Preface
The blog started a quick peek at Java Concurrency Containers after a simple peek at CAS and final keywords in the previous post. HashMap, ArrayList, and so on, are non-thread-safe. In Java, if you want HashMap and Array List to be thread safe directly, you can do so by doing the following
Collections.synchronizedList(new ArrayList<E>()); Collections.synchronizedMap(new HashMap<K,V>());
However, the bottom level of this code is the synchronized synchronized block of code, which is less efficient. In older Java versions, Hashtable and Vector containers were thread-safe, and if viewed from source, the key methods in both collections were synchronized, and concurrency performance was not high. So there's a dedicated concurrency container, and this blog begins by summarizing concurrency containers in Java.
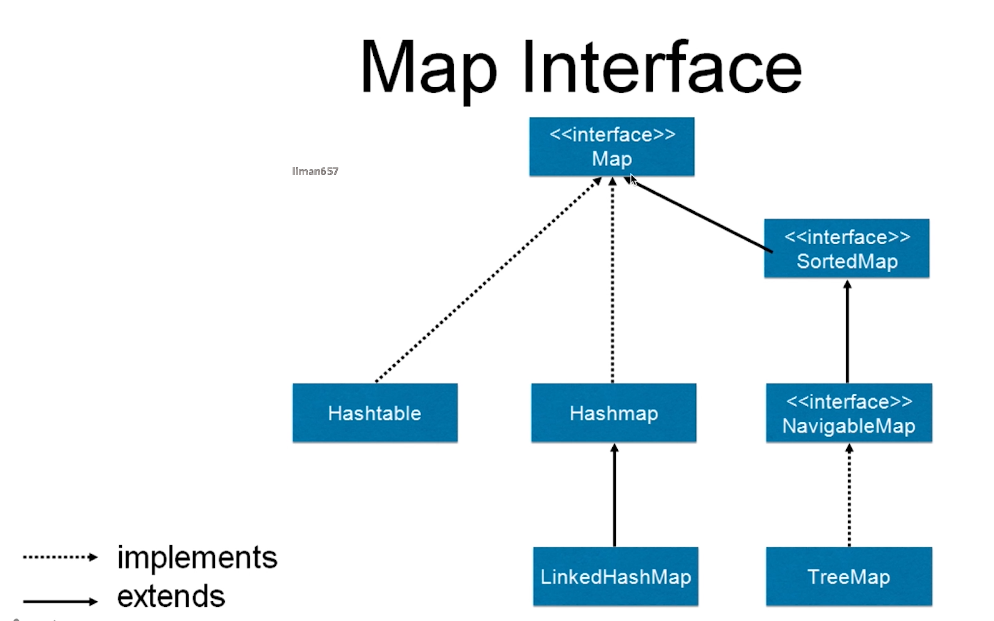
Map interface
Map is the top-level interface of the key,value data structure, and the commonly used HashMap is an implementation class of the Map interface. In addition to the HashMap implementation class, there are several other specific implementation classes, each of which has a different role
| Implementation Class | Effect |
|---|---|
| HashMap | A non-thread-safe K-V container that allows key s and value s to be null |
| Hashtable | K-V collection in older versions of Java, thread-safe, but synchronized based |
| LinkedHashMap | From the name, the order of K-V insertion is recorded using a chain table based on HashMap |
| TreeMap | Implements the Sort interface, which can be sorted by key |
Problems with HashMap
In addition to being thread-safe, HashMap also has an infinite loop when multithreaded extensions occur, which can be a bit disgusting for an interviewer to ask this boring and ineffective question. Let's take a note here. Instead of making a summary, let's give a better summary of this problem. Dead cycle of JAVA HASHMAP.
The root of this problem is to force concurrent HashMap s, which do not support concurrency, into concurrent scenarios, leading to the problem of chain list looping pointing. If you encounter this kind of problem during an interview, you can look down upon the interviewer internally because it's really a bit boring, just like you could have made a bicycle with a round tire, but some people prefer a square tire, and when you're done, ask what square tire you made for is not a practical bicycle.
One thing in all -- HashMap cannot be enforced in concurrent situations. HashMap and Concurrent HashMap differ significantly in JDK versions 1.7 and 1.8, which this blog will summarize briefly
HashMap and Concurrent HashMap in version 1.7
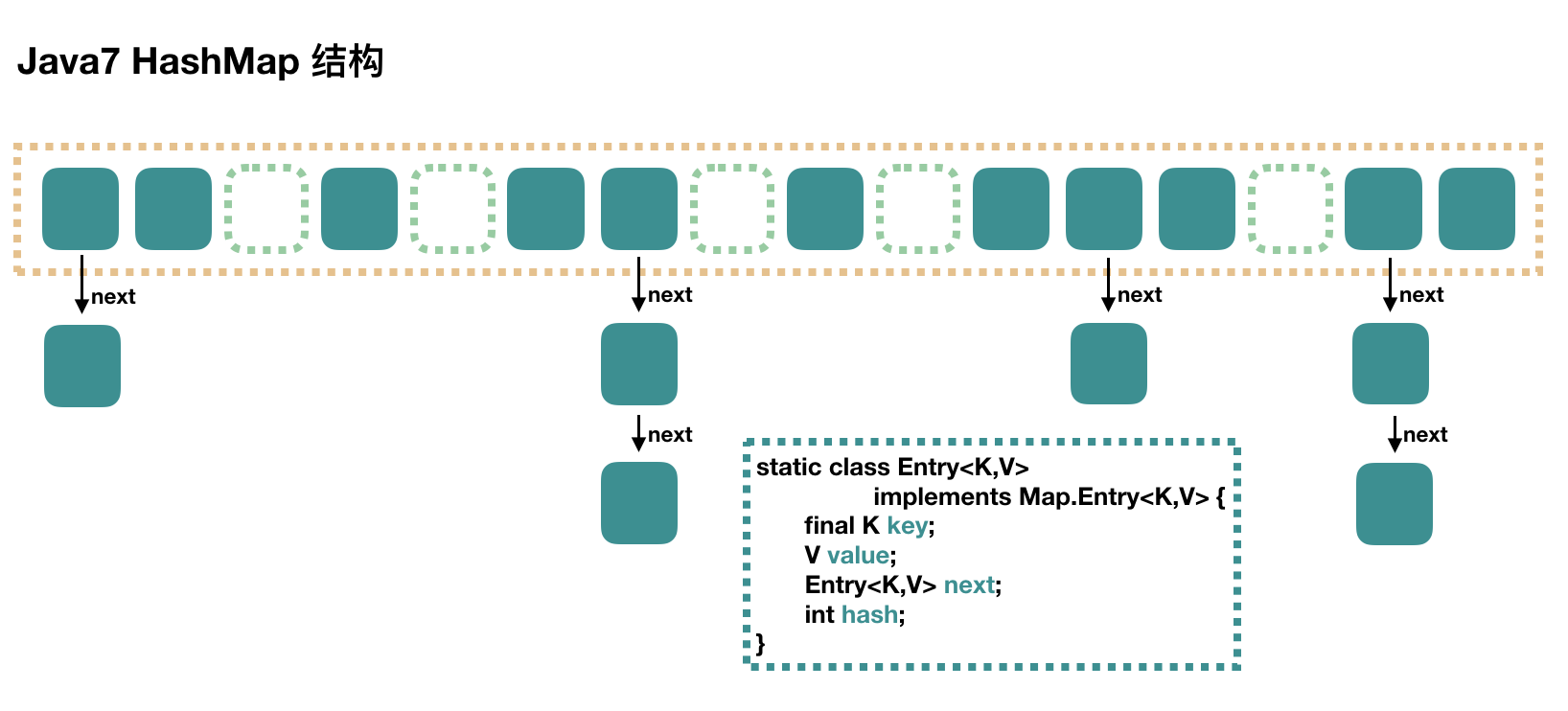
AshMap in 1.7
This is a simpler, Key-denoted array, and then each element in the array is a one-way chain list. If there is a hash conflict, the conflict elements are stored by zipper method.
Concurrent HashMap in 1.7
ConcurrentHashMap in 1.7 is similar to HashMap, but ConcurrentHashMap supports concurrent operations. So it's slightly more complicated. Since ConcurrentHashMap supports segmented locks, an array of slots is introduced. A ConcurrentHashMap in 1.7 is an array of Segments, Segments inherit ReentrantLock, so each time a thread concurrently operates against ConcurrentHashMap in 1.7, it only locks individual Segmentation elements, ensuring that each Segment is thread safe ensures that the entire ConcurrentHashMap is thread safe.
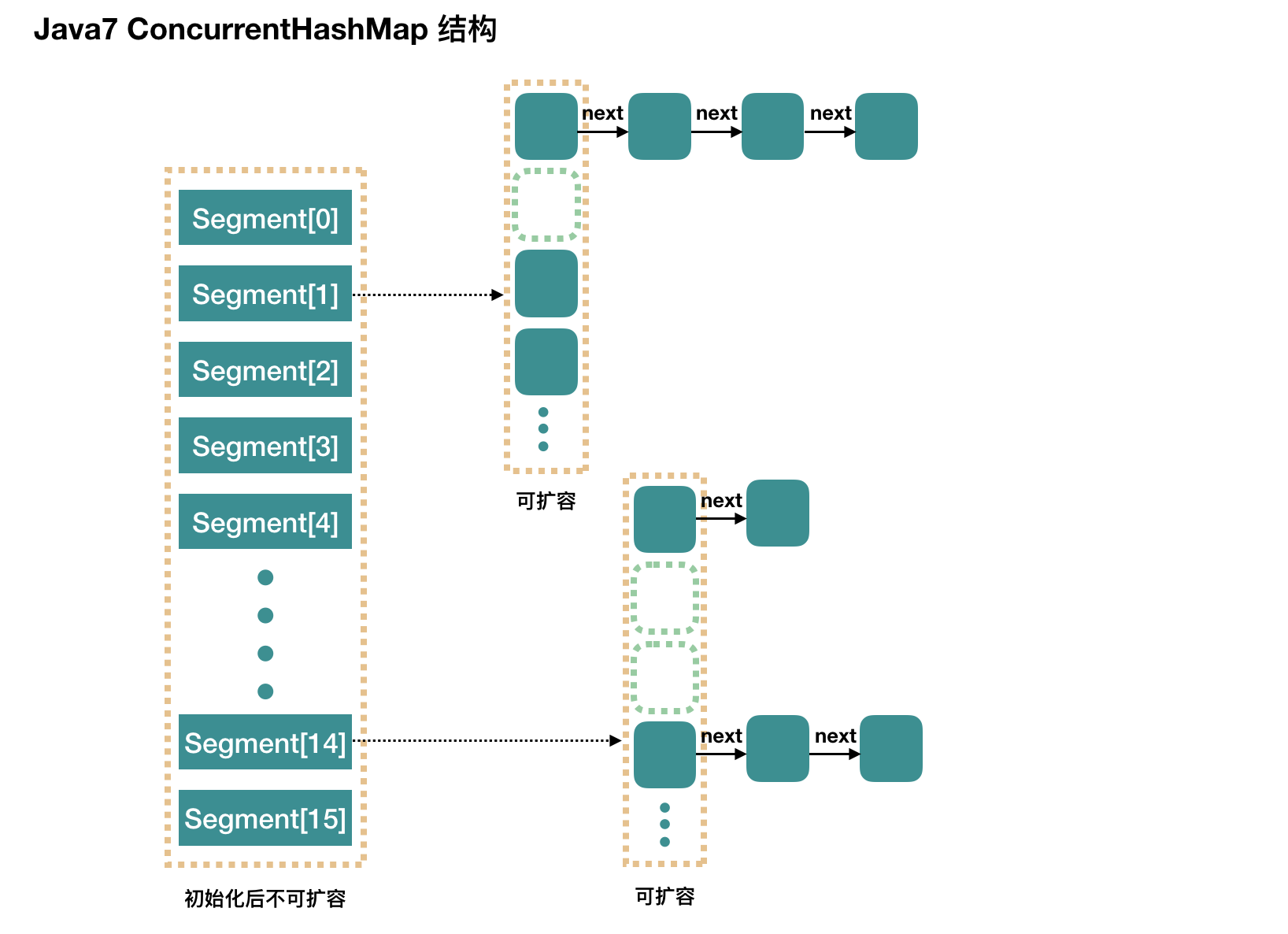
ConcurrentHashMap in 1.7 contains 16 Segments by default. Since 1.7 stores Segments in arrays, you can specify the number of Segments at initialization, but once specified, it cannot be expanded. Inside each Segment is actually a HashMap data structure, but it is thread-safe.
HashMap and Concurrent HashMap in Version 1.8
HashMap structure in 1.8
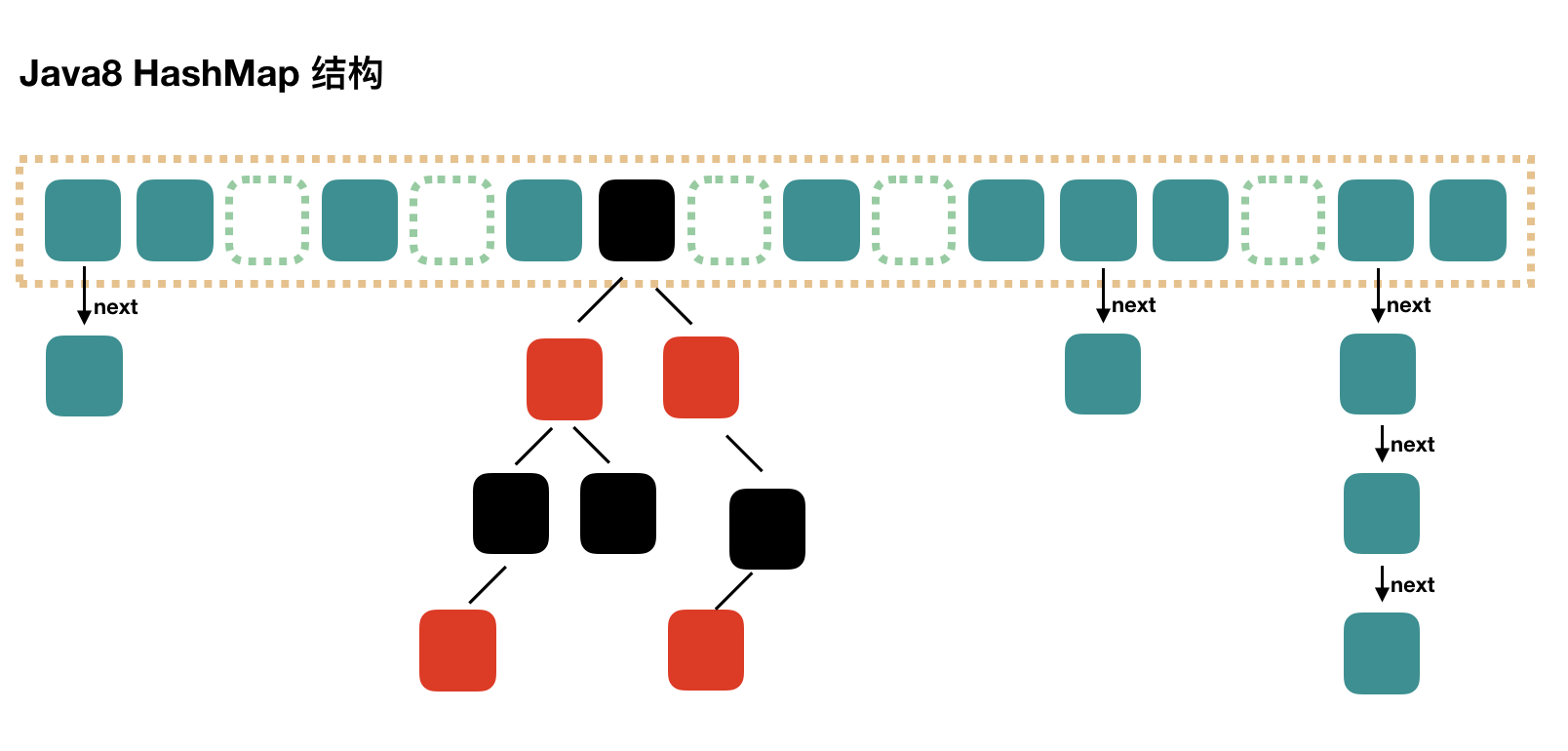
HashMap in 1.8 made some changes, the biggest difference being the use of red and black trees when the chain list for resolving hash conflicts was too long. After positioning the subscript according to the hash value in 1.7, a chain-walking search is required to find the target element, and the complexity of this search is O(n). To reduce this complexity, in Java8, if there are eight elements in hash conflict, the chain table is converted to a red-black tree, so the time complexity of the lookup becomes O(logN)
About red and black trees-- Red and Black Tree Details . (Personally, the red-black tree algorithm is not very portable, just simple to understand)
ConcurrentHashMap in 1.8
Major changes have been made to 1.7 ConcurrentHashMap in 1.8. The structure of ConcurrentHashMap is as follows
[External chain picture transfer failed, source station may have anti-theft chain mechanism, it is recommended to save the picture and upload it directly (img-adjPh7g2-16374853960) (F:blog_docblogPicsync&JUC-learn4.png)]
HashMap in 1.8 does not seem to be different, but it is much more complex in source code to keep threads safe.
Related Sources
putVal
final V putVal(K key, V value, boolean onlyIfAbsent) {
//The case where both key and value are null is no longer supported
if (key == null || value == null) throw new NullPointerException();
//Calculate hash value
int hash = spread(key.hashCode());
int binCount = 0;
//Traverse each slot
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
//Initialize slot with empty slot
if (tab == null || (n = tab.length) == 0)
tab = initTable();
//If the slot location found for the corresponding hash is empty, the data is directly put in, and the CAS is put in
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
//If slot really moves or expands
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);//Help expand capacity
else {//If slot is not empty and ConcurrentHashMap is not expanding
V oldVal = null;
synchronized (f) {//Gets the monitor lock for the header node of the array at that location
if (tabAt(tab, i) == f) {//Is to judge again
if (fh >= 0) {//The hash value of the header node is greater than 0, indicating that it is a chain table
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
// If an "equal" key is found, determine if a value override is required, and then break is possible
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {//If it's a red-black tree
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
//Determine if you need to convert to a red-black tree, where TREEIFY_THRESHOLD=8, which is the threshold for converting to a red-black tree. More than 8 trees will be converted to a red-black tree
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
get
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
//Calculate hash value
int h = spread(key.hashCode());
//Slot array must not be empty and must be greater than 0
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
if ((eh = e.hash) == h) {//If it is the first node, the data for the first node is returned directly
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
else if (eh < 0)//If the hash value is a negative number, then it is a red-black tree and the nodes need to be found from the red-black tree.
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {//If it is a chain list, follow the chain to find
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
Contrast between 1.7 and 1.8
HashMap and Concurrent HashMap in 1.7 and 1.8 are just a simple comparison without further introduction. As for scaling up and migrating data, the final summary document at the end of these references (I don't think it's really necessary to know that level).
In data structure, 1.8 for hash conflict data, after reaching a certain threshold, introduces the structure of red and black trees for storage, in ConcurrentHashMap, the node array can actually be expanded
In terms of ensuring concurrency, 1.7 uses segmented locks, where Segment s inherit from ReentrantLock, while in 1.8 thread-safe operations are implemented through CAS+synchronized.
The time complexity of the query is O(n) in 1.7 and O(logN) in 1.8
Why do I need to convert more than eight conflict chain lists into red-black trees in 1.8? Are conversion operations less performance intensive? This is also mentioned in the source comment
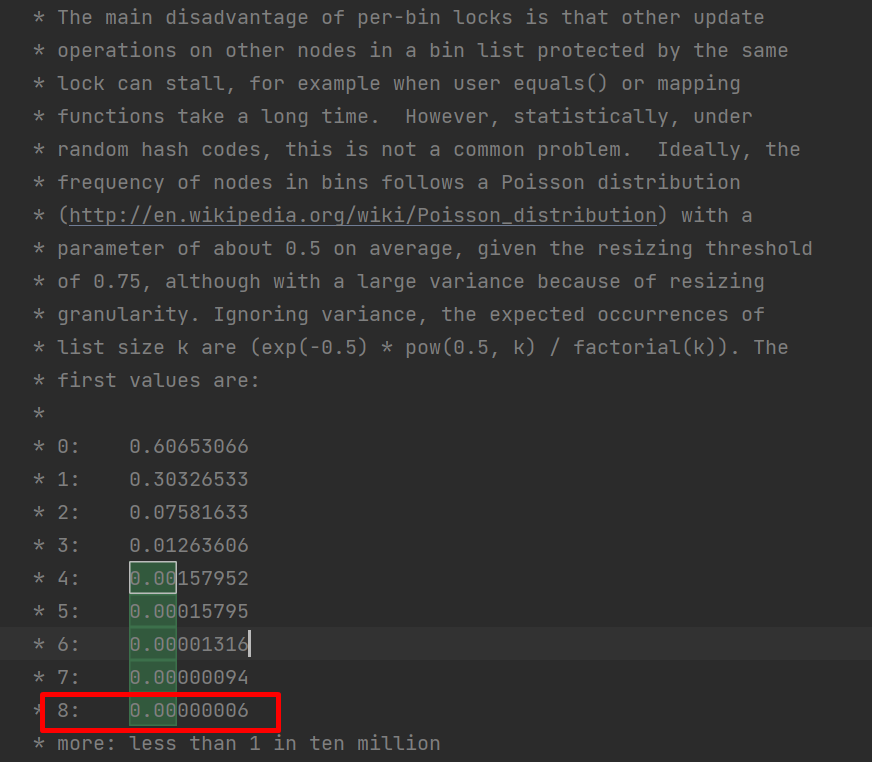 In HashMap, the probability of the number of node conflict elements exceeding eight is very low. In other words, the probability of converting a chain list to a red-black tree in 1.8 is extremely low. This will not affect the efficiency, but will also improve the efficiency of subsequent searches. Why not?
In HashMap, the probability of the number of node conflict elements exceeding eight is very low. In other words, the probability of converting a chain list to a red-black tree in 1.8 is extremely low. This will not affect the efficiency, but will also improve the efficiency of subsequent searches. Why not?
A simple example
/**
* autor:liman
* createtime:2021/11/21
* comment:Simple ConcurrentHashMap usage example
*/
@Slf4j
public class ConcurrentHashMapOptionsNotSafeDemo implements Runnable{
private static ConcurrentHashMap<String ,Integer> scores = new ConcurrentHashMap<>();
public static void main(String[] args) throws InterruptedException {
scores.put("codeman",100);
Thread threadOne = new Thread(new ConcurrentHashMapOptionsNotSafeDemo());
Thread threadTwo = new Thread(new ConcurrentHashMapOptionsNotSafeDemo());
threadOne.start();
threadTwo.start();
threadOne.join();
threadTwo.join();
System.out.println(scores.get("codeman"));
}
@Override
public void run() {
for(int i=0;i<1000;i++){
Integer score = scores.get("codeman");
int newScore = score+1;
scores.put("codeman",newScore);
}
}
}
The above code runs in a multi-threaded environment and is still not thread-safe because ConcurrentHashMap is used in its threads, but the operation to modify the value is not an atomic operation, so it is still not thread-safe, and this error is common in actual development. The normal operation should be changed to the following code
@Override
public void run() {
for(int i=0;i<1000;i++){
while(true) {
Integer score = scores.get("codeman");
int newScore = score + 1;
//replace successfully returns true, which allows you to decide whether to exit the modified operation or not.
boolean putsuccess = scores.replace("codeman", score, newScore);
if(putsuccess){//Exit after successful modification
break;
}
}
}
}
summary
Recommend Daniel's summary of HashMap and Concurrent HashMap. Most of the content in this article refers to this blog, even some pictures, which comes from this article. I don't think there is any better summary on the Internet than this blog has written. Full Resolution of HashMap and Concurrent HashMap in Java 7/8.