Implementation of keyword based text sorting and retrieval system in Java@ TOC
Note: personal learning records should not be used in other ways
Test requirements:
(1) The TF-IDF model is used to create an index (such as inverted index) for the text in the text library.
(2) The keywords entered by the user can be one or more.
(3) For the returned result text, the frequency information of each search keyword in the result text shall be displayed at the same time.
(4) The system supports viewing the returned result text.
(5) Development requirements support the management and maintenance of stop words. Stop words refer to words that have no retrieval value, such as is, am, are, a, an, the,that, etc.
(6) It is required to support dynamic loading and processing of text library
Design ideas
Program flow chart
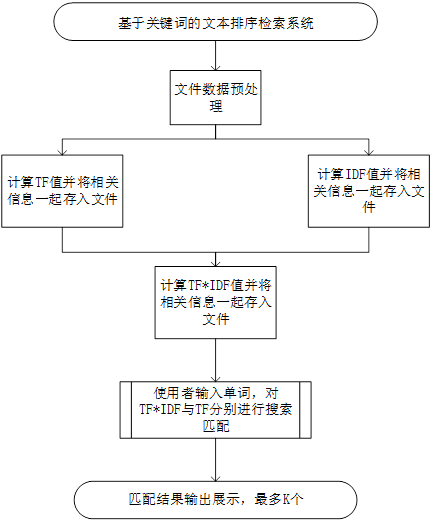
**Note: * * it is implemented in the form of txt file. The given text data set is processed to obtain the index file, and then the index file is directly searched. (ps: it feels like setting up a pointer to the keywords in the file)
Design ideas
1 data preprocessing
Get the unzipped file path, traverse the file array through the for loop, and use strAll = getTemplateContent(file); The function gives the contents of the file in the form of String, converts all words into uppercase letters through toUpperCase() function, and then cuts the word of strAll. First, replace various useless separators with "-", such as str = str.replaceAll("\r\n","-");str = str.replaceAll("\ |", "-") and replace multiple "-" with a single "-". Then, by cutting "-", the file is cut into String [], and each element is a meaningful character. After that, you can use HashMap < String, integer > to carry out word frequency information, write TF files and execute subsequent steps.
2 TF-IDF model
Based on TF-IDF (term frequency inverted document frequency) is a commonly used weighting technique for information retrieval and information exploration. TF-IDF is a statistical method to evaluate the importance of a word to a document set or one of the documents in a corpus. The importance of a word increases in proportion to the number of times it appears in the document, but at the same time it increases in the corpus The frequency of occurrence in the library decreases inversely. In short, TF is to count the word frequency of words in this document; IDF reflects the relationship between the number of documents with a word and the total number of documents. The more documents appear, the less important the word is.
Therefore, the TF value and IDF of the file can be calculated separately and then combined to obtain the TF-IDF value. Calculation method of TF:
〖TF〗_i=n_i/all
Where the numerator is the number of occurrences of word i in the current file, and the denominator is the number of words in the current file. IDF calculation method:
〖IDF〗_i=log D_i/allD
In the fraction of the logarithmic function, the numerator is the number of files in which the word i is contained, and the denominator is the number of all files, that is, 1000.
Finally, multiply the TF value of word i by the IDF value to get the final result and write it to a new file.
3 keyword matching algorithm
According to the String entered by the user, cut and coexist as String [], and traverse TF and TFIDF files in order, if word Equals (strs1 [0]) that is, if the strings are equal, relevant text information is returned. It is found in the data processing that some words have high TF values, but the IDF value is very small. Therefore, I use to return K files with the largest TF and the largest TFIDF at the same time. I think this is more reasonable. If the user inputs a stop word, the prompt information will be output and the program will exit; If the word entered by the user is less than k files, only K files will be returned.
The code is as follows
**Note: * * codes are not put together. First process the text, calculate the index file, and then display the search and return results.
1.File data preprocessing
package testCode;
import java.io.File;
import java.io.FileInputStream;
import java.nio.charset.StandardCharsets;
public class getFileName {
static int count =0;
public static void main(String[] args) {
String path = "C:\\Users\\11422\\Desktop\\Algorithm design\\subject B3 Data set for";
File f = new File(path);
getFileName.getFile(f);
System.out.println(count);
}
public static void getFile(File file){
if(file != null){
File[] files = file.listFiles();
String strAll="";
if(files != null){
for(int i=0;i<files.length;i++){
getFile(files[i]);
}
}else{
//Output file path: system out. println(file);
try {
//Fetch file contents to string
strAll = getTemplateContent(file);
//Count how many files are taken out
count++;
testCode test = new testCode();
test.SplitFile(strAll);
//Output string length and content
//System.out.println(strAll.length()+"--"+strAll);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
//Get file content to string
private static String getTemplateContent(File file) throws Exception{
if(!file.exists()){
return null;
}
FileInputStream inputStream = new FileInputStream(file);
int length = inputStream.available();
byte bytes[] = new byte[length];
inputStream.read(bytes);
inputStream.close();
String str =new String(bytes, StandardCharsets.UTF_8);
return str ;
}
}
2.calculation TF Value and save to file
package testCode;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.util.HashMap;
public class testCode {
public static void SplitFile(String str){
//Index files for all words
File SimplifiedData =
new File("C:\\Users\\11422\\Desktop\\Algorithm design\\SimplifiedData.txt");
FileWriter fw = null;
BufferedWriter bw = null;
try {
fw =new FileWriter(SimplifiedData,true);
} catch (IOException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
bw =new BufferedWriter(fw);
//Capitalize all letters of the string for subsequent processing
str = str.toUpperCase();
//Convert various characters into a unified character, which is easy to cut and will not be left blank
str = str.replaceAll("\r\n","-");
str = str.replaceAll(" ","-");
str = str.replaceAll("$","-");
str = str.replaceAll("\\(","-");
str = str.replaceAll("\\[","-");
str = str.replaceAll("\\]","-");
str = str.replaceAll("\\)","-");
str = str.replaceAll("\\'","-");
str = str.replaceAll("\\!","-");
str = str.replaceAll(":","-");
str = str.replaceAll(";","-");
str = str.replaceAll("\\.","-");
str = str.replaceAll("\\?","-");
str = str.replaceAll("\\|","-");
str = str.replaceAll(",","-");
str = str.replaceAll("\\'","-");
str = str.replaceAll("--------","-");
str = str.replaceAll("-------","-");
str = str.replaceAll("------","-");
str = str.replaceAll("-----","-");
str = str.replaceAll("----","-");
str = str.replaceAll("---","-");
str = str.replaceAll("--","-");
//Replacement complete
//System.out.println(str);
//Press - to cut
String[] strs = str.split("-");
System.out.println("Total number of file words"+strs.length);
for(int i = 0 ; i < strs.length ; i++){
System.out.println(strs[i]);
}
//Defines the number of occurrences of each string in a two column set storage string
HashMap<String,Integer> hashMap = new HashMap<>();
//HashMap<String,Integer> hashMap2 = new HashMap<>();
for(String c :strs){
//If it is included, add 1, otherwise it will be stored as a key
if(!hashMap.containsKey(c)){
hashMap.put(c,1);
}else{
hashMap.put(c,hashMap.get(c)+1);
}
}
//frequnency recording frequency
double frequnency = 0;
for(String key : hashMap.keySet()){
//Calculate TF value
frequnency = (double)hashMap.get(key)/(double)strs.length;
try {
bw.write(key+"--"+hashMap.get(key)+"--"+frequnency+"--"+strs[0]);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
try {
bw.newLine();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
//Output and write content to Console
System.out.println(key+"--"+hashMap.get(key)+"--"+frequnency+"--"+strs[0]);
}
try {
bw.flush();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
try {
bw.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
3.calculation IDF value
package MAIN;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;
public class IDF {
public void IdfCalculate(String path) throws IOException{
File Directory = new File(path);
FileReader reader = new FileReader(Directory);
BufferedReader bReader = new BufferedReader(reader);
String temp="";
//Create a hash table to calculate the total number of occurrences of words in all documents
HashMap<String,Integer> hashMap = new HashMap<>();
//The dynamic array is used to store the words that appear in all simplified documents, and there are duplicates at this time
ArrayList words = new ArrayList();
//String[] words = new String[]{}; String type array cannot complete dynamic length change
while((temp =bReader.readLine()) !=null){//Read file by line
//Cut and group strings by "-"
String[] strs = temp.split("--");
//The first element of each cut is a word
words.add(strs[0]);
}
//Calculate dynamic array length
int size = words.size();
//Convert the ArrayList into a String type array to facilitate the subsequent input hash table to calculate the IDF value and write it to the Directory file
String[] array = (String[])words.toArray(new String[size]);
for(String c :array){
//If it is included, add 1, otherwise it will be stored as a key
if(!hashMap.containsKey(c)){
hashMap.put(c,1);
}else{
hashMap.put(c,hashMap.get(c)+1);
}
}
bReader.close();
for(String key : hashMap.keySet()){
//Output and write content to Console
System.out.println(key+"--"+hashMap.get(key));
}
System.out.println(hashMap.size());
//Write IDF value to IDF file after calculation
FileWriter fw = null;
BufferedWriter bw = null;
File Idf = new File("C:\\Users\\11422\\Desktop\\Algorithm design\\IDF.txt");
try {
fw =new FileWriter(Idf,true);
} catch (IOException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
bw =new BufferedWriter(fw);
double idf = 0;
for(String key : hashMap.keySet()){
//Calculate TF value
idf = log(1000/hashMap.get(key),10);
try {
bw.write(key+"--"+hashMap.get(key)+"--"+idf);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
try {
bw.newLine();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
//Output and write content to Console
System.out.println(key+"--"+hashMap.get(key)+"--"+idf);
}
try {
bw.flush();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
try {
bw.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
//Calculate the base 10 logarithmic function
static public double log(double value, double base) {
return Math.log(value) / Math.log(base);
}
}
4.calculation TF*IDF value
package MAIN;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
public class TFIDF {
//Extract the contents of files 1 and 2 and write them to file 3
public void TfIdf(String path1,String path2,String path3){
File file1=new File(path1);
File file2=new File(path2);
File file3=new File(path3);
//String[] strs = temp1.split("--");
try {
if(!file3.exists()){
file3.createNewFile();
}
BufferedReader br1=new BufferedReader(new FileReader(file1));
String line1=br1.readLine();
BufferedReader br2=new BufferedReader(new FileReader(file2));
//Flag, used to read and write files, return to the beginning
br2.mark((int)file2.length()+1);
String line2=br2.readLine();
BufferedWriter bw=new BufferedWriter(new FileWriter(file3,true));
//Loop control file content writing
while(line1!=null){
String[] strs1 = line1.split("--");
while(line2 !=null){
String[] strs2 = line2.split("--");
if(strs1[0].equals(strs2[0])){
//Calculate the TFIDF value through files 1 and 2 and write it to the Directory file
double tfidf =Double.parseDouble(strs1[2])*Double.parseDouble(strs2[2]);
//File content format, which is conducive to cutting and grouping
bw.write(strs1[0]+"--"+strs1[1]+"--"+tfidf+"--"+strs1[3]);
bw.newLine();
}
line2=br2.readLine();
}
if(line2==null){
//If file 2 is read to the last, the tag position is returned
br2.reset();
line2=br2.readLine();
}
line1=br1.readLine();
//System.out.println(line1);
}
//Close file read / write stream
br1.close();
br2.close();
bw.flush();
bw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
5.Keyword matching
package MAIN;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
import java.util.ArrayList;
public class Find {
public void FindWord(String word,String TF,String TFIDF){
//Returns up to 5 most relevant texts
int times=5;
//Format words in uppercase
word=word.toUpperCase();
//IDF value
ArrayList<String> list1= new ArrayList<String>();
//TFIDF value
ArrayList<String> list2= new ArrayList<String>();
File file1=new File(TF);
File file2=new File(TFIDF);
try {
BufferedReader br1=new BufferedReader(new FileReader(file1));
String line1=br1.readLine();
BufferedReader br2=new BufferedReader(new FileReader(file2));
//Flag, used to read and write files, return to the beginning
br2.mark((int)file2.length()+1);
String line2=br2.readLine();
//The contents of the directory matching the keyword of the circular control file are written to the dynamic array
while(line1!=null){
String[] strs1 = line1.split("--");
if(word.equals(strs1[0])){
list1.add(line1);
}
line1=br1.readLine();
}
while(line2!=null){
String[] strs2 = line2.split("--");
if(word.equals(strs2[0])){
list2.add(line2);
}
line2=br2.readLine();
}
//Close file read / write stream
br1.close();
br2.close();
} catch (IOException e) {
e.printStackTrace();
}
//Descending sort by bubble sort
int size = list1.size();
for (int i = 0; i < size - 1; i++) {
for (int j = i + 1; j < list1.size(); j++) {
String[] strs1 = list1.get(i).split("--");
String[] strs2 = list1.get(j).split("--");
//The string is converted to double type data. Pay attention to the interference of E-4 and use the valueOf function to solve it
if (Double.valueOf(strs1[2]) < Double.valueOf(strs2[2])) {
String temp = list1.get(i);
list1.set(i, list1.get(j));
list1.set(j, temp);
}
}
}
//Same as list1
int size2 = list2.size();
for (int i = 0; i < size2 - 1; i++) {
for (int j = i + 1; j < list2.size(); j++) {
String[] strs1 = list2.get(i).split("--");
String[] strs2 = list2.get(j).split("--");
if (Double.valueOf(strs1[2]) < Double.valueOf(strs2[2])) {
String temp = list2.get(i);
list2.set(i, list2.get(j));
list2.set(j, temp);
}
}
}
//Loop through the times text that matches the output
if(list1.size()<times){//Judge, if the number of text you want is more than some, output all the sorted text
System.out.println("All documents and TF Value (word)--Number of occurrences in the document--TF value--Document No.)");
for(int i =0; i<list1.size() ;i++){
System.out.println(list1.get(i));
}
System.out.println("All documents and TF*IDF Value (word)--Number of occurrences in all documents--TF*IDF--Document No.)");
for(int i =0; i<list2.size() ;i++){
System.out.println(list2.get(i));
}
}else{
//If there are more files than you need, you can output them with the upper limit of what you need
System.out.println("All documents and TF Value (word)--Number of occurrences in the document--TF value--Document No.)");
for(int i =0; i<times ;i++){
System.out.println(list1.get(i));
}
System.out.println("All documents and TF*IDF Value (word)--Number of occurrences in all documents--TF*IDF--Document No.)");
for(int i =0; i<times ;i++){
System.out.println(list2.get(i));
}
}
}
}
6.Stop word comparison
package MAIN;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.util.ArrayList;
public class StopWord {
public Boolean SW(String word) throws IOException{
File fileSW = new File("C:\\Users\\11422\\Desktop\\Algorithm design\\StopWords.txt");
String temp =null;
BufferedReader br = new BufferedReader(new FileReader(fileSW));
//Dynamic array read stop words
ArrayList<String> words = new ArrayList();
while((temp = br.readLine()) != null){
//Write the read out stop word to the dynamic array and return
words.add(temp);
}
//Search for keywords and return true if any
for(int i = 0 ; i <words.size() ; i++){
//Convert the entered keywords to lowercase
if(word.toLowerCase().equals(words.get(i))){
return true;
}
}
return false;
}
}
7.Open file function
package MAIN;
import java.io.File;
import java.io.IOException;
public class OpenFile {
public void Open(int number){
String path = "C:\\Users\\11422\\Desktop\\Algorithm design\\subject B3 Data set for\\"+number+".txt";
File file=new File(path);
try {
java.awt.Desktop.getDesktop().open(file);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
8.Retrieval system running main function
package MAIN;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
import java.util.Scanner;
public class Main {
public static void main(String args[]){
String Filepath1 = "C:\\Users\\11422\\Desktop\\Algorithm design\\SimplifiedData.txt";//Word -- number of occurrences in the document -- TF value -- document sequence number
String Filepath2 = "C:\\Users\\11422\\Desktop\\Algorithm design\\IDF.txt";//Words -- total library times -- IDF value
String Filepath3 = "C:\\Users\\11422\\Desktop\\Algorithm design\\Directory.txt";//Word -- number of occurrences in the document -- TF*IDF -- document serial number
String Filepath4 = "C:\\Users\\11422\\Desktop\\Temp.txt";
File file1=new File(Filepath1);
File file2=new File(Filepath2);
File file3=new File(Filepath3);
//Get IDF values for all text
/*IDF idf = new IDF();
try {
idf.IdfCalculate(Filepath1);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
*/
//Through files 1 and 2, calculate the TFIDF value and establish an index library. The file contains: word -- number of occurrences in the document -- TF*IDF -- document serial number
/*TFIDF value = new TFIDF();
value.TfIdf(Filepath1, Filepath2, Filepath3);
*/
String str;
int number;
StopWord word = new StopWord();
System.out.println("Welcome to keyword retrieval system!");
System.out.println("Please enter the keyword (English word) to retrieve,Do not enter stop words) multiple keyword formats( A--B--C): ");
//Read the keyword to be retrieved into the String type variable str
Scanner sc = new Scanner(System.in);
str = sc.next();
String[] words = str.split("--");
for(int i=0 ; i <words.length ;i++){
boolean result;
if(result = words[i].matches("[a-zA-Z]+")){
//Stop word judgment
try {
if(word.SW(words[i])){
System.out.println("You have entered a stop word! Invalid stop word!");
return;
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
//Stop word judgment completed
}else{
System.out.println("Not all English! The program is over!");
return;
}
Find find=new Find();
find.FindWord(words[i],Filepath1 ,Filepath3);
System.out.println("Enter 1 to query the document, and 2 to find the next keyword or exit the program after searching:");
number = sc.nextInt();
while(number!=1&&number!=2){
System.out.println("Illegal input! Please re-enter 1 or 2!");
System.out.println("Enter 1 to query the document, and 2 to find the next keyword or exit the program after searching:");
number = sc.nextInt();
}
while(number==1){
System.out.println("Please enter the document serial number to query (only numbers)");
number=sc.nextInt();
OpenFile open =new OpenFile();
open.Open(number);
//Ask again if you want to continue querying the document
System.out.println("Enter 1 to query the document, and 2 to find the next keyword or exit the program after searching:");
number=sc.nextInt();
while(number!=1&&number!=2){
System.out.println("Illegal input! Please enter 1 or 2!");
System.out.println("Enter 1 to query the document, and 2 to find the next keyword or exit the program after searching:");
number = sc.nextInt();
}
}
if(number == 2){
if(i==words.length-1){
System.out.println("Keyword retrieval completed! Thank you for using this program! Welcome to use next time!");
return;
}
System.out.println("------------------------------Next keyword------------------------------");
}
}
System.out.println("Keyword retrieval completed! Thank you for using this program! Welcome to use next time!");
return;
}
}
**Note: * * stop words are a simple and rough way to think, that is, all meaningless symbols are replaced with "-", and then multiple "-" to single "-" are replaced. (unified as "-" for convenience of cutting)
Test data and results
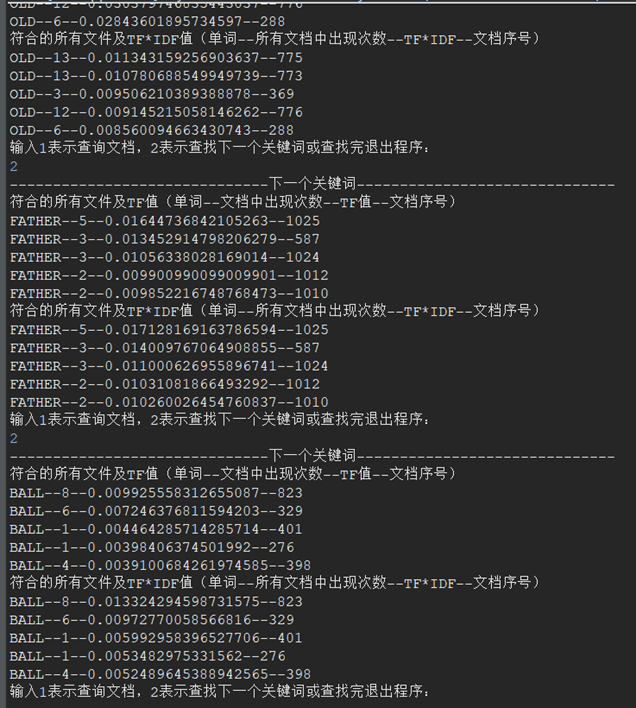
During the test, it is set to return the first k=5 file information at most.
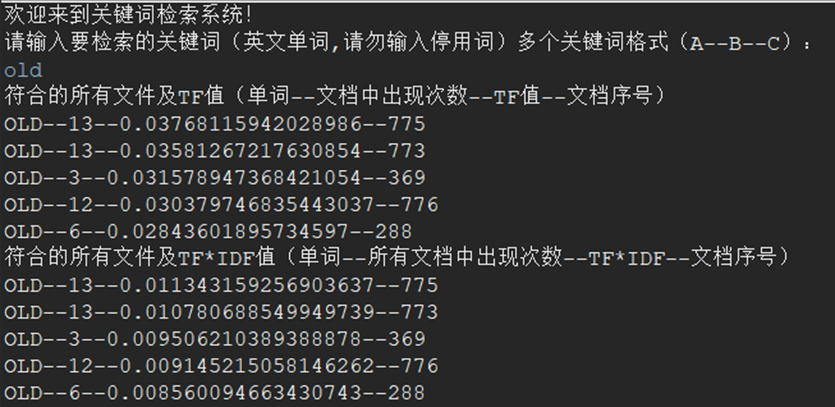
- Test return file information
Input: old
Ideal output: the first 5 TF values and TF*IDF values
Actual output: consistent with ideal output
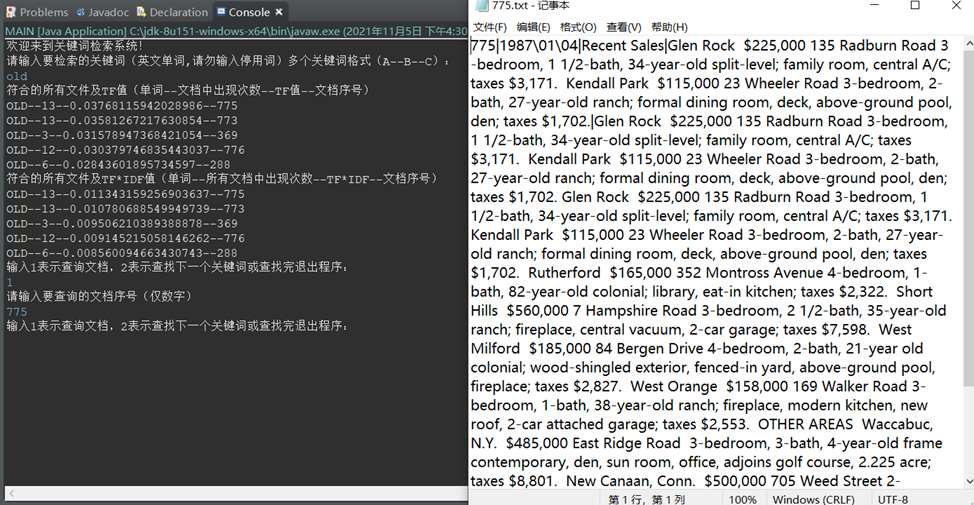
- Return to file open test
Input: corresponds to the file number to be opened
Ideal output: open the corresponding file
Actual output: the corresponding file is opened
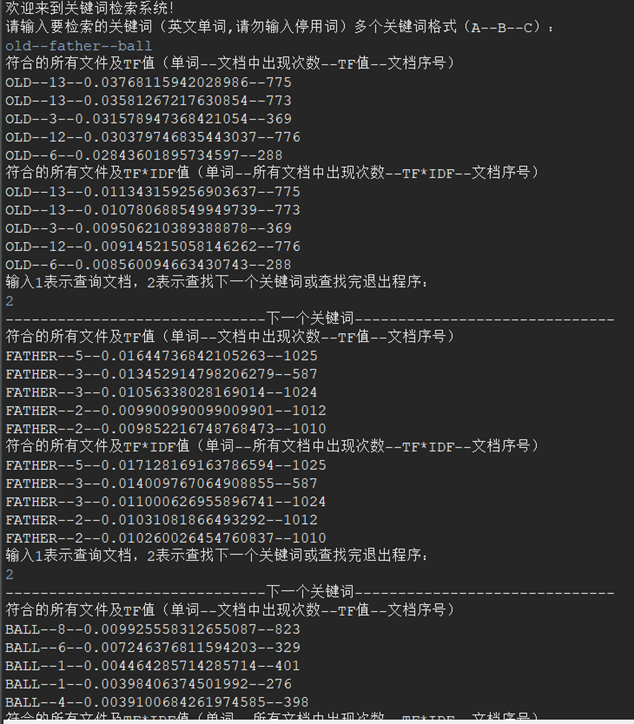
- Multiple string input tests
Input: old – father – ball
Ideal output: returns the relevant text in turn
Actual output: consistent with ideal
! [insert picture description here]( https://img-blog.csdnimg.cn/a67f452e093d4593bfef92d2176fb7bf.png?x -oss-process=image/watermark,type_ d3F5LXplbmhlaQ,shadow_ 50,text_ Q1NETiBA5p2l5aaC6aOO6ZuoLeWOu-iLpeW-ruWwmA==,size_ 13,color_ FFFFFF,t_ 70,g_ se,x_ sixteen
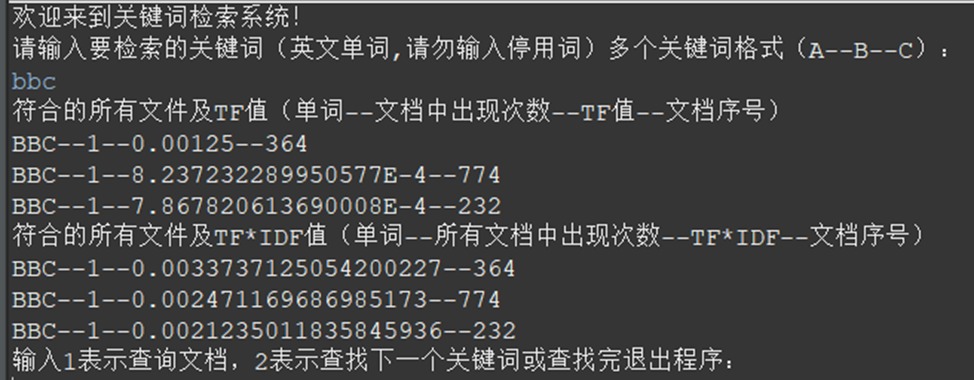
- If the number of related files is less than k, some will be returned
Input: bbc
Ideal output: less than 5 files
Actual output: consistent with ideal
Problems in algorithm design and program debugging
Problem 1: when using String [] array to store the cut String, the array subscript is out of bounds.
Solution: use the dynamic array ArrayList for storage.
Problem 2: it is too troublesome to count the occurrence times of words by loop traversal.
Solution: use the hash table to store, and all words and their occurrence frequency can be counted in one traversal.
Question 3: there is no logarithm function with base 10 in Java.
Solution: transform through the bottom changing formula, write your own function for transformation, math log(value) / Math. log(base).
Question 4: when converting and comparing the floating-point values stored in the String type in the file, the result is incorrect, but there is no syntax problem.
Solution: it is found that there is data of type 0.00xxe-4 during storage, and the last value of forced type conversion is incorrect. Then use another function double Valueof (strs1 [2]) can be compared after conversion.
Pit excavation summary
During the algorithm design, in fact, there are some library functions in Java that can be called directly to complete the corresponding functions, but I still want to write them myself because it is not difficult. However, due to the use of text for data storage and conversion, it takes a lot of time to read and write a large amount of data. Just like the last text content of B3, I read the contents of two texts at the same time, and then write the third text after data type conversion. It took almost 30 minutes from the beginning to the end of writing the last text. However, after processing these three texts, the keyword retrieval is very fast. However, if the text is added or deleted, the update of the file will be too expensive. I think if the next step is to optimize the algorithm, the most important thing is to use the database to process the text content, which is more conducive to dynamic change.