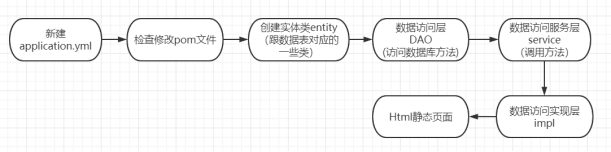
1, Task:
The purpose is to extract various commodity information in the network by using java crawler, establish a unified data model to store data, and describe the basic attributes of commodities through the data model. Such as spu, sku, product description, price and other information. At the same time, it is necessary to eliminate unnecessary information and achieve accurate analysis. Provide the commodity display page according to the obtained information, and obtain the commodity data information through search. Grab commodity data, establish a unified data model, model scalability, commodity data display.
Purpose: the project is conducive to a simple understanding of the crawler process of java, spring boot, simple project debugging, calling, mapping mode, database connection, and help understand the front and back-end interaction principle of spring boot.
2, Class and data design
2.1 development environment of the project
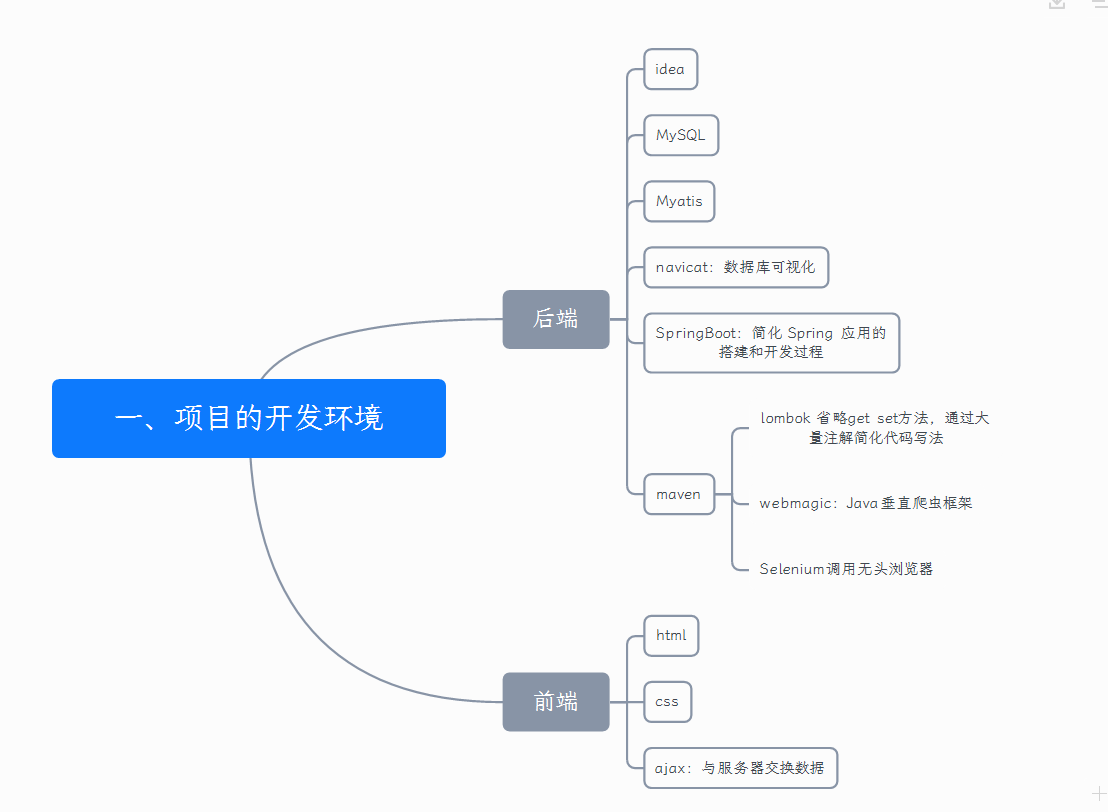
2.2 system function structure design
The program uses the crawler function to crawl data, establish a data model, and use MySQL to store data. Query and call the database content, the extensibility of the model, and provide web page display through html/css.
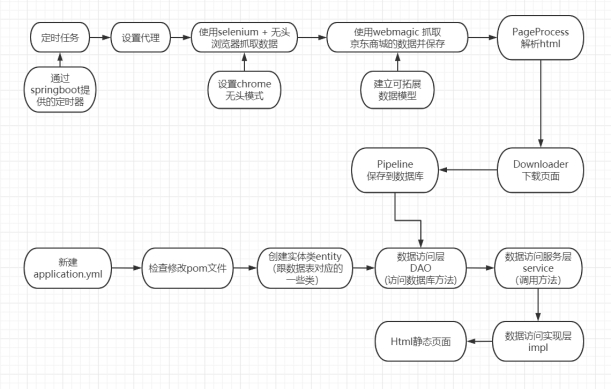
2.2.1 data crawling and data model establishment
WebMagic:
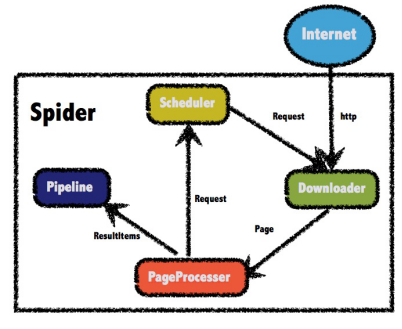
The structure of WebMagic is divided into four components: Downloader, PageProcessor, Scheduler and Pipeline, which are organized by Spider.
1) Downloader: responsible for downloading pages from the Internet for subsequent processing. WebMagic uses Apache HttpClient as the download tool by default.
2) PageProcessor: responsible for parsing pages, extracting useful information, and discovering new links. WebMagic uses Jsoup as an HTML parsing tool and develops a tool Xsoup for parsing XPath based on it. In these four components, the PageProcessor is different for each page of each site, which needs to be customized by users.
3) Scheduler: responsible for managing URLs to be fetched and some de duplication work. WebMagic provides the memory queue of JDK to manage URLs by default, and uses collections to remove duplicates. Redis can also be used for distributed management. Unless the project has some special distributed requirements, you don't need to customize the scheduler yourself.
4) Pipeline: responsible for the processing of extraction results, including calculation, persistence to files, databases, etc. WebMagic provides two result processing schemes of "output to console" and "save to file" by default. Pipeline defines how to save the results. If you want to save to the specified database, you need to write the corresponding pipeline. For a class of requirements, you generally only need to write a pipeline.
Selenium:
Selenium is an automatic testing tool for the Web. According to our instructions, we can use code to control the browser, let the browser automatically load the page, obtain the required data, even screen shots, or judge whether some actions on the website occur, and support mainstream browsers
The program uses Downloader, PageProcessor, Pipeline and Spider components to crawl and establish data model. Automatic operation of Google headless browser through selenium.
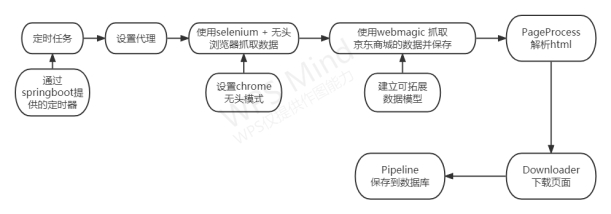
1. Scheduled task
Use the timer in the springboot project. Create a common class in the project and add the annotation @ Component,
The annotation is added on the @ enabled Scheduled class of the project, and the execution time is marked on the boot of the project by using the @ enabled method.
2. Set agent
The proxy server is used to initiate the request to prevent the anti crawling policy from blocking the ip
Proxy server process:
Crawler server - > proxy server - > target server
Target server - > proxy server - > crawler server - > parse data
Free agents available:
Free private agent - MIPO agent
http://www.xiladaili.com/gaoni/
3. Capture data using selenium + headless browser
Add selenium dependency through Maven. Selenium is a front-end testing framework that uses code to control the browser through selenium.
Headless browser: browser without interface, parsing js. Get some data that cannot be found by default. It is used for various test scenarios and can be used for frequent repeated operations and repeated tests on any given page.
4. Use the browser to render, grab the data of Jingdong Mall and save it
1) PageProcess parsing html
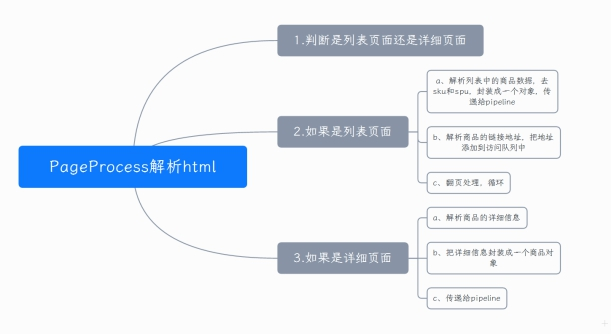
1. Determine whether it is a list page or a detailed page
2. If it is a list page
a. analyze the commodity data in the list, remove sku and spu, package it into an object and pass it to pipeline
b. resolve the link address of the commodity and add the address to the access queue
c. page turning and fixed url setting: Enterprise Cybersecurity Solutions, Services & Training | Proofpoint US Add an attachment: the url of the current request
3. If it is a detailed page
a. analyze the details of goods
b. encapsulate the detailed information into a commodity object
c. transfer to pipeline
2) Downloader download page
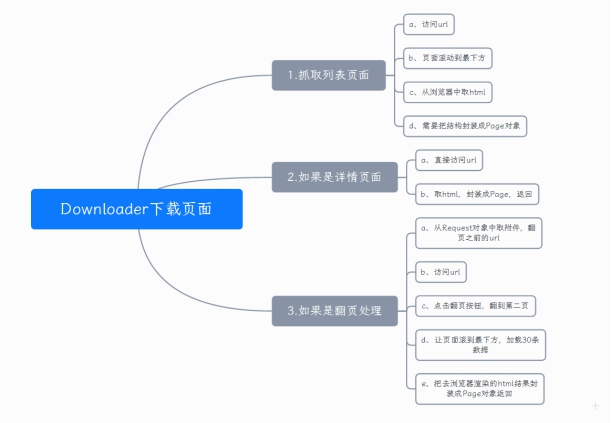
1. Grab list page
a. access url
b. scroll the page to the bottom
c. get html from the browser
d. the structure needs to be encapsulated into a Page object
2. If details page
a. directly access the url
b. take html, package it into Page, and return
3. In case of page turning
a. take the attachment from the Request object and the url before turning the page
b. access url
c. click the page turning button to turn to the second page
d. scroll the page to the bottom and load 30 pieces of data
e. encapsulate the html result rendered by the browser and return it as a Page object
3) Save Pipeline to database
Create database tables and create corresponding attributes
5. Scalability of the model
Based on the control inversion of springboot, there is no strong coupling between classes, which has a good "feature:" high cohesion and low coupling ". The instantiation operation is handed over to the bean factory of Spring and recorded through the xml configuration file. Therefore, the model has strong scalability. Just add the attribute in the Item and add the corresponding browser action.
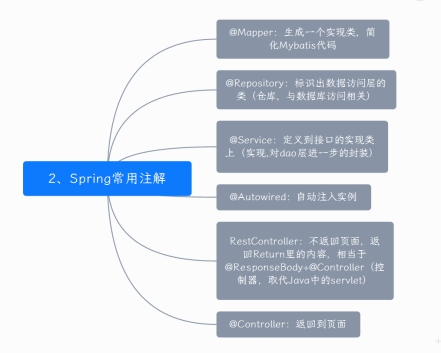
2.2.2 SpringBoot+Ajax+MyBatis query operation database
Development sequence
The back-end SpringBoot+MyBatis and the front-end Ajax+jQuery+CSS+HTML obtain data through crawler operation. According to the data, the back-end interface data is designed and used, and the front-end data request and response fill the interface. The database adopts MySQL 8.0.26 to learn the key technologies and development architecture of front-end and back-end development.
With Spring Boot becoming more and more popular, MyBatis has also developed a set of starter based on Spring Boot mode: MyBatis Spring Boot starter.
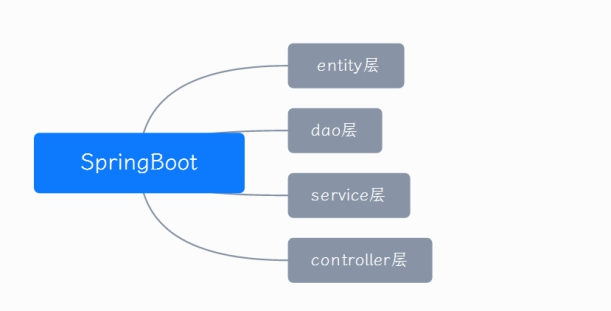
Entity layer: the entity class is stored, the attribute value is consistent with the database value, and the setter and getter methods are implemented.
dao layer: that is, mapper layer, which carries out persistent operation on the database. His method basically uses addition, deletion, modification and query for database operation. As an interface, there is only a method name, which is implemented in mapper XML.
service layer: business layer, which stores business logic processing and does not directly operate the database. It has interfaces and interface implementation classes and provides calling methods of controller layer.
Controller layer: the control layer imports the service layer and calls your service method. The controller performs business operations by accepting the parameters from the front end and returns a specified path or data table.
The reason for choosing AJAX is that based on the large amount of data and many changes of crawler operation, AJAX can provide the technology of updating some web pages without reloading the whole web page. AJAX is a technology for creating fast dynamic web pages. Ajax can make web pages update asynchronously by exchanging a small amount of data with the server in the background. This means that a part of a web page can be updated without reloading the whole web page.
Choose MyBatis because MyBatis can be configured with simple XML or comments, and map primitives, mapping interfaces and POJO s to database records. It eliminates most JDBC code and manual setting of parameters and result retrieval. At the same time, based on the flexible characteristics of MyBatis, it will not impose any impact on the existing design of the application or database. SQL is written in XML, which is completely separated from the program code, reduces the coupling degree, and provides the basis for the scalability of the program.
III. partial codes
3.1 reptile part
@Override
public void process(Page page) {
String level = page.getRequest().getExtra("level").toString();
switch (level){
case "list":
parseList(page);
break;
case "detail":
praseDetail(page);
break;
}
/**
* Analysis details page
*
* @param page
*/
private void praseDetail(Page page) {
Html html = page.getHtml();
String title = html.$("div.master .p-name").xpath("///allText()").get();
String priceStr = html.$("div.summary-price-wrap .p-price span.price").xpath("///allText()").get();
String pic = "https:"+html.$("#spec-img").xpath("///@src").get();
String url = "https:"+html.$("div.master .p-name a").xpath("///@href").get();
String sku = html.$("a.notice.J-notify-sale").xpath("///@data-sku").get();
Item item = new Item();
item.setTitle(title);
item.setPic(pic);
item.setPrice(Float.valueOf(priceStr));
item.setUrl(url);
item.setUpdated(new Date());
item.setSku(StringUtils.isNotBlank(sku)?Long.valueOf(sku) : null);
// Single data entry
page.putField("item", item);
}
/**
* Parse list page
* @param page
*/
private void parseList(Page page) {
Html html = page.getHtml();
// Get sku and spu here and give them to pipeline
List<Selectable> nodes = html.$("ul.gl-warp.clearfix > li").nodes();
List<Item> itemList = new ArrayList<>();
for (Selectable node : nodes) {
// Get sku and spu
String sku = node.$("li").xpath("///@data-sku").get();
String spu = node.$("li").xpath("///@data-spu").get();
String href = "https:" + node.$("div.p-img a").xpath("///@href").get();
Item item = new Item();
item.setSku(Long.valueOf(sku));
item.setSpu(StringUtils.isNotBlank(spu) ? Long.valueOf(spu) : 0);
item.setCreated(new Date());
itemList.add(item);
// You also need to add the link to the details page to the queue
Request request = new Request(href);
request.putExtra("level", "detail");
request.putExtra("pageNum", page.getRequest().getExtra("pageNum"));
request.putExtra("detailUrl", href);
page.addTargetRequest(request);
}
// Stored as a collection
page.putField("itemList", itemList);
// At the same time, I have to do paging
String pageNum = page.getRequest().getExtra("pageNum").toString();
if ("1".equals(pageNum)){
Request request = new Request("https://nextpage.com");
request.putExtra("level", "page"); // Identify de paging
request.putExtra("pageNum", (Integer.valueOf(pageNum) + 1) + "");// The page number should be + 1, and then the second page
// Add to queue
page.addTargetRequest(request);
}3.2 spring boot query operation database
Control Control layer:
@RestController//Returns the data format of the rest service type
@RequestMapping("/Jd")//How is the data interface controller called
public class ItemController {
//Call some methods to get the return value and take the service layer as an object
@Autowired//Automatic injection to generate instances
private ItemService itemService;//Good packaging
@GetMapping("/getJd")//If the path is getJd under Jd, the parameter 'id' passed from the front end will be obtained, and the value of the id will be passed to the findById method
public String getItem(@Param("id")Integer id){
Item item = itemService.findById(id);
return item.getTitle();
}
@GetMapping("/getId") // Get the id through title / /
public Integer getId(@Param("Message") String title){
Item item = itemService.findByTitle(title);
return item.getId();
}
@GetMapping("/getOne") // Get id through title / / and a data record
public Item getAll(@Param("id") Integer id){
Item item = itemService.findById(id);
return item;
}
@GetMapping("/getJson") // Get id through title
public String getJson(@Param("id") Integer id) {
Item item = itemService.findById(id);
Gson gson = new Gson();
return gson.toJson(item);
}
@GetMapping("/getAll") // Get the id through the title and get multiple pieces of data
public List<Item> getAll(){
List<Item> list = itemService.findItemAll();
return list;
}
@GetMapping("/getAllJson") // Get id through title
public String getAllJson(){
List<Item> list = itemService.findItemAll();
Gson gson = new Gson();
return gson.toJson(list);
}
}3.3 front end design
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<link rel="stylesheet" type="text/css"href="https://cdn.bootcss.com/bootstrap/4.0.0-beta.2/css/bootstrap.min.css">
<script type="text/javascript"src="https://cdn.bootcss.com/jquery/1.4.0/jquery.js"></script>
<script>
$(document).ready(function(){
$("#btn1").click(function(){
test1();
});
$("#btn2").click(function(){
$.test2();
});
});
//data is an array
function test1(){
//alert("Text1: " + $("#test").text());
$.ajax({
url:'/msg/getAllJson',//Access the background interface, use get, and return json in the background
type:'get',
dataType:'json',
success:function(data){
$("#tabletest").find('tr').remove();
tr='<td>id</td><td>title</td>'
$("#tabletest").append('<tr>'+tr+'</tr>')
//The parameter data passed in the method is the data obtained in the background
for(i in data) //data refers to the array, and i is the index of the array
{
var tr;
tr='<td>'+data[i].id+'</td>'+'<td>'+data[i].title +'</td>'
$("#tabletest").append('<tr>'+tr+'</tr>')
}
}
});
}
</script>
<style type="text/css">
.center{
margin: auto;
text-align:center;
font-size: 24px;
width: 60%;
background: lightblue;
}
</style>
</head>
<body>
<div class="center">
<p id="test">Springboot integration MyBatis adopt ajax query MySQL Database data</b></p>
<button id="btn1">Show all data</button>
<button id="btn2">query</button>
<input id="id" name="id" type="text" placeholder="Please enter id value"/>
<br>
<table class="table table-bordered" id='tabletest'>
</table>
</div>
</body>
</html>4, Program running, testing and analysis
4.1 program operation

4.2 summary and analysis
- When using java programs, you should pay attention to the jdk version and the corresponding database version of the jdk.
- When using database operation, you should pay attention to the format of url, username and password in the application of database and idea connection.
- Attention should be paid to the relative absolute path of the incoming data file path.
- Learn to gradually understand the process of a project and eliminate errors through debug.
- In the debugging program, we should search for solutions with thinking and eliminate the causes of errors one by one.
- Understanding the role of various annotation API s is helpful to optimize the code.
- For a wide range of technologies, we need to start from the demand and reasonably select appropriate, efficient and expandable technologies.
- Through the program, we can have a deeper understanding of the working mode of the front and rear end and the working principle of springboot.
4.3 improvement scheme
4.3.1 for reptiles:
First, we can speed up the crawler speed through a more efficient framework to achieve more flexible customized crawling. Secondly, through the optimization algorithm, we can summarize some records of crawling failure or data acquisition failure, feed back the successful and complete data on the page, and filter the links irrelevant to the subject through the web page analysis algorithm.
Interaction is a problem that needs to be solved. Crawling the page involves user information input and verification code processing. With the emergence of various verification codes, it will be difficult for crawlers to deal with this situation.
javascript parsing problem. At present, most web pages belong to dynamic web pages. Most useful data in web pages are dynamically obtained through ajax/fetch, and then filled into web pages by js. There is little useful data in simple html static pages. Let the background script do javascript operation will be very troublesome. It not only needs to clearly understand the logic of the original web page code, but also makes the code look very bloated.
ip parsing problem. Although proxy ip is used in this program, it is still the most fatal problem that crawlers will encounter. The website firewall will limit the number of requests of an ip within a certain period of time. If it exceeds the upper limit, the request will be rejected. When crawling in the background, the machine and ip are limited, so it is easy to get online and cause the request to be rejected. At present, the main solution is to use agents, which will increase the number of ip, but the agent ip is still limited.