
Interface Overview
By looking at the description of the Map interface, we find that the collections under the Map interface and the collections under the Collection interface store data in different forms, as shown in the following figure.
For the Collection in the Collection, the elements exist in isolation (understood as detail), and the elements stored in the Collection are stored in the form of elements one by one.
The collection elements in the Map exist in pairs (understood as husband and wife). Each element consists of a key and a value. You can find the corresponding value through the key.
Collections in the Collection are called single column collections, and collections in the Map are called double column collections.
It should be noted that the set in the Map cannot contain duplicate keys, and the values can be repeated; Each key can only correspond to one value.
The commonly used sets in Map are HashMap set and LinkedHashMap set.
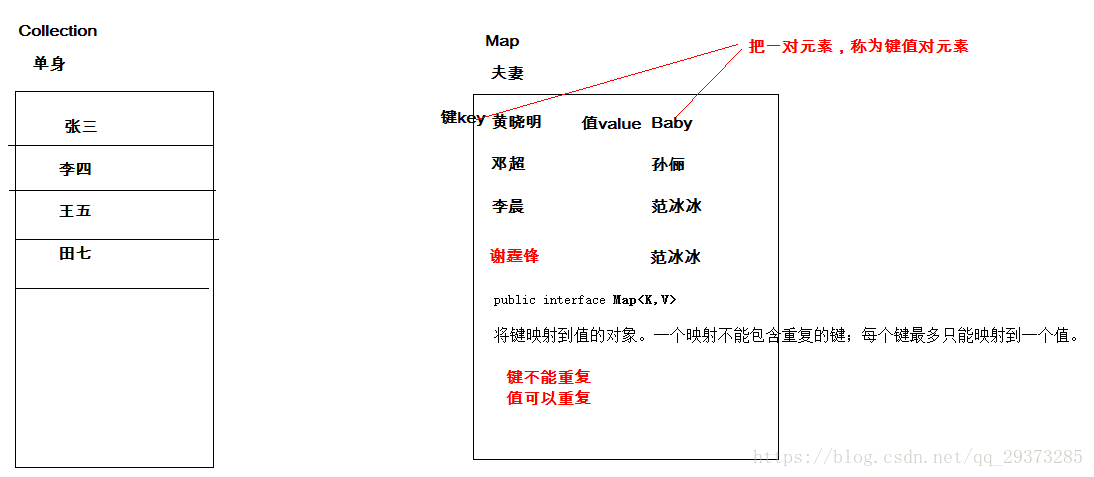
Overview of common collections in Map interface
By viewing the Map interface description, we can see that there are multiple subclasses of Map. Here we mainly explain the commonly used HashMap sets and LinkedHashMap sets.
HashMap < K, V >: the hash table structure used to store data, and the access order of elements cannot be guaranteed to be consistent. To ensure that the key is unique and not repeated, you need to rewrite the hashCode() method and equals() method of the key.
LinkedHashMap < K, V >: there is a subclass LinkedHashMap under HashMap, which uses hash table structure + linked list structure to store data. Through the linked list structure, the access order of elements can be ensured to be consistent; The hash table structure can ensure the uniqueness and non repetition of the key. The hashCode() method and equals() method that need to rewrite the key are required.
Note: the set in the Map interface has two generic variables < K, V >. When using, the two generic variables should be given data types. The data types of two generic variables < K, V > can be the same or different.
map introduction
Before explaining map sorting, let's learn a little about map. Map is a collection interface of key value pairs. Its implementation classes mainly include HashMap,TreeMap,Hashtable and LinkedHashMap. The differences between the four are as follows (brief introduction):
- HashMap
Our most commonly used Map stores data according to the HashCode Value of the key. Its Value can be obtained directly according to the key. At the same time, it has fast access speed. HashMap can only allow the key Value of one record to be Null at most (multiple records will be overwritten); Multiple records are allowed to have Null values. Asynchronous.
- TreeMap
The saved records can be sorted according to the key. By default, they are sorted in ascending order. You can also specify the sorting comparator. When traversing the TreeMap with the Iterator, the records obtained are sorted. TreeMap does not allow null value for key. Asynchronous.
- Hashtable
Similar to HashMap, the difference is: the values of key and value are not allowed to be null; It supports thread synchronization, that is, only one thread can write Hashtable at any time, which also leads to the slow writing of Hashtale.
- LinkedHashMap
The insertion order of records is saved. When traversing LinkedHashMap with Iterator, the records obtained first must be inserted first. When traversing, it will be slower than HashMap. Both key and value can be null and asynchronous
Sorting of map s
- Sorting of TreeMap
TreeMap is in ascending order by default. If we need to change the sorting method, we need to use the Comparator.
Comparator is a comparator interface that can sort set objects or arrays. The public compare(T o1,To2) method that implements this interface can realize sorting. This method mainly returns negative integers, 0 or positive integers respectively according to the first parameter o1, which is less than, equal to or greater than o2. As follows:
public class TreeMapTest {
public static void main(String[] args) {
Map<String, String> map = new TreeMap<String, String>(
new Comparator<String>() {
public int compare(String obj1, String obj2) {
// Descending sort
return obj2.compareTo(obj1);
}
});
map.put("c", "ccccc");
map.put("a", "aaaaa");
map.put("b", "bbbbb");
map.put("d", "ddddd");
Set<String> keySet = map.keySet();
Iterator<String> iter = keySet.iterator();
while (iter.hasNext()) {
String key = iter.next();
System.out.println(key + ":" + map.get(key));
}
}
}
The operation results are as follows:
d:ddddd c:ccccc b:bbbbb a:aaaaa
The above example sorts according to the key value of TreeMap, but sometimes we need to sort according to the value of TreeMap. To sort values, we need to use the sort (list < T > list, comparator <? Super T > C) method of Collections, which sorts the specified list according to the order generated by the specified comparator. However, there is a prerequisite that all elements must be able to compare according to the provided comparator. As follows:
public class TreeMapTest {
public static void main(String[] args) {
Map<String, String> map = new TreeMap<String, String>();
map.put("d", "ddddd");
map.put("b", "bbbbb");
map.put("a", "aaaaa");
map.put("c", "ccccc");
//Here, map.entrySet() is converted to a list
List<Map.Entry<String,String>> list = new ArrayList<Map.Entry<String,String>>(map.entrySet());
//Then the sorting is realized by comparator
Collections.sort(list,new Comparator<Map.Entry<String,String>>() {
//Ascending sort
public int compare(Entry<String, String> o1,
Entry<String, String> o2) {
return o1.getValue().compareTo(o2.getValue());
}
});
for(Map.Entry<String,String> mapping:list){
System.out.println(mapping.getKey()+":"+mapping.getValue());
}
}
}
Operation results:
a:aaaaa b:bbbbb c:ccccc d:ddddd
- Sorting of HashMap
We all know that the values of HashMap are not in order. It is implemented according to the HashCode of key. How do we implement sorting for this unordered HashMap? Referring to the value sorting of TreeMap, we can also sort HashMap.
public class HashMapTest {
public static void main(String[] args) {
Map<String, String> map = new HashMap<String, String>();
map.put("c", "ccccc");
map.put("a", "aaaaa");
map.put("b", "bbbbb");
map.put("d", "ddddd");
List<Map.Entry<String,String>> list = new ArrayList<Map.Entry<String,String>>(map.entrySet());
Collections.sort(list,new Comparator<Map.Entry<String,String>>() {
//Ascending sort
public int compare(Entry<String, String> o1,
Entry<String, String> o2) {
return o1.getValue().compareTo(o2.getValue());
}
});
for(Map.Entry<String,String> mapping:list){
System.out.println(mapping.getKey()+":"+mapping.getValue());
}
}
}
Operation results:
a:aaaaa b:bbbbb c:ccccc d:ddddd
List is a commonly used collection class in Java. There are many implementation classes for the list interface. This article will briefly introduce the relationship and differences between several key implementations ArrayList, LinkedList and Vector.
List is an interface that inherits from the interface of Collection. It represents an orderly queue. When we discuss list, we usually compare it with Set.
List The elements in the can be repeated and ordered (the order here refers to the order in which they are stored. For example, 1,2,3 Deposit List,So, from List The traversal order is also 1,2,3). Set The elements in cannot be repeated and are unordered (from set The data traversed in has nothing to do with the putting order).
Differences between ArrayList, LinkedList and Vector:
ArrayList, LinkedList and Vector all implement the List interface. They are three implementations of List, so they are very similar in usage. The main difference between them is reflected in the performance of different operations. It will be analyzed in detail later.
ArrayList
The bottom layer of ArrayList is implemented by array. It can be considered that ArrayList is an array with variable size. As more and more elements are added to ArrayList, its size increases dynamically.
LinkedList
The underlying layer of LinkedList is realized through two-way linked list. Therefore, the main difference between LinkedList and ArrayList is the difference between array and linked list.
The query and assignment in the array are faster because the specified location can be accessed directly through the array subscript.
Deleting and adding in the linked list is faster, because you can modify the pointer of the linked list directly( Java There is no pointer in, which can be simply understood as a pointer. In fact, it is through Node The variable in the node specifies) to add or delete elements.
Therefore, LinkedList is faster than ArrayList in adding and deleting, but slower in querying and modifying values. At the same time, LinkedList also implements the Queue interface, so it also provides methods such as offer(), peek(), poll().
Vector
Like ArrayList, Vector is implemented through arrays, but Vector is thread safe. Compared with ArrayList, many of these methods ensure thread safety through synchronized processing.
If your program does not involve thread safety issues, it is better to use ArrayList (because Vector uses synchronized, which will inevitably affect efficiency).
Another difference between the two is that the expansion strategy is different. When the List is created for the first time, it will have an initial size. With the continuous addition of elements to the List, when the List thinks that the capacity is not enough, it will be expanded. Vector automatically doubles by default ArrayList increases by 50% of the original array length.
Performance comparison between ArrayList and LinkedList
Use the following code to compare the time taken for several main operations in ArrayList and LinkedList:
ArrayList<Integer> arrayList = new ArrayList<Integer>(); LinkedList<Integer> linkedList = new LinkedList<Integer>(); // ArrayList add long startTime = System.nanoTime(); for (int i = 0; i < 100000; i++) { arrayList.add(i); } long endTime = System.nanoTime(); long duration = endTime - startTime; System.out.println("ArrayList add: " + duration); // LinkedList add startTime = System.nanoTime(); for (int i = 0; i < 100000; i++) { linkedList.add(i); } endTime = System.nanoTime(); duration = endTime - startTime; System.out.println("LinkedList add: " + duration); // ArrayList get startTime = System.nanoTime(); for (int i = 0; i < 10000; i++) { arrayList.get(i); } endTime = System.nanoTime(); duration = endTime - startTime; System.out.println("ArrayList get: " + duration); // LinkedList get startTime = System.nanoTime(); for (int i = 0; i < 10000; i++) { linkedList.get(i); } endTime = System.nanoTime(); duration = endTime - startTime; System.out.println("LinkedList get: " + duration); // ArrayList remove startTime = System.nanoTime(); for (int i = 9999; i >=0; i--) { arrayList.remove(i); } endTime = System.nanoTime(); duration = endTime - startTime; System.out.println("ArrayList remove: " + duration); // LinkedList remove startTime = System.nanoTime(); for (int i = 9999; i >=0; i--) { linkedList.remove(i); } endTime = System.nanoTime(); duration = endTime - startTime; System.out.println("LinkedList remove: " + duration);
result:
ArrayList add: 13265642 LinkedList add: 9550057 ArrayList get: 1543352 LinkedList get: 85085551 ArrayList remove: 199961301 LinkedList remove: 85768810
The difference in their performance is obvious. LinkedList is faster in add and delete operations, but slower in query.
How to choose
If multithreading is involved, select Vector (of course, you can also use ArrayList and synchronize yourself).
If multithreading is not involved, select from LinkedList and ArrayList. LinkedList is more suitable for inserting or deleting from the middle (the feature of linked list). ArrayList is more suitable for retrieving and inserting or deleting at the end (the characteristics of an array).
Source from: https://mp.weixin.qq.com/s/eiQj3GLN84knfpyNt8cFVA
https://blog.csdn.net/qq_29373285/article/details/81487594
https://www.cnblogs.com/htyj/p/7723887.html