Java collections in simple terms
1. Overview of collection framework
- Sets and arrays are structures that store multiple data, referred to as Java containers for short.
- Note: storage at this time mainly refers to memory level storage, and does not involve persistent storage (. txt,.jpg,.avi, in the database)
- Array features in storing multiple data:
-
Once initialized, its length is determined.
-
Once an array is defined, the type of its elements is determined. We can only operate on the specified type of data.
-
For example: String[] arr; int[] arr1; Object[] arr2;
- Disadvantages of arrays in storing multiple data:
- Once initialized, its length cannot be modified.
- The methods provided in the array are very limited. It is very inconvenient and inefficient to add, delete and insert data.
- The requirement to obtain the number of actual elements in the array. There are no ready-made properties or methods available in the array
- The characteristics of array storage data: orderly and repeatable. For disordered and unrepeatable needs, they cannot be met.
2. Collection framework inheritance relationship
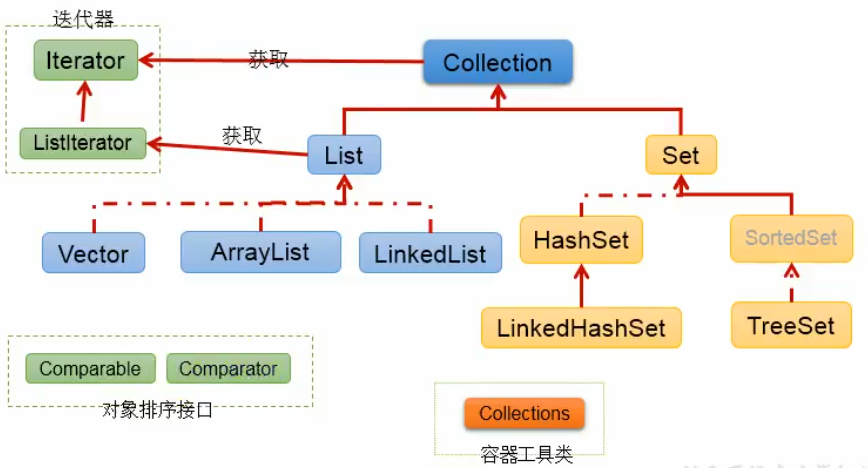
Overview: Java collections can be divided into Collection and Map systems.
- Collection interface: single column data, which defines the collection of methods to access a group of objects
- List: an ordered and repeatable collection of elements
- Set: an unordered and non repeatable set of elements
- Map day connection: double column data, which saves the set with mapping relationship "key value pair"
Collection interface inheritance tree
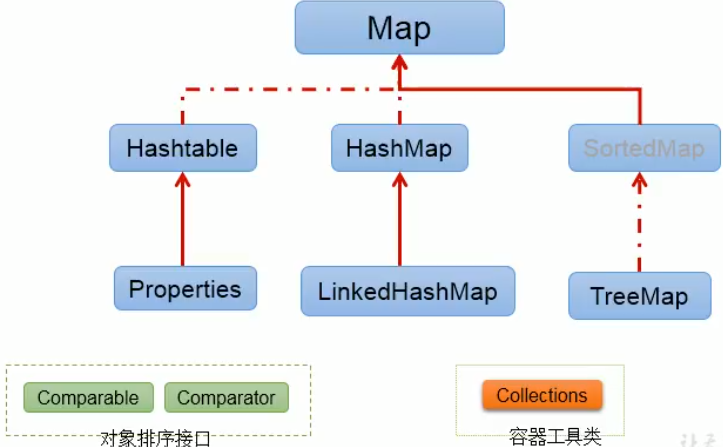
Map interface inheritance tree
Interface inheritance relationship display
|----Collection Interface: a single column collection used to store objects one by one
|----List Interface: store ordered and repeatable data. -->"Dynamic array
|----ArrayList,LinkedList,Vector
|----Set Interface: stores unordered and unrepeatable data -->"Collection" in high school
|----HashSet,LinkedHashSet,TreeSet
|----Map Interface: a two column set used to store a pair of data(key - value)A pair of data -->High school function: y = f(x)
|----HashMap,LinkedHashMap,TreeMap,Hashtable,Properties
3. Common methods of collection interface
import org.junit.Test;
import java.util.*;
public class CollectionTest1 {
@Test
public void test1() {
Collection coll = new ArrayList();
//add(Object e): add element e to the collection coll
coll.add("AA");
coll.add("BB");
coll.add(123);//Automatic packing
coll.add(new Date());
//size(): gets the number of added elements
System.out.println(coll.size());//4
//addAll(Collection coll1): adds the elements in the coll1 collection to the current collection
Collection coll1 = new ArrayList();
coll1.add(456);
coll1.add("CC");
coll.addAll(coll1);
System.out.println(coll.size());//6
System.out.println(coll);//[AA, BB, 123, Wed May 05 18:07:59 CST 2021, 456, CC]
//clear(): clear collection elements
//coll.clear();
//isEmpty(): judge whether the current collection is empty
System.out.println(coll.isEmpty());
}
@Test
public void test2() {
Collection coll = new ArrayList();
coll.add(123);
coll.add(456);
coll.add(new String("Tom"));
// Person p = new Person("Jerry",20);
// coll.add(p);
coll.add(new Person("Jerry", 20));
coll.add(false);
//1.contains(Object obj): judge whether the current set contains obj
//When judging, we will call equals() of the class where the obj object is located.
boolean contains = coll.contains(123);
System.out.println(contains);
System.out.println(coll.contains(new String("Tom")));
// System.out.println(coll.contains(p));//true
System.out.println(coll.contains(new Person("Jerry", 20)));//false -->true
//2.containsAll(Collection coll1): judge whether all elements in formal parameter coll1 exist in the current collection.
Collection coll1 = Arrays.asList(123, 4567);// ***
System.out.println(coll.containsAll(coll1));
}
@Test
public void test3() {
//3.remove(Object obj): removes obj elements from the current collection.
Collection coll = new ArrayList();
coll.add(123);
coll.add(456);
coll.add(new Person("Jerry", 20));
coll.add(new String("Tom"));
coll.add(false);
coll.remove(1234);
System.out.println(coll);
coll.remove(new Person("Jerry", 20));
System.out.println(coll);
//4. removeAll(Collection coll1): difference set: removes all elements in coll1 from the current set.
Collection coll1 = Arrays.asList(123, 456);
coll.removeAll(coll1);
System.out.println(coll);
}
@Test
public void test4() {
Collection coll = new ArrayList();
coll.add(123);
coll.add(456);
coll.add(new Person("Jerry", 20));
coll.add(new String("Tom"));
coll.add(false);
//5. Retain all (collection coll1): intersection: get the intersection of the current set and coll1 set and return it to the current set
//Collection coll1 = Arrays.asList(123,456,789);
//coll.retainAll(coll1);
//System.out.println(coll);
//6.equals(Object obj): to return true, the elements of the current set and the parameter set must be the same.
Collection coll1 = new ArrayList();
coll1.add(456);
coll1.add(123);
coll1.add(new Person("Jerry", 20));
coll1.add(new String("Tom"));
coll1.add(false);
System.out.println(coll.equals(coll1));
}
@Test
public void test5() {
Collection coll = new ArrayList();
coll.add(123);
coll.add(456);
coll.add(new Person("Jerry", 20));
coll.add(new String("Tom"));
coll.add(false);
//7.hashCode(): returns the hash value of the current object
System.out.println(coll.hashCode());
//8. Set -- > array: toArray()
Object[] arr = coll.toArray();
for (Object o : arr) {
System.out.println(o);
}
//Extension: array -- > collection: call the static method asList() of the Arrays class
List<String> list = Arrays.asList("AA", "BB", "CC");
System.out.println(list);
List arr1 = Arrays.asList(new int[]{123, 456});
System.out.println(arr1.size());//1
List arr2 = Arrays.asList(new Integer[]{123, 456});
System.out.println(arr2.size());//2
//9.iterator(): returns an instance of the iterator interface for traversing collection elements. Put it in iteratortest Testing in Java
}
}
4. Use Iterator to traverse the Collection
Overview: GOF defines iterator pattern as providing a way to access each element in a container object
Element without exposing the internal details of the object. The iterator pattern is born for containers. Similar to "conductor on bus".
example
@Test
public void test1() {
Collection coll = new ArrayList();
coll.add(123);
coll.add(456);
coll.add(new Person("Jerry", 20));
coll.add(new String("Tom"));
coll.add(false);
// 1. Call the iterator() method through the collection to return an iterator object
Iterator iterator = coll.iterator();
// 2. By calling hasNext(): judge whether there is another element
while (iterator.hasNext()) {
// 3. Call next() to: ① move the pointer down ② return the elements at the collection position after moving down
System.out.println(iterator.next());
}
}
5. Analysis of Iterator principle
summary
Iterator is only used to traverse collections
Every time a collection object calls the iterator() method, it gets a new iterator object
Principle analysis

-
When the above collection calls the iterator() method to return an iterator object, it can be seen that the iterator object pointer is null at this time.
-
The pseudo code on the left comes to the while structure and calls hasNext() to determine whether the first element of the set exists. If so, it enters the inside of while. On the contrary, the while structure ends the loop.
Note: when the hasNext() method is called, the iterator object pointer generated in the first step does not move.
-
Assuming that the first element exists at this time, enter the while structure, call the next() method and return the element for printing.
Note: when the next() method is called, the iterator object pointer moves down to point to the position of the current element.
-
Repeat steps 2 and 3 until all the set elements are printed.
Error writing method of iterator based on principle example
//Error mode 1:
Iterator iterator = coll.iterator();
while((iterator.next()) != null){
System.out.println(iterator.next());
}
//Error mode 2:
//Every time a collection object calls the iterator() method, it gets a new iterator object, and the default cursor is before the first element of the collection.
while (coll.iterator().hasNext()) {
System.out.println(coll.iterator().next());
}
6. remove() method in Iterator iterator
In addition to the hasNext() and next() methods, the Iterator also has the remove() method, which is different from the remove() defined in the collection.
example
@Test
public void test3() {
Collection coll = new ArrayList();
coll.add(123);
coll.add(456);
coll.add(new Person("Jerry", 20));
coll.add(new String("Tom"));
coll.add(false);
//Delete "Tom" in the collection
Iterator iterator = coll.iterator();
while (iterator.hasNext()) {
// iterator.remove();
Object obj = iterator.next();
if ("Tom".equals(obj)) {
iterator.remove();
}
}
}
7.foreach loop traversal set
jdk 5.0 adds a foreach loop to traverse collections and arrays
import org.junit.Test;
import java.util.ArrayList;
import java.util.Collection;
public class ForeachTest {
@Test
public void test1() {
Collection coll = new ArrayList();
coll.add(123);
coll.add(456);
coll.add(new Person("Jerry", 20));
coll.add(new String("Tom"));
coll.add(false);
//For (type of collection element local variable: collection object)
//The iterator is still called internally.
for (Object obj : coll) {
System.out.println(obj);
}
}
@Test
public void test2() {
int[] arr = new int[]{1, 2, 3, 4, 5, 6};
//For (type of array element, local variable: array object)
for (int i : arr) {
System.out.println(i);
}
}
//Exercises
@Test
public void test3() {
String[] arr = new String[]{"MM", "MM", "MM"};
// //Method 1: normal for assignment, which will modify the value of arr
// for(int i = 0;i < arr.length;i++){
// arr[i] = "GG";
// }
//Method 2: enhance the for loop, which will not
for (String s : arr) {
s = "GG";
}
for (int i = 0; i < arr.length; i++) {
System.out.println(arr[i]);
}
}
}
8. Comparison of common implementation classes of list interface
List Interface framework
|----Collection Interface: a single column collection used to store objects one by one
|----List Interface: store ordered and repeatable data. -->"Dynamic array,Replace the original array
|----ArrayList: As List Main implementation classes of the interface; Unsafe thread and high efficiency; Bottom use Object[] elementData storage
|----LinkedList: This kind of efficiency ratio is used for frequent insertion and deletion operations ArrayList High; The bottom layer uses two-way linked list storage
|----Vector: As List Interface implementation class; Thread safety and low efficiency; Bottom use Object[] elementData storage
9.ArrayList source code analysis
jdk7 case
// jdk 7 ArrayList list = new ArrayList();//The bottom layer creates an Object [] array elementData with a length of 10 list.add(123);//elementData[0] = new Integer(123); ... list.add(11);//If the capacity of the underlying elementData array is insufficient due to this addition, the capacity will be expanded. By default, the capacity expansion is 1% of the original capacity.5 At the same time, the data in the original array needs to be copied to the new array. Conclusion: it is recommended to use the constructor with parameters in the development (initialize the capacity and avoid unnecessary capacity expansion): ArrayList list = new ArrayList(int capacity)
jdk8 case
// Changes in ArrayList in jdk 8:
ArrayList list = new ArrayList();//The underlying Object[] elementData is initialized to {} No array of length 10 was created
list.add(123);//The first time add() is called, the underlying layer creates an array of length 10 and adds data 123 to elementData[0]
...
Subsequent addition and expansion operations and jdk 7 No different.
Summary
The creation of ArrayList objects in jdk7 is similar to the starving type of singleton, while the creation of ArrayList objects in jdk8 is similar to the lazy type of singleton, which delays the creation of arrays and saves memory.
10.LinkedList source code analysis
LinkedList list = new LinkedList(); Internal declaration Node Type first and last Property, the default value is null
list.add(123);// Encapsulate 123 into Node and create a Node object.
Among them, Node Defined as: reflects LinkedList Two way linked list
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
11.Vector source code analysis
Vector Source code analysis: jdk7 and jdk8 Passed in Vector()When the constructor creates an object, the underlying layer creates an array with a length of 10. In terms of capacity expansion, the default capacity expansion is twice the length of the original array.
12. Common methods in list interface
Code summary
public class ListTest {
/**
void add(int index, Object ele):Insert the ele element at the index position
boolean addAll(int index, Collection eles):Add all elements in eles from the index position
Object get(int index):Gets the element at the specified index location
int indexOf(Object obj):Returns the position where obj first appears in the collection
int lastIndexOf(Object obj):Returns the last occurrence of obj in the current collection
Object remove(int index):Removes the element at the specified index position and returns this element
Object set(int index, Object ele):Set the element at the specified index location to ele
List subList(int fromIndex, int toIndex):Returns a subset from fromIndex to toIndex
Summary: common methods
Add: add(Object obj)
Delete: remove(int index) / remove(Object obj)
**********************************************
Note: the remove() method defined here in the List interface is overloaded. Because the parameters are different, it deletes elements according to the index; The remove() of the Collection interface is to delete Object of
*********************************************
Change: set(int index, Object ele)
Query: get(int index)
Insert: add(int index, Object ele)
Length: size()
Traversal: ① Iterator iterator mode
② Enhanced for loop
③ Ordinary cycle
*/
@Test
public void test1() {
ArrayList list = new ArrayList();
list.add(123);
list.add(456);
list.add("AA");
list.add(new Person("Tom", 12));
list.add(456);
System.out.println(list);
//void add(int index, Object ele): inserts an ele element at the index position
list.add(1, "BB");
System.out.println(list);
//boolean addAll(int index, Collection eles): add all elements in eles from the index position
List list1 = Arrays.asList(1, 2, 3);
list.addAll(list1);
//list.add(list1); Be careful not to report errors, but there are only 7 in total
System.out.println(list.size());//9
//Object get(int index): gets the element at the specified index position
System.out.println(list.get(0));
}
}
13.List interface traversal mode summary
Code summary
@Test
public void test3() {
ArrayList list = new ArrayList();
list.add(123);
list.add(456);
list.add("AA");
//Mode 1: Iterator iterator mode
Iterator iterator = list.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
System.out.println("***************");
//Mode 2: enhanced for loop
for (Object obj : list) {
System.out.println(obj);
}
System.out.println("***************");
//Mode 3: normal for loop
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
}
remove() method of classic interview questions
import org.junit.Test;
import java.util.ArrayList;
import java.util.List;
public class ListExer {
/*
Distinguish between remove(int index) and remove(Object obj) in the List
*/
@Test
public void testListRemove() {
List list = new ArrayList();
list.add(1);
list.add(2);
list.add(3);
updateList(list);
System.out.println(list);//
}
private void updateList(List list) {
// Since the objects to be deleted must be boxed first, the system default parameter is index
list.remove(2);
// If you want to call the remove() method in the Collection, you only need to box it manually
list.remove(new Integer(2));
}
}
14.Set interface implementation class comparison
Set Interface framework:
|----Collection Interface: a single column collection used to store objects one by one
|----Set Interface: stores unordered and unrepeatable data -->"Collection" in high school
|----HashSet: As Set Main implementation classes of the interface; Thread unsafe; Can store null value
|----LinkedHashSet: As HashSet Subclasses of; When traversing its internal data, it can be traversed in the order of addition
For frequent traversal operations, LinkedHashSet Higher efficiency HashSet.
|----TreeSet: You can sort according to the specified attributes of the added object.
15. Disorder and non repeatability of set
Take HashSet as an example:
- Disorder: not equal to randomness. The stored data is not added in the order of array index in the underlying array, but determined according to the hash value of the data.
- Non repeatability: ensure that the added element cannot return true when judged according to equals(). That is, only one element can be added to the same element.
16. Adding elements to HashSet
The process of adding elements: HashSet For example:
We to HashSet Add element to a,Call the element first a Class hashCode()Method, calculation element a Hash value of,
This hash value is then calculated by some algorithm HashSet The storage location (i.e. index location) in the underlying array is determined
|----Whether the array already has elements at this position:
|----If there are no other elements at this location, the element a Added successfully. --->Case 1
|----If there are other elements at this location b(Or multiple elements in the form of a linked list), the elements are compared a And elements b of hash Value:
|----If hash If the values are different, the element a Added successfully.--->Case 2-----------------------------
|----If hash The value is the same, and then the element needs to be called a Class equals()method:
|----equals()return true,element a Add failed
|----equals()return false,Then element a Added successfully.--->Case 3------------------------
For case 2 and case 3 of successful addition: element a The data at the specified index location already exists is stored in a linked list.
jdk 7 :Element to insert a Put it in the array and point to the original element.
jdk 8 :The original element is in the array and points to the element to be inserted a
Conclusion: seven up and eight down
HashSet Bottom layer: array+Structure of linked list.
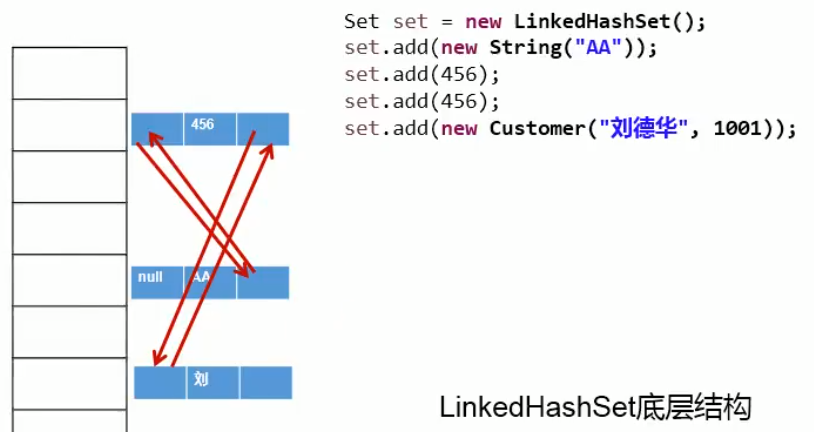
17.LinkedHashSet usage
/**
LinkedHashSet Use of
LinkedHashSet As a subclass of HashSet, while adding data, each data also maintains two references to record the previous data and the latter data.
Advantages: LinkedHashSet is more efficient than HashSet for frequent traversal operations
*/
@Test
public void test2(){
Set set = new LinkedHashSet();
set.add(456);
set.add(123);
set.add(123);
set.add("AA");
set.add("CC");
set.add(new User("Tom",12));
set.add(new User("Tom",12));
set.add(129);
Iterator iterator = set.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
}
Here is a brief display of its underlying data structure form: (focus on the two-way linked list)
18. Two sorting methods of TreeSet
When comparing whether two data elements are the same in the TreeSet class, compareTo() is used instead of equals().
1, Natural sorting
TreeSet class
import org.junit.Test;
import java.util.Comparator;
import java.util.Iterator;
import java.util.TreeSet;
public class TreeSetTest {
/**
* TreeSet Its main function is to sort:
* 1. The data added to TreeSet must be objects of the same class. (compare the same attributes, otherwise you can't sort)
* 2. There are two sorting methods: natural sorting (implementing Comparable interface) and custom sorting (Comparator)
* In natural sorting, the standard for comparing whether two objects are the same is: compareTo() returns 0. No longer equals().
* In custom sorting, the standard for comparing whether two objects are the same is: compare() returns 0. No longer equals().
*/
@Test
public void test1() {
TreeSet set = new TreeSet();
//Failed: cannot add objects of different classes
// set.add(123);
// set.add(456);
// set.add("AA");
// set.add(new User("Tom",12));
//Example 1:
// set.add(34);
// set.add(-34);
// set.add(43);
// set.add(11);
// set.add(8);
//Example 2:
set.add(new User("Tom", 12));
set.add(new User("Jerry", 32));
set.add(new User("Jim", 2));
set.add(new User("Mike", 65));
set.add(new User("Jack", 33));
set.add(new User("Jack", 56));
Iterator iterator = set.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
}
}
Overridden compareTo() method in User class
// In descending order of name and age
@Override
public int compareTo(Object o) {
if (o instanceof User) {
User user = (User) o;
// First level sorting
// return -this.name.compareTo(user.name);
// Secondary sort
int compare = -this.name.compareTo(user.name);
if (compare != 0) {
return compare;
} else {
return Integer.compare(this.age, user.age);
}
} else {
throw new RuntimeException("The types entered do not match");
}
}
2, Custom sorting
import org.junit.Test;
import java.util.Comparator;
import java.util.Iterator;
import java.util.TreeSet;
public class TreeSetTest {
/**
* TreeSet Its main function is to sort:
* 1. The data added to TreeSet must be objects of the same class. (compare the same attributes, otherwise you can't sort)
* 2. There are two sorting methods: natural sorting (implementing Comparable interface) and custom sorting (Comparator)
* In natural sorting, the standard for comparing whether two objects are the same is: compareTo() returns 0. No longer equals().
* In custom sorting, the standard for comparing whether two objects are the same is: compare() returns 0. No longer equals().
*/
@Test
public void test2() {
Comparator com = new Comparator() {
//Arranged from small to large according to age
@Override
public int compare(Object o1, Object o2) {
if (o1 instanceof User && o2 instanceof User) {
User u1 = (User) o1;
User u2 = (User) o2;
return Integer.compare(u1.getAge(), u2.getAge());
} else {
throw new RuntimeException("The data types entered do not match");
}
}
};
//Note that the constructor with parameters receives a Comparator
TreeSet set = new TreeSet(com);
set.add(new User("Tom", 12));
set.add(new User("Jerry", 32));
set.add(new User("Jim", 2));
set.add(new User("Mike", 65));
set.add(new User("Mary", 33));
set.add(new User("Jack", 33));
set.add(new User("Jack", 56));
Iterator iterator = set.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
}
}
19. Use of Set interface for classic interview questions
example
import org.junit.Test;
import java.util.ArrayList;
import java.util.Collection;
import java.util.HashSet;
import java.util.List;
public class CollectionTest {
@Test
public void test1() {
Collection coll = new ArrayList();
coll.add(123);
coll.add(456);
coll.add(343);
coll.add(343);
coll.forEach(System.out::println);
}
@Test
public void test2() {
List list = new ArrayList();
list.add(new Integer(1));//If it is a custom class, remember to override hashcode()
list.add(new Integer(2));
list.add(new Integer(2));
list.add(new Integer(4));
list.add(new Integer(4));
List list2 = duplicateList(list);
for (Object integer : list2) {
System.out.println(integer);
}
}
//Exercise: remove duplicate numeric values from the List and make it as simple as possible
public static List duplicateList(List list) {
HashSet set = new HashSet();
set.addAll(list);
return new ArrayList(set);
}
@Test
public void test3() {
HashSet set = new HashSet();
Person p1 = new Person(1001, "AA");
Person p2 = new Person(1002, "BB");
set.add(p1);
set.add(p2);
System.out.println(set);//2
// Here, change the name attribute of p1 to "CC"
p1.name = "CC";
// Before remove, call hashCode to get the hash value. At this time, the hash value is calculated according to 1001 and CC, so the obtained index position is different from p1, so there is no need to delete effect
set.remove(p1);
System.out.println(set);//2
// Before adding the object here, the hash value of the comparison is the same as the above result, so the corresponding position of the index is empty and can be inserted
set.add(new Person(1001, "CC"));
System.out.println(set);//3
// At this time, the compared index value is the same as p1 position, but when further compared through the equals() method, the name attribute of the two objects is different, so the new object is inserted into the external linked list of p1 Come on.
set.add(new Person(1001, "AA"));
System.out.println(set);//4
}
}
Person class
public class Person {
int id;
String name;
public Person() {
}
public Person(int id, String name) {
this.id = id;
this.name = name;
}
@Override
public String toString() {
return "Person{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
if (id != person.id) return false;
return name != null ? name.equals(person.name) : person.name == null;
}
@Override
public int hashCode() {
int result = id;
result = 31 * result + (name != null ? name.hashCode() : 0);
return result;
}
}
20. Comparison of map interface and its multiple implementation classes
Map Structure of implementation class:
|----Map:Dual column data, storage key-value Right data ---Functions similar to high school: y = f(x)
|----HashMap:As Map Main implementation classes of; Unsafe thread and high efficiency; storage null of key and value
|----LinkedHashMap:Guaranteed in traversal map Elements can be traversed in the order they are added.
Reason: in the original HashMap Based on the underlying structure, a pair of pointers are added to point to the previous and subsequent elements.
For frequent traversal operations, this kind of execution efficiency is higher than HashMap.
|----TreeMap:Ensure that the added key-value Sort to achieve sorting traversal. Consider at this time key Natural sorting or custom sorting
Red and black trees are used at the bottom
|----Hashtable:As an ancient implementation class; Thread safety and low efficiency; Cannot store null of key and value
|----properties:Commonly used to process configuration files. key and value All String type
HashMap Bottom layer of: array+Linked list( jdk7 (and before)
array+Linked list+Red black tree( jdk 8)
Note: t in Hashtable is lowercase, which does not meet the hump naming method.
21. Key value pair characteristics stored in map
Features are shown in the figure:
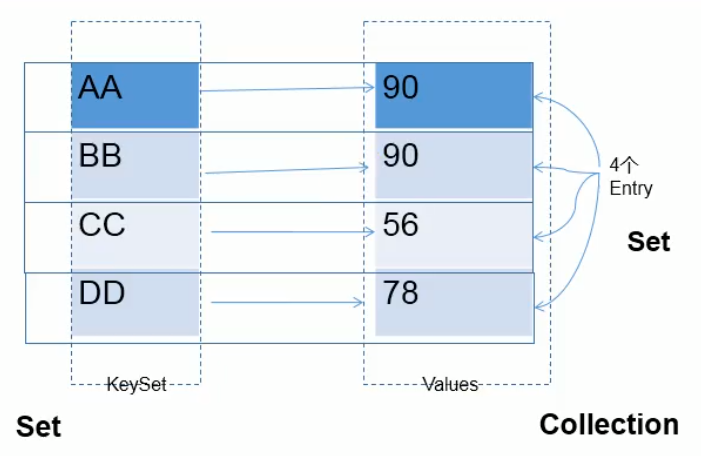
Map structure obtained from pictures:
- Keys in Map: unordered and non repeatable. Use Set to store all keys - > the class where the key is located should override equals() and hashCode() (take HashMap as an example)
- Value in Map: unordered and repeatable. Use Collection to store all values - > the class where value is located should override equals()
- A key value pair: key value constitutes an Entry object.
- Entries in Map: unordered and non repeatable. Set is used to store all entries
22. Implementation principle and source code analysis of HashMap at the bottom of JDK7
Important constants in HashMap source code
| DEFAULT_INITIAL_CAPACITY | Default capacity of HashMap, 16 |
|---|---|
| MAXIMUM_ CAPACITY | Maximum supported capacity of HashMap, 2 ^ 30 |
| DEFAULT_ LOAD_ FACTOR | Default load factor for HashMap |
| TREEIFY_ THRESHOLD | If the length of the linked list in the Bucket is greater than the default value, it will be converted into a red black tree |
| UNTREEIFY_ _THRESHOLD | The Node stored in the red black tree in the Bucket is smaller than the default value and is converted into a linked list |
| MIN_ TREEIFY_ _CAPACITY | The minimum hash table capacity when the nodes in the bucket are trealized. (when the number of nodes in the bucket is so large that it needs to be changed into a red black tree, if the hash table capacity is less than min tree capability, it should be executed at this time. resize the capacity expansion operation. The value of Min tree capability is at least 4 times that of tree threshold.) |
| table | An array of storage elements is always the n-th power of 2 |
| entrySet | A set that stores concrete elements |
| size | The number of key value pairs stored in the HashMap |
| modCount | The number of HashMap expansion and structure changes. |
| threshold | Critical value of expansion, = capacity * filling factor |
| loadFactor | Fill factor (load factor) |
Underlying implementation principle
HashMap map = new HashMap():
After instantiation, the bottom layer creates a one-dimensional array with a length of 16 Entry[] table.
...It may have been performed multiple times put...
map.put(key1,value1):
First, call key1 Class hashCode()calculation key1 Hash value, which is obtained after being calculated by some algorithm Entry The storage location in the array.
If the data at this location is empty, the key1-value1 Added successfully. ----Case 1
If the data in this location is not empty,(Means that one or more data exists at this location(Exist as a linked list)),compare key1 And the hash value of one or more existing data:
If key1 The hash value of is different from that of the existing data. At this time key1-value1 Added successfully.----Case 2
If key1 The hash value of and a data that already exists(key2-value2)The hash value of is the same, continue to compare: call key1 Class equals(key2)Method, comparison:
If equals()return false:here key1-value1 Added successfully.----Case 3
If equals()return true:use value1 replace value2.
Add: about case 2 and case 3: at this time key1-value1 And the original data are stored in a linked list.
In the process of continuous addition, capacity expansion will be involved when the critical value is exceeded(And the location to be stored is not empty)When, expand the capacity.
Default capacity expansion method: double the original capacity and copy the original data.
Source code analysis
-
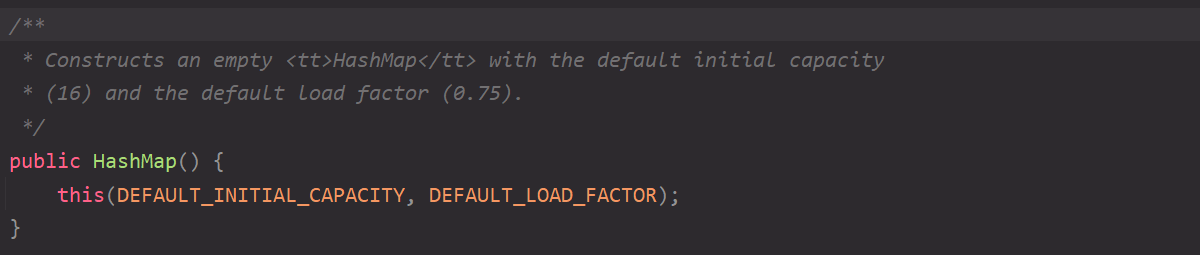
Open the HashMap class, Ctrl + F12, and find the HashMap null parameter constructor;
-
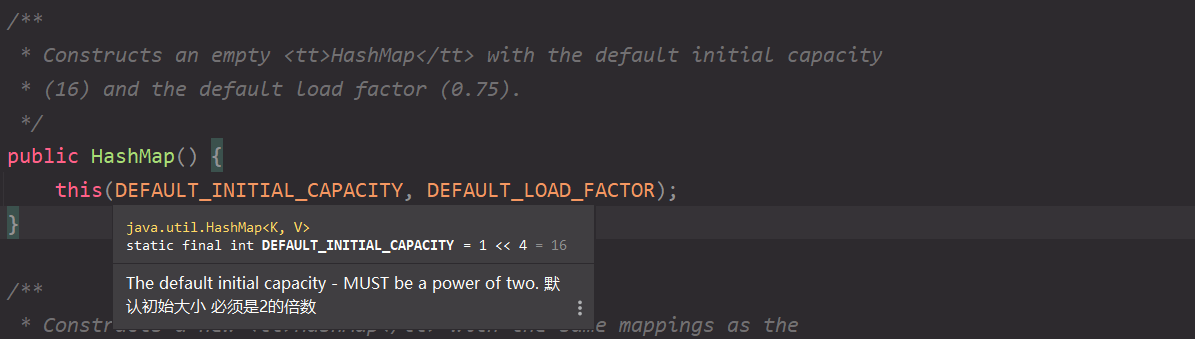
You can see that the constant initialization capacity is 16, i.e. 1 < < 4, by hovering the mouse or looking directly on it; The load factor is initialized to 0.75;
-
After understanding its initialization capacity, we come to the constructor with parameters;
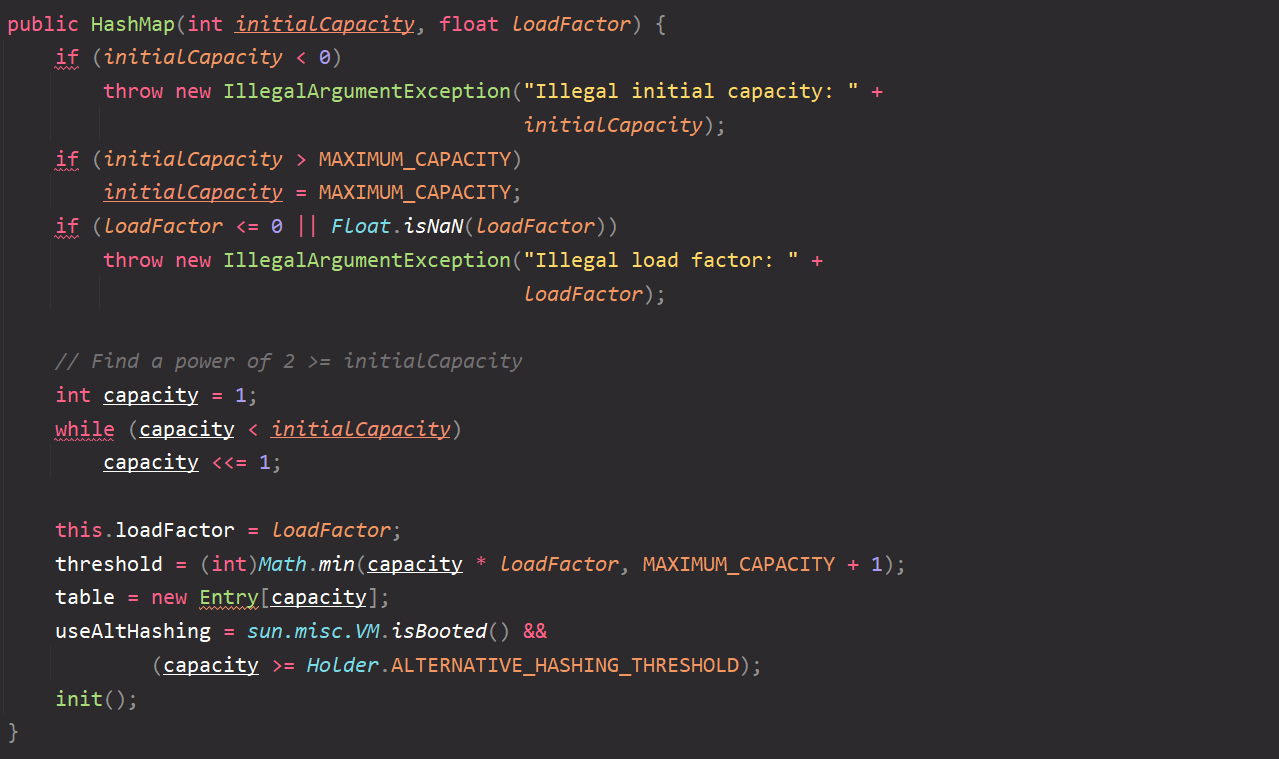
Let's go through the constructor through the pseudo code:
-
Incoming initialization capacity 16 and load factor 0.75;
-
Judge that since the initialization capacity is not less than 0, it will not throw exceptions and enter the next step;
-
Judge that the initialization capacity is less than the set maximum capacity value of 2 ^ 30, so go to the next step;
-
Here is a specification of the capacity so that it is power 2;
-
The load factor of the current assignment object is 0.75;
-
The critical value of expansion is 16 * 0.75 = 12;
Its function is to prepare for capacity expansion before the HashMap is full, and the critical value serves as that boundary. That is, the capacity will be expanded when 12 are stored;
-
Construct an array table with data type of Entry (Entry < K, V > [] table);
After the process is completed, it is equivalent to initializing a HashMap object. Namely
HashMap map = new HashMap();
-
After initialization, enter the put phase. Find the corresponding position by Ctrl + F12 search method;
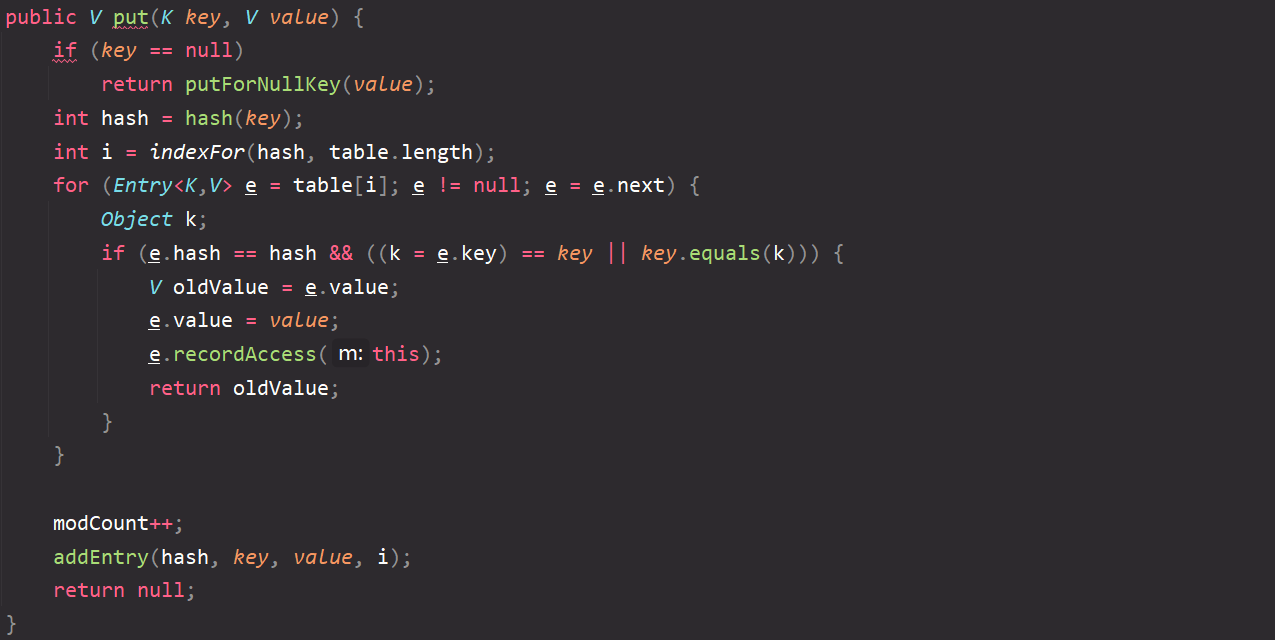
Here through
map.put(key1,value1);
Call the put method. Now go inside the put method:
-
Pass in key1 and value1 key value pairs;
-
Judge that key1 is assumed to be non empty and proceed to the next step; Of course, if key1 is null, it is stored in the HashMap instantiation object through the putForNullKey() method;
-
Get the hash value through the hash() method (Note: it is not a direct call to the hashCode() method). Click the specific algorithm to see that more bit operations are involved. Continue to study it if you are interested; As shown in the figure:
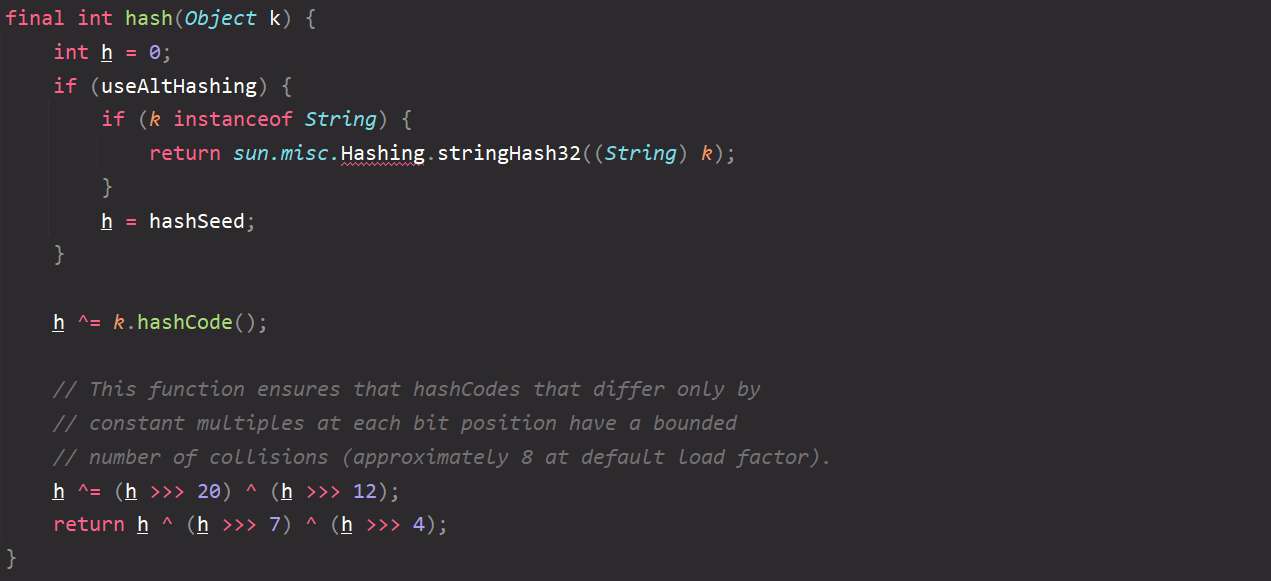
-
At this time, the calculated hash value cannot be used (you can see that the median operation in the source code is enough to see that the result may be very large, so the algorithm must be optimized). Therefore, calculate through the indexFor() method to get the location where the element should be stored. As shown in the figure:

-
Through and operation, I can be obtained, that is, the position where the required elements should be stored in the array. By the way, the modular% operation can be used when the user-defined hash function is mentioned earlier. Why use & operation here? Because the mutation hash value of the previous step & table Length (i.e. 16 - 1 = 15). Here, it is guaranteed that the result has only four bits, does not exceed the maximum value of the array index, and the operation efficiency is slightly higher than the modular operation; (as we all know, modular operation is the least efficient)
-
Then judge the for loop condition.
Case 1 (case 1 in the underlying implementation principle above, see the corresponding): the data does not conflict:
-
First, it is assumed that the data does not conflict, that is, it does not enter the cycle and enters the next step;
-
You can directly add the key value pair through the addEntry() method.
Case 2: data conflict:
- At this time, entering the for loop indicates that there are already elements at this position, and there may be more than one;
- If the hash value of the element to be added is different from the current e.hash through comparison, the for loop enters e.next(); If there is no matching known element, the for loop will be jumped out and added successfully; (see case 2 in the underlying implementation principle above)
- If the hash value of the element to be added is found to be equal to e.hash through comparison, continue to compare its keys. If the keys are different, call the equals() method again to find that the keys are different, return false, and jump out of the loop to add key value pairs; (see case 2 in the underlying implementation principle above)
- If it is found through comparison that the hash value of the element to be added is equal to e.hash, and the address of the key is also equal, it means that it must be the same, return true and enter the if statement block;
- Declare oldValue and assign it back, assign it to the value of the newly added element of e.value, and produce a replacement effect.
-
-
-
In the process of adding elements, you may encounter the problem of capacity expansion. At this time, enter the addEntry() method;
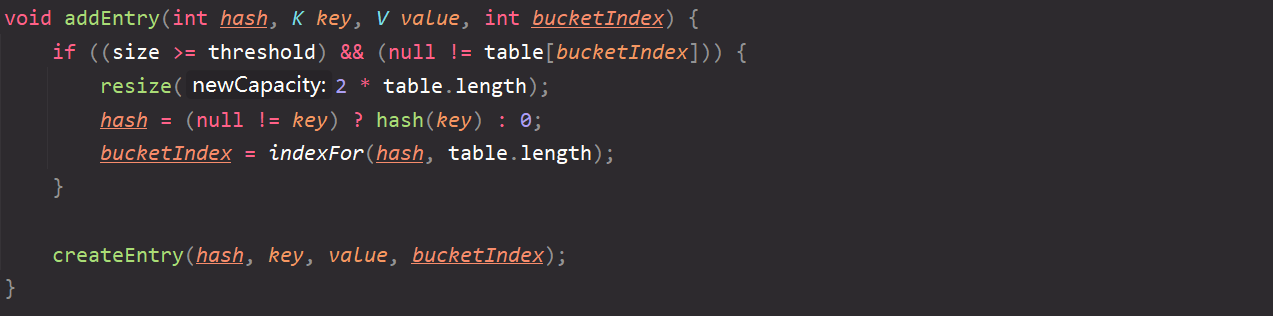
-
bucketIndex is the index position in the table into which the new element will be inserted. As usual, run the method through pseudo code:
Case 1:
- Judge that if the number of elements stored in the table is greater than or equal to the expansion critical value and the corresponding index position is not empty, the expansion will be twice the original;
- And calculate and arrange each element (key value pair) in the new table;
Case 2:
- Judge if the number of elements stored in the table is greater than or equal to the capacity expansion threshold, but the corresponding index position is empty;
- Without capacity expansion, directly call the createEntry() method to store a new key value pair.
-
Here, go inside the createEntry() method;

-
What is involved here is the algorithm of adding elements to the corresponding linked list structure on each table; The pseudo code is as follows:
- First, take out the key value pairs that originally existed on the table index;
- Assign the new key value pair to the original table index position;
- What about the key value pair corresponding to the original index? Next step description.
-
Click the Entry data type in the createEntry method, and we can find:
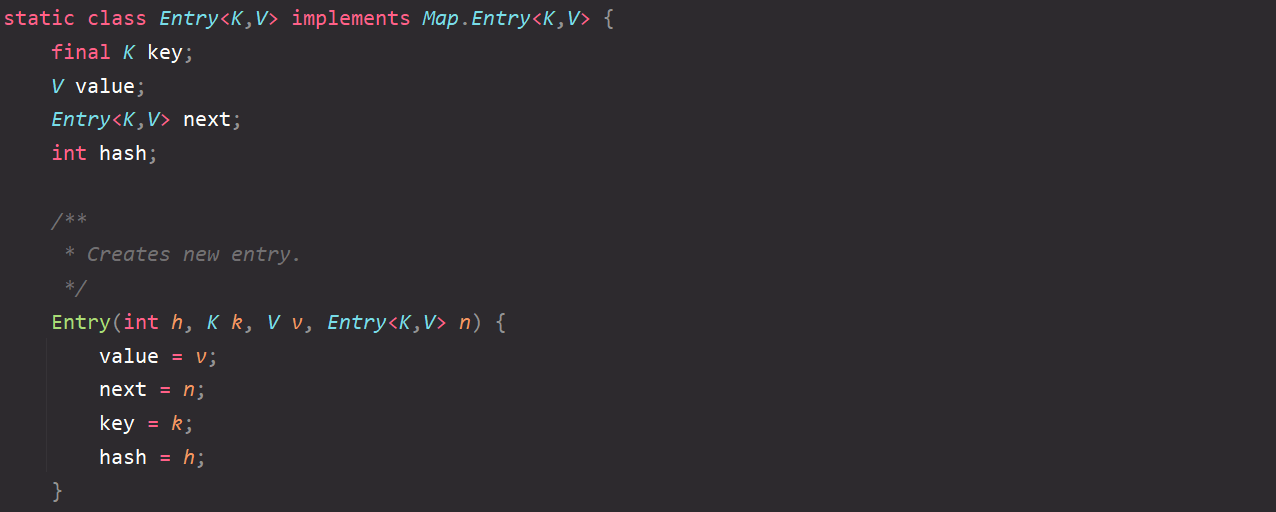
-
In addition to value, key also has a next attribute in the Entry data type, and the statement is just called:
table[bucketIndex] = new Entry<>(hash, key, value, e);
The function is: ① replace the original index position with the newly added key value pair; ② pass e as the next attribute into the new key value pair
- The above is the analysis of jdk7HashMap source code.
23. Implementation principle and source code analysis of HashMap at the bottom of JDK8
Underlying implementation principle
jdk8 Compared to jdk7 Differences in underlying implementation:
1. new HashMap():The bottom layer does not create an array with a length of 16, jdk8 The underlying array is: Node[],Not Entry[],
First call put()Method, the underlying layer creates an array with a length of 16
2. jdk7 The underlying structure has only: array+Linked list. jdk8 Middle and bottom structure: array+Linked list+Red and black trees.
2.1 When forming a linked list, seven up and eight down( jdk7:The new element points to the old element. jdk8: Old element points to new element)
2.2 The number of data in the form of a linked list when the element at an index position of the array exists >= 8 And the length of the current array >= 64 When,
At this time, all data at this index location is stored in red black tree instead.
DEFAULT_INITIAL_CAPACITY : HashMap Default capacity of, 16
DEFAULT_LOAD_FACTOR: HashMap Default load factor for: 0.75
threshold: Critical value of capacity expansion,= capacity*Loading factor = 16 * 0.75 => 12
TREEIFY_THRESHOLD: Bucket If the length of the linked list is greater than the default value, it will be converted into a red black tree:8
MIN_TREEIFY_CAPACITY: In the bucket Node Smallest when treelized hash Table capacity:64
Source code analysis
-
And jdk1 7. Click Ctrl + F12 to search for the parameterless HashMap constructor in the source code;

-
It can be seen that the table capacity is not given at the beginning, but only the initial load factor, that is, the default 0.75; At this time, an array with a length of 16 is not created, which corresponds to the above underlying principle;
-
Then find the Node class. It can be found that except for changing the Entry to Node, the internally defined attributes have not changed;
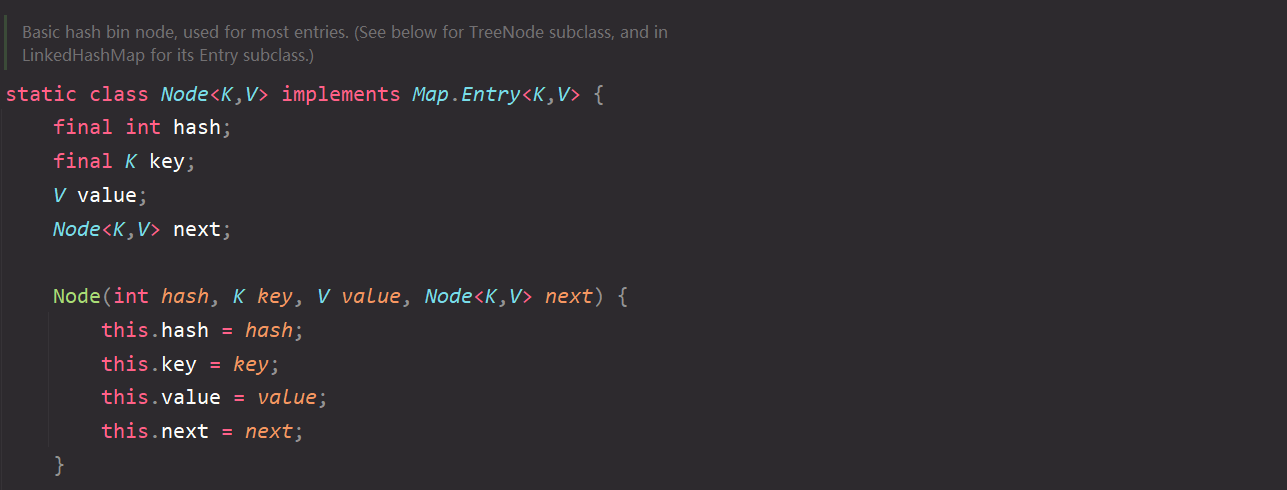
-
Now you are ready to add elements, so Ctrl + F12 searches for the put() method to enter;

This is the call
map.put(key1, value1);
Enter putVal() method;
-
In this, first obtain the hash value (or mutation hash value) of the element through the hash() method, because the "hash value" obtained after some processing; See the following for specific treatment:

-
Now I will officially enter the putVal() method. Due to the long code, I directly use comments to write pseudo code and run the whole method for visualization;
// 1. Pass in parameters: Processed hash value, key1, value1 and two Boolean values; (two Boolean values are not concerned for the time being)
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
// 2. Declare the instantiated object tab, p of Node type; int type n, i;
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 3. Judge that the table at this time is null because it is not initialized, so it returns true in if
if ((tab = table) == null || (n = tab.length) == 0)
// 3.1 enter if and click to enter the resize() method for initialization; The resize() method is shown below;
n = (tab = resize()).length;
// 4. Judge whether the object corresponding to the processed index is empty;
if ((p = tab[i = (n - 1) & hash]) == null)
// 4.1 if it is blank, you can add it directly; This newNode() is a return value method
tab[i] = newNode(hash, key, value, null);
// 4.2 if it is not empty at this time, enter the following structure;
else {
// Declare some temporary variables
Node<K,V> e; K k;
// p here is the key value pair corresponding to the original index position. Note: the following subheadings correspond to 5.1 -- > 6.1 -- > 7.1
// 5.1 assuming that the newly added key value pair is exactly the same as the key value pair at the original index position, of course, value is generally different, enter the following if structure
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
// 5.1 take out the key value pair of the original index position and assign it to the new Node object e;
e = p;
// 5.2 red and black trees will not be considered temporarily and will be skipped;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// 5.2 suppose that the newly added key value pairs are different from p (different hash values or different keys), in order to compare the key value pairs on the external linked list of the original index, enter else
else {
for (int binCount = 0; ; ++binCount) {
// 6.2 judge that if the index has no external linked list or the corresponding index has only one element, enter the following structure
if ((e = p.next) == null) {
// 6.2.1 insert the element to be inserted as the element attribute next on the meta index. At this time, there is only one element in the external linked list
p.next = newNode(hash, key, value, null);
// When the length of the external linked list exceeds the defined constant treeify_ When threshold = 8, enter the following structure
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
// Integrate into a tree structure and click to enter the treeifyBin() method, as shown below
treeifyBin(tab, hash);
break;
}
// At this time, e is p.next; After the for loop, compare each element on the external linked list of the index. If there is the same, break out and replace value
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// 6.1 since e is assigned as a copy of p and is not empty, it enters the if structure;
if (e != null) { // existing mapping for key
// 7. Pass in the value in the new key value pair and replace the old value
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
- Determine if to initialize the table through putVal() method. Since the resize() method, the pseudo code is embedded as follows:
final Node<K,V>[] resize() {
// 1. Assign an empty table to the newly declared Node object;
Node<K,V>[] oldTab = table;
// 2. Since table is null, 0 is assigned to oldCap
int oldCap = (oldTab == null) ? 0 : oldTab.length;
// 3. Since a load factor is assigned at the beginning, the critical value of capacity expansion here is also 0 and assigned to oldThr
int oldThr = threshold;
int newCap, newThr = 0;
// 4. Judge that since oldCap is 0, skip;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
// 5. Judge that since oldThr is 0, it is also skipped;
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
// 6. Enter the structure; At this time, newCap can be initialized to 16; newThr is initialized to 12;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 7. Judge, because newthr = 12= 0, skip;
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
// 8. Assign newThr to the critical value to initialize it;
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
// 9. At this time, initialize an object of Node type through newCap = 16 and allocate space;
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
// 10. Assign this object address to table; At this time, the table is not empty and initialized as a Node object with a capacity of 16
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
// 11. Return the object
return newTab;
}
- Enter treeifyBin() method and convert it into red black tree if it meets the conditions
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
// Only when the tab is empty or returns true will it enter the if structure;
// 1. If tab Length is now less than the defined constant min_ TREEIFY_ If capacity = 64, expand and resize();
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
TreeNode<K,V> hd = null, tl = null;
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}
Note: why is the load factor initially set to 0.75?
A: the original intention of the load factor is to meet the demand of expanding HashMap in advance; So why do you need to expand HashMap in advance? Because the index value obtained by the indexFor() method may not cover individual indexes, there will be more linked list forms. In order to reduce the probability of the linked list, the load factor is reduced; However, if it is too small, it will lead to the urgent expansion of the array just after using several indexes, resulting in the decline of array utilization; So we have to increase the load factor a little, but too much will lead to the increase of linked list. Through the study of statistical law, it is concluded that the load factor is the most appropriate when it is (0.7 ~ 0.75).
24. Underlying implementation principle of LinkedHashMap
Why can LinkedHashMap print in initialization order during traversal? In fact, it is because its underlying layer overrides the newNode() method and the Entry() method.
-
First, go to the LinkedHashMap source code. It can be found that when calling the put method, because the put method is not implemented, what is actually called is the put() method of the parent class HashMap;

-
Similarly, we enter the newNode() method in the putVal() method:

Finally, it is found that LinkedHashMap implements the newNode() method; Click to enter the Entry class to find its underlying data structure;
-
We can know why LinkedHashMap can traverse the elements in the print set according to the input order:

Because there are two more pointers in its Entry, pointing to the previous element (before) and the latter element (after).
25. Common methods in map
① Add, delete and modify
| Object put(Object key,Object value) | Add (or modify) the specified key value to the current map object |
|---|---|
| void putAll(Map m) | Store all key value pairs in m into the current map |
| Object remove(Object key) | Remove the key value pair of the specified key and return value |
| void clear() | Clear all data in the current map |
② Operation of element query
| Object get(Object key) | Gets the value corresponding to the specified key |
|---|---|
| boolean containsKey(Object key) | Whether to include the specified key |
| boolean containsValue(Object value) | Whether to include the specified value |
| int size() | Returns the number of key value pairs in the map |
| boolean isEmpty() | Judge whether the current map is empty |
| boolean equals(Object obj) *** | Judge whether the current map and parameter object obj are equal |
③ Methods of meta view operation
| Set keySet() | Returns the Set set composed of all key s |
|---|---|
| Collection values() | Returns a Collection of all value s |
| Set entrySet() | Returns the Set set composed of all key value pairs |
④ Common methods
| add to | put(Object key,Object value) |
|---|---|
| delete | remove(Object key) |
| modify | put(Object key,Object value) |
| query | get(Object key) |
| length | size() |
| ergodic | keySet() / values() / entrySet() |
example
public class MapTest1 {
@Test
public void test1() {
Map map = new HashMap();
// map = new Hashtable();
map.put(null, 123);
}
@Test
public void test2() {
Map map = new HashMap();
map = new LinkedHashMap();
map.put(123, "AA");
map.put(345, "BB");
map.put(12, "CC");
System.out.println(map);
}
/*
Add, delete and modify:
Object put(Object key,Object value): Add (or modify) the specified key value to the current map object
void putAll(Map m):Store all key value pairs in m into the current map
Object remove(Object key): Remove the key value pair of the specified key and return value
void clear(): Clear all data in the current map
*/
@Test
public void test3() {
Map map = new HashMap();
//add to
map.put("AA", 123);
map.put(45, 123);
map.put("BB", 56);
//modify
map.put("AA", 87);
System.out.println(map);
Map map1 = new HashMap();
map1.put("CC", 123);
map1.put("DD", 123);
map.putAll(map1);
System.out.println(map);
//remove(Object key)
Object value = map.remove("CC");
System.out.println(value);
System.out.println(map);
//clear()
map.clear();//Different from map = null operation
System.out.println(map.size());
System.out.println(map);
}
/**
Operation of element query:
Object get(Object key): Gets the value corresponding to the specified key
boolean containsKey(Object key): Whether to include the specified key
boolean containsValue(Object value): Whether to include the specified value
int size(): Returns the number of key value pairs in the map
boolean isEmpty(): Judge whether the current map is empty
boolean equals(Object obj): Judge whether the current map and parameter object obj are equal
*/
@Test
public void test4() {
Map map = new HashMap();
map.put("AA", 123);
map.put(45, 123);
map.put("BB", 56);
// Object get(Object key)
System.out.println(map.get(45));
//containsKey(Object key)
boolean isExist = map.containsKey("BB");
System.out.println(isExist);
//containsValue(Object value)
isExist = map.containsValue(123);
System.out.println(isExist);
map.clear();
System.out.println(map.isEmpty());
}
/**
Method of metaview operation:
Set keySet(): Returns the Set set composed of all key s
Collection values(): Returns a Collection of all value s
Set entrySet(): Returns the Set set composed of all key value pairs
*/
@Test
public void test5() {
Map map = new HashMap();
map.put("AA", 123);
map.put(45, 1234);
map.put("BB", 56);
//Traverse all key sets: keySet()
Set set = map.keySet();
Iterator iterator = set.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
System.out.println();
//Traverse all value sets: values()
Collection values = map.values();
for (Object obj : values) {
System.out.println(obj);
}
System.out.println();
//Traverse all key values
//Method 1: entrySet()
Set entrySet = map.entrySet();
Iterator iterator1 = entrySet.iterator();
while (iterator1.hasNext()) {
Object obj = iterator1.next();
//All the elements in the entry set set are entries, so force to call the getKey() and getValue() methods in the Map
Map.Entry entry = (Map.Entry) obj;
System.out.println(entry.getKey() + "---->" + entry.getValue());
}
System.out.println();
//Mode 2:
Set keySet = map.keySet();
Iterator iterator2 = keySet.iterator();
while (iterator2.hasNext()) {
Object key = iterator2.next();
// Get value by calling get() method through key
Object value = map.get(key);
System.out.println(key + "=====" + value);
}
}
}
26. Two sorting methods of treemap
Natural sorting
//Natural sorting
@Test
public void test1() {
TreeMap map = new TreeMap();
User u1 = new User("Tom", 23);
User u2 = new User("Jerry", 32);
User u3 = new User("Jack", 20);
User u4 = new User("Rose", 18);
map.put(u1, 98);
map.put(u2, 89);
map.put(u3, 76);
map.put(u4, 100);
Set entrySet = map.entrySet();
Iterator iterator1 = entrySet.iterator();
while (iterator1.hasNext()) {
Object obj = iterator1.next();
Map.Entry entry = (Map.Entry) obj;
System.out.println(entry.getKey() + "---->" + entry.getValue());
}
}
Custom sorting
//Custom sorting
@Test
public void test2() {
TreeMap map = new TreeMap(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
if (o1 instanceof User && o2 instanceof User) {
User u1 = (User) o1;
User u2 = (User) o2;
return Integer.compare(u1.getAge(), u2.getAge());
}
throw new RuntimeException("The input type does not match!");
}
});
User u1 = new User("Tom", 23);
User u2 = new User("Jerry", 32);
User u3 = new User("Jack", 20);
User u4 = new User("Rose", 18);
map.put(u1, 98);
map.put(u2, 89);
map.put(u3, 76);
map.put(u4, 100);
Set entrySet = map.entrySet();
Iterator iterator1 = entrySet.iterator();
while (iterator1.hasNext()) {
Object obj = iterator1.next();
Map.Entry entry = (Map.Entry) obj;
System.out.println(entry.getKey() + "---->" + entry.getValue());
}
}
User class
public class User implements Comparable {
private String name;
private int age;
public User() {
}
public User(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "User{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
@Override
public boolean equals(Object o) {
System.out.println("User equals()....");
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
User user = (User) o;
if (age != user.age) return false;
return name != null ? name.equals(user.name) : user.name == null;
}
@Override
public int hashCode() { //return name.hashCode() + age;
int result = name != null ? name.hashCode() : 0;
result = 31 * result + age;
return result;
}
//In descending order of name and age
@Override
public int compareTo(Object o) {
if (o instanceof User) {
User user = (User) o;
// return -this.name.compareTo(user.name);
int compare = -this.name.compareTo(user.name);
if (compare != 0) {
return compare;
} else {
return Integer.compare(this.age, user.age);
}
} else {
throw new RuntimeException("The types entered do not match");
}
}
}
27.Properties processing properties file
Overview: Properties is a subclass of Hashtable, which is used to process property files.
import java.io.FileInputStream;
import java.io.IOException;
import java.util.Properties;
public class PropertiesTest {
/**
* properties:Commonly used to process configuration files. Both key and value are String types
*/
public static void main(String[] args) {
FileInputStream fis = null;
try {
Properties pros = new Properties();
fis = new FileInputStream("jdbc.properties");
pros.load(fis); // Load the file corresponding to the stream
String name = pros.getProperty("name");
String password = pros.getProperty("password");
System.out.println("name = " + name + ", password = " + password);
} catch (IOException e) {
e.printStackTrace();
} finally {
if (fis != null) {
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
28. Common methods of collections tool class
import org.junit.Test;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;
/**
* Collections:Tool classes for operating Collection and Map
*
* Interview question: what is the difference between Collection and Collections?
*/
public class CollectionsTest {
/**
reverse(List): Reverse the order of elements in the List
shuffle(List): Random sorting of List collection elements
sort(List): Sorts the specified List collection elements in ascending order according to the natural order of the elements
sort(List,Comparator): Sorts the List collection elements according to the order generated by the specified Comparator
swap(List,int, int): Exchange the elements at i and j in the specified list set
int frequency(Collection,Object): Returns the number of occurrences of the specified element in the specified collection
Object max(Collection): Returns the largest element in a given set according to the natural order of the elements
Object max(Collection,Comparator): Returns the largest element in a given collection in the order specified by the Comparator
Object min(Collection)
Object min(Collection,Comparator)
void copy(List dest,List src): Copy the contents of src to dest
boolean replaceAll(List list,Object oldVal,Object newVal): Replace all the old values of the List object with the new values
*/
@Test
public void test1() {
List list = new ArrayList();
list.add(123);
list.add(43);
list.add(765);
list.add(765);
list.add(765);
list.add(-97);
list.add(0);
System.out.println(list);
// Collections.reverse(list);
// Collections.shuffle(list);
// Collections.sort(list);
// Collections.swap(list,1,2);
System.out.println(list);
int frequency = Collections.frequency(list, 123);
System.out.println(frequency);
}
@Test
public void test2() {
List list = new ArrayList();
list.add(123);
list.add(43);
list.add(765);
list.add(-97);
list.add(0);
//Exception: IndexOutOfBoundsException("Source does not fit in dest")
//Reason: srcsize > dest Size(), even if the length is specified, it is still 0 at this time
// List dest = new ArrayList();
// Collections.copy(dest,list);
//Correct: ****************************************************** important
List dest = Arrays.asList(new Object[list.size()]);
System.out.println(dest.size());//list.size();
Collections.copy(dest, list);
System.out.println(dest);
/*
Collections Class provides multiple synchronizedXxx() methods,
This method can wrap the specified set into a thread synchronized set, which can solve the problem
Thread safety in multithreaded concurrent access to collections
*/
//The returned list1 is the thread safe List
List list1 = Collections.synchronizedList(list);
}
}
29. Review of additional associations: common methods of Arrays tools
import java.util.Arrays;
/*
* java.util.Arrays:The tool class for operating arrays defines many methods for operating arrays
*
*
*/
public class ArraysTest {
public static void main(String[] args) {
//1.boolean equals(int[] a,int[] b): judge whether two arrays are equal.
int[] arr1 = new int[]{1, 2, 3, 4};
int[] arr2 = new int[]{1, 3, 2, 4};
boolean isEquals = Arrays.equals(arr1, arr2);
System.out.println(isEquals);
//2.String toString(int[] a): output array information.
System.out.println(Arrays.toString(arr1));
//3.void fill(int[] a,int val): fill the specified value into the array.
Arrays.fill(arr1, 10);
System.out.println(Arrays.toString(arr1));
//4.void sort(int[] a): sort the array.
Arrays.sort(arr2);
System.out.println(Arrays.toString(arr2));
//5.int binarySearch(int[] a,int key)
int[] arr3 = new int[]{-98, -34, 2, 34, 54, 66, 79, 105, 210, 333};
int index = Arrays.binarySearch(arr3, 210);
if (index >= 0) {
System.out.println(index);
} else {
System.out.println("not found");
}
}
}