Basic implementation of HashMap (before JDK 8)
HashMap usually uses a pointer array (assumed to be table []) to disperse all keys. When a key is added, it will calculate the subscript i of the array through the key through the Hash algorithm, and then insert this into table[i]. If two different keys are counted in the same I, it is called conflict or collision, This will form a linked list on table[i]
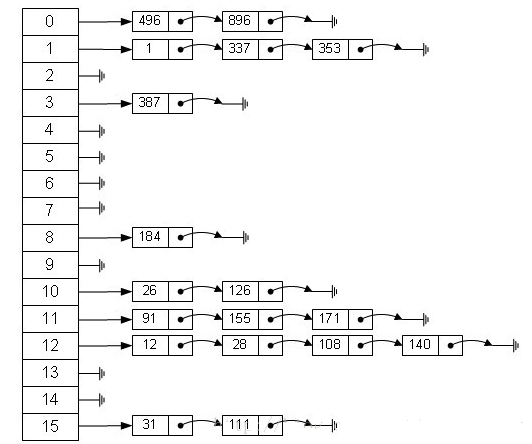
If the size of table [] is very small, for example, there are only two, if you want to put 10 keys into it, the collision is very frequent, so an O(1) search algorithm becomes linked list traversal, and the performance becomes O(n), which is the defect of Hash table
Therefore, the size and capacity of the Hash table are very important. Generally speaking, when the container of the Hash table has data to be inserted, it will check whether the capacity exceeds the set threshold. If it exceeds the threshold, the size of the Hash table needs to be increased, but in this way, the elements in the whole Hash table need to be recalculated. This is called rehash, which costs a lot
HashMap rehash source code
Put a key and value to the Hash table:
public V put(K key, V value) {
......
// Calculate Hash value
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
// If the key has been inserted, replace the old value (link operation)
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
// The key does not exist. You need to add a node
addEntry(hash, key, value, i);
return null;
}
Check whether the capacity exceeds the standard
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
//Check whether the current size exceeds the set threshold. If it exceeds the threshold, resize it
if (size++ >= threshold)
resize(2 * table.length);
}
Create a larger hash table, and then migrate the data from the old hash table to the new hash table
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
......
// Create a new Hash Table
Entry[] newTable = new Entry[newCapacity];
// Migrate data from Old Hash Table to New Hash Table
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
Migrated source code
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
//The following code means:
// Pick an element from the OldTable and put it into the NewTable
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
The mechanism of this method is to convert each linked list to a new linked list, and the position in the linked list is reversed, which is easy to cause a linked list loop in the case of multithreading, resulting in a get() loop. Therefore, as long as it is ensured that the original order is followed when building a new chain, there will be no cycle (improvement of JDK 8)
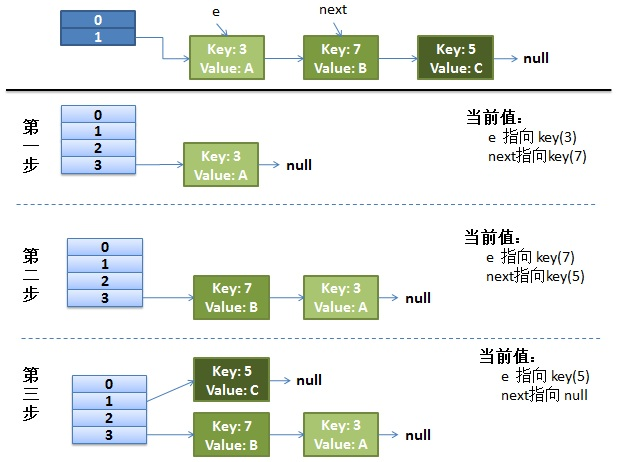
Normal ReHash process
- Suppose our hash algorithm simply uses key mod to check the size of the table (that is, the length of the array)
- The top is the old hash table. The size of the Hash table is 2, so the key is 3, 7 and 5. After mod 2, they all conflict in table[1]
- The next three steps are to resize the Hash table to 4, and then all rehash
Rehash under concurrent
1) Suppose there are two threads
do {
Entry<K,V> next = e.next; // Suppose that the thread is suspended by scheduling as soon as it executes here
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
The execution of thread 2 is completed. So it looks like this
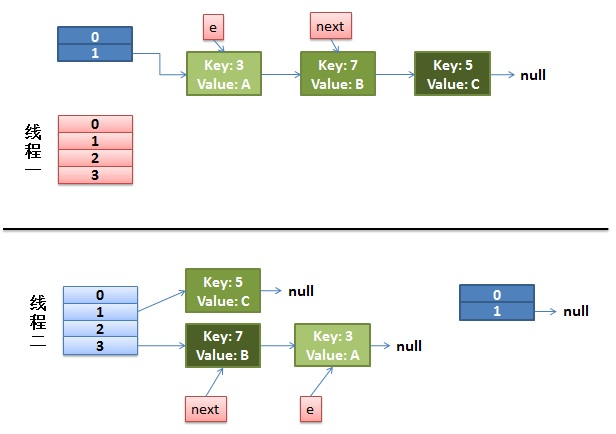
Note that e of Thread1 points to key(3) and next points to key(7). After rehash of thread 2, it points to the list reorganized by thread 2. You can see that the order of the linked list is reversed
2) As soon as the thread is scheduled to execute
- First, execute newTalbe[i] = e;
- Then e = next, resulting in e pointing to key(7)
- next = e.next in the next cycle causes next to point to key(3)
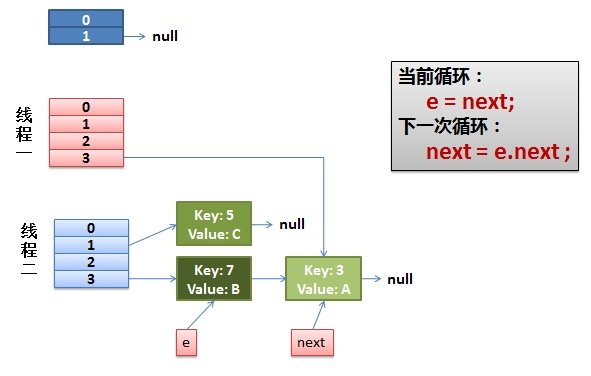
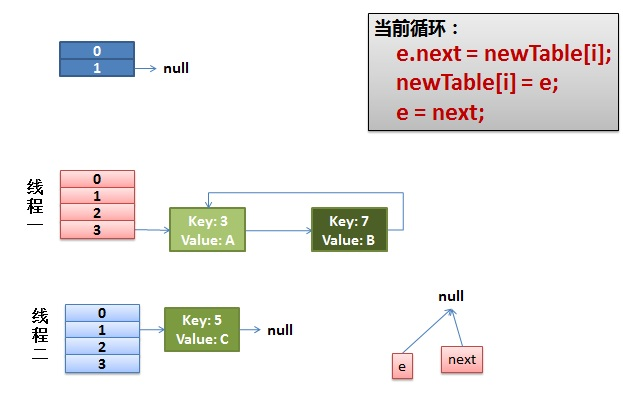
3) The thread continues to work. Take off the key(7), put it in the first one of the newTable[i], and then move e and next down
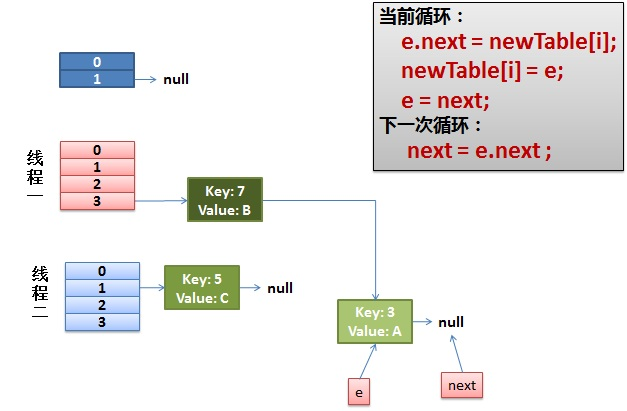
4) The ring link appears
e.next = newTable[i] causes key (3) Next points to key(7)
Key (7) at this time Next has pointed to key(3), and the circular linked list appears
Improvement of JDK 8
JDK 8 adopts the method of bit bucket + linked list / red black tree. When the length of the linked list of a bit bucket exceeds 8, the linked list will be converted into a red black tree
HashMap will not cause an endless loop due to multi-threaded put (JDK 8 uses head and tail to ensure that the order of the linked list is the same as before; JDK 7 rehash will invert the linked list elements), but it will also have disadvantages such as data loss (the problem of concurrency itself). Therefore, it is recommended to use ConcurrentHashMap in case of multithreading
Why are threads unsafe
There are two main problems that may occur when HashMap is concurrent:
-
If multiple threads use the put method to add elements at the same time, and it is assumed that there are two put keys that collide (the same as the bucket calculated according to the hash value), according to the implementation of HashMap, the two keys will be added to the same position in the array, so that the data put by one thread will eventually be overwritten
-
If multiple threads detect that the number of elements exceeds the array size * loadFactor at the same time, multiple threads will expand the Node array at the same time, recalculating the element position and copying the data, but finally only one thread's expanded array will be assigned to the table, that is, the of other threads will be lost, and the put data of their respective threads will also be lost