This is the third in the Java Crawler series, in the last one What should Java crawlers do when they encounter websites that need to be logged in? In this article, we will talk about the problem of asynchronous loading of data when crawling, which is also a common problem in crawling.
Now many of them are front-end and back-end separation projects, which will make the problem of asynchronous data loading more prominent, so you should not be surprised when you encounter such problems when crawling, do not panic. Generally speaking, there are two solutions to such problems:
1. Built-in a browser kernel
The built-in browser is to start a browser kernel in the crawler program so that we can get the pages rendered by js, so that we can collect the same static pages. There are three kinds of tools commonly used:
- Selenium
- HtmlUnit
- PhantomJs
These tools can help us solve the problem of data asynchronous loading, but they all have shortcomings, that is, inefficiency and instability.
2. Reverse Analytical Method
What is the reverse analytic method? The data of our js rendering page is acquired from the back end by Ajax. We only need to find the corresponding Ajax request connection on OK, so we can get the data we need. The advantage of reverse parsing is that the data obtained by this way are all in json format, which is more convenient to parse. Another advantage is that the interface is relative to the page. The probability of change is smaller. It also has two drawbacks. One is that you need to be patient and skillful in Ajax, because you need to find what you want in a big push, and the other is that you have no way to do anything about JavaScript rendered pages.
Above are two solutions for asynchronous data loading. In order to deepen your understanding and how to use them in the project, I take the collection of Netease news as an example, Netease news address: https://news.163.com/. Use two ways of appeal to get the news list of Netease's important news. The main news of Netease is as follows:

Built-in browser Selenium mode
Selenium is a simulation browser, automated testing tool, which provides a set of API s that can interact with the real browser kernel. There are many applications in automated testing, and it is often used to solve asynchronous loading when crawling. There are two things we need to do to use Selenium in our project:
- 1. Introduce Selenium dependency packages and add them to pom.xml
<!-- https://mvnrepository.com/artifact/org.seleniumhq.selenium/selenium-java -->
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>3.141.59</version>
</dependency>- 2. Download the corresponding driver, such as the chrome driver I downloaded. The download address is https://npm.taobao.org/mirrors/chrome driver/. After downloading, you need to write the location of the driver into Java environment variables, such as I put it directly under the project, so my code is:
System.getProperties().setProperty("webdriver.chrome.driver", "chromedriver.exe");After completing the above two steps, we can compile and use Selenium to collect the news of NetEase. The code is as follows:
/**
* selenium Solving the problem of data asynchronous loading
* https://npm.taobao.org/mirrors/chromedriver/
*
* @param url
*/
public void selenium(String url) {
// Setting chromedirver's storage location
System.getProperties().setProperty("webdriver.chrome.driver", "chromedriver.exe");
// Set headless browsers so that browser windows do not pop up
ChromeOptions chromeOptions = new ChromeOptions();
chromeOptions.addArguments("--headless");
WebDriver webDriver = new ChromeDriver(chromeOptions);
webDriver.get(url);
// Get a list of important news
List<WebElement> webElements = webDriver.findElements(By.xpath("//div[@class='news_title']/h3/a"));
for (WebElement webElement : webElements) {
// Extracting news links
String article_url = webElement.getAttribute("href");
// Extraction of news headlines
String title = webElement.getText();
if (article_url.contains("https://news.163.com/")) {
System.out.println("Title:" + title + " ,Links to articles:" + article_url);
}
}
webDriver.close();
}Running this method, the results are as follows:

We used Selenium to extract the list news of Netease's main news correctly.
Reverse Analytical Method
Reverse parsing is to get the link of Ajax asynchronous data acquisition, and get news data directly. Without skills, the process of finding Ajax will be painful, because there are too many links loaded on a page. Look at the network that NetEase has heard about:

There are hundreds of requests. How can I find out which requests get the news data? If you don't mind the trouble, you can go one by one and you can definitely find it. Another quick way is to use the search function of the network. If you don't know the search button, I have circled it in the picture above. We can copy a news headline in the main news randomly, and then retrieve it, then we can get the result, as shown in the following figure:
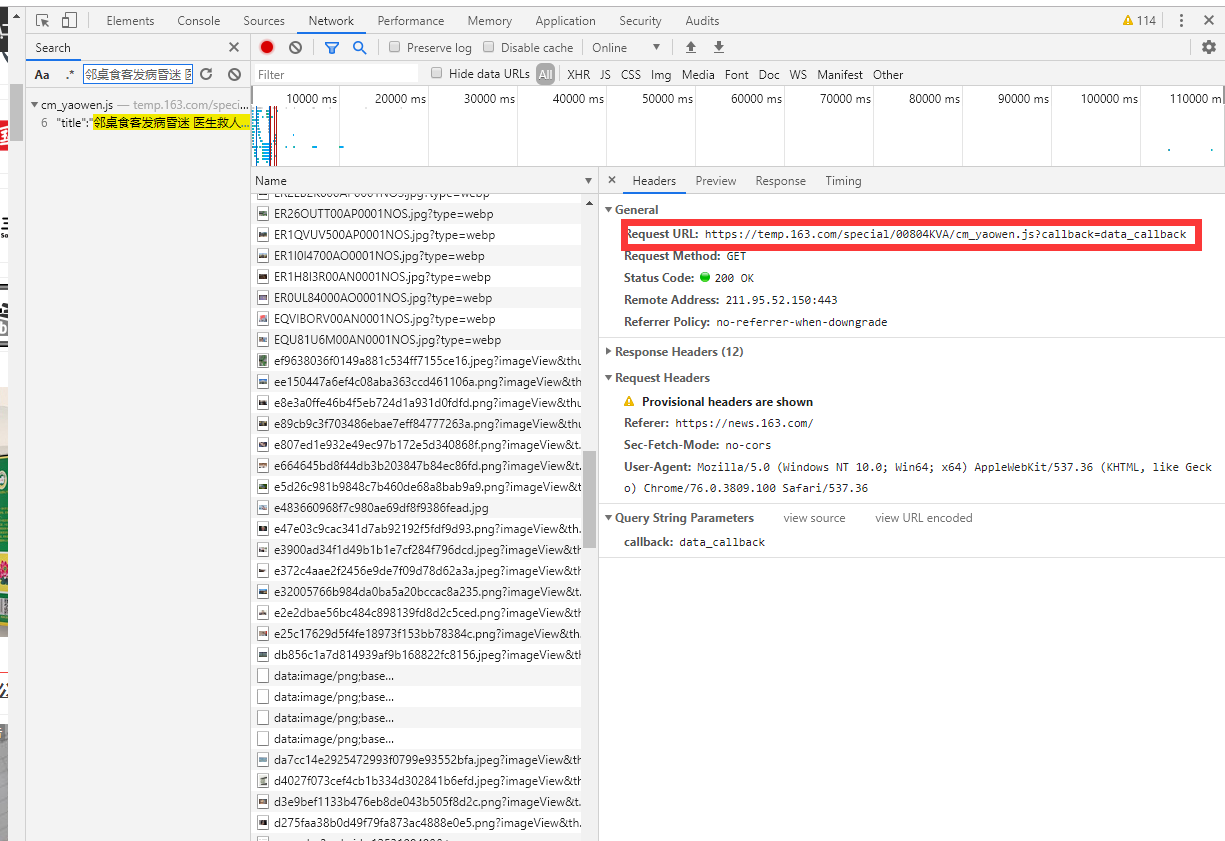
In this way, we can quickly get the request link of the important news data, which is https://temp.163.com/special/00804KVA/cm_yaowen.js?callback=data_callback. Visit the link and see the data returned by the link, as shown in the following figure:

From the data, we can see that all the data we need is here, so we just need to parse this data link. There are two ways to parse news headlines and news links from this data, one is regular expression, the other is to convert the data into json or list. Here I choose the second way, using fastjson to convert the returned data into JSONArray. So we're going to introduce fastjson and fastjson dependencies in pom.xml:
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.59</version>
</dependency>In addition to the introduction of fastjson dependency, we need to process the data simply before transformation, because the current data does not conform to the list format, we need to remove the data "callback (and the last one). Specific reverse analysis to obtain Netease news code as follows:
/**
* Solving the problem of data asynchronous loading by using reverse analytic method
*
* @param url
*/
public void httpclientMethod(String url) throws IOException {
CloseableHttpClient httpclient = HttpClients.createDefault();
HttpGet httpGet = new HttpGet(url);
CloseableHttpResponse response = httpclient.execute(httpGet);
if (response.getStatusLine().getStatusCode() == 200) {
HttpEntity entity = response.getEntity();
String body = EntityUtils.toString(entity, "GBK");
// Replace the front data_callback first(
body = body.replace("data_callback(", "");
// Filter out the last one) right parentheses
body = body.substring(0, body.lastIndexOf(")"));
// Converting body to JSONArray
JSONArray jsonArray = JSON.parseArray(body);
for (int i = 0; i < jsonArray.size(); i++) {
JSONObject data = jsonArray.getJSONObject(i);
System.out.println("Title:" + data.getString("title") + " ,Links to articles:" + data.getString("docurl"));
}
} else {
System.out.println("Handling failure!!! Return status code:" + response.getStatusLine().getStatusCode());
}
}Write the main method and execute the above method. Note that at this time the incoming link is https://temp.163.com/special/00804KVA/cm_yaowen.js?callback=data_callback instead of https://news.163.com/. The following results are obtained: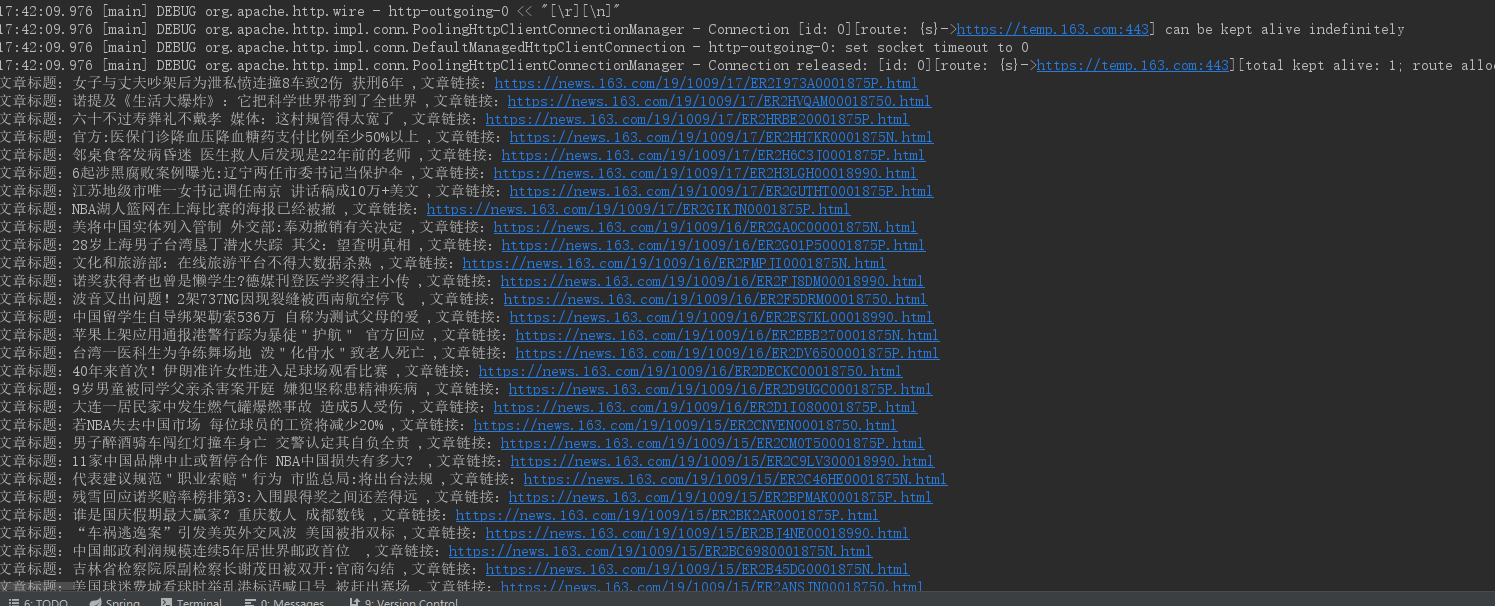
Both methods have succeeded in obtaining the news lists loaded asynchronously by Netease. For the selection of these two methods, my personal preference is to use the reverse parsing method, because its performance and stability are more reliable than the built-in browser core, but for some pages rendered with JavaScript fragments, the built-in browser is more reliable. So choose according to the specific situation.
I hope this article will be helpful to you. The next one is about the problem of crawler IP being blocked. If you are interested in reptiles, you might as well pay attention to a wave, learn from each other and make progress with each other.
Source code: source code
The article's shortcomings, I hope you can give more advice, learn together, and make progress together.
Last
Play a small advertisement. Welcome to pay close attention to the Wechat Public Number: "Hirago's Technological Blog" and make progress together.