(20) NOT NULL DEFAULT '' COMMENT 'Permission name', `permission_description` varchar(64) NOT NULL DEFAULT '' COMMENT 'Permission description', `url` varchar(1000) NOT NULL DEFAULT '' COMMENT 'Permission address json array', `is_deleted` tinyint(1) unsigned NOT NULL DEFAULT 0 COMMENT 'Is it logically deleted? 1 means yes, 0 means No', `update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT 'Last update time', `create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT 'Creation time', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='Authority details';
#Role permission association table CREATE TABLE `role_permission` ( `id` bigint unsigned NOT NULL AUTO_INCREMENT COMMENT 'Role permission association table PK id', `rid` bigint unsigned NOT NULL DEFAULT 0 COMMENT 'role id', `pid` bigint unsigned NOT NULL DEFAULT 0 COMMENT 'jurisdiction id', `is_deleted` tinyint(1) unsigned NOT NULL DEFAULT 0 COMMENT 'Is it logically deleted? 1 means yes, 0 means No', `update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT 'Last update time', `create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT 'Creation time', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='Role permission association table';
② The unique index of the user table and the "is_delete" field establish a federated index to improve the search speed, but a federated index will cause conflict when inserting data. See the blog for details: https://blog.csdn.net/u013310037/article/details/113045905
-
Suggestions for modification are as follows:
yml file configuration
mybatis-plus: global-config: db-config: logic-delete-value: id #The logical deletion value is ID, that is, update is_deleted=id logic-not-delete-value: 0 #The logical undeleted value is 0
Or use the @ TableLogic annotation in the entity class field
@ApiModelProperty(value = "0:No other deleted(id):Deleted")
@TableLogic(delval = "id")
private Long isDeleted;And delete fields logically: change from tinyint to bigint, which is the same as the attributes of the primary key field
RBAC reference blog: https://blog.csdn.net/qq_21743659/article/details/109259004
2. Database table creation: index, type, non empty
-
This project is developed according to Alibaba's specifications, which specify the requirements for the establishment of indexes and the data types of some fields.



-
Non empty field: when the field is null, the index will be discarded and the whole table will be scanned
Learning blog: https://www.cnblogs.com/rocker-pg/p/9908506.html
3. swagger notes
Official description: Swagger is a standardized and complete framework for generating, describing, invoking and visualizing RESTful Web services.
In short, it is a visual back-end interface operation framework. In the front-end and back-end separated projects, the back-end developers use the swagger annotation to generate interface documents (interface address, interface parameters and interface results); the front-end developers use this document to understand the back-end interface and complete the front-end development.
This project uses the Knife4j tool to complete the integration of swagger
What is knife4j https://baijiahao.baidu.com/s?id=1699829803518284149&wfr=spider&for=pc
Use reference: https://blog.csdn.net/qq_27142569/article/details/105884131
Steps to use knifej:
① Add dependency:
<dependency> <groupId>com.github.xiaoymin</groupId> <artifactId>knife4j-spring-boot-starter</artifactId> <version>2.0.2</version> </dependency>
② Create profile:
@Configuration
@EnableSwagger2
@EnableKnife4j
@Import(BeanValidatorPluginsConfiguration.class)
public class SwaggerConfiguration {
@Bean
public Docket api() {
return new Docket(DocumentationType.SWAGGER_2) // Select swagger2 version
.apiInfo(apiInfo()) //Define api document summary information
.select()
.apis(RequestHandlerSelectors
.basePackage("com.dave.controller")) // Specifies the package that generates the api document
.paths(PathSelectors.any()) // Specify all paths
.build()
;
}
/**
* Build document api information
* @return
*/
private ApiInfo apiInfo() {
return new ApiInfoBuilder()
.title("document title") // document title
.contact(new Contact("name", "url", "mail")) //contact information
.description("describe") //describe
.version("0.1") //Document version number
.termsOfServiceUrl("http://localhost:8080 ") / / website address
.build();
}
}③ Using swagger annotations
④ Through access http://localhost: Port number / doc HTML to see the api document page of knife4j
swagger annotation
Official website WIKI: https://github.com/swagger-api/swagger-core/wiki/Annotations-1.5.X#quick-annotation-overview
Common notes:
| @Api() for class | Indicates that this class is a resource of swagger |
|---|---|
| @ApiOperation() for method | Represents the operation of an http request |
| @ApiImplicitParam() for method | Represents a separate request parameter |
| @ApiImplicitParams() for method | Contains multiple @ apiimplicitparams |
| @ApiModel() for class | Represents a description of the class, which is used to receive parameters with entity classes |
| @ApiModelProperty() is used for methods and fields | Represents a description of the model property or a data operation change |
@RestController
@Api(tags = "user management ")
@RequestMapping("/user")
public class UserController {
@Autowired
private UserService userService;
@ApiOperation(value = "Sign in", notes = "Login interface")
@ApiImplicitParam(name = "condition", value = "Information required for user login", dataType = "User")
@PostMapping("/login")
public CommonResult<User> login(@RequestBody @Validated User condition) {
userService.userLogin(condition);
return CommonResult.success(null,"Login succeeded");
}
}@Data
@ApiModel(value = "User object",description = "User table")
public class User implements Serializable {
private static final long serialVersionUID=1L;
@ApiModelProperty(value = "user Primary key id")
@TableId(value = "id", type = IdType.AUTO)
private Long id;
}4.@Validated annotation parameter verification
For the safety of the software system, the interface parameters need to be verified not only at the front end, but also at the back end. By introducing Validation, you can use annotations to complete parameter verification.
Common notes:
| @Validation | When used on interface parameters, subsequent annotation verification takes effect |
|---|---|
| @NotNull | Check that the annotated value is not null |
| @NotEmpty | Check whether the annotated element is null or empty |
| @NotBlank | Check whether the annotated character sequence is not null and the length is greater than 0. The difference from @ NotEmpty is that this constraint can only be applied to strings and trailing whitespace is ignored |
| @Range(min, max) | Check whether the annotated value is between (including) the specified minimum and maximum values |
| @Pattern(regex, flag) | Check whether the annotated string matches the regular expression regex |
The interface parameter uses @ Validated, and the parameters in the User entity class can be verified later
@ApiOperation(value = "Sign in", notes = "Login interface")
@ApiImplicitParam(name = "condition", value = "Information required for user login", dataType = "User")
@PostMapping("/login")
public CommonResult<User> login(@RequestBody @Validated User condition) {
userService.userLogin(condition);
return CommonResult.success(null,"Login succeeded");
}public class User implements Serializable {
@NotEmpty(message = "Password cannot be empty")
@Pattern(regexp = "^1(3|4|5|7|8)\\d{9}$",message = "Mobile phone number format error")
@TableField(value = "phone_number")
private String phoneNumber;
@NotEmpty(message = "Password cannot be empty")
private String password;
}Learning blog: https://blog.csdn.net/qq_32352777/article/details/108424932
And: https://blog.csdn.net/BrightZhuz/article/details/119712778
5. mybatis plus lamda expression
Using lambdaQuery(), you can call the methods in mybatis plus so that you don't have to write mapper XML file
More importantly, you can use the operation of entity field names by means of method reference to avoid unintentional wrong writing when directly writing database table field names
Example:
/**
* Query user data list according to criteria
* @param condition condition
* @return
*/
@Override
public List<User> selectByCondition(User condition) {
List<User> list = this.lambdaQuery()
.eq(ObjectUtil.isNotNull(condition.getId()),User::getId, condition.getId())
.like(StrUtil.isNotBlank(condition.getName()), User::getName, condition.getName())
return list;
}Reference 1: four expressions of lambda
https://blog.csdn.net/weixin_44472810/article/details/105649901
1, Lambdaquerywrapper < >
2, Querywrapper < entity > () lambda()
3, Wrappers< Entity > lambdaquery ()
4, Lambdaquerychainwrapper < entity > (xxmapper)
Reference 2: conditional constructor
https://blog.csdn.net/u012417405/article/details/82994910

Reference 3: chain query
https://blog.csdn.net/qq_25851237/article/details/111713102

6. Use of tool class: objectutil Isnotempty() et al
Integrated tool classes should be used in the project to accelerate the development of the project. More importantly, the use of tool classes can standardize the project code and reduce errors at the same time.
/**
* Object tool classes, including null determination, cloning, serialization and other operations
*
* @author Looly
*/
public class ObjectUtil {
/**
* Check whether the object is null
*/
public static boolean isNull(Object obj) {
//noinspection ConstantConditions
return null == obj || obj.equals(null);
}
}Use example:
/**
* Query user information according to user id
* @param id User id
* @return User information
*/
@Override
public User selectUserById(Long id) {
User user = this.getById(id);
if (ObjectUtil.isNull(user)){
Asserts.fail("No such user found");
}
return user;
}/**
* Collection related tool classes
* <p>
* This tool method is a tool encapsulated for {@ link Collection} and its implementation classes.
* <p>
* Because {@ link Collection} implements the {@ link Iterable} interface, some tools are not provided, but are provided in {@ link IterUtil}
*
* @author xiaoleilu
* @see IterUtil
* @since 3.1.1
*/
public class CollUtil {
/**
* Is the collection non empty
*/
public static boolean isNotEmpty(Collection<?> collection) {
return false == isEmpty(collection);
}
}Use example:
/**
* Add or update a history
* @param browsingHistory
*/
@Override
@Transactional(propagation = Propagation.REQUIRED,rollbackFor = {Exception.class})
public void add(BrowsingHistory browsingHistory) {
//If the same user accesses the same item, only the latest data is stored
LambdaQueryWrapper<BrowsingHistory> eq = new LambdaQueryWrapper<BrowsingHistory>()
.eq(BrowsingHistory::getUserId, browsingHistory.getUserId())
.eq(BrowsingHistory::getProjectId, browsingHistory.getProjectId());
List<BrowsingHistory> list = baseMapper.selectList(eq);
if (CollUtil.isNotEmpty(list)){
int i = baseMapper.update(browsingHistory,eq);
if (i==0){
Asserts.fail("History update failed");
}
}else{
int i = baseMapper.insert(browsingHistory);
if (i==0){
Asserts.fail("Failed to save history");
}
}
}16 tool classes commonly used in Java: https://www.cnblogs.com/nizuimeiabc1/p/9651094.html
7. Everything should be standardized
After participating in this project, I understand the importance of specifications, which can greatly improve efficiency and development quality. In a word, everything should be standardized: the database should be standardized, the fields should be standardized, the interfaces should be standardized, the methods should be standardized, the codes should be standardized, and things should be done carefully.
The project is developed in accordance with Alibaba's specifications: Alibaba Java development manual 1.7.0 (Songshan version), which includes the following contents:

The most viewed part in this development is about MySQL database, as shown in the previous 2 Database table building has been mentioned. Alibaba code specification plug-in has also been added to IDEA:
In addition, the logical structure of the code shall be standardized in the project:
① : the controller layer does not have specific business data operation logic, but only calls the methods in the service. This can reduce the coupling degree of code, and other controllers can also realize business data operations by calling methods in the service.
@RestController
@RequestMapping("/user")
public class UserController {
@Autowired
private UserService userService;
@PostMapping("/login")
public CommonResult<User> login(@RequestBody @Validated User condition) {
userService.userLogin(condition);
return CommonResult.success(null,"Login succeeded");
}②: the service layer reports an error, intercepts the error globally, performs corresponding operations according to the error, and simplifies the logic code (for example, the following)
@Service
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService {
public void userLogin(User condition) {
User user = selectByPhoneNumber(condition.getPhoneNumber());
boolean flag = condition.getPassword().equals(user.getPassword());
if (!flag){
Asserts.fail("Login failed");
}
}
}8. Use of idea + gitee
The previous projects were all done by one person, so gitee has not been used for collaborative development. I was a little confused when I first started. I'd like to record:
① Pull item:
First, create a local repository: VCs - > import into version control - > create git repository
Then clone: VCs - > get from version control
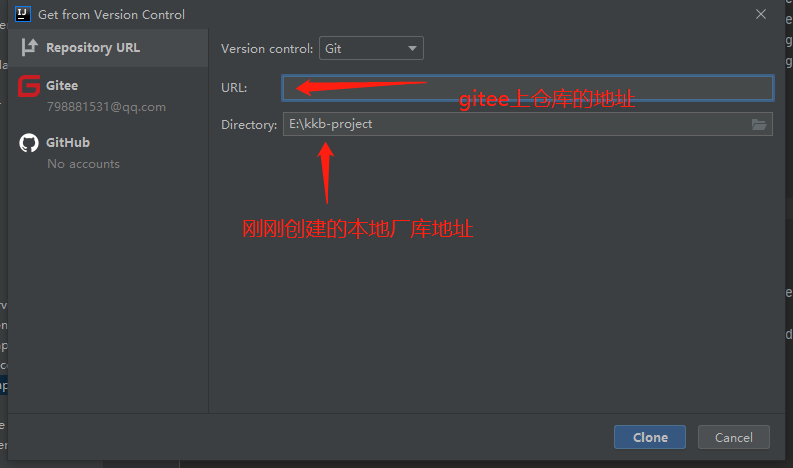
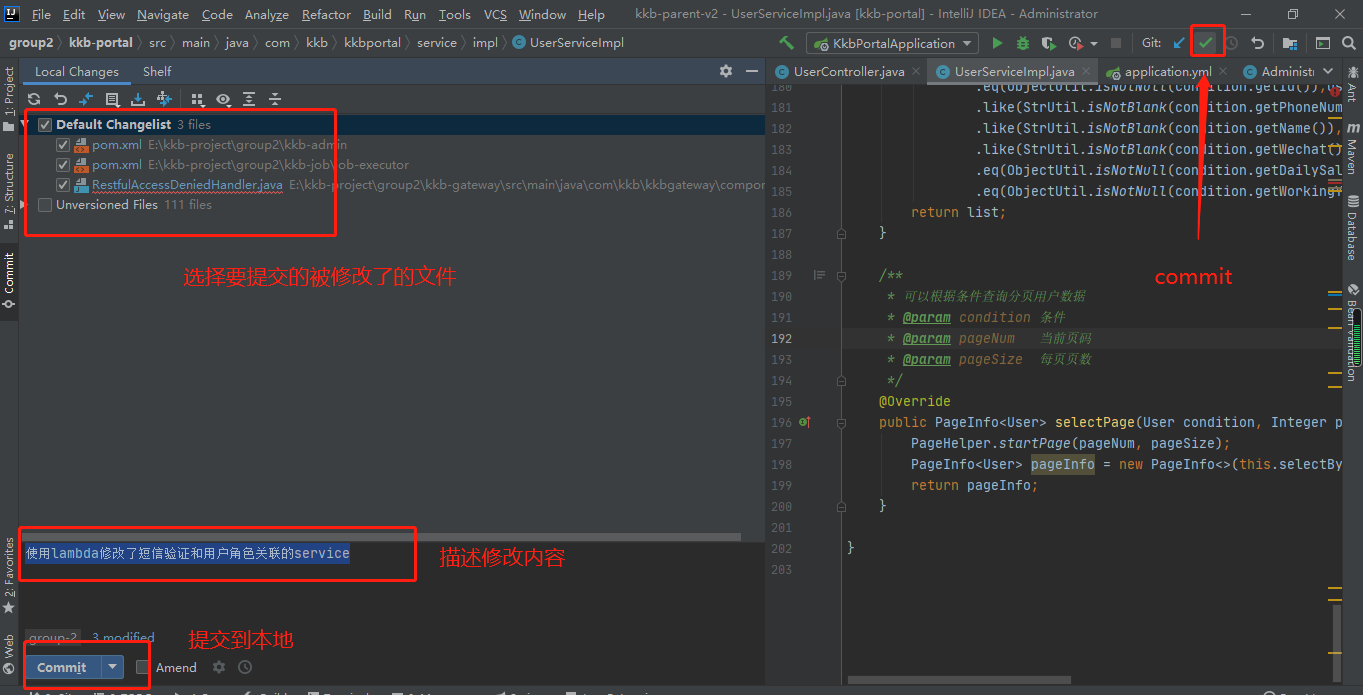
② Submit project:
You need to submit to local first:
Then push to the remote warehouse:
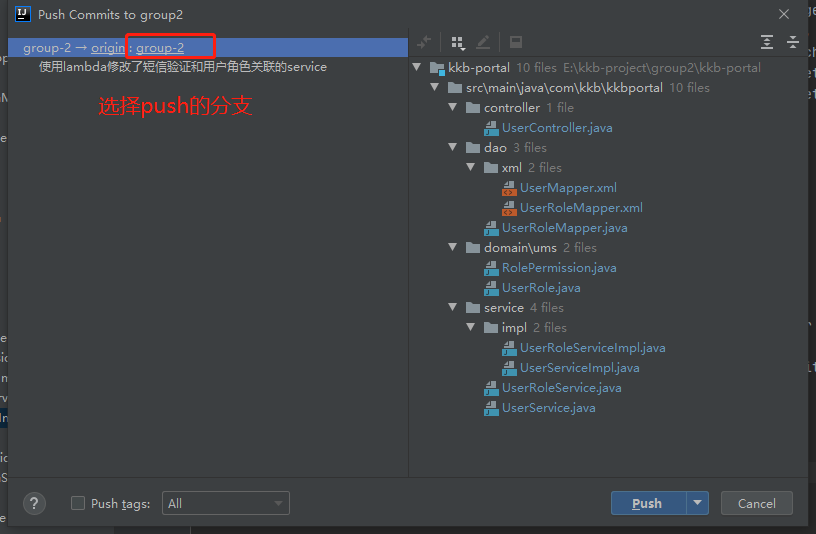
And: https://blog.csdn.net/weixin_45606067/article/details/109536927
9. Master slave replication + multiple data sources + read / write separation
Spring Boot + MyBatis Plus + Druid to separate reading and writing from multiple data sources
(1) The problem of only realizing multi data source discovery
At the beginning, configure multiple data sources according to the blog: (configure multiple data sources according to springboot+mybatis+mysql+yml)
https://blog.csdn.net/weixin_38689747/article/details/114590305
Mapper files with two directories configured:
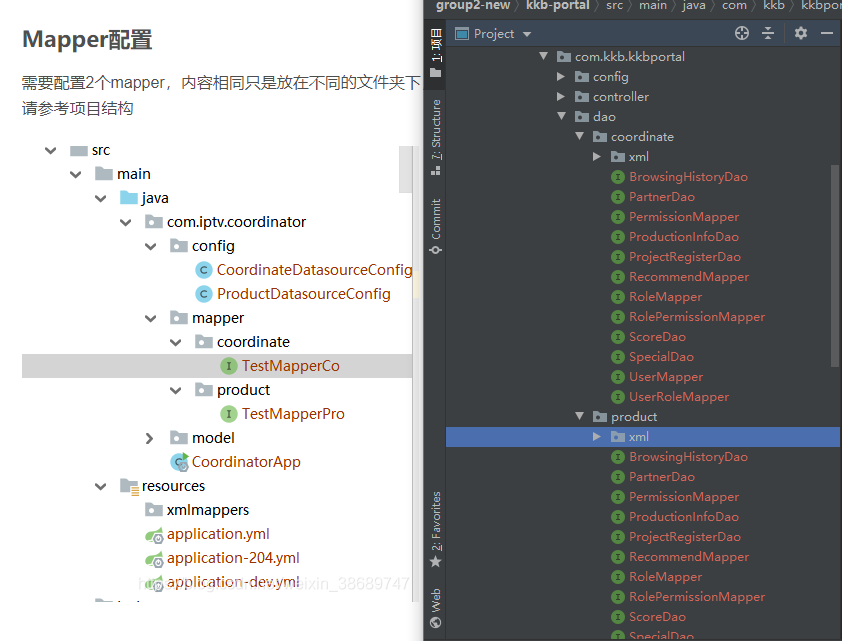
There are two dao problems when the Service uses dao
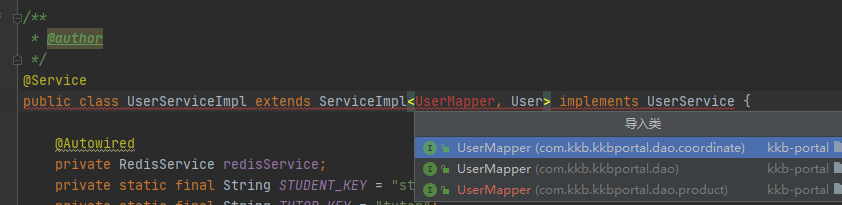
However, there are both write and read in a service. The introduction of multiple data sources is also to achieve read-write separation. Two Daos cannot be introduced at the same time, so this scheme is not applicable here
(2) Separation of reading and writing from multiple data sources
This blog provides four schemes: (Spring+MyBatis to realize the separation of database reading and writing)
https://www.jianshu.com/p/2222257f96d3
Scheme 4:
If your background structure is spring+mybatis, you can achieve very friendly read-write separation through spring's AbstractRoutingDataSource and mybatis Plugin interceptor, and the original code does not need any change.
Refer to blog implementation scheme 4: (SpringBoot+MybatisPlus multi data source configuration, master-slave library read-write separation, complete explanation)
https://blog.csdn.net/fjekin/article/details/79583744
① Configuration file application yaml
spring: application: name: kkb-portal datasource: slave: driver-class-name: com.mysql.cj.jdbc.Driver type: com.alibaba.druid.pool.DruidDataSource url: jdbc:mysql://127.0.0.1:3308/kkb-parent-v2?useUnicode=true&characterEncoding=utf-8&serverTimezone=Asia/Shanghai username: root password: 123465 filters: mergeStat on-off: true master: driver-class-name: com.mysql.cj.jdbc.Driver type: com.alibaba.druid.pool.DruidDataSource jdbc-url: jdbc:mysql://127.0.0.1:3307/kkb-parent-v2?useUnicode=true&characterEncoding=utf-8&serverTimezone=Asia/Shanghai username: root password: 123465 filters: mergeStat druid: initial-size: 5 #Connection pool initialization size min-idle: 10 #Minimum number of free connections max-active: 20 #maximum connection
PS: because in this scheme
The Master data source connection pool adopts HikariDataSource
The Slave data source connection pool adopts DruidDataSource
Therefore, the url of the master should be written as JDBC url, otherwise the following error will be reported:

Refer to the following links for solutions:
Scheme directory structure:
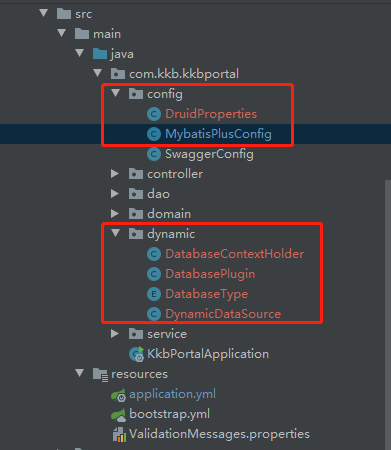
② DruidProperties Druid property configuration
package com.kkb.kkbportal.config;
import com.alibaba.druid.pool.DruidDataSource;
import lombok.Data;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.stereotype.Component;
/**
* <p>Database data source configuration</p>
*/
@Data
@Component
@ConfigurationProperties(prefix = "spring.datasource.slave")
public class DruidProperties {
private String url;
private String username;
private String password;
private String driverClassName;
private Integer initialSize = 2;
private Integer minIdle = 1;
private Integer maxActive = 20;
private Integer maxWait = 60000;
private Integer timeBetweenEvictionRunsMillis = 60000;
private Integer minEvictableIdleTimeMillis = 300000;
private String validationQuery = "SELECT 'x' from dual";
private Boolean testWhileIdle = true;
private Boolean testOnBorrow = false;
private Boolean testOnReturn = false;
private Boolean poolPreparedStatements = true;
private Integer maxPoolPreparedStatementPerConnectionSize = 20;
private String filters = "stat";
private Boolean onOff = false;
public void coinfig(DruidDataSource dataSource) {
dataSource.setUrl(url);
dataSource.setUsername(username);
dataSource.setPassword(password);
dataSource.setDriverClassName(driverClassName);
//Defines the number of initial connections
dataSource.setInitialSize(initialSize);
//Minimum idle
dataSource.setMinIdle(minIdle);
//Define the maximum number of connections
dataSource.setMaxActive(maxActive);
//Maximum waiting time
dataSource.setMaxWait(maxWait);
// Configure how often to detect idle connections that need to be closed. The unit is milliseconds
dataSource.setTimeBetweenEvictionRunsMillis(timeBetweenEvictionRunsMillis);
// Configure the minimum lifetime of a connection in the pool, in milliseconds
dataSource.setMinEvictableIdleTimeMillis(minEvictableIdleTimeMillis);
dataSource.setValidationQuery(validationQuery);
dataSource.setTestWhileIdle(testWhileIdle);
dataSource.setTestOnBorrow(testOnBorrow);
dataSource.setTestOnReturn(testOnReturn);
// Open PSCache and specify the size of PSCache on each connection
dataSource.setPoolPreparedStatements(poolPreparedStatements);
dataSource.setMaxPoolPreparedStatementPerConnectionSize(maxPoolPreparedStatementPerConnectionSize);
try {
dataSource.setFilters(filters);
} catch (Exception e) {
e.printStackTrace();
}
}
}③ DatabaseType data source type
package com.kkb.kkbportal.dynamic;
public enum DatabaseType {
master("write"),slave("read");
private String name;
private DatabaseType(String name) {
this.name = name();
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}④ DatabaseContextHolder data source type processing
package com.kkb.kkbportal.dynamic;
public class DatabaseContextHolder {
private static final ThreadLocal<DatabaseType> contextHolder = new ThreadLocal<>();
public static void setDatabaseType(DatabaseType type) {
contextHolder.set(type);
}
public static DatabaseType getDatabaseType() {
return contextHolder.get();
}
}⑤ DynamicDataSource data source selection record
package com.kkb.kkbportal.dynamic;
import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource;
public class DynamicDataSource extends AbstractRoutingDataSource {
@Override
protected Object determineCurrentLookupKey() {
DatabaseType type = DatabaseContextHolder.getDatabaseType();
if(type == null) {
logger.info("========= dataSource ==========" + DatabaseType.slave.name());
return DatabaseType.slave.name();
}
logger.info("========= dataSource ==========" + type);
return type;
}
}⑥ DatabasePlugin Interceptor: dynamic selection of data sources
package com.kkb.kkbportal.dynamic;
import org.apache.ibatis.executor.Executor;
import org.apache.ibatis.executor.keygen.SelectKeyGenerator;
import org.apache.ibatis.mapping.BoundSql;
import org.apache.ibatis.mapping.MappedStatement;
import org.apache.ibatis.mapping.SqlCommandType;
import org.apache.ibatis.plugin.*;
import org.apache.ibatis.session.ResultHandler;
import org.apache.ibatis.session.RowBounds;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.transaction.support.TransactionSynchronizationManager;
import java.util.Locale;
import java.util.Map;
import java.util.Properties;
import java.util.concurrent.ConcurrentHashMap;
@Intercepts({
@Signature(type = Executor.class, method = "update", args = {
MappedStatement.class, Object.class }),
@Signature(type = Executor.class, method = "query", args = {
MappedStatement.class, Object.class, RowBounds.class,
ResultHandler.class }) })
public class DatabasePlugin implements Interceptor {
protected static final Logger logger = LoggerFactory.getLogger(DatabasePlugin.class);
private static final String REGEX = ".*insert\\u0020.*|.*delete\\u0020.*|.*update\\u0020.*";
private static final Map<String, DatabaseType> cacheMap = new ConcurrentHashMap<>();
@Override
public Object intercept(Invocation invocation) throws Throwable {
boolean synchronizationActive = TransactionSynchronizationManager.isSynchronizationActive();
if(!synchronizationActive) {
Object[] objects = invocation.getArgs();
MappedStatement ms = (MappedStatement) objects[0];
DatabaseType databaseType = null;
if((databaseType = cacheMap.get(ms.getId())) == null) {
//Reading method
if(ms.getSqlCommandType().equals(SqlCommandType.SELECT)) {
//! selectKey is the auto increment ID query primary key (SELECT LAST_INSERT_ID()) method, using the main database
if(ms.getId().contains(SelectKeyGenerator.SELECT_KEY_SUFFIX)) {
databaseType = DatabaseType.master;
} else {
BoundSql boundSql = ms.getSqlSource().getBoundSql(objects[1]);
String sql = boundSql.getSql().toLowerCase(Locale.CHINA).replaceAll("[\\t\\n\\r]", " ");
if(sql.matches(REGEX)) {
databaseType = DatabaseType.master;
} else {
databaseType = DatabaseType.slave;
}
}
}else{
databaseType = DatabaseType.master;
}
logger.warn("Setting method[{}] use [{}] Strategy, SqlCommandType [{}]..", ms.getId(), databaseType.name(), ms.getSqlCommandType().name());
cacheMap.put(ms.getId(), databaseType);
}
DatabaseContextHolder.setDatabaseType(databaseType);
}
return invocation.proceed();
}
@Override
public Object plugin(Object target) {
if (target instanceof Executor) {
return Plugin.wrap(target, this);
} else {
return target;
}
}
@Override
public void setProperties(Properties properties) {
// TODO Auto-generated method stub
}
}⑦ MybatisPlusConfig data source configuration
package com.kkb.kkbportal.config;
import com.alibaba.druid.pool.DruidDataSource;
import com.baomidou.mybatisplus.extension.spring.MybatisSqlSessionFactoryBean;
import com.github.pagehelper.PageInterceptor;
import com.kkb.kkbportal.dynamic.DatabasePlugin;
import com.kkb.kkbportal.dynamic.DatabaseType;
import com.kkb.kkbportal.dynamic.DynamicDataSource;
import org.apache.ibatis.plugin.Interceptor;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.jdbc.DataSourceBuilder;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import javax.sql.DataSource;
import java.util.HashMap;
import java.util.Map;
/**
* @ClassName MybatisPlusConfig
* @Description MybatisPlus Configuration class
* @Author mzj
* @Date 2021/8/13
**/
@Configuration
@MapperScan(basePackages = "com.kkb.kkbportal.dao")
public class MybatisPlusConfig {
@Autowired
DruidProperties druidProperties;
/**
* mp Paging interceptor
* @return PageInterceptor
*/
@Bean
public PageInterceptor pageInterceptor() {
return new PageInterceptor();
}
/**
* Configure master data source
* According to spring. In yaml datasource. master
* @return masterDataSource
*/
@Bean(name = "masterDataSource")
@Qualifier("masterDataSource")
@ConfigurationProperties(prefix = "spring.datasource.master")
public DataSource masterDataSource() {
return DataSourceBuilder.create().build();
}
/**
* Configure slave data source
* Configure according to the previously configured DruidProperties
* @return slaveDataSource
*/
@Bean(name = "slaveDataSource")
@Qualifier("slaveDataSource")
public DataSource slaveDataSource() {
DruidDataSource dataSource = new DruidDataSource();
druidProperties.coinfig(dataSource);
return dataSource;
}
/**
* Construct multi data source connection pool
* Master The data source connection pool adopts HikariDataSource
* Slave The data source connection pool adopts DruidDataSource
* @param master
* @param slave
* @return
*/
@Bean
@Primary
public DynamicDataSource dataSource(@Qualifier("masterDataSource") DataSource master,
@Qualifier("slaveDataSource") DataSource slave) {
Map<Object, Object> targetDataSources = new HashMap<>();
targetDataSources.put(DatabaseType.master, master);
targetDataSources.put(DatabaseType.slave, slave);
DynamicDataSource dataSource = new DynamicDataSource();
// This method is the method of AbstractRoutingDataSource
dataSource.setTargetDataSources(targetDataSources);
// The default datasource is myTestDbDataSourcereturn dataSource;
dataSource.setDefaultTargetDataSource(slave);
return dataSource;
}
@Bean
public MybatisSqlSessionFactoryBean sqlSessionFactory(@Qualifier("masterDataSource") DataSource master,
@Qualifier("slaveDataSource") DataSource slave) throws Exception {
MybatisSqlSessionFactoryBean fb = new MybatisSqlSessionFactoryBean();
fb.setDataSource(this.dataSource(master, slave));
// Whether to start multi data source configuration to facilitate debugging in the local environment without affecting other environments
if (druidProperties.getOnOff() == true) {
fb.setPlugins(new Interceptor[]{new DatabasePlugin()});
}
return fb;
}
}(3) Effect
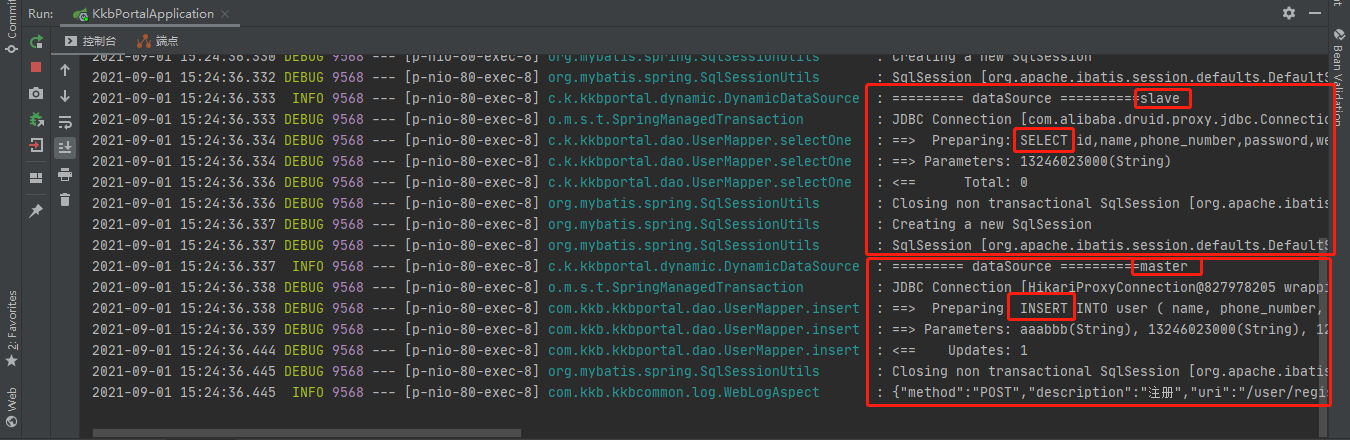
(4) Question
① Inserting the same data does not return a failure, but becomes a query. At present, we don't know what the problem is
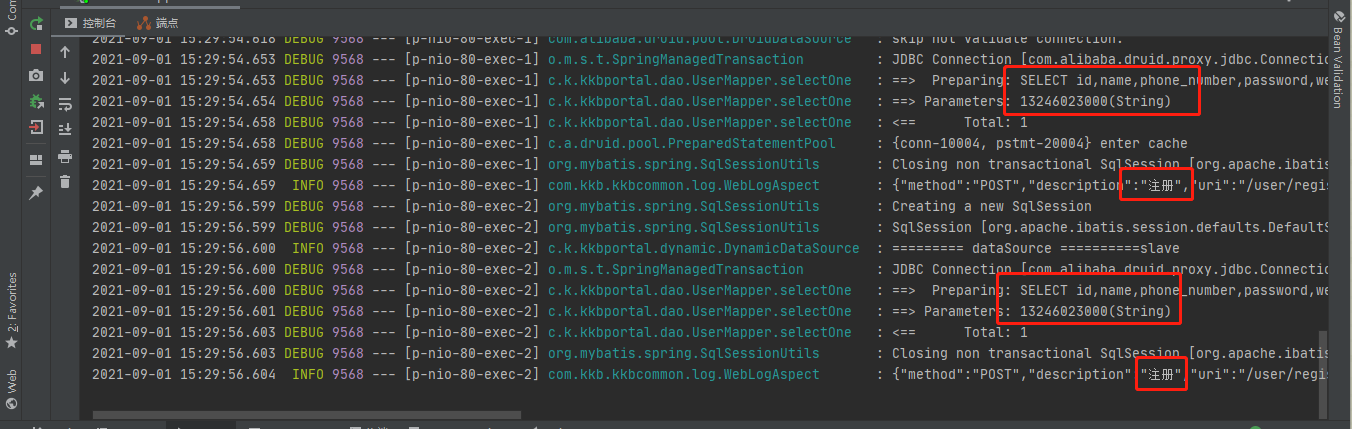
② To be optimized
At present, I only refer to the blog to realize the function, but I feel that there are still many places to be optimized. I haven't fully understood how to realize it, so I need follow-up optimization
5. MyBatis Plus multi data source official website configuration
Official website: https://mp.baomidou.com/guide/dynamic-datasource.html#%E6%96%87%E6%A1%A3-documentation
After working for a long time, I found that there are multiple data source configurations on the official website and @ DS annotation is used to realize read-write separation
usage method:
① Introducing dynamic datasource spring boot starter
② Configure data sources
③ Use @ DS to switch data sources
@DS can be annotated on methods or classes. In principle, method annotations take precedence over class annotations.
| annotation | result |
|---|---|
| No @ DS | Default data source |
| @DS("dsName") | dsName can be a group name or a specific library name |
@Service
@DS("slave")
public class UserServiceImpl implements UserService {
@Autowired
private JdbcTemplate jdbcTemplate;
public List selectAll() {
return jdbcTemplate.queryForList("select * from user");
}
@Override
@DS("slave_1")
public List selectByCondition() {
return jdbcTemplate.queryForList("select * from user where age >10");
}
}4, Reading notes during the project
At the beginning of the project, the book selected was Java core technology sorting. Because of the limited time, I only read the following contents and sorted them out. Although I can't completely accomplish the task of reading, I still agree with it. It's really important and not easy to take time to read and study every day, but knowledge is accumulated in this way. I hope I can spur myself to continue reading and learning.
1. MySQL part
MySQL storage engine (table processor)
Function: receive the upper instruction and operate the data in the table.
Main storage engines: MyISAM, InnoDB and Memory (different storage structures and access algorithms).
Differences between MyISAM and InnoDB:
① Supported transactions: not supported by MyISAM; InnoDB support;
② Storage structure: MyISAM is saved into three files: frm (storage table structure). MYD (storage data). MYI (storage index); InnoDB is stored in two files:. frm (storage table structure). ibd (storage data and index [multiple]);
③ Table lock difference: MyISAM only supports table level locks; InnoDB supports transaction and row level locks;
④ Table primary key: MyISAM allows tables without any indexes and primary keys to exist; InnoDB will automatically generate a 6-byte primary key
⑤ CRUD operation: if MyISAM performs a large number of SELECT operations, it is better; For example, it is better to perform a large number of INSERT or UPDATE operations
⑥ Foreign key: not supported by MyISAM; InnoDB support
MySQL record storage (page structure)
Page header: records the control information of the page, a total of 56 bytes, including the left and right sibling pointers of the page and the usage of page space
Virtual record: ① maximum virtual record: more than the maximum primary key in the page; ② Minimum virtual record: smaller than the minimum primary key in the page
Record heap: row record storage area, which is divided into valid records and deleted records
Free space list: a linked list of deleted records
Unallocated space: unused storage space for the page
Slot area: slot (fixed length)
Footer: the last part of the page, accounting for 8 bytes, mainly stores the verification information of the page
Binary search effect based on Slot: because the data storage structure in the page is a linked list, and the linked list structure does not have an orderly and fixed length structure, binary search cannot be realized. MySQL solutions are: ① use Slot list to realize order; ② Fixed length of each Slot; ③ Traverse in each fixed length Slot. Approximately achieve the effect of binary search
InnoDB memory management:
Buffer pool: preallocated memory pool
page: minimum unit of Buffer pool
Free list: a linked list of free page s
Flush list: dirty page linked list
page hash table: maintain the mapping relationship between memory page and file page
LRU: memory elimination algorithm
LRU: the data with high access heat is placed on the head, and the data with low access heat is naturally moved to the tail. When new data comes in, eliminate the data with low tail heat.
(Mysql solution to avoid the elimination of heat data: two LRU tables)
Indexes:
Improve data retrieval efficiency and reduce database IO cost (understood as: a data structure that quickly finds and arranges order)
MySQL index structure is B + tree:
① B + tree has only leaf nodes to store data; ② Non leaf nodes act as indexes; ③ All leaf nodes are connected by linked list
Advantages: reduce disk IO times and low cost of reading and writing; The leaf node height is the same, and the speed is more stable; B + trees have sequential ID s and are more efficient
Classification: clustered index, secondary index and joint index
Clustered index: leaf node stores row records (InnoDB must have and only have one clustered index)
Secondary index: the leaf node stores the PK value of the primary key
[back to table] (query process of secondary index: ① locate the primary key value through secondary index; ② locate the row record through cluster index)
Joint index (overlay index): an index composed of multiple fields including the primary key. All column data required by SQL can be obtained on one index tree without returning to the table, which is faster
2. JUC concurrent programming [java.util.concurrent]
Volatile keyword:
① It can ensure visibility and order
② But atomicity cannot be guaranteed
③ Prohibit instruction rearrangement (memory barrier)
CAS: [CompareAndSwapInt]
CAS is a system primitive, which belongs to the language specification of the operating system and is composed of several instructions. A process used to complete a function, and the execution of primitives is continuous without interruption; Reflected in Java is sum misc. Various methods in the unsafa class.
CAS is a CPU atomic instruction, which will not cause the so-called data inconsistency problem.
Disadvantages: ① spin lock, cycle all the time, high overhead
② Only one shared variable can guarantee atomicity, and multiple variables need to be locked to ensure atomicity
③ Cause ABA problems
ABA problem: CAS implementation needs to take out the data in memory at a certain moment and compare the replacement data at the current moment, which will lead to time difference and problems
CAS only pays attention to the beginning and end, and accepts it when the beginning and end are consistent. However, if there is a need, it should pay attention to the process and cannot be modified in the middle (AtomicReference atomic reference)
Solution: introduce the version "Stamp" into atomicstampedreferral class
3. Java Foundation
What is Java object-oriented
① Three characteristics of object-oriented: encapsulation, inheritance and polymorphism
② Encapsulation: it is to abstract specific transactions and only provide external interfaces
③ Inheritance: it can realize all the functions of the original class without changing the original class, and can be modified and expanded according to the actual situation
④ Polymorphism: calling the same method can have different responses. Specifically, it is divided into compile time polymorphism: method overload and runtime polymorphism: Method override
⑤ In short, object-oriented is to abstract a specific process into objects, and then use and modify the objects according to different needs, so as to achieve high reusability, high availability and low coupling.
JVM: ① class loading; ② Memory model; ③GC
Class loading: the classloader and its subclasses implement [load - > connect - > initialize]
The first is the loading phase, which puts the class The class file is read into memory, and then the corresponding class object is generated;
Next is the connection phase, which completes the verification, preparation and analysis. Specifically, allocate memory for static variables and set the default initial value; Replace symbol references with direct references;
The last is the initialization stage: if the class has a parent class and is not initialized, initialize the parent class first, and then initialize it in turn ([parent delegation] requests to delegate to the parent class loader to load the class)
Loader: root loader (Bootstrap); extension loader (Extension); Application Loader
Memory model:
PC register: record byte instruction address
Java virtual heap: basic data type, object reference, method exit
Local method heap: basic data type, object reference, method exit (serving local)
Java heap: object instances, arrays
Method area (constant pool): class information, constants and static variables have been loaded
Young: Old = 1:2
[Cenozoic] Eden: Survivor (from: to) = 8:1:1
Garbage collector: ① CMS collector: mark removal algorithm; ② GI collector: tag collation algorithm
Complete GC process:
When Eden area is full, Minor GC is triggered once;
Those who survived were included in the Survivor area, age + 1;
Over 15 years old, promoted to the older generation area;
When the old generation area is full, trigger Major GC (Full GC) once
5, Summary
The project development participation is not too high (this needs to be reviewed), but there are still many achievements. At least through the development process of the project from 0 to 1, I have a preliminary understanding of the specific implementation and implementation process of the project and a certain understanding of the project development process management. At the same time, during the project development process, Shige, as an elder in the industry, shared a lot of life experience with us, which provided me with an unparalleled experience as a layman There are few suggestions on understanding the industry and personal knowledge.
First of all, for personal reasons, he did not participate in the architecture development, nor did he take the initiative to play the role of team leader in promoting project development. I think this project needs to be reviewed because it only completes the tasks according to the assignment and is not proactive enough. Elder martial brother said that I care about one thing: people who work together hope to be people with ability and good character. Because it's easy to work with capable people and learn at the same time; And working with people with good character can finish the work happily. That is to say, a person should have certain ability and relatively good character, which will have a far-reaching impact on his future career. What I care about is that I failed in both of these two points, so next I should think about how to work hard in these two directions.
Then there is communication. A very important point of project development is communication, and collaborative development is even more important. From confirming requirements to module design to code implementation and testing, it needs to be discussed, implemented, modified and improved for many times. Therefore, members need to communicate in time to find and solve problems in time. Lack of communication is making cars behind closed doors, and the things they make can not be used. I am faced with this problem in this development. I am introverted and no one guides me, which leads to the progress can not keep up with other groups. I hope I can pay attention to this and solve it in my future work.
Also, through the project, I at least got started. Because in the development process, in fact, I am a little ignorant after assigning tasks every time, full of blood, but I don't know what to do. For example, let's look at the PRD document sorting requirements. We have finished reading and sorting, but we just don't know what the specific sorting is for. Until I saw the task documents sorted by other groups and the specific data table design, I didn't know why I had to sort out the requirements documents. What should be done in each stage is really understood at the beginning of the next stage. This should be learning. Through this participation, I can't say I understand, but at least I understand and won't be confused again. Shige also said that the focus of participating in a real project is not to write code, but to understand the development process of the project through the project and learn general technologies such as RBAC. At the same time, we should find the direction of learning and efforts through the project. Find the gap between yourself and others and industry through the project, so as to continue to work hard.
Finally, I want to thank elder martial brother and other / her little partners for their company for more than a month. The next thing to do is to digest the project content and continue to work hard.