preface
HashMap is a data structure of key value pairs. Given a unique key, get value. The previous two articles said that ArrayList is particularly efficient in random access. LinkedList is efficient for random insertion and deletion. The HashMap in jdk integrates these two advantages.
Now jdk11 it's out. But most of our work uses jdk7. I wrote this HashMap after reading jdk7 and jdk8. Both have reference ideas. (refer to the idea of JDK. It's not an explanation of the JDK source code. I hope it won't cause you misunderstanding.)
Aside: in addition, I hope you still use jdk8. Try to use jdk8 for new projects. The optimization of java is a qualitative leap. As we all know, jdk5 started as a qualitative leap (Introducing generics, foreach, automatic boxing / unpacking, variable length parameters, etc.), but jdk8 has greatly improved the performance of locks and collections. And add the processing set of stream. There is also the addition of lamdba expression, so that you don't have to write so long code when writing function interfaces (such as Runable).
The HashMap written in this article is only a simple version of the key value pair set to help you understand. In terms of naming, some have referred to the naming rules of jdk!
Focus
Not just HashMap, in any collection, you should pay attention to the following points:
Can it be empty: key can have a null, and value is optional
Whether the hash code is in order (whether the order at the time of insertion is consistent with that at the time of reading): the hash code is random, so it is out of order
Allow repetition: key is definitely not allowed, value is optional
Thread safe: thread is not safe (jdk8 the following links will appear)
Characteristics: the time complexity is constant
principle
There is an Entry (internally defined class) array inside, which takes the hash value of the newly added element and the length of the array. Then put it at the corresponding subscript position of the array. What if the calculated hash is the same and the corresponding array subscript already has elements?? For example, LinkedList (here is a one-way linked list) is added to the head of the linked list in the form of a linked list. If your data is such a coincidence that the subscripts of all data are in the same position, you can keep the chain. At this time, the time complexity of get(key) is equivalent to that of linked list, but this situation is rare (hash algorithm will be analyzed in detail later). However, jdk8 has optimized here. If the length of the linked list > = 8, it will be transformed into a red black tree (the characteristics of the red black tree can find the data by yourself). The average time complexity of binary lookup tree is O(LogN), and the efficiency is much higher than that of linked list. (I personally think that hash is highly random, evenly distributed, and the array capacity is expanded, so there should be few cases where the length of the linked list is > 8, and the cost of transforming the red black tree also exists. The space occupation is related to the performance cost of transforming the linked list into the red black tree.)
realization
Constructor: first, define our HashMap and store the Entry class internally. The above principle: the length of our default array is 16 and there is a LOAD_FACTOR load factor is used for capacity expansion. The default is 0.75, that is, when the element > 16 * 0.75 = 12, capacity expansion occurs. We define a variable threshold for this 12, and modify this value after each expansion. The implementation is as follows:
/**
* @author HK
* jdk7 In jdk8, I prefer to be named Entry, while in jdk8, I prefer to be named Node
*/
public class HkHashMap {
/**
* table Default initial length of
*/
static final int DEFAULT_INITIAL_CAPACITY = 16;
/**
* Load factor, which triggers capacity expansion when it reaches 16 * 0.75
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
Entry[] table;
int size;
/**
* Threshold, when this value is reached, the capacity will be expanded. threshold=DEFAULT_INITIAL_CAPACITY*DEFAULT_LOAD_FACTOR
*/
int threshold;
/**
* Parameterless constructors, of course, specify the initial length and load factor better.
*/
public HkHashMap() {
threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR);
table = new Entry[DEFAULT_INITIAL_CAPACITY];
}
//Storage unit of map
static class Entry{
int hash;
Object key;
Object value;
Entry next;
public Entry(int hash, Object key, Object value, Entry next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
}
}
Focus on the internal class Entry. Calculate the hash value through the key to locate the storage location. Because there is hash collision, it is implemented in the form of single linked list to define the next node. If a subscript on the table array has only one element, the next of the element is null.
Add put(key)
In fact, this api is also used to modify the value of a key. There are only add / delete queries in the HashMap. If the keys are the same, the old value will be overwritten. Next, focus on the put(key) method
First, get the key and get the hashCode of the key (the implementation of jdk will override hashCode and equals). hashCode is a native method of Object class (the values of different virtual machines of the same Object may be different) and returns an int type value. The value of this int type is highly uncertain and its length is not fixed. as follows
public static void main(String[] args) {
String str = "66";
Integer i = 66;
System.out.println("String of HashCode: "+str.hashCode());//1728
System.out.println("Integer of HashCode: "+i.hashCode());//66
}
Therefore, we need a hash algorithm to calculate a number with strong randomness and relatively fixed length. Here, we refer to jdk8 and XOR hashCode high 16 with itself. As follows: you can see that if the key is null, it is fixed in the position of table[0]
/**
* HashCode Do a hash operation. So as to ensure hashing
*/
static final int hash(Object key) {
int h;
//Move the hashCode to the right by 16 bits and perform an XOR operation with the hashCode, that is, the high 16 bits ^ hashCode (refer to jdk8). If the key is null, fix it to the position of table[0]
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
ok, with the hash value, how to determine the position on the array? And the position on the array must be evenly distributed. We take the hash value to the length of the array, and the remainder = hash%table.length. Then put the Entry of this key to the position of table [remainder].
There is a provision for capacity expansion in hashMap that the capacity of table will be twice the original, and it is recommended that the table.length be the N-power of 2. Why? Let's look at the following n-th idempotents of 2, such as 8, 16 and 32. Their binary systems are 1000, 10000 and 100000 respectively. If they are reduced by 1, they become 111111.
Use the following figure to explain: add a key casually, and calculate the hash value of "I am key". If the result is int hash = "555"
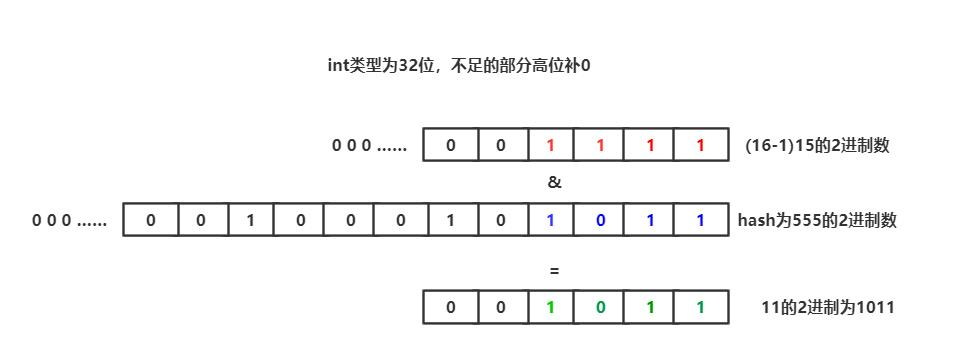
After we perform the and operation, the result is the last four bits of the binary with the hash value of 555. A 4-bit binary number can never be greater than 15. Similarly, when the length of table becomes 32 bits, the binary of 31 is 11111. At this time, the result of the and operation must be a number less than or equal to 31.
Therefore, if the hashMap length is not the nth power of 2, the and operation will have a bad result. If one of the red positions in the figure above is 0, then & after the operation, one will always be 0. At this time, there are positions on the table array that can never store elements, * * or if there are too many red positions 0, only one or two table positions in hashMap will store data, and the performance will be greatly reduced** I didn't notice the optimization of this in the source code before. If the initial length is manually changed to the N-power of 2, it will be automatically adjusted to the N-power of 2 (this red is a modified article, which was wrong for people's children before. I'm sorry).
In the following code, we define the method of finding the position of the table array through hash, which is similar to the method of finding the remainder:
/**
* For any key, you need to find the corresponding hash bucket position after the hash
*/
static int findBucketIndex(int h, int length) {
//The result of the algorithm for finding the remainder is the same.
return h & (length-1);
}
At this point, let's write the put method again
/**
* Add the element. If the key already exists, replace it
*/
public Object put(Object key,Object value){
if(null==key){
return putNullKey(value);
}
int h=hash(key);
int i = findBucketIndex(h,table.length);
//If the key already exists, replace it
for (Entry e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == h && ((k = e.key) == key || key.equals(k))) {
Object oldValue = e.value;
e.value = value;
return oldValue;
}
}
addEntry(h, key, value, i);
return null;
}
void addEntry(int hash, Object key, Object value, int bucketIndex){
Entry e = table[bucketIndex];
table[bucketIndex] =new Entry(hash,key,value,e);
size++;
if(size>threshold){
resize(table.length*2);
}
}
In the above code, lines 5 to 7 deal with the Entry with null key bit. We fix the Entry to the position of table[0],
Line 8 calculates the hash value through the key, and then calculates the position of the key in the hash bucket through the hash value and the length of the table.
Lines 11 ~ 18 are the modification of HashMap, that is, if the key already exists, replace it. (after locating the hash bucket, traverse the one-way linked list of this location).
The hashMap in the jdk, i.e. put, returns null successfully. If the key is a replacement operation, it returns the old value.
Take a look at the addEntry method in lines 23 to 30.
Line 24: assign the Entry of the position of the original hash bucket to the e element. Obviously, if it was originally an empty location, the e is null.
Line 25: the newly added element is placed in the position of table[i], and the original element is linked to the next element in the current position.
27 ~ 29 are related to capacity expansion. It can be seen that when the number of elements is greater than the threshold, the expansion is twice the original. Detailed analysis of capacity expansion, write the last side 👇 (capacity expansion is also implemented differently in different jdk s)
/**
* hashMap Allow the key to be empty, and handle this empty key separately
*/
private Object putNullKey(Object value){
//If there is already a Null Key, replace it
for (Entry e = table[0]; e != null; e = e.next) {
if (e.key == null) {
Object oldValue = e.value;
e.value = value;
return oldValue;
}
}
addEntry(0, null, value, 0);
return null;
}
This is a separate process for the case where the key is null. It will not be explained!
Find get(key)
With the description of the put method, get is much simpler. The core idea is: according to the key, first find the location of the hash bucket, and then traverse the linked list on the location of the hash bucket. If not found, return null. Don't explain too much. Look at the following code!
/**
* Get element
*/
public Object get(Object key){
int h = hash(key);
for(Entry e = table[findBucketIndex(h,table.length)];e!=null;e=e.next){
if(e.hash==h&&(key==e.key||key.equals(e.key))){
return e.value;
}
}
return null;
}
Delete remove(key)
Delete an element according to the key. The core idea is to locate the key and then the position of the table array. After locating it, traverse the linked list at this position. After finding Entry e, cut off the relationship between E and the front and rear linked lists and connect the front and rear nodes, which is the same as the core idea of LinkedListd
For details, the code Notes have been explained and will not be described. As follows:
public Object remove(Object key){
return removeEntryForKey(key);
}
private Entry removeEntryForKey (Object key){
int hash = hash(key.hashCode());
int i = findBucketIndex(hash,table.length);
//First define a prev to represent the previous element to be deleted
Entry prev = table[i];
Entry e=prev;
while(e!=null){
//Locate the next element of e. when we find the element we want to delete, cut off the linked list and connect prev and next. Refer to the deletion of linkedList
Entry next = e.next;
//Locate this element on the linked list, first judge whether the hash value is equal, and then judge whether the equals of the key is equal! Note that if = = returns true here, it indicates that it is a reference, so the judgment of equals can be omitted.
if(e.hash==hash&& (e.key==key||(key!=null&&key.equals(e.key))) ){
size--;//At this time, the existing element is located. Note that the hash value is determined to be equal outside the while. When hash values are equal, equals is not necessarily equal.
//Here, we have to judge whether the Entry located is table[i], because the deletion on table[i] is different from the deletion on the linked list
if(prev==e){
table[i]=next;//Although next may be empty
}else{
prev.next=next;//If it is not in the table position, it is the element behind the linked list. At this time, set the next prev as the next of E. at this time, e has been cut off and the front and rear entries of E are connected
}
return e;
}
//If the upper if does not go in, the next loop will be executed, and the pointer will move back one bit!
prev=e;
e=next;
}
//Until the end of while, if no element is found, return null
return null;
}
Capacity expansion
ok, next, let's talk about the capacity expansion. The capacity expansion in jdk8 is quite different from the previous version. Jdk8 solves the problem of linked list forming a ring, and there are red and black trees in jdk8 capacity expansion, so there must be great differences. We mainly talk about the following jdk7 capacity expansion (header insertion, that is, the original linked list will be inverted after capacity expansion).
/**
* Capacity expansion, incoming new capacity
*/
void resize(int newCapacity){
Entry[] newTable = new Entry[newCapacity];
//Replace all old elements in the new table start
Entry[] oldTable = table;
//Traverse all locations
for (int j = 0; j < oldTable.length; j++){
Entry e = oldTable[j];
if(null!=e){
oldTable[j]=null;//At the end of the cycle, all oldTable references will be empty and GC will recycle them
do{
Entry next = e.next;//First remember who is next in e's list
int i = findBucketIndex(e.hash,newTable.length);//New hash bucket location found
e.next=newTable[i];//Note that this is a loop, and there may be elements on the newTable[i]. Set the element on newTable[i] as the next element of e,
newTable[i]=e;//Therefore, the expansion in jdk7 is the insertion of the chain header.
e=next;//Next recycling
}while(null!=e);
}
}
table=newTable;
//Replace all old elements in the new table
threshold=(int)(newCapacity*DEFAULT_LOAD_FACTOR);
}
Define a new array, newTable, and expand the capacity. The parameters passed in are usually twice the length of the original array
At this time, we need to traverse the old array one by one, starting with table[j], calculate the hash bucket separately for the entries with hash collision on table[j], and put it back to the new position of the new array. (because those elements whose length was originally in a hash bucket are not necessarily in a hash bucket now)
Finally, reference table to newTable
The threshold is recalculated to facilitate the next expansion.
Summary:
If you have an estimate of the amount of data, it is recommended to specify the length when creating the Map to reduce the expansion of hashMap! Capacity expansion is a very performance consuming operation. It is best to manually specify it as the N-power of 2.
HashMap threads are unsafe. For example, the problem of linked list looping only occurs in the case of multithreading. But this is not a defect in jdk design. Therefore, if your collection needs to be accessed under multithreading, please prohibit the use of HashMap. It is recommended to use the HashMap under the Juc package. The detailed explanation of ConcurrentHashMap will be explained to you in the subsequent multi-threaded concurrency module. Personally, I think hashTable should be eliminated!
doubt
What is the modCount variable in hashMap for? A: all data results in java have this variable, which is mainly used for fail fast failure. That is, when the set is modified concurrently during traversal, this variable can be used to judge whether to modify it during traversal.
Why is the table array variable modified by transient in jdk source code? As we know, this modifier refers to ignoring this field when serializing. Why should HashMap make this setting? A: because HashMap relies heavily on hashCode, the hashcodes of different virtual machines are different! It means that the serialized collection on machine a may not work properly after deserialization on machine B. Because the hash algorithm cannot locate the position on the table!
For the previous question, the hashMap solution is to rewrite its own serial number. The writeObject method performs its own serial number. Only the key and value are written to a file and do not participate in the hash storage! Please study it in detail!
Complete code
package my.hashmap.mymap.Utils;
import lombok.Data;
@Data
public class HkHashMap <K,V>{
/**
* table Default initial length of
*/
static final int DEFAULT_INITIAL_CAPACITY = 16;
/**
* Load factor, which triggers capacity expansion when it reaches 16 * 0.75
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
private Entry<K,V>[] table;
int size;
// K key;
V value;
/**
* Threshold, when this value is reached, the capacity will be expanded. threshold=DEFAULT_INITIAL_CAPACITY*DEFAULT_LOAD_FACTOR
*/
int threshold;
/**
* Parameterless constructors, of course, specify the initial length and load factor better.
*/
public HkHashMap() {
threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR);
table = new Entry[DEFAULT_INITIAL_CAPACITY];
}
/**
* Get element
*/
public V get(K key){
int h = hash(key);
for(Entry<K,V> e = table[findBucketIndex(h,table.length)];e!=null;e=e.next){
if(e.hash==h&&(key==e.key||key.equals(e.key))){
return e.value;
}
}
return null;
}
/**
* Add the element. If the key already exists, replace it
*/
public V put(K key,V value){
if(null==key){
return putNullKey(value);
}
int h=hash(key);
int i = findBucketIndex(h,table.length);
//If the key already exists, replace it
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
K k;
if (e.hash == h && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
return oldValue;
}
}
addEntry(h, key, value, i);
return null;
}
public Object remove(K key){
return removeEntryForKey(key);
}
private Entry removeEntryForKey (K key){
int hash = hash(key.hashCode());
int i = findBucketIndex(hash,table.length);
//First define a prev to represent the previous element to be deleted
Entry prev = table[i];
Entry e=prev;
while(e!=null){
//Locate the next element of e. when we find the element we want to delete, cut off the linked list and connect prev and next. Refer to the deletion of linkedList
Entry next = e.next;
//Locate this element on the linked list, first judge whether the hash value is equal, and then judge whether the equals of the key is equal! Note that if = = returns true here, it indicates that it is a reference, so the judgment of equals can be omitted.
if(e.hash==hash&& (e.key==key||(key!=null&&key.equals(e.key))) ){
size--;//At this time, the existing element is located. Note that the hash value is determined to be equal outside the while. When hash values are equal, equals is not necessarily equal.
//Here, we have to judge whether the Entry located is table[i], because the deletion on table[i] is different from the deletion on the linked list
if(prev==e){
table[i]=next;//Although next may be empty
}else{
prev.next=next;//If it is not in the table position, it is the element behind the linked list. At this time, set the next prev as the next of E. at this time, e has been cut off and the front and rear entries of E are connected
}
return e;
}
//If the upper if does not go in, the next loop will be executed, and the pointer will move back one bit!
prev=e;
e=next;
}
//Until the end of while, if no element is found, return null
return null;
}
/**
* hashMap Allow the key to be empty, and handle this empty key separately
*/
private V putNullKey(V value){
//If there is already a Null Key, replace it
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
return oldValue;
}
}
addEntry(0, null, value, 0);
return null;
}
void addEntry(int hash, K key, V value, int bucketIndex){
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] =new Entry(hash,key,value,e);
size++;
if(size>threshold){
resize(table.length*2);
}
}
/**
* Capacity expansion, incoming new capacity
*/
void resize(int newCapacity){
Entry[] newTable = new Entry[newCapacity];
//Replace all old elements in the new table start
Entry[] oldTable = table;
//Traverse all locations
for (int j = 0; j < oldTable.length; j++){
Entry e = oldTable[j];
if(null!=e){
oldTable[j]=null;//At the end of the cycle, all oldTable references will be empty and GC will recycle them
do{
Entry next = e.next;//First remember who is next in e's list
int i = findBucketIndex(e.hash,newTable.length);//New hash bucket location found
e.next=newTable[i];//Note that this is a loop, and there may be elements on the newTable[i]. Set the element on newTable[i] as the next element of e,
newTable[i]=e;//Therefore, the expansion in jdk7 is the insertion of the chain header.
e=next;//Next recycling
}while(null!=e);
}
}
table=newTable;
//Replace all old elements in the new table
threshold=(int)(newCapacity*DEFAULT_LOAD_FACTOR);
}
/**
* HashCode Do a hash operation. So as to ensure hashing
*/
static final int hash(Object key) {
int h;
//Move the hashCode to the right by 16 bits and perform an XOR operation with the hashCode, that is, the upper 16 bits ^ 16 bits (refer to jdk8). If the key is null, fix it to the position of table[0]
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
/**
* For any key, you need to find the corresponding hash bucket position after the hash
*/
static int findBucketIndex(int h, int length) {
//The result of the algorithm for finding the remainder is the same. High bit operation efficiency (a little bit)
return h & (length-1);
}
//Storage unit of map
private static class Entry<K,V>{
int hash;
K key;
V value;
Entry next;
public Entry(int hash, K key, V value, Entry next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
}
}
test
public class MyMap {
public static void main(String[] args) {
HkHashMap<String,Person> myMap = new HkHashMap();
myMap.put("Zhang San", new Person("Zhang San",20) );
myMap.put("Li Si", new Person("Li Si",21) );
myMap.put("Wang Wu", new Person("Wang Wu",22) );
myMap.put("Zhao Liu", new Person("Zhao Liu",23) );
myMap.put("1", new Person("Zhang San",20) );
myMap.put("2", new Person("Li Si",21) );
myMap.put("3", new Person("Wang Wu",22) );
myMap.put("4", new Person("Zhao Liu",23) );
myMap.put("5", new Person("Zhang San",20) );
myMap.put("6", new Person("Li Si",21) );
myMap.put("7", new Person("Wang Wu",22) );
myMap.put("8", new Person("Zhao Liu",23) );
myMap.put("9", new Person("Zhang San",20) );
myMap.put("10", new Person("Li Si",21) );
myMap.put("11", new Person("Wang Wu",22) );
myMap.put("12", new Person("Zhao Liu",23) );
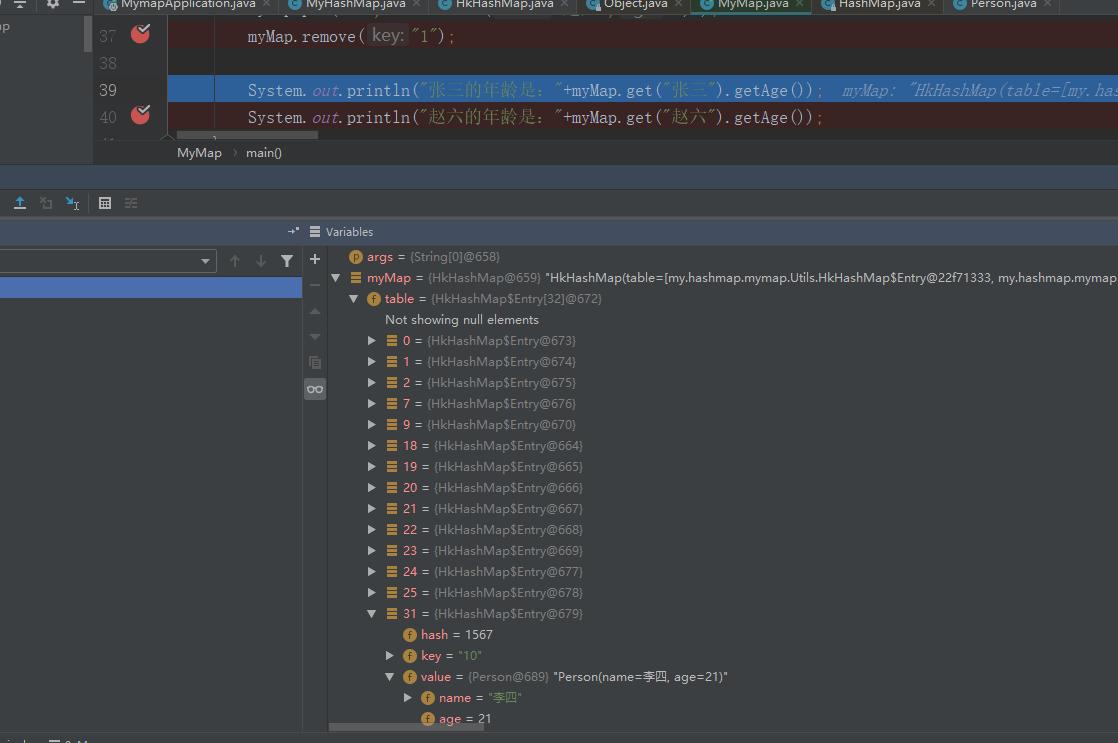
myMap.remove("1");
System.out.println("Zhang San's age is:"+myMap.get("Zhang San").getAge());
System.out.println("Zhao Liu's age is:"+myMap.get("Zhao Liu").getAge());
}
}
Output results:
Connected to the target VM, address: '127.0.0.1:14375', transport: 'socket' Zhang San's age is: 20 Zhao Liu's age is 23 Disconnected from the target VM, address: '127.0.0.1:14375', transport: 'socket'
As the put element increases, the threshold will also increase after resize.
Reference article:
https://www.cnblogs.com/hkblogs/p/9151160.html