Fork / Join is a tool framework. Its core idea is to cut a large operation into multiple small parts and make the most efficient use of resources. It mainly involves three classes: forkjoinpool / forkjointask / recursive task
1, Overview
ava.util.concurrent.ForkJoinPool is written under the auspices of Java master Doug Lea. It can split a large task into multiple subtasks for parallel processing, and finally merge the subtask results into the final calculation results for output. The explanation of Fork/Join framework in this article is based on jdk1 The Fork/Join framework in 8 + is implemented. The main source code of the referenced Fork/Join framework is also based on jdk1 8+.
This article will first talk about recursive task, and then explain the basic use of Fork/Join framework; Then, understand the key points to be paid attention to in combination with the working principle of Fork/Join framework; Finally, I will explain how to use Fork/Join framework to solve some practical problems.
2, Say something about recursive task
Recursive task is a recursive implementation of ForkJoinTask. For example, it can be used to calculate Fibonacci sequence:
class Fibonacci extends RecursiveTask<Integer> {
final int n;
Fibonacci(int n) { this.n = n; }
Integer compute() {
if (n <= 1)
return n;
Fibonacci f1 = new Fibonacci(n - 1);
f1.fork();
Fibonacci f2 = new Fibonacci(n - 2);
return f2.compute() + f1.join();
}
}RecursiveTask inherits the ForkJoinTask interface and has several main methods:
// Node 1: returns the result and stores the final result
V result;
// Node 2: abstract method compute, which is used to calculate the final result
protected abstract V compute();
// Node 3: get the final result
public final V getRawResult() {
return result;
}
// Node 4: the final execution method. Here, the specific implementation class compute needs to be called
protected final boolean exec() {
result = compute();
return true;
}Common usage:
@
public class ForkJoinPoolService extends RecursiveTask<Integer> {
private static final int THRESHOLD = 2; //threshold
private int start;
private int end;
public ForkJoinPoolService(Integer start, Integer end) {
this.start = start;
this.end = end;
}
@Override
protected Integer compute() {
int sum = 0;
boolean canCompute = (end - start) <= THRESHOLD;
if (canCompute) {
for (int i = start; i <= end; i++) {
sum += i;
}
} else {
int middle = (start + end) / 2;
ForkJoinPoolService leftTask = new ForkJoinPoolService(start, middle);
ForkJoinPoolService rightTask = new ForkJoinPoolService(middle + 1, end);
//Execute subtasks
leftTask.fork();
rightTask.fork();
//Wait for the execution of the subtask and get its results
Integer rightResult = rightTask.join();
Integer leftResult = leftTask.join();
//Merge subtasks
sum = leftResult + rightResult;
}
return sum;
}
}3, Fork/Join framework is basically used
Here is a simple example of the use of the Fork/Join framework. In this example, we calculated the accumulated value of 1-1001:
/**
* This is a simple Join/Fork calculation process, adding 1-1001 numbers
*/
public class TestForkJoinPool {
private static final Integer MAX = 200;
static class MyForkJoinTask extends RecursiveTask<Integer> {
// The value calculated at the beginning of the subtask
private Integer startValue;
// Value calculated at the end of the subtask
private Integer endValue;
public MyForkJoinTask(Integer startValue , Integer endValue) {
this.startValue = startValue;
this.endValue = endValue;
}
@Override
protected Integer compute() {
// If the condition is true, it indicates that the value to be calculated for this task is small enough
// The accumulation calculation can be formally carried out
if(endValue - startValue < MAX) {
System.out.println("Part to start calculation: startValue = " + startValue + ";endValue = " + endValue);
Integer totalValue = 0;
for(int index = this.startValue ; index <= this.endValue ; index++) {
totalValue += index;
}
return totalValue;
}
// Otherwise, split the task into two tasks
else {
MyForkJoinTask subTask1 = new MyForkJoinTask(startValue, (startValue + endValue) / 2);
subTask1.fork();
MyForkJoinTask subTask2 = new MyForkJoinTask((startValue + endValue) / 2 + 1 , endValue);
subTask2.fork();
return subTask1.join() + subTask2.join();
}
}
}
public static void main(String[] args) {
// This is the thread pool of the Fork/Join framework
ForkJoinPool pool = new ForkJoinPool();
ForkJoinTask<Integer> taskFuture = pool.submit(new MyForkJoinTask(1,1001));
try {
Integer result = taskFuture.get();
System.out.println("result = " + result);
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace(System.out);
}
}
}The above code is very simple, and there are relevant notes at key locations. Here, the key points in the above example are explained. First, take a look at the possible execution results of the above example code:
Start calculation part: startValue = 1;endValue = 126 Start calculation part: startValue = 127;endValue = 251 Start calculation part: startValue = 252;endValue = 376 Start calculation part: startValue = 377;endValue = 501 Start calculation part: startValue = 502;endValue = 626 Part to start calculation: startValue = 627;endValue = 751 Start calculation part: startValue = 752;endValue = 876 Start calculation part: startValue = 877;endValue = 1001 result = 501501
4, Working sequence diagram
The following figure shows the working process outline of the above code, but in fact, the internal working process of the Fork/Join framework is much more complex than this figure, such as how to decide which thread a recursive task uses to run; Another example is how to decide whether to create a new thread to run or let it wait in the queue after a task / subtask is submitted to the Fork/Join framework.
Therefore, if we do not deeply understand the operation principle of the Fork/Join framework and only observe the operation effect according to the simplest use example above, we can only know that after the subtasks are split small enough in the Fork/Join framework, and the multithreading is used to complete the calculation of these small tasks in parallel, then the result upward merging action is carried out, and finally the top-level result is formed. Don't worry, step by step. Let's start with this outline process diagram.
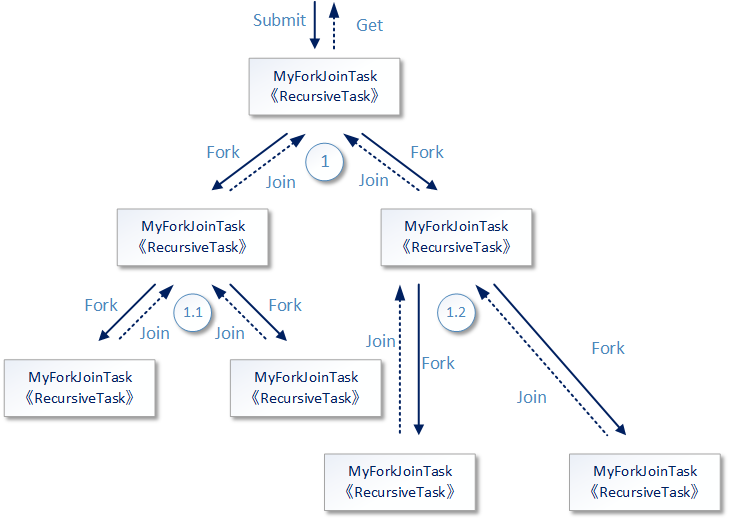
The top-level task in the figure is submitted to the Fork/Join framework in the submit mode. The latter puts the former into a thread to run. The code of the compute method in the work task starts to analyze the task T1. If the number range that the current task needs to accumulate is too large (the number set in the code is greater than 200), the calculation task is divided into two subtasks (T1.1 and T1.2). Each subtask is responsible for calculating half of the data accumulation. See the fork method in the code. If the range of numbers to be accumulated in the current subtask is small enough (less than or equal to 200), accumulate and return to the upper task.
1. ForkJoinPool constructor
ForkJoinPool has four constructors, of which the constructor with the most complete parameters is as follows:
public ForkJoinPool(int parallelism, ForkJoinWorkerThreadFactory factory, UncaughtExceptionHandler handler, boolean asyncMode)
-
Parallelism: parallelism level. The Fork/Join framework will determine the number of threads executing in parallel within the framework according to the setting of this parallelism level. Each parallel task will be processed by a thread, but do not understand this attribute as the maximum number of threads in the Fork/Join framework, and do not compare this attribute with the corePoolSize and maximumPoolSize attributes in the ThreadPoolExecutor thread pool, because the organizational structure and working mode of ForkJoinPool are completely different from the latter. In the subsequent discussion, readers can also find that the relationship between the number of threads that can exist in the Fork/Join framework and the parameter value is not absolute (based on but not entirely determined by it).
-
Factory: when the Fork/Join framework creates a new thread, it will also use the thread to create the factory. However, the thread factory no longer needs to implement the ThreadFactory interface, but needs to implement the ForkJoinWorkerThreadFactory interface. The latter is a functional interface that only needs to implement a method called newThread. In the Fork/Join framework, there is a default ForkJoinWorkerThreadFactory interface implementation: DefaultForkJoinWorkerThreadFactory.
-
Handler: exception capture handler. When an exception occurs in the executed task and is thrown from the task, it will be caught by the handler.
-
asyncMode: this parameter is also very important. Literally, it refers to the asynchronous mode. It does not mean whether the Fork/Join framework works in synchronous mode or asynchronous mode. In the Fork/Join framework, the corresponding task queue to be executed is prepared for each thread working independently. This task queue is a two-way queue composed of arrays. That is, the tasks to be executed in the queue can use either the first in first out mode or the last in first out mode.
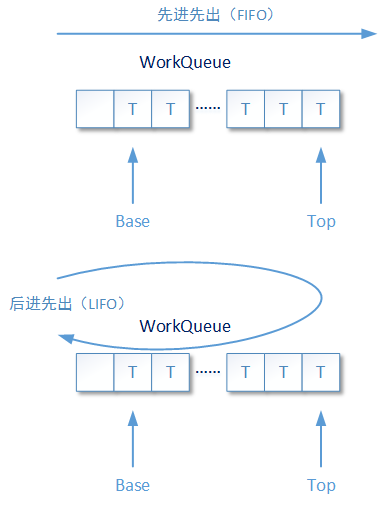
When asyncMode is set to true, the queue works in the first in first out mode; Otherwise, it works in the last in first out mode. This value is false by default
...... asyncMode ? FIFO_QUEUE : LIFO_QUEUE, ......
ForkJoinPool also has two other constructors. One constructor only takes the parallelism parameter, which can set the maximum number of parallel tasks of the Fork/Join framework; The other constructor does not take any parameters and is only a default value for the maximum number of parallel tasks - the number of CPU cores that the current operating system can use (runtime. Getruntime() availableProcessors()). In fact, ForkJoinPool also has a private and native constructor. The three constructors mentioned above are calls to this private and native constructor.
......
private ForkJoinPool(int parallelism,
ForkJoinWorkerThreadFactory factory,
UncaughtExceptionHandler handler,
int mode,
String workerNamePrefix) {
this.workerNamePrefix = workerNamePrefix;
this.factory = factory;
this.ueh = handler;
this.config = (parallelism & SMASK) | mode;
long np = (long)(-parallelism); // offset ctl counts
this.ctl = ((np << AC_SHIFT) & AC_MASK) | ((np << TC_SHIFT) & TC_MASK);
}
......If you have no specific execution requirements for the Fork/Join framework, you can directly use the constructor without any parameters. In other words, it is recommended that the maximum number of parallel tasks within the Fork/Join framework be based on the number of CPU cores that can be used by the current operating system, so as to ensure that when the CPU processes parallel tasks, Minimize the running state switching between task threads (in fact, the state switching between threads on a single CPU core is basically unavoidable, because the operating system runs multiple threads and processes at the same time).
2. fork method and join method
The fork method and join method provided in the Fork/Join framework can be said to be the two most important methods provided in the framework. They work together with the parallelism "number of parallel tasks", which can lead to the split subtask T1 1,T1.2. Even TX has different operation effects in Fork/Join framework. For example, TX subtasks or wait for other existing threads to run associated subtasks, or "recursively" execute other tasks in the thread running TX, or start a new thread to run subtasks
The fork method is used to put the newly created subtask into the work queue of the current thread. The Fork/Join framework will decide whether to let the task wait in the queue or create a new ForkJoinWorkerThread thread to run it according to the ForkJoinWorkerThread thread status of the ForkJoinTask task currently executing concurrently, Or it can evoke other ForkJoinWorkerThread threads waiting for a task to run it.
There are several element concepts to note. ForkJoinTask is a specific task that can be run in the Fork/Join framework, and only this type of task can be split and merged in the Fork/Join framework. ForkJoinWorkerThread thread is a feature thread running in the Fork/Join framework. In addition to the characteristics of ordinary threads, its main feature is that each ForkJoinWorkerThread thread has an independent work queue, which is used to store several sub tasks split in this thread.
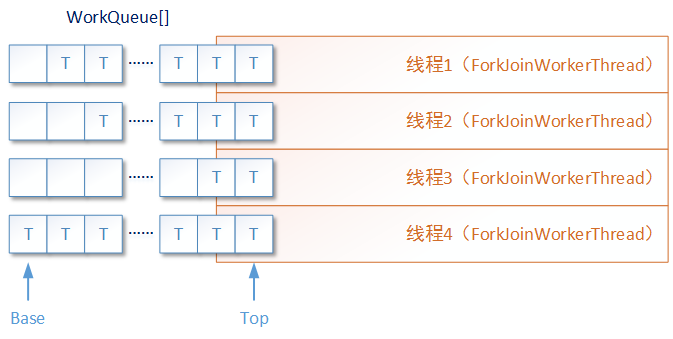
The join method is used to block the current thread until the corresponding subtask completes running and returns the execution result. Or, if the subtask exists in the work queue of the current thread, take out the subtask for "recursive" execution. The purpose is to get the running results of the current subtask as soon as possible, and then continue to execute.
5, Use Fork/Join to solve practical problems
The previous example is to use the Fork/Join framework to complete the integer accumulation of 1-1000. This example is OK if it only demonstrates the use of Fork/Join framework, but there is still a certain gap between this example and the problems faced in practical work. In this article, we use the Fork/Join framework to solve a practical problem, that is, the problem of efficient sorting.
1. Use the merge algorithm to solve the sorting problem
Sorting problem is a common problem in our work. At present, many ready-made algorithms have been invented to solve this problem, such as a variety of interpolation sorting algorithms and a variety of exchange sorting algorithms. Among all the current sorting algorithms, merge sorting algorithm has better average time complexity (O(nlgn)) and better stability. Its core algorithm idea decomposes the large problem into multiple small problems, and merges the results.
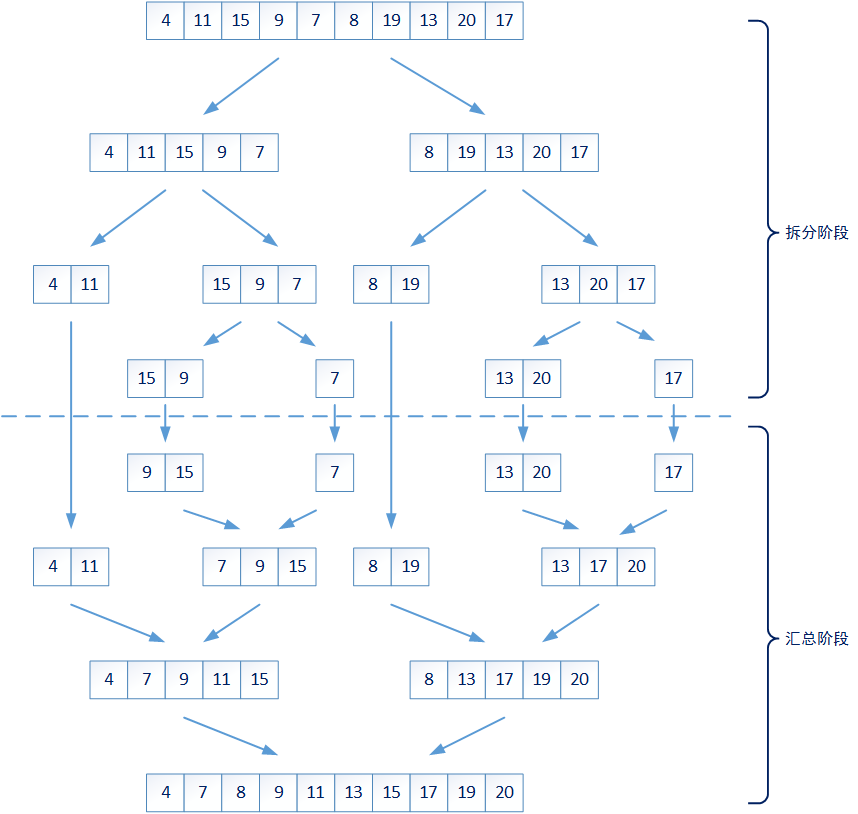
The splitting stage of the whole algorithm is to recursively split the unordered number set from a larger set into several smaller sets. These smaller sets either contain at most two elements or are considered not small enough and need to be split.
Then the sorting problem of elements in a set becomes two problems: 1. The size sorting of up to two elements in a smaller set; 2. How to merge two ordered sets into a new ordered set. The first problem is easy to solve, so will the second problem be very complex? In fact, the second problem is also very simple. You only need to traverse two sets at the same time - compare the smallest element in the current set and put the smallest element into a new set. Its time complexity is O(n):
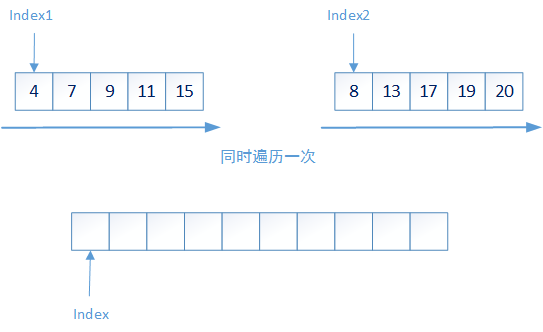
The following is a simple implementation of the merge sort algorithm:
package test.thread.pool.merge;
import java.util.Arrays;
import java.util.Random;
/**
* Merge sort
* @author yinwenjie
*/
public class Merge1 {
private static int MAX = 10000;
private static int inits[] = new int[MAX];
// This is to generate a set of random integers with the number of MAX and prepare the calculation data
// It has nothing to do with the algorithm itself
static {
Random r = new Random();
for(int index = 1 ; index <= MAX ; index++) {
inits[index - 1] = r.nextInt(10000000);
}
}
public static void main(String[] args) {
long beginTime = System.currentTimeMillis();
int results[] = forkits(inits);
long endTime = System.currentTimeMillis();
// If the data involved in sorting is very large, remember to remove this printing method
System.out.println("time consuming=" + (endTime - beginTime) + " | " + Arrays.toString(results));
}
// Split into smaller elements or sort a collection of elements that are small enough
private static int[] forkits(int source[]) {
int sourceLen = source.length;
if(sourceLen > 2) {
int midIndex = sourceLen / 2;
int result1[] = forkits(Arrays.copyOf(source, midIndex));
int result2[] = forkits(Arrays.copyOfRange(source, midIndex , sourceLen));
// Combine two ordered arrays into an ordered array
int mer[] = joinInts(result1 , result2);
return mer;
}
// Otherwise, it means that there is only one or two elements in the collection. You can compare and sort these two elements
else {
// If the condition holds, there is only one element in the array, or the elements in the array have been arranged
if(sourceLen == 1
|| source[0] <= source[1]) {
return source;
} else {
int targetp[] = new int[sourceLen];
targetp[0] = source[1];
targetp[1] = source[0];
return targetp;
}
}
}
/**
* This method is used to merge two ordered sets
* @param array1
* @param array2
*/
private static int[] joinInts(int array1[] , int array2[]) {
int destInts[] = new int[array1.length + array2.length];
int array1Len = array1.length;
int array2Len = array2.length;
int destLen = destInts.length;
// You only need to traverse once based on the length of the new set destInts
for(int index = 0 , array1Index = 0 , array2Index = 0 ; index < destLen ; index++) {
int value1 = array1Index >= array1Len?Integer.MAX_VALUE:array1[array1Index];
int value2 = array2Index >= array2Len?Integer.MAX_VALUE:array2[array2Index];
// If the condition holds, it indicates that the value in array array1 should be taken
if(value1 < value2) {
array1Index++;
destInts[index] = value1;
}
// Otherwise, take the value in array array2
else {
array2Index++;
destInts[index] = value2;
}
}
return destInts;
}
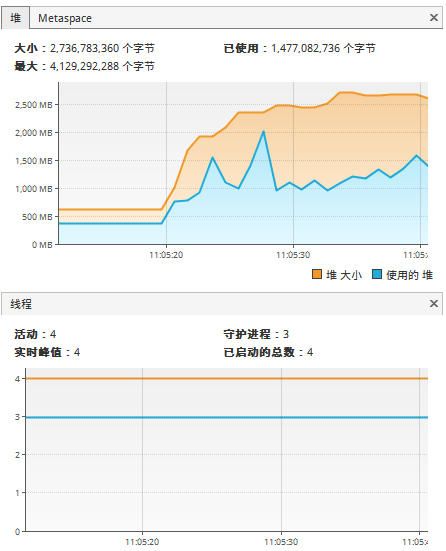
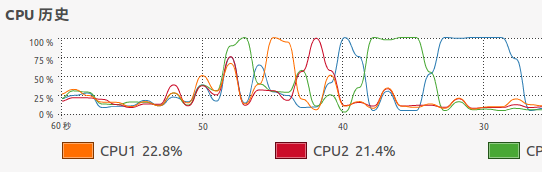
}The above merging algorithm only takes 2-3 milliseconds to sort 10000 random numbers, about 20 milliseconds to sort 100000 random numbers, and the average time to sort 1 million random numbers is about 160 milliseconds (depending on whether the randomly generated array to be sorted itself is messy). It can be seen that the merging algorithm itself has good performance. Using JMX tools and the CPU monitor of the operating system to monitor the execution of the application, it can be found that the whole algorithm runs in a single thread, and only a single CPU kernel works as the main processing kernel at the same time:
-
Thread conditions observed in JMX:
CPU operation:
2. Use Fork/Join to run the merge algorithm
However, as the data scale in the set to be sorted continues to increase, the code implementation of the above merging algorithm is not enough. For example, when the above algorithm sorts 100 million random number sets, it takes about 27 seconds.
Then we can use the Fork/Join framework to optimize the execution performance of the merge algorithm, instantiate the split subtasks into multiple ForkJoinTask tasks and put them into the to be executed queue, and the Fork/Join framework schedules these tasks among multiple ForkJoinWorkerThread threads. As shown in the figure below:
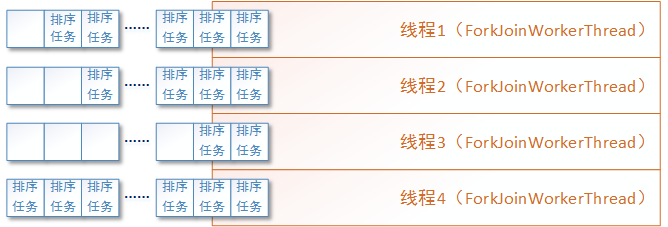
The following is the merging algorithm code after using the Fork/Join framework. Please note that the code for merging two ordered sets into a new ordered set in the joinInts method has not changed. Please refer to the previous section of this article. So I won't repeat it in the code:
......
/**
* Merge sorting algorithm using Fork/Join framework
* @author yinwenjie
*/
public class Merge2 {
private static int MAX = 100000000;
private static int inits[] = new int[MAX];
// Random queue initialization is also performed, which will not be repeated here
static {
......
}
public static void main(String[] args) throws Exception {
// Official start
long beginTime = System.currentTimeMillis();
ForkJoinPool pool = new ForkJoinPool();
MyTask task = new MyTask(inits);
ForkJoinTask<int[]> taskResult = pool.submit(task);
try {
taskResult.get();
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace(System.out);
}
long endTime = System.currentTimeMillis();
System.out.println("time consuming=" + (endTime - beginTime));
}
/**
* Single sorted subtasks
* @author yinwenjie
*/
static class MyTask extends RecursiveTask<int[]> {
private int source[];
public MyTask(int source[]) {
this.source = source;
}
/* (non-Javadoc)
* @see java.util.concurrent.RecursiveTask#compute()
*/
@Override
protected int[] compute() {
int sourceLen = source.length;
// If the condition holds, the set to be sorted in the task is not small enough
if(sourceLen > 2) {
int midIndex = sourceLen / 2;
// Split into two subtasks
MyTask task1 = new MyTask(Arrays.copyOf(source, midIndex));
task1.fork();
MyTask task2 = new MyTask(Arrays.copyOfRange(source, midIndex , sourceLen));
task2.fork();
// Combine two ordered arrays into an ordered array
int result1[] = task1.join();
int result2[] = task2.join();
int mer[] = joinInts(result1 , result2);
return mer;
}
// Otherwise, it means that there is only one or two elements in the collection. You can compare and sort these two elements
else {
// If the condition holds, there is only one element in the array, or the elements in the array have been arranged
if(sourceLen == 1
|| source[0] <= source[1]) {
return source;
} else {
int targetp[] = new int[sourceLen];
targetp[0] = source[1];
targetp[1] = source[0];
return targetp;
}
}
}
private int[] joinInts(int array1[] , int array2[]) {
// Consistent with the code shown above
}
}
}After using Fork/Join framework optimization, the sorting processing time of 100 million random numbers is about 14 seconds. Of course, this is also related to the clutter of the set to be sorted and CPU performance. However, in general, this method has about 30% performance improvement over the merge sorting algorithm without Fork/Join framework. The following are the CPU state and thread state observed during execution:
-
Memory and thread status in JMX:
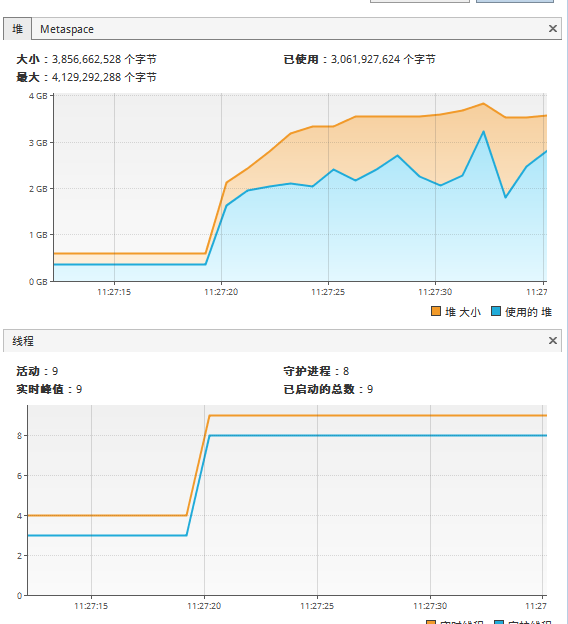
CPU usage:
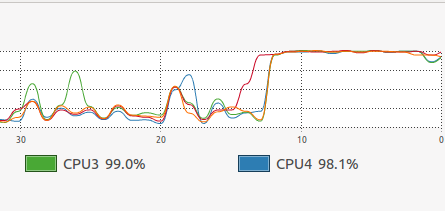
In addition to the internal optimization details of the merging algorithm code implementation, after using the Fork/Join framework, we basically give full play to the computing resources of each CPU core at the same time while ensuring the thread size of the operating system.