Background
In order to get novel coronavirus epidemic data in time, the project team needs to construct a crawler running batch crawl data. You may be familiar with crawlers. Common crawler technologies include requests + LXM + beautiful soup in Python, or the crawler framework of python, such as the scratch framework. Generally speaking, it's easy to start with Python crawler, with rich examples. You can almost get it easily for general websites, apps, wechat applets, etc( python crawling wechat applet (actual combat),Python crawling wechat applet (Charles) ) But the only trouble is that there may be no corresponding server or Python environment in the corresponding production environment. Generally, Java applications are distributed and deployed on Linux servers. Linux will bring its own version of Python 2 environment, which is not very friendly to today's Python 3. Therefore, this paper uses Java to complete a simple crawler task and introduces a java written one Crawler frame webmagic. The process seems to be simple, but in fact, the road is rugged, and there is a big hole in webmagic.
2, Simple logic
The data to be crawled this time is as follows: https://ad.thsi.cn/2020/yiqing2020/index.html
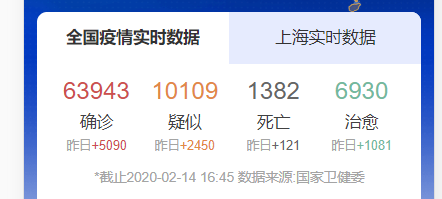
It includes nine data: the number of confirmed cases and their increase, the number of suspected cases and their increase, the number of deaths and their increase, the number of cured cases and their increase, and the deadline. Open the webpage F12 and find that the data structure is actually relatively simple, but after viewing the source code of the webpage, it is found as follows:

It shows that the data is rendered after delayed loading in js. At this time, a famous web application testing tool selenium is needed, which is very useful for automatic testing, automatic login of crawlers and dynamic analysis of web pages.
Here, we choose to use chrome driver to load the web page, wait for 1 second for the rendering to finish, and then parse the label to get the data. The code of the main crawler function is relatively simple, as follows:
@Override
public void dataCrawler() {
// Set chrome options
ChromeOptions options = new ChromeOptions();
options.addArguments("--headless");
// Build selenium driver
WebDriver driver = new ChromeDriver(options);
// Destination address
driver.get("https://ad.thsi.cn/2020/yiqing2020/index.html");
try {
// Delay loading to ensure normal loading of JS data
Thread.sleep(1000);
// Parsing tag
WebElement webElement = driver.findElement(By.id("easter_egg"));
String str = webElement.getAttribute("outerHTML");
Html html = new Html(str);
// Confirmed number
String confirmNum = html.xpath("//*[@class='icon-item confirm']/div[1]/text()").get();
// New number of confirmed cases compared with yesterday
String confirmAddNum = html.xpath("//*[@class='icon-item confirm']/div[3]/span/text()").get();
// Suspected number
String unconfirmNum = html.xpath("//*[@class='icon-item unconfirm']/div[1]/text()").get();
// The number of people suspected to have increased from yesterday
String unconfirmAddNum = html.xpath("//*[@class='icon-item unconfirm']/div[3]/span/text()").get();
// death toll
String deadNum = html.xpath("//*[@class='icon-item dead']/div[1]/text()").get();
// More deaths than yesterday
String deadAddNum = html.xpath("//*[@class='icon-item dead']/div[3]/span/text()").get();
// Cure number
String cureNum = html.xpath("//*[@class='icon-item cure']/div[1]/text()").get();
// The number of people cured is higher than that of yesterday
String cureAddNum = html.xpath("//*[@class='icon-item cure']/div[3]/span/text()").get();
// Update time
String updateTime = html.xpath("//*[@class='data-from']/text()").get();
// Determine whether the parsing data is empty. If it is empty, the data in redis will not be updated
if (StringUtils.isEmpty(confirmNum) || StringUtils.isEmpty(confirmAddNum) || StringUtils.isEmpty(unconfirmNum) ||
StringUtils.isEmpty(unconfirmAddNum) || StringUtils.isEmpty(deadNum) || StringUtils.isEmpty(deadAddNum) ||
StringUtils.isEmpty(cureNum) || StringUtils.isEmpty(cureAddNum) || StringUtils.isEmpty(updateTime)) {
_logger.error("Data parsing exception! There is a null value!");
} else {
Map<String, Object> map = new HashMap<>();
map.put("confirmNum", confirmNum);
map.put("confirmAddNum", confirmAddNum);
map.put("unconfirmNum", unconfirmNum);
map.put("unconfirmAddNum", unconfirmAddNum);
map.put("deadNum", deadNum);
map.put("deadAddNum", deadAddNum);
map.put("cureNum", cureNum);
map.put("cureAddNum", cureAddNum);
map.put("updateTime", updateTime);
JSONObject jsonObject = new JSONObject(map);
//
saveDataToCommonServiceRedis(jsonObject.toString());
}
} catch (Exception e) {
_logger.error("Epidemic data crawler run batch task, data analysis abnormal! Exception information:", e);
} finally {
//
driver.close();
}
}
As it is a maven project, the packages loaded in the pom file are as follows:
<dependency> <groupId>org.seleniumhq.selenium</groupId> <artifactId>selenium-api</artifactId> <version>3.14.0</version> </dependency> <dependency> <groupId>org.seleniumhq.selenium</groupId> <artifactId>selenium-chrome-driver</artifactId> <version>3.14.0</version> </dependency> <dependency> <groupId>org.seleniumhq.selenium</groupId> <artifactId>selenium-api</artifactId> <version>3.14.0</version> </dependency> <!-- webmagic --> <dependency> <groupId>us.codecraft</groupId> <artifactId>webmagic-core</artifactId> <version>0.7.3</version> </dependency>
The algorithm of crawling is also well understood. First, set the configuration of chrome options and Chrome browser. Here it is set to not open the browser access page (options.addArguments("--headless")). Second, set up the selenium driver to access the target web address. Then use the delayed loading to make the front-line program sleep for 1 second, so as to ensure that the js data can be parsed normally after the normal loading. I think it's better to delay the loading of static web pages or dynamic loaded data to ensure that some text and pictures loaded by js can get the tag structure normally. After getting the data, get the tag string of this part, turn it into HTML, and then use xpath to parse it.
Throughout the whole process, it is not complicated, the idea is very clear, and the implementation method is very similar to that of Python. The above is the basic and simple implementation of Java crawler, but at the beginning of doing it, it took a lot of detours. The reason is that how to combine the Java crawler framework webmagic with the existing spring projects?
3, Integration with existing framework
The structure of Webmagic crawler framework itself is not very complex, as shown in the figure below, which is divided into four parts.
Downloader: responsible for requesting the url to obtain the accessed data (html page, json, etc.)
PageProcessor: parse the data obtained by Downloader
Pipeline: the data parsed by PageProcessor is saved by pipeline, or called persistence
Scheduler: the scheduler is usually responsible for url de duplication or saving the url queue. The url parsed by PageProcessor can be added to the scheduler queue for the next crawling.
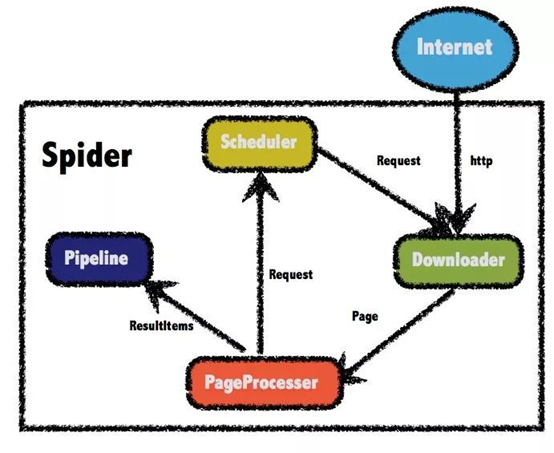
The Webmagic framework is very similar to the scrape framework, and the functions of the components are almost the same. When using, as long as the PageProcessor interface is implemented, the crawler task can be started.
If you add a pipeline when creating a spider crawler instance, that is:
Spider.create(new EpidemicDataCrawlerController())
.addUrl("https://ncov.dxy.cn/ncovh5/view/pneumonia")
.thread(1)
.addPipeline(new EpidemicDataPipeLineController())
.run();In the rewritten process(Page page) method, you can use the
page.putField("data", data);Method to transfer data to the specified pipeline, and the specified pipeline is received as follows:
page.getResultItems().get("data")It seems normal here, but there are some "weird" problems when it is combined with the spring framework. For example, when an instance is injected by annotation, the instance object exists when it is initialized, but when it comes to the process() method or pipeline, the instance object cannot be obtained, as shown below:
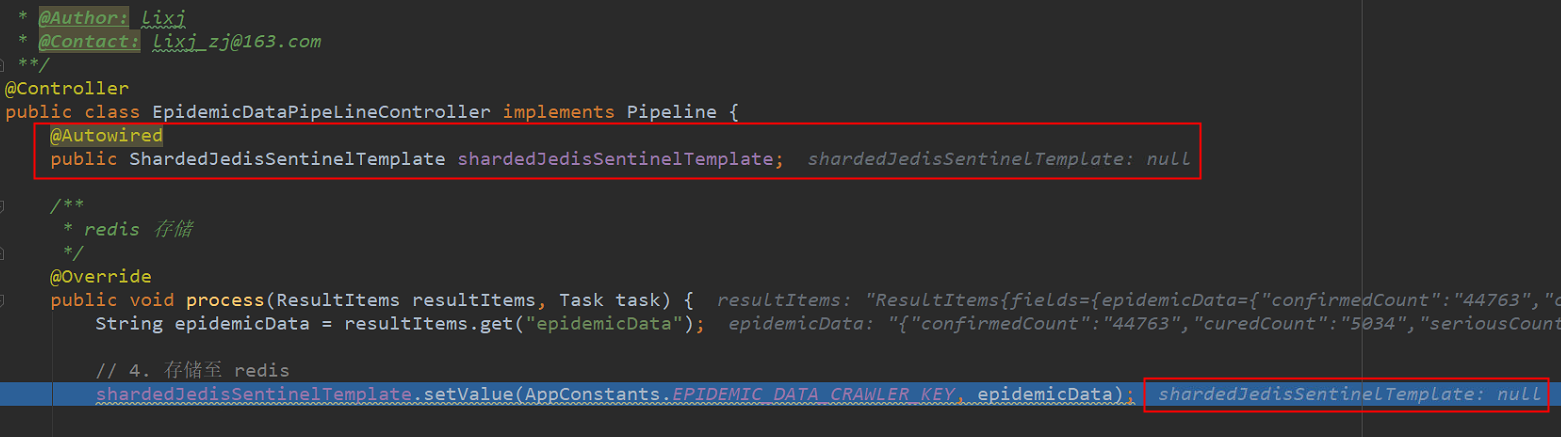
The data has been parsed in the process. In theory, the bean object that has been injected during the system initialization can be used to call its methods to persist the data. But at this time, you can see that the redis instance is null, and you can see that there is an instance object when you start by debugging one step. The reason is that in the spring framework, the existing instance object has been injected into the system after initialization, but when it is called in the webmagic framework, it can not find the specific implementation of the object. Object is null and a null pointer exception is reported.
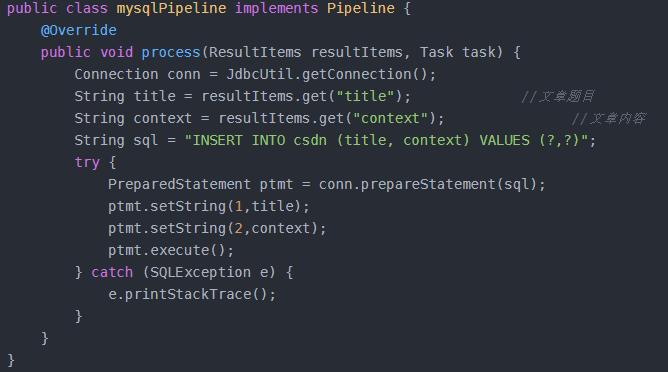
In addition to bean objects, the custom Dao is also null when it is used. After looking at the examples on the official website, it is found that in several pipelines provided by webmagic, they are all printed to the console, persisted to file saving, etc. the only jobhunter project that saves the results to MySQL cannot be reproduced in the integration of existing projects. The implementation method of someone on the Internet is as follows:, It stores data to MySQL by directly connecting database tool class, but the method of calling bean object by annotation fails to realize data persistence. Therefore, I finally gave up the combination of webmagic framework and the existing system, only used an HTML parsing class in the webmagic library to complete the first part of the crawler code.
4, Summary and reflection
Webmagic framework itself is a simple and easy-to-use crawler framework. Most of the basic requirements and tasks can be completed. However, in combination with the existing system of the company, it is necessary to try compatibility, and constantly find out the final cause of the problem through single step debugging, so as to better use new skills.
5, Reference link
http://webmagic.io/docs/zh/posts/ch6-custom-componenet/pipeline.html
https://blog.csdn.net/qq_41061437/article/details/85287803

