introduction
Hello, guys, I haven't seen you for a week. During this time, I updated a version of the code generator in my spare time after work and added the previously popular multi data source mode. In this way, the generated code can realize the function of dynamic switching of data sources. Multi data sources are commonly used in projects, such as master-slave read-write separation, Multi database operations need to operate multiple databases in the same project. This update solves this pain point. After generating the code, you can flexibly switch data sources by annotation and support multi database transaction consistency. Let's take a look at the specific implementation effect and the internal principle of dynamic multi data sources by the way!
Generator interface adjustment
In order to realize the multi data source mode, the code generator adjusts the interface as follows:
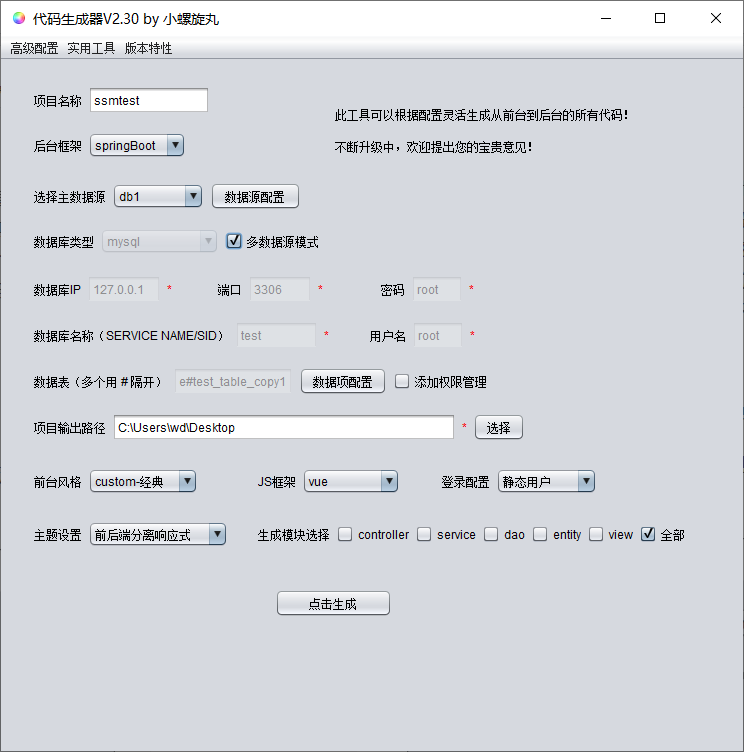
The function of selecting data source is added to the main interface, and now the database information needs to be configured by clicking data source configuration. After clicking, the following window will pop up:
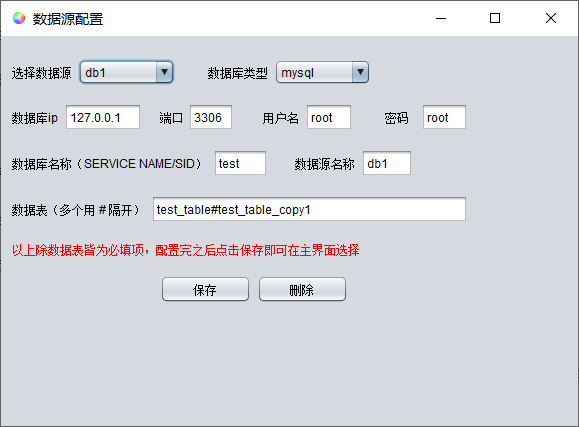
Here we can configure the database information. After configuration, click Save to select in the main interface. The data source selected in the main interface will be used as the default data source in the generated code.
If multi data source mode is checked, multi data source mode code can be generated. If it is not checked, conventional single data source items will be generated as before.
Generally, there is little difference from the original. The basic steps of generating code using multi data source mode are as follows:
- Configuration data source save
- In the main interface, select the data source in turn and configure the data item information
- Check the multi data source mode and click generate code
Generated code display
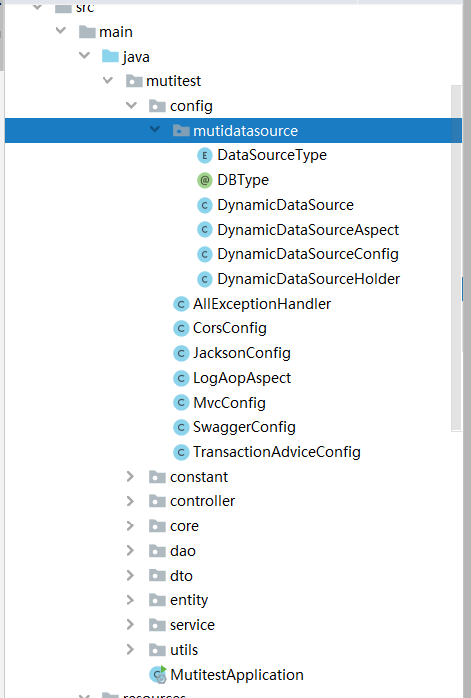
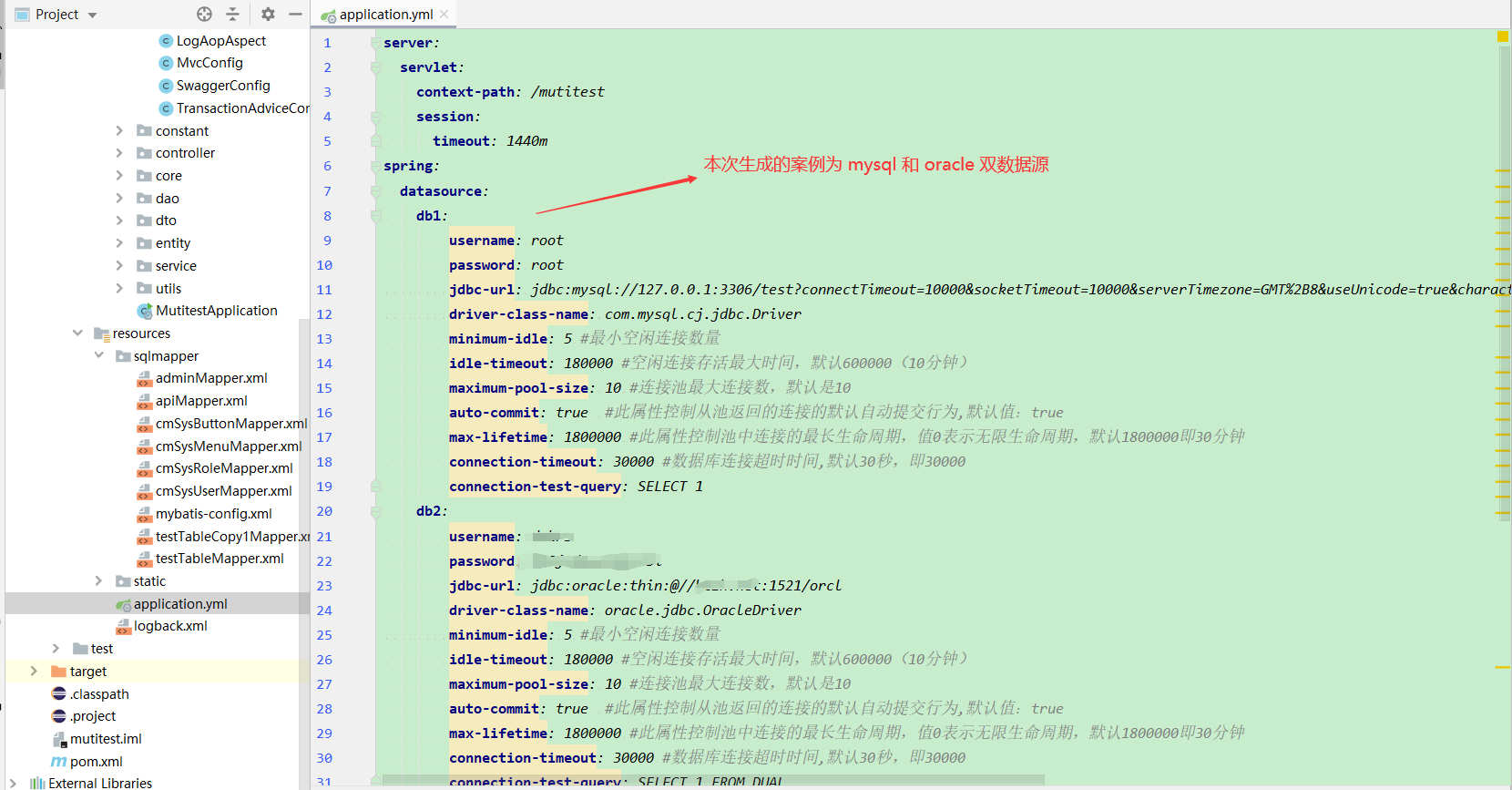
In the multi data source mode, the configuration classes and aspects related to multi data sources will be generated under the config package. If you have personalized needs, you can modify the DynamicDataSourceAspect aspect to realize the dynamic switching logic. The existing switching logic is basically sufficient.
In fact, multiple data sources can also be realized through code subcontracting, which is easy to understand: configure multiple data sources, scan different packages, and create their own sqlSessionFactory and txManager (transaction manager). When using, you can realize the effect of multiple data sources by calling mapper s under different packages, However, the disadvantages of this method are also obvious. Subcontracting will make mistakes if it is careless, and it is troublesome to achieve transaction consistency under different data sources. Therefore, it is limited to operate multiple databases in the same service method.
Dynamic multi data sources will not have the above problems. Therefore, the code generator selects the generation mode of dynamic multi data sources, uses aop to realize the dynamic switching of data sources, and can ensure the consistency of multi database operation transactions, which will be explained in detail later.
Code running effect
Run the generated code in idea, log in after startup, and click the menu on the left to query:
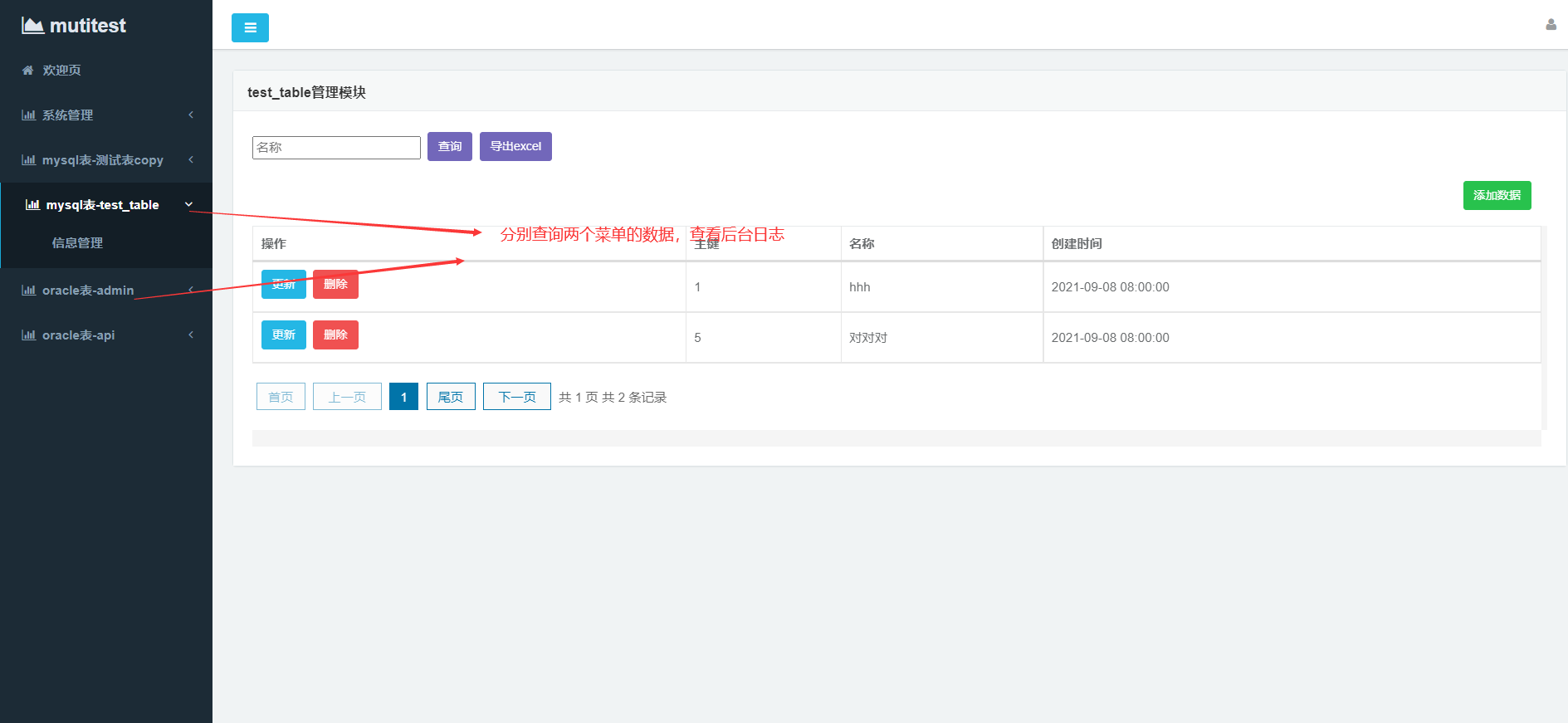
Check the background log and find that different databases will be switched to execute sql:
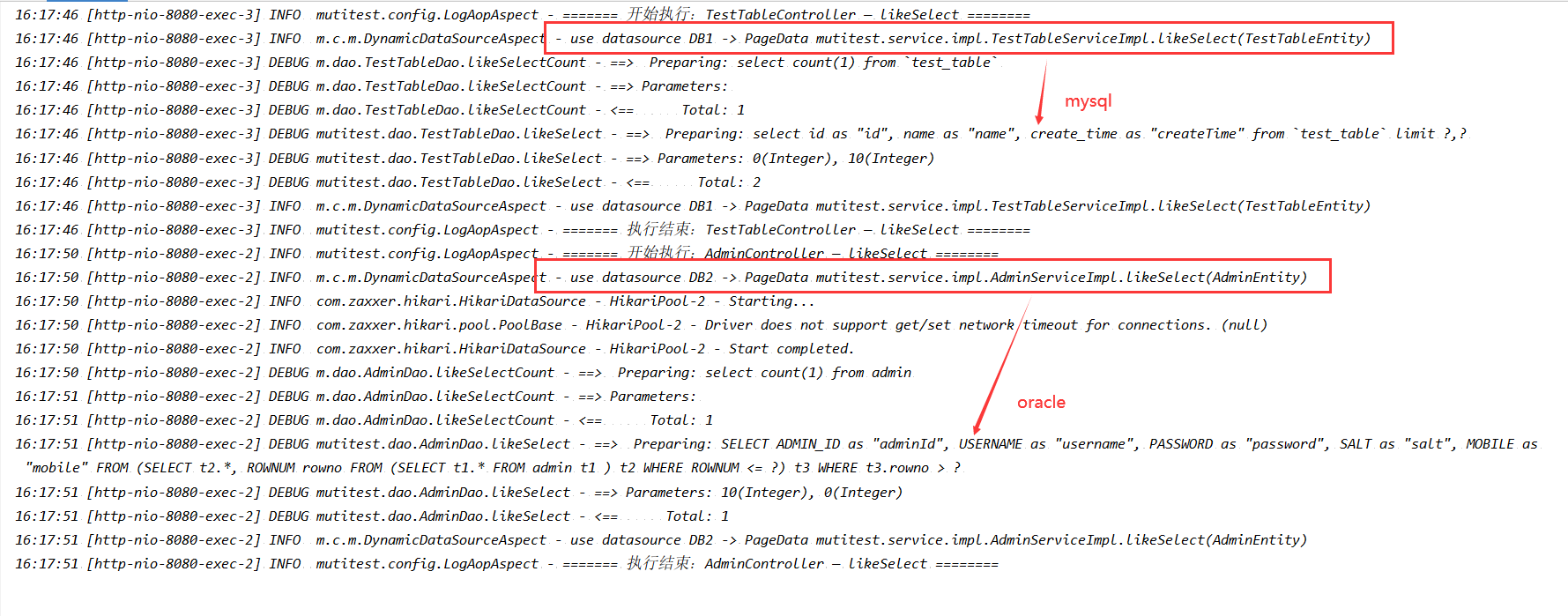
Let's take springboot as an example to talk about the internal principle of multiple data sources.
Internal principle and core code of dynamic multi data source
The internal principle of dynamic multi data sources is actually aop, but the complex is the implementation process of aop.
mybatis provides us with an abstract class AbstractRoutingDataSource. By inheriting this class and overriding the determineCurrentLookupKey method, we can determine which data source to use according to the return value. Therefore, we create a class DynamicDataSource, inherit AbstractRoutingDataSource and override the determineCurrentLookupKey method:
/**
* Override the data source selection method (get the data source set by the current thread)
* @author zrx
*/
public class DynamicDataSource extends AbstractRoutingDataSource {
@Override
protected Object determineCurrentLookupKey() {
}
}
Don't be busy with the implementation first. If you want to correctly match the data source, you also need to register the data source with the DynamicDataSource class, so you need to configure the data source first. Here, register two data sources db1 (mysql) and db2 (oracle). We use the enumeration values db1 and db2 as the key s of the data sources db1 and db2:
package mutitest.config.mutidatasource;
/**
* Data source enumeration
* @author zrx
*/
public enum DataSourceType {
/**
* DB1
*/
DB1,
/**
* DB2
*/
DB2,
}
package mutitest.config.mutidatasource;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.jdbc.DataSourceBuilder;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import org.springframework.jdbc.datasource.DataSourceTransactionManager;
import org.springframework.transaction.PlatformTransactionManager;
import javax.sql.DataSource;
import java.util.HashMap;
import java.util.Map;
/**
* Data source configuration class
*
* @author zrx
*/
@Configuration
public class DynamicDataSourceConfig {
@Bean(name = "db1")
@ConfigurationProperties(prefix = "spring.datasource.db1")
public DataSource db1DataSource() {
return DataSourceBuilder.create().build();
}
@Bean(name = "db2")
@ConfigurationProperties(prefix = "spring.datasource.db2")
public DataSource db2DataSource() {
return DataSourceBuilder.create().build();
}
@Bean
@Primary
public DataSource dynamicDataSource(@Qualifier(value = "db1") DataSource db1,@Qualifier(value = "db2") DataSource db2) {
DynamicDataSource dynamicDataSource = new DynamicDataSource();
//Set default data source
dynamicDataSource.setDefaultTargetDataSource(db1);
Map<Object, Object> dataSourceMap = new HashMap<>();
dataSourceMap.put(DataSourceType.DB1, db1);
dataSourceMap.put(DataSourceType.DB2, db2);
//Register all data source information with the dynamic data source
dynamicDataSource.setTargetDataSources(dataSourceMap);
return dynamicDataSource;
}
@Bean
public PlatformTransactionManager txManager(DataSource dataSource) {
//Returns the transaction manager for the dynamic data source
return new DataSourceTransactionManager(dataSource);
}
}
Through the above configuration, we have successfully registered db1 and db2 with the dynamic datasource. How can we obtain the data source in the current program? This requires us to use ThreadLocal. ThreadLocal can set and get values from the current thread and is not affected by other threads. Each request of our server is processed by a worker thread (nio mode is also a request and a worker thread, but io multiplexing is used when receiving requests), Therefore, ThreadLocal can be used to store the data source of the current working thread. ThreadLocal is used in many open source frameworks, mainly for thread isolation.
Create a DynamicDataSourceHolder class to store the data sources in the current thread:
package mutitest.config.mutidatasource;
import java.util.Arrays;
import java.util.HashSet;
import java.util.Set;
/**
* Data source selector
*
* @author zrx
*/
public class DynamicDataSourceHolder {
private static final ThreadLocal<DataSourceType> DATA_SOURCE_HOLDER = new ThreadLocal<>();
private static final Set<DataSourceType> DATA_SOURCE_TYPES = new HashSet<>();
static {
//Add all enumerations
DATA_SOURCE_TYPES.addAll(Arrays.asList(DataSourceType.values()));
}
public static void setType(DataSourceType dataSourceType) {
if (dataSourceType == null) {
throw new NullPointerException();
}
DATA_SOURCE_HOLDER.set(dataSourceType);
}
public static DataSourceType getType() {
return DATA_SOURCE_HOLDER.get();
}
static void clearType() {
DATA_SOURCE_HOLDER.remove();
}
static boolean containsType(DataSourceType dataSourceType) {
return DATA_SOURCE_TYPES.contains(dataSourceType);
}
}
Then, implement the determineCurrentLookupKey method, and one line of code is enough:
@Override
protected Object determineCurrentLookupKey() {
return DynamicDataSourceHolder.getType();
}
Finally, if we want to realize the dynamic switching of data sources, we need to implement a dynamic aspect of data sources to change the data sources in the current thread. We can use annotations to assist the implementation. In the aspect, we can know which data source to switch to by scanning the annotations on the method.
Create DBType annotation:
package mutitest.config.mutidatasource;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
/**
* Multi data source annotation
* @author zrx
*/
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface DBType {
DataSourceType value() default DataSourceType.DB1;
}
Create a data source dynamic aspect DynamicDataSourceAspect:
package mutitest.config.mutidatasource;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.annotation.After;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.core.annotation.Order;
import org.springframework.stereotype.Component;
/**
* Dynamic data source aspect (order must be set, otherwise the transaction aspect will be executed first. If the data source has been set, it will be invalid)
* @author zrx
*/
@Aspect
@Component
@Order(1)
public class DynamicDataSourceAspect {
private static final Logger logger = LoggerFactory.getLogger(DynamicDataSourceAspect.class);
@Before("@annotation(dbType)")
public void changeDataSourceType(JoinPoint joinPoint, DBType dbType) {
DataSourceType curType = dbType.value();
//Judge annotation type
if (!DynamicDataSourceHolder.containsType(curType)) {
logger.info("specify data source[{}]Does not exist, use default data source-> {}", dbType.value(), joinPoint.getSignature());
} else {
logger.info("use datasource {} -> {}", dbType.value(), joinPoint.getSignature());
// Switch the data source of the current thread
DynamicDataSourceHolder.setType(dbType.value());
}
}
@After("@annotation(dbType)")
public void restoreDataSource(JoinPoint joinPoint, DBType dbType) {
logger.info("use datasource {} -> {}", dbType.value(), joinPoint.getSignature());
//After the method is executed, it is emptied to prevent memory leakage
DynamicDataSourceHolder.clearType();
}
}
The @ Order annotation needs to be added on the data source aspect, and the value is 1. This is because we have configured the dynamic data source transaction before. Therefore, spring will generate the transaction agent and take precedence over the aspect execution. Once the transaction agent is generated, the data source will be fixed, so it will be invalid for us to switch the data source in the aspect, Therefore, the aspect logic needs to be executed before the transaction agent to take effect.
So far, the basic implementation of dynamic multi data sources has been completed!
Transaction consistency problem
When using dynamic multiple data sources, you should also pay attention to ensuring transaction consistency. You may encounter this situation. In traditional single data source applications, the same service invokes the method of opening the transaction in the method that does not open the transaction, which will lead to transaction failure. This is because spring will only proxy the same service once, Otherwise, if the self proxy is opened again in the method that does not open the transaction, the circular dependency problem will occur, which is similar to the "infinite Doll": the method of the self proxy calls another method of the self proxy, and the other method also needs its own proxy. The method to solve this problem is very simple. Let the caller start the transaction, which is also applicable in the multi data source mode.
In addition, there are the following scenarios in the multi data source mode: Methods A and B in serviceA start transactions, but operate on different databases (different ip). At this time, a calls B and uses the agent of A. if it is not applicable to B, an error will be reported. Therefore, we can move method B to another serviceB and inject serviceB into serviceA, In method a, serviceB is used to call method B. in this way, the agent of serviceB is used when executing method B. It seems that there is no problem, but there is another omission, that is, the propagation behavior of transactions.
As we all know, the default transaction propagation behavior in Spring is required: if you need to start a transaction, start the transaction. If you have already started a transaction, add the current transaction. In the above, although the agent of serviceB is used when executing method B, because its transaction propagation behavior is required and the transaction has been started when executing method a, method B is added to the transaction of method A. However, a and B belong to two different databases, and using the same transaction manager will inevitably cause problems. To solve this problem, we can change the transaction propagation behavior to required_new: if you need to start a transaction, start the transaction and always start a new transaction. In this way, a new transaction will be opened when executing method B. the transaction manager of the database where B is located is used, and method B can be executed normally. If B has an exception and a does not actively capture it, both a and B will roll back.
Some people may ask why there is no such problem when using required in the single data source mode. Because the same database is used in the single data source mode, the current transaction is shared and common during transaction execution, so there is no problem. In addition, the use of required does not require frequent and heavy transactions, but also improves the system performance to a certain extent. In the multi data source mode, the use of required is required because the transactions between different databases are completely isolated_ The new restart transaction, of course, also needs to be analyzed according to the specific business scenarios. Only the more general cases are discussed here.
The transaction propagation behavior used by the code generator in the multi data source mode is required_new, the global configuration class is as follows:
package mutitest.config;
import org.aspectj.lang.annotation.Aspect;
import org.springframework.aop.Advisor;
import org.springframework.aop.aspectj.AspectJExpressionPointcut;
import org.springframework.aop.support.DefaultPointcutAdvisor;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.transaction.PlatformTransactionManager;
import org.springframework.transaction.TransactionDefinition;
import org.springframework.transaction.interceptor.DefaultTransactionAttribute;
import org.springframework.transaction.interceptor.NameMatchTransactionAttributeSource;
import org.springframework.transaction.interceptor.TransactionInterceptor;
/**
* Global transaction support
*
* @author zrx
*
*/
@Aspect
@Configuration
public class TransactionAdviceConfig {
private static final String AOP_POINTCUT_EXPRESSION = "execution(* mutitest.service.impl.*.*(..))";
@Autowired
private PlatformTransactionManager transactionManager;
@Bean
public TransactionInterceptor txAdvice() {
DefaultTransactionAttribute txAttr_REQUIRED = new DefaultTransactionAttribute();
txAttr_REQUIRED.setPropagationBehavior(TransactionDefinition.PROPAGATION_REQUIRES_NEW);
DefaultTransactionAttribute txAttr_REQUIRED_READONLY = new DefaultTransactionAttribute();
txAttr_REQUIRED_READONLY.setPropagationBehavior(TransactionDefinition.PROPAGATION_REQUIRES_NEW);
txAttr_REQUIRED_READONLY.setReadOnly(true);
NameMatchTransactionAttributeSource source = new NameMatchTransactionAttributeSource();
//You can add methods that need to be represented by transactions according to business needs
source.addTransactionalMethod("add*", txAttr_REQUIRED);
source.addTransactionalMethod("delete*", txAttr_REQUIRED);
source.addTransactionalMethod("update*", txAttr_REQUIRED);
source.addTransactionalMethod("select*", txAttr_REQUIRED_READONLY);
source.addTransactionalMethod("likeSelect*", txAttr_REQUIRED_READONLY);
return new TransactionInterceptor(transactionManager, source);
}
@Bean
public Advisor txAdviceAdvisor() {
AspectJExpressionPointcut pointcut = new AspectJExpressionPointcut();
pointcut.setExpression(AOP_POINTCUT_EXPRESSION);
return new DefaultPointcutAdvisor(pointcut, txAdvice());
}
}
So far, we have realized a complete dynamic multi data source function. It can be seen that there are many technical details hidden in it. Friends can use the code generator to generate the code in the multi data source mode and run it by themselves.
epilogue
This article ends here. In fact, it took a lot of effort to write the multi data source generation function. It is easy to write code, but it is really not easy to generate in turn. Moreover, because the multi data source situation was not taken into account at the beginning, the initial design was all aimed at a single database. This time, it was forced to make a layer outside, and it was finally realized, During this process, I also reviewed Spring's circular dependency, Bean loading cycle and other old issues, which is also rewarding. As developers, we should pay more attention to the underlying functions rather than simple api calls, so as to continuously break through the bottleneck and achieve growth. The code word is not easy. You watchers can praise it. Watch it. Pay attention to the star sign. See you next time!
Focus on the official account spiral programming geeks acquire the latest developments in code generator, and at the same time, unlock more exciting content.