In the previous article, I have published common interview questions. Here I spent some time sorting out the corresponding answers. Due to my limited personal ability, it may not be in place. If there are unreasonable answers, please give me some advice. Thank you here.
This article mainly describes the collection content that is almost necessary to ask in the java interview. The java collection is an important content in the jdk, and it is also the most commonly used content in our usual development process. Therefore, whether we are preparing for the interview or not, we should master the knowledge related to the collection. Since it is the key point, it means that there will be a lot of questions for collection classes in java interview, especially hashmap. Because of its exquisite design and outstanding detail optimization, hashmap is often the first choice for collection in interview, so I will use a separate article to record hashmap.
Can you give a brief description of the collection?
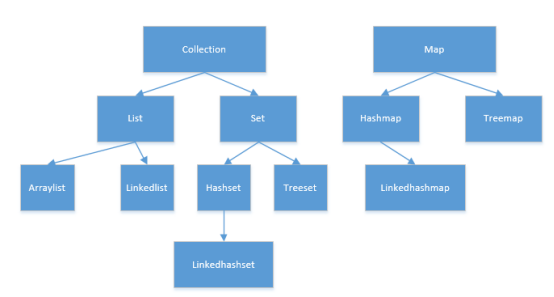
Java collections are divided into two categories: collection and map. Collection is a set of data collection types, which can be understood as a dynamic array. It contains two major classes: list and set. The biggest difference between list and set is whether there can be duplicate elements. List is a group of ordered and repeatable arrays, and set is a group of unordered and non repeatable arrays. Map is stored in key value pairs, which is a form of key value. There are two major implementation classes treemap and hashmap under the map. Specifically, the following figure shows the commonly used set diagrams in set classes. When introducing, we generally introduce the commonly used ones.
What are the differences among ArrayList, linkedlist and vector?
In fact, all three are dynamic arrays under the collection interface. The specific differences are shown in the table below:
|
| ArrayList | Linkedlist | Vector |
| Bottom implementation | array | Linked list | array |
| Thread safety | unsafe | unsafe | security |
| Frequency of use | highest | higher | Not used |
| Capacity expansion | Increase by 0.5x | Linked list, no capacity expansion concept | Doubled |
Vector is a thread safe collection implemented by the early jdk. Its implementation basically adds lock synchronization to the ArrayList method, resulting in performance degradation. Now it has been basically replaced by the concurrent series. The core difference between ArrayList and linkedlist lies in the underlying implementation. ArrayList's array based implementation has a capacity expansion mechanism. At the same time, the array can access 0 (1) randomly. If it is adding elements at the tail, it is also o(1). If an element is added at a certain position in the middle, ArrayList calls the system copy function (System.arraycopy), which will move all the following contents back one bit at a time, so the time complexity is o(1). Of course, deletion is also similar. In this way, addition and deletion basically achieve o(1). The advantage of linkedlist is the deletion and addition of random positions, But when it finds the location, it is linear, so basically linkedlist has no advantage in access and deletion, and capacity expansion may be its only advantage. Without any special circumstances, we generally use ArrayList, and rarely use linkedlist and vector.
What's the difference between hashset and treeset?
In fact, the two bottom layers are the extension of hashmap and treemap, so they are consistent with hashmap and treemap in difference. Hashset takes hash table as the main storage structure, and treeset bottom layer takes red black tree as the main storage structure. Hashset determines the order based on the hashcode value of key and the equals method, while treeset specifies the order through comparable (external comparator) and comparator (internal comparator).
How to safely delete the data of an ArrayList in a loop?
This is a basic operation. The correct deletion method is given directly, as follows:
public static void main(String[] args) throws Exception {
List<String> list = new ArrayList<>();
list.add("1");
list.add("1");
//Use the for loop to delete incomplete, undeleted and undesirable
for (int i =0;i<list.size();i++){//After deletion, the size is 1 and i is also 1, so exit the loop directly
if (list.get(i).equals("1")){
list.remove(i);//After deleting one, the size changes to 1
}
}
//----------------------------------------
List<String> list1 = new ArrayList<>();
list1.add("1");
list1.add("1");
//Before 1.8, the iterator} can be deleted
Iterator<String> iterator = list1.iterator();
while (iterator.hasNext()){
if (iterator.next().equals("1")){
iterator.remove();
}
}
//-------------------------------------------------
List<String> list2 = new ArrayList<>();
list2.add("1");
list2.add("1");
//After version 1.8, it can be deleted by using removeIf
list2.removeIf(s -> s.equals("1"));//The underlying implementation is the iterator
}Jdk1. The iterator was used before 8, and the removeif function was used after 1.8.
Tell me about your understanding of fail fast and fail safe?
Fail fast is a mechanism for java to quickly judge whether there is a multi-threaded operation set. In the process of traversing the collection with iterator, once it is found that the data of the container has been modified, it will throw a concurrentModificationException, resulting in traversal failure. It is common in the implementation of hashmap and ArrayList. Let's see how ListItr judges whether there is any modification.
private class Itr implements Iterator<E> {
int expectedModCount = modCount;//The initial values are equal
//Quick judgment is mainly used to judge whether the modified data is consistent with the expected modification
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}expectedModCount has no other modification in the iterator except assigning the value of modCount, which means that if it needs to be unequal, the value of modCount has been modified, and the value modification of modCount means that other threads are calling the add or remove operation of list.
Fail safe is based on the clone of the set. When the value of the container is modified, the combination of the cloned sets will not be affected. The concurrent package is basically fail safe. This is an application of the cow (copy on write) principle. Its advantage is that it will not trigger the concurrentModificationException, but it traverses a snapshot of the collection at that time. If the data is added at the same time, it cannot be traversed.
Talk about the capacity expansion mechanism of ArrayList?
Directly analyze the source code:
//Input parameter: minimum value after capacity expansion
private void grow(int minCapacity) {
// Original capacity
int oldCapacity = elementData.length;
//The new capacity is 1.5 times that of the original. Here, move 1 bit to the right, which is similar to dividing by 2 JDK source code has many bit operations
int newCapacity = oldCapacity + (oldCapacity >> 1);
//After 1.5 times, it is smaller than the minimum value and directly becomes the minimum value
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
// Whether it is greater than the defined maximum value. If it is greater than the maximum value of integer, otherwise it is MAX_ARRAY_SIZE
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// Data copy, using system copy function
elementData = Arrays.copyOf(elementData, newCapacity);
}From the source code analysis, the capacity expansion has been judged in several steps: it is directly the original 1.5 - "and input reference comparison -" and maxARRAY comparison.
How does hashset ensure the uniqueness of elements?
Let's start with the source code. Let's first look at the process of adding an element.
public boolean add(E e) {
return map.put(e, PRESENT)==null;//If it exists, oldvalue is returned; if it does not exist, null is returned
}
//The bottom layer is hashmap. Let's look at the implementation of hashmap. value is a fixed object
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
//...
//To judge whether it exists, the hash value and the equals method must be equal
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//...
}From the above process, if hash and equals are equal, it is considered to exist. This will focus on the putval method in hashmap.
What is the difference between comparable and Comparator?
Comparator in package Java Util, while comparable is in the package Java Let's go. Comparable is the sort implemented by the method defined inside the collection, and comparator is the sort implemented outside the collection. Comparble is an object supported interface that needs to be implemented. For example, string and Byte all implement this interface. When the comparison method defined by an object cannot meet the requirements, we can consider implementing the comparator interface, which is the difference between the two.
Let's give an example:
public static void main(String[] args) throws Exception {
Test test1 = new Test(1,2);
Test test2 = new Test(2,1);
Test[] testArray = new Test[]{test1,test2};
Arrays.sort(testArray);//Result order test1,test2
Arrays.sort(testArray,new ComparatorTest());//Result order: test2,test1
}
//Define a new comparison function without modifying the class
public static class ComparatorTest implements Comparator<Test>{
@Override
public int compare(Test o1, Test o2) {
return o1.b.compareTo(o2.b);
}
}
//Define the comparison function of the class
public static class Test implements Comparable<Test>{
private Integer a;
private Integer b;
Test(int a,int b){
this.a = a;
this.b = b;
}
@Override
public int compareTo(Test o) {
return this.a.compareTo(o.a);
}
}In the above example, a test class is defined. While defining the class, the comparable interface is defined to realize intra class comparison. A ComparatorTest class is also defined for comparators that cannot be satisfied by those classes.
The set introduced in this article focuses on the collection of sets. In the next section, we will focus on map, especially hashmap. If there is time, we suggest that we look at the collection class of jdk source code. If there are any problems, we can see the source code or the message in the official account.
There are so many contents in this article. If you think it is helpful for your study and interview, please give me a favor or forward it. Thank you.
Want to know more java content (including big factory interview questions and questions) can pay attention to the official account, also can leave messages in official account, help push Ali, Tencent and other Internet factories.