java interview questions from basic to advanced
I Basics
What are the characteristics of Java object-oriented and how to apply it
Object oriented programming is an idea of using class and object programming. All things can be classified. Class is a high abstraction of things in the world. Different things have different relationships, the encapsulation relationship between a class itself and the outside world, the inheritance relationship between a parent class and a child class, and the polymorphic relationship between a class and multiple classes. All things are objects. Objects are specific world things. The three characteristics of object-oriented are encapsulation, inheritance and polymorphism. Encapsulation, which describes the relationship between a class behavior and attributes and other classes, with low coupling and high cohesion; Inheritance is the relationship between parent and child classes, and polymorphism is the relationship between classes.
Encapsulation hides the internal implementation mechanism of the class, which can change the internal structure of the class without affecting the use, and also protect the data. To the outside world, its internal details are hidden, and only its access methods are exposed to the outside world. Encapsulation of attributes: users can only access data through pre-defined methods, and can easily add logic control to limit unreasonable operations on attributes; Method encapsulation: the user calls the method according to the established way, and does not need to care about the internal implementation of the method, which is easy to use; Easy to modify and enhance the maintainability of the code;
Inheritance is to derive a new class from an existing class. The new class can absorb the data properties and behaviors of the existing class and expand new capabilities. In essence, it is a special ~ general relationship, that is, the is-a relationship. The subclass inherits the parent class, which indicates that the subclass is a special parent class and has some properties or methods that the parent class does not have. Abstract a base class from multiple implementation classes to make it have the common characteristics of multiple implementation classes, When the implementation class inherits the base class (parent class) with the extends keyword, the implementation class has these same properties. The inherited class is called a subclass (derived class or superclass), and the inherited class is called a parent class (or base class). For example, an animal class can be abstracted from cat, dog and tiger, which has the same characteristics as cat, dog and tiger (eat, run, call, etc.). Java implements inheritance through the extends keyword. Variables and methods defined through private in the parent class will not be inherited, and variables and methods defined through private in the parent class cannot be directly operated in subclasses. Inheritance avoids repeated description of common features between general classes and special classes, and each common feature can be clearly expressed through inheritance The applicable conceptual scope, the attributes and operations defined in the general class are applicable to the class itself and all objects of each layer of special classes below it. The application of inheritance principle makes the system model more concise and clear.
Compared with encapsulation and inheritance, Java polymorphism is one of the three difficult features. Encapsulation and inheritance finally come down to polymorphism. Polymorphism refers to the relationship between classes. The two classes are inherited and have method rewriting. Therefore, parent class references can point to child class objects when calling. Polymorphism requires three elements: inheritance, rewriting, and parent class references pointing to child class objects.
What is the principle of HashMap? In jdk1 What is the difference between 7 and 1.8
HashMap stores data according to the hashCode value of the key. In most cases, it can directly locate its value, so it has fast access speed, but the traversal order is uncertain. HashMap only allows the key of one record to be null at most, and the value of multiple records to be null. HashMap is not thread safe, that is, multiple threads can write HashMap at any time, which may lead to inconsistent data. If you need to meet thread safety, you can use the synchronized map method of Collections to make HashMap thread safe, or use ConcurrentHashMap. Let's use the following picture to introduce
The structure of HashMap.
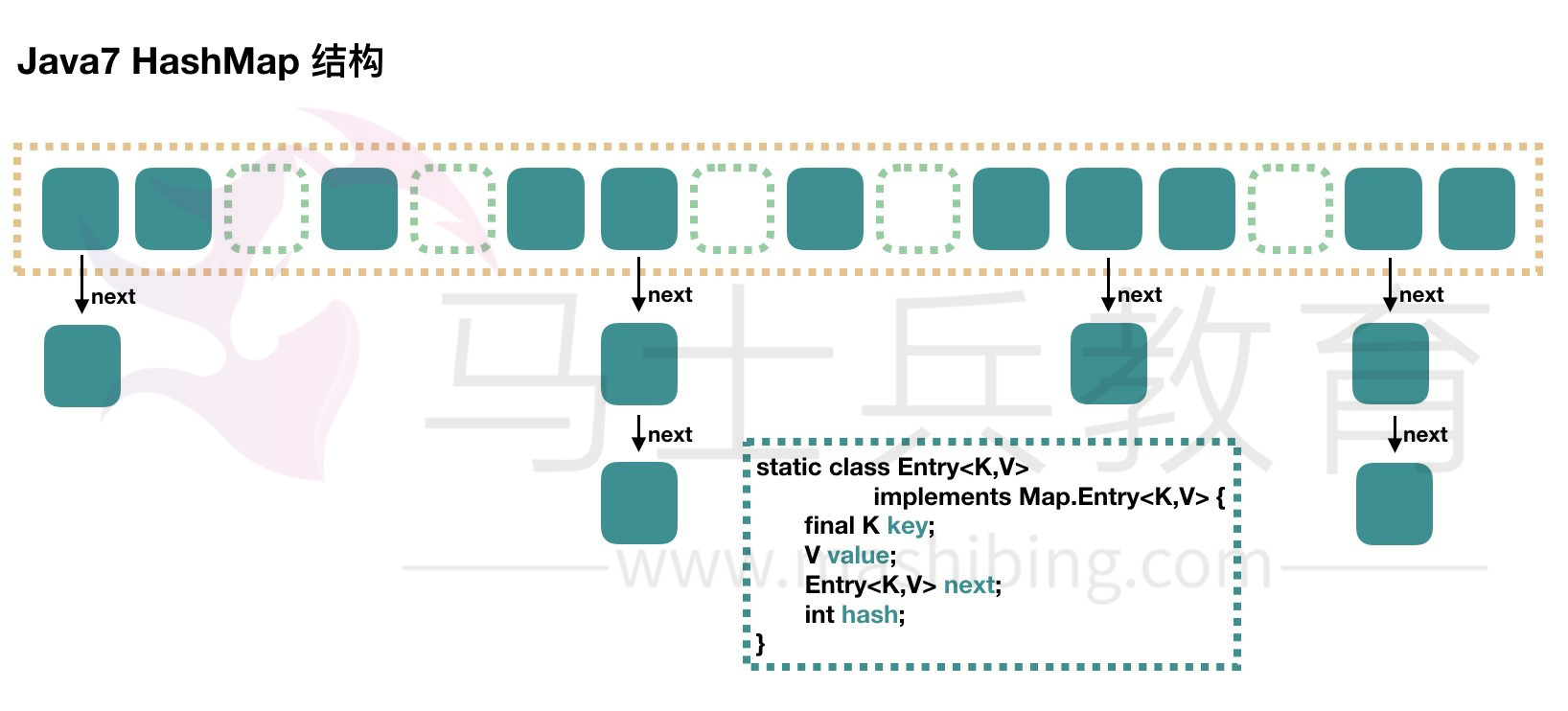
In the general direction, there is an array in the HashMap, and then each element in the array is a one-way linked list. In the figure above, each green
The entity of is an instance of the nested class Entry. The Entry contains four attributes: key, value, hash value and next for one-way linked list.
-
Capacity: the current array capacity, which is always 2^n, can be expanded. After expansion, the array size is twice the current size.
-
loadFactor: load factor, which is 0.75 by default.
-
Threshold: the threshold of capacity expansion, equal to capacity * loadFactor
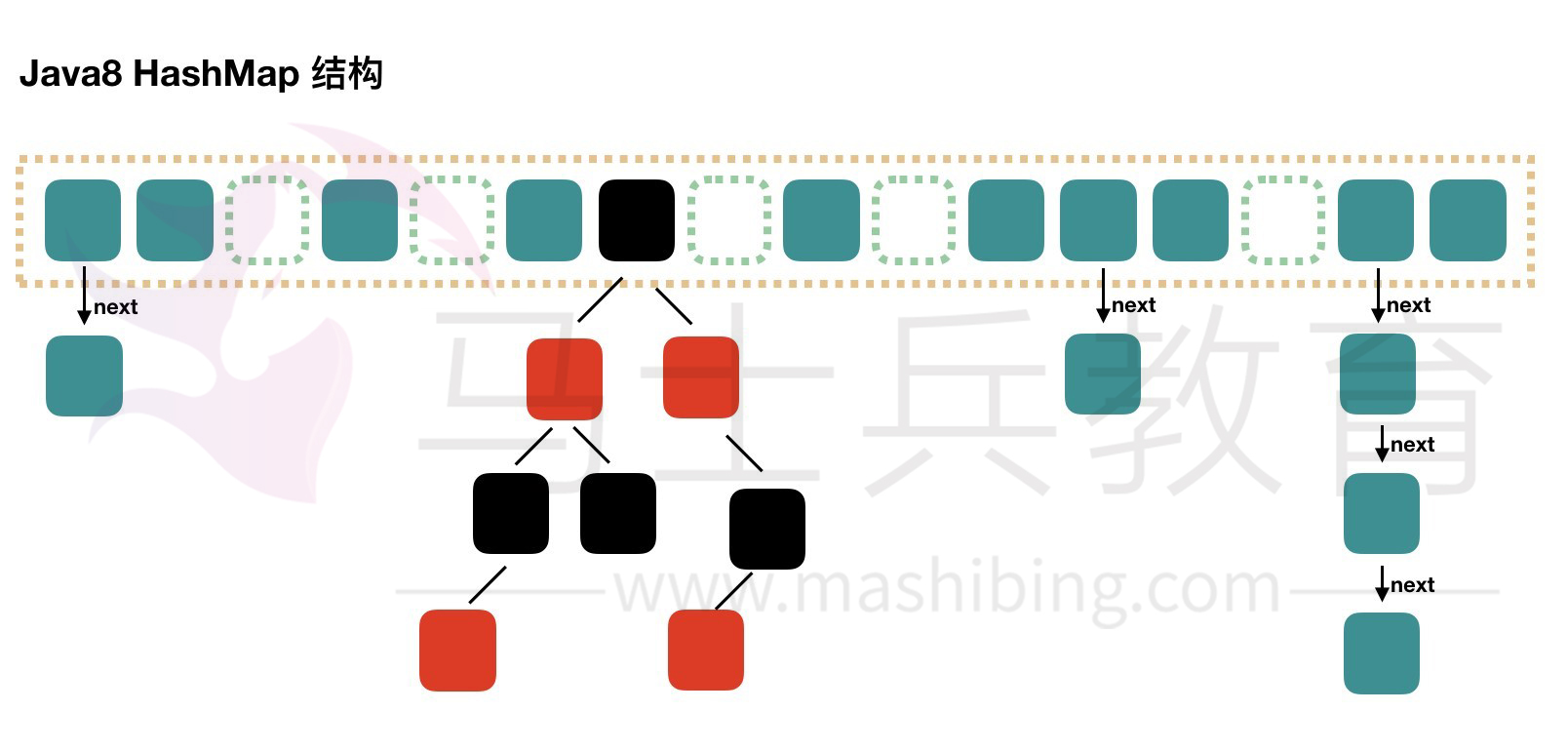
JAVA8 implementation
Java 8 has made some modifications to HashMap. The biggest difference is that it uses red black tree, so it is composed of array + linked list + red black tree.
According to the introduction of Java7 HashMap, we know that when searching, we can quickly locate the specific subscript of the array according to the hash value, but then we need to compare one by one along the linked list to find what we need. The time complexity depends on the length of the linked list, which is O(n). In order to reduce the overhead of this part, in Java 8, when there are more than 8 elements in the linked list, the linked list will be converted into a red black tree. When searching in these locations, the time complexity can be reduced to O(logN).
What is the difference between ArrayList and LinkedList
ArrayList and LinkedList both implement the List interface. They have the following differences:
- ArrayList is an index based data interface, and its bottom layer is array. It can randomly access elements with O(1) time complexity. Correspondingly, LinkedList stores its data in the form of element list. Each element is linked with its previous and subsequent elements. In this case, the time complexity of finding an element is O(n).
- Compared with ArrayList, the insertion, addition and deletion operations of LinkedList are faster, because when elements are added to any position in the collection, there is no need to recalculate the size or update the index like an array.
- LinkedList takes more memory than ArrayList because LinkedList stores two references for each node, one to the previous element and one to the next element.
You can also refer to ArrayList vs. LinkedList.
-
Because Array is an index based data structure, it is fast to search and read data in an Array using an index. The time complexity of obtaining data in Array is O(1), but deleting data is very expensive, because it needs to rearrange all the data in the Array.
-
LinkedList insertion is faster than ArrayList. Unlike ArrayList, LinkedList does not need to change the size of the array or reload all data into a new array when the array is full. This is the worst case of ArrayList. The time complexity is O(n), while the time complexity of insertion or deletion in LinkedList is only O(1). ArrayList also needs to update the index when inserting data (in addition to inserting the tail of the array).
-
Similar to inserting data, LinkedList is also better than ArrayList when deleting data.
-
LinkedList needs more memory because the location of each index in ArrayList is the actual data, Each Node in the LinkedList stores the actual data and the positions of the front and rear nodes (a LinkedList instance stores two values: Node first and Node last respectively represent the actual Node and tail Node of the linked list, and each Node instance stores three values: e item, Node next and Node pre).
What scenario is better to use LinkedList instead of ArrayList
-
Your app doesn't randomly access data. Because if you need the nth element in the LinkedList, you need to count from the first element to the nth data, and then read the data.
-
Your application inserts and deletes more elements and reads less data. Because inserting and deleting elements does not involve rearranging data, it is faster than ArrayList.
In other words, ArrayList is implemented with arrays, LinkedList is based on linked lists, ArrayList is suitable for searching, and LinkedList is suitable for adding and deleting
The above is the difference between ArrayList and LinkedList. When you need an unsynchronized index based data access, try to use ArrayList. ArrayList is fast and easy to use. But remember to give an appropriate initial size and reduce the size of the array as much as possible.
jdk1. What are the new features of 8
1, Default method for interface
Java 8 allows us to add a non abstract method implementation to the interface. We only need to use the default keyword. This feature is also called extension method. An example is as follows:
The code is as follows:
interface Formula {
double calculate(int a);
default double sqrt(int a) {
return Math.sqrt(a);
}
}
In addition to the calculate method, the Formula interface also defines the sqrt method. Subclasses that implement the Formula interface only need to implement one calculate method. The default method sqrt will be used directly on subclasses.
The code is as follows:
Formula formula = new Formula() {
@Override
public double calculate(int a) {
return sqrt(a * 100);
}
};
formula.calculate(100); // 100.0 formula.sqrt(16); // 4.0
The formula in this paper is implemented as an instance of an anonymous class. The code is very easy to understand. Six lines of code realize the calculation of sqrt(a * 100). In the next section, we'll see a simpler way to implement a single method interface.
Translator's note: in Java, there is only single inheritance. If you want to give a class new features, it is usually implemented using interfaces. In C + +, multiple inheritance is supported, allowing a subclass to have the interfaces and functions of multiple parent classes at the same time. In other languages, the method of making a class have its reusable code at the same time is called mixin. This new feature of the new Java 8 is closer to Scala's trait in terms of compiler implementation. In C #, it is also known as the concept of extension method, which allows extending methods to existing types, which is semantically different from that in Java 8.
2, Lambda expression
First, let's look at how strings are arranged in the old version of Java:
The code is as follows:
List<String> names = Arrays.asList("peterF", "anna", "mike", "xenia");
Collections.sort(names, new Comparator<String>() {
@Override public int compare(String a, String b) {
return b.compareTo(a);
}
});
Just give the static method collections Sort passes in a List object and a comparator to sort in the specified order. The usual approach is to create an anonymous comparator object and pass it to the sort method.
In Java 8, you don't need to use the traditional anonymous object method. Java 8 provides a more concise syntax, lambda expression:
The code is as follows:
Collections.sort(names, (String a, String b) -> {
return b.compareTo(a);
});
You see, the code becomes more segmented and readable, but it can actually be shorter:
The code is as follows:
Collections.sort(names, (String a, String b) -> b.compareTo(a));
If there is only one line of code in the function body, you can remove the braces {} and the return keyword, but you can also write it shorter:
The code is as follows:
Collections.sort(names, (a, b) -> b.compareTo(a));
The Java compiler can automatically derive parameter types, so you don't have to write types again. Next, let's see what more convenient things lambda expressions can do:
3, Functional interface
How are lambda expressions represented in the java type system? Each lambda expression corresponds to a type, usually an interface type. The "functional interface" refers to an interface that contains only one abstract method, and every lambda expression of this type will be matched to this abstract method. Because the default method is not an abstract method, you can also add a default method to your functional interface.
We can treat lambda expression as any interface type that contains only one abstract method to ensure that your interface must meet this requirement. You only need to add @ functional interface annotation to your interface. The compiler will report an error if it finds that there are more than one abstract method on the interface with this annotation.
Examples are as follows:
The code is as follows:
@FunctionalInterface
interface Converter<F, T> {
T convert(F from);
}
Converter<String, Integer> converter = (from) -> Integer.valueOf(from);
Integer converted = converter.convert("123");
System.out.println(converted); // 123
Note that if @ FunctionalInterface is not specified, the above code is also correct.
Translator's note: mapping lambda expressions to a single method interface has been implemented in other languages before Java 8, such as the Rhino JavaScript interpreter. If a function parameter receives a single method interface and you pass a function, the Rhino interpreter will automatically act as an adapter from an instance of a single interface to a function, A typical application scenario is org w3c. dom. events. The second parameter of addEventListener of EventTarget is EventListener.
4, Method and constructor references
The code in the previous section can also be represented by static method references:
The code is as follows:
Converter<String, Integer> converter = Integer::valueOf;
Integer converted = converter.convert("123");
System.out.println(converted); // 123
Java 8 allows you to use the:: keyword to pass method or constructor references. The above code shows how to reference a static method. We can also reference an object's method:
The code is as follows:
converter = something::startsWith;
String converted = converter.convert("Java");
System.out.println(converted); // "J"
Next, let's look at how constructors are referenced using the:: keyword. First, we define a simple class containing multiple constructors:
The code is as follows:
class Person {
String firstName;
String lastName;
Person() {}
Person(String firstName, String lastName) {
this.firstName = firstName;
this.lastName = lastName;
}
}
Next, we specify an object factory interface to create the Person object:
The code is as follows:
interface PersonFactory<P extends Person> {
P create(String firstName, String lastName);
}
Here we use constructor references to associate them instead of implementing a complete factory:
The code is as follows:
PersonFactory<Person> personFactory = Person::new;
Person person = personFactory.create("Peter", "Parker");
We only need to use Person::new to obtain the reference of the Person class constructor, and the Java compiler will automatically generate the reference according to the Person factory The signature of the Create method to select the appropriate constructor.
5, Lambda scope
Accessing outer scopes in lambda expressions is similar to accessing anonymous objects in older versions. You can directly access external local variables marked final, or instance fields and static variables.
6, Accessing local variables
We can directly access the local variables of the outer layer in the lambda expression:
The code is as follows:
final int num = 1; Converter<Integer, String> stringConverter = (from) -> String.valueOf(from + num); stringConverter.convert(2); // 3
However, unlike anonymous objects, the variable num here does not need to be declared final. The code is also correct:
The code is as follows:
int num = 1; Converter<Integer, String> stringConverter = (from) -> String.valueOf(from + num); stringConverter.convert(2); // 3
However, the num here must not be modified by the following code (i.e. implicit with final semantics). For example, the following cannot be compiled:
The code is as follows:
int num = 1; Converter<Integer, String> stringConverter = (from) -> String.valueOf(from + num); num = 3;
Attempting to modify num in a lambda expression is also not allowed.
7, Accessing object fields and static variables
Different from local variables, lambda can read and write the fields of instances and static variables. This behavior is consistent with anonymous objects:
The code is as follows:
class Lambda4 {
static int outerStaticNum;
int outerNum;
void testScopes() {
Converter<Integer, String> stringConverter1 = (from) -> {
outerNum = 23;
return String.valueOf(from);
};
Converter<Integer, String> stringConverter2 = (from) -> {
outerStaticNum = 72; return String.valueOf(from);
};
}
}
8, Default method for provider
Remember the formula example in the first section? The interface formula defines a default method sqrt, which can be accessed directly by formula instances, including anonymous objects, but not in Lambda expressions. The default method cannot be accessed in Lambda expression, and the following code cannot be compiled:
The code is as follows:
Formula formula = (a) -> sqrt( a * 100); Built-in Functional Interfaces
JDK 1.8 API contains many built-in functional interfaces, such as Comparator or Runnable interfaces commonly used in old Java. These interfaces have added @ functional interface annotation to be used on lambda. Java 8 API also provides many new functional interfaces to make work more convenient. Some interfaces come from Google Guava library. Even if you are familiar with these interfaces, it is necessary to see how they are extended to lambda.
Predict interface
The predict interface has only one parameter and returns boolean type. The interface contains a variety of default methods to combine predict into other complex logic (such as and, or, non):
The code is as follows:
Predicate<String> predicate = (s) -> s.length() > 0;
predicate.test("foo"); // true predicate.negate().test("foo"); // false
Predicate<Boolean> nonNull = Objects::nonNull;
Predicate<Boolean> isNull = Objects::isNull;
Predicate<String> isEmpty = String::isEmpty;
Predicate<String> isNotEmpty = isEmpty.negate();
Function interface
The Function interface has a parameter and returns a result, with some default methods (compose, and then) that can be combined with other functions:
The code is as follows:
Function<String, Integer> toInteger = Integer::valueOf;
Function<String, String> backToString = toInteger.andThen(String::valueOf);
backToString.apply("123"); // "123"
Supplier interface the supplier interface returns a value of any template. Unlike the Function interface, this interface does not have any parameters
The code is as follows:
Supplier<Person> personSupplier = Person::new; personSupplier.get(); // new Person
Consumer interface the consumer interface represents an operation performed on a single parameter.
The code is as follows:
Consumer<Person> greeter = (p) -> System.out.println("Hello, " + p.firstName); greeter.accept(new Person("Luke", "Skywalker"));
Comparator interface comparator is a classic interface in old Java. Java 8 adds a variety of default methods on it:
The code is as follows:
Comparator<Person> comparator = (p1, p2) -> p1.firstName.compareTo(p2.firstName);
Person p1 = new Person("John", "Doe");
Person p2 = new Person("Alice", "Wonderland");
comparator.compare(p1, p2); // > 0 comparator.reversed().compare(p1, p2); // < 0
Optional interface
Optional is not a function but an interface. It is an auxiliary type used to prevent NullPointerException exceptions. This is an important concept to be used in the next session. Now let's take a brief look at what this interface can do:
Optional is defined as a simple container whose value may or may not be null. Before Java 8, generally a function should return a non empty object, but occasionally it may return null. In Java 8, it is not recommended that you return null but optional.
The code is as follows:
Optional<String> optional = Optional.of("bam");
optional.isPresent();
// true optional.get();
// "bam" optional.orElse("fallback"); // "bam"
optional.ifPresent((s) -> System.out.println(s.charAt(0))); // "b"
Stream interface
java.util.Stream represents a sequence of operations that can be applied to a group of elements. Stream operations are divided into intermediate operations or final operations. The final operation returns a specific type of calculation result, while the intermediate operation returns the stream itself, so you can string multiple operations in turn. To create a stream, you need to specify a data source, such as Java util. Subclass of collection, List or Set, Map does not support. Stream operations can be performed serially or in parallel.
First, let's see how Stream is used. First, create the data List used in the instance code:
The code is as follows:
List<String> stringCollection = new ArrayList<>();
stringCollection.add("ddd2");
stringCollection.add("aaa2");
stringCollection.add("bbb1");
stringCollection.add("aaa1");
stringCollection.add("bbb3");
stringCollection.add("ccc");
stringCollection.add("bbb2");
stringCollection.add("ddd1");
Java 8 extends the collection class through collection Stream () or collection Parallelstream() to create a stream. The following sections explain common stream operations in detail:
Filter filter
Filtering is performed through a predicate interface, and only qualified elements are retained. This operation is an intermediate operation, Therefore, we can apply other Stream operations (such as forEach) to the filtered results. forEach requires a function to execute the filtered elements in turn. forEach is the final operation, so we cannot perform other Stream operations after forEach.
The code is as follows:
stringCollection.stream().filter((s) -> s.startsWith("a")).forEach(System.out::println);
// "aaa2", "aaa1"
Sort sort
Sorting is an intermediate operation that returns the sorted Stream. If you do not specify a custom Comparator, the default sort will be used.
The code is as follows:
stringCollection.stream().sorted().filter((s) -> s.startsWith("a")) .forEach(System.out::println);
// "aaa1", "aaa2"
It should be noted that sorting only creates a sorted Stream without affecting the original data source. After sorting, the original data stringCollection will not be modified:
The code is as follows:
System.out.println(stringCollection); // ddd2, aaa2, bbb1, aaa1, bbb3, ccc, bbb2, ddd1
The map mapping intermediate operation map will convert the elements into other objects in turn according to the specified Function interface. The following example shows how to convert a string to an uppercase string. You can also convert objects into other types through map. The Stream type returned by map is determined by the return value of the Function passed in by map.
The code is as follows:
stringCollection.stream().map(String::toUpperCase).sorted((a, b) -> b.compareTo(a)) .forEach(System.out::println); // "DDD2", "DDD1", "CCC", "BBB3", "BBB2", "AAA2", "AAA1"
Match match
Stream provides a variety of matching operations that allow you to detect whether a specified Predicate matches the entire stream. All matching operations are final and return a boolean value.
The code is as follows:
boolean anyStartsWithA = stringCollection.stream().anyMatch((s) -> s.startsWith("a"));
System.out.println(anyStartsWithA); // true
boolean allStartsWithA = stringCollection.stream().allMatch((s) -> s.startsWith("a"));
System.out.println(allStartsWithA); // false
boolean noneStartsWithZ = stringCollection.stream().noneMatch((s) -> s.startsWith("z"));
System.out.println(noneStartsWithZ); // true
Count is a final operation that returns the number of elements in the Stream. The return value type is long.
The code is as follows:
long startsWithB = stringCollection.stream().filter((s) -> s.startsWith("b")) .count();
System.out.println(startsWithB); // 3
Reduce protocol
This is a final operation, which allows multiple elements in the stream to be reduced to one element through the specified function. The results after exceeding the specification are represented through the Optional interface:
The code is as follows:
Optional<String> reduced = stringCollection.stream().sorted().reduce((s1, s2) -> s1 + "#" + s2); reduced.ifPresent(System.out::println); // "aaa1#aaa2#bbb1#bbb2#bbb3#ccc#ddd1#ddd2"
Parallel Streams
As mentioned earlier, there are two kinds of streams: serial and parallel. The operations on the serial Stream are completed successively in one thread, while the parallel Stream is executed simultaneously on multiple threads.
The following example shows how parallel streams can improve performance:
First, we create a large table without duplicate elements:
The code is as follows:
int max = 1000000;
List<String> values = new ArrayList<>(max);
for (int i = 0; i < max; i++) {
UUID uuid = UUID.randomUUID();
values.add(uuid.toString());
}
Then we calculate how long it takes to sort this Stream. Serial sorting:
The code is as follows:
long t0 = System.nanoTime();
long count = values.stream().sorted().count();
System.out.println(count);
long t1 = System.nanoTime();
long millis = TimeUnit.NANOSECONDS.toMillis(t1 - t0);
System.out.println(String.format("sequential sort took: %d ms", millis));
//Serial time: 899 ms
Parallel sort:
The code is as follows:
long t0 = System.nanoTime();
long count = values.parallelStream().sorted().count();
System.out.println(count);
long t1 = System.nanoTime();
long millis = TimeUnit.NANOSECONDS.toMillis(t1 - t0); System.out.println(String.format("parallel sort took: %d ms", millis));
//Parallel sorting takes 472 ms. the above two codes are almost the same, but the parallel version is as fast as 50%. The only change to be made is to change stream() to parallelStream().
Map
As mentioned earlier, the Map type does not support stream, but Map provides some new and useful methods to deal with some daily tasks.
The code is as follows:
Map<Integer, String> map = new HashMap<>();
for (int i = 0; i < 10; i++) {
map.putIfAbsent(i, "val" + i);
}
map.forEach((id, val) -> System.out.println(val));
The above code is easy to understand. putIfAbsent does not need us to do additional existence checks, and forEach receives a Consumer interface to operate each key value pair in the map.
The following example shows other useful functions on the map:
The code is as follows:
map.computeIfPresent(3, (num, val) -> val + num); map.get(3); // val33 map.computeIfPresent(9, (num, val) -> null); map.containsKey(9); // false map.computeIfAbsent(23, num -> "val" + num); map.containsKey(23); // true map.computeIfAbsent(3, num -> "bam"); map.get(3); // val33
Next, we show how to delete an item whose key values all match in the Map:
The code is as follows:
map.remove(3, "val3"); map.get(3); // val33 map.remove(3, "val33"); map.get(3); // null
Another useful method:
The code is as follows:
map.getOrDefault(42, "not found"); // not found
It is also easy to merge the elements of the Map:
The code is as follows:
map.merge(9, "val9", (value, newValue) -> value.concat(newValue)); map.get(9); // val9 map.merge(9, "concat", (value, newValue) -> value.concat(newValue)); map.get(9); // val9concat
What Merge does is insert if the key name does not exist. Otherwise, Merge the values corresponding to the original key and re insert them into the map.
9, Date API
Java 8 in package Java Time contains a new set of time and date APIs. The new date API is similar to the open source joda time library, but not exactly the same. The following examples show some of the most important parts of the new API:
Clock clock
Clock class provides a method to access the current date and time. Clock is time zone sensitive and can be used to replace system Currenttimemillis() to get the current number of microseconds. A specific point in time can also be represented by the Instant class, which can also be used to create old Java util. Date object.
The code is as follows:
Clock clock = Clock.systemDefaultZone(); long millis = clock.millis(); Instant instant = clock.instant(); Date legacyDate = Date.from(instant); // legacy java.util.Date
Timezones time zone
In the new API, the time zone is represented by ZoneId. The time zone can be easily obtained by using the static method of. The time zone defines the time difference to UTS time, which is extremely important when converting from Instant time point object to local date object.
The code is as follows:
System.out.println(ZoneId.getAvailableZoneIds());
// prints all available timezone ids
ZoneId zone1 = ZoneId.of("Europe/Berlin");
ZoneId zone2 = ZoneId.of("Brazil/East");
System.out.println(zone1.getRules());
System.out.println(zone2.getRules());
// ZoneRules[currentStandardOffset=+01:00]
// ZoneRules[currentStandardOffset=-03:00]
LocalTime local time
LocalTime defines a time without time zone information, such as 10 p.m. or 17:30:15. The following example creates two local times using the time zone created by the previous code. Then compare the time and calculate the time difference between the two times in hours and minutes:
The code is as follows:
LocalTime now1 = LocalTime.now(zone1); LocalTime now2 = LocalTime.now(zone2); System.out.println(now1.isBefore(now2)); // false long hoursBetween = ChronoUnit.HOURS.between(now1, now2); long minutesBetween = ChronoUnit.MINUTES.between(now1, now2); System.out.println(hoursBetween); // -3 System.out.println(minutesBetween); // -239
LocalTime provides a variety of factory methods to simplify object creation, including parsing time strings.
The code is as follows:
LocalTime late = LocalTime.of(23, 59, 59);
System.out.println(late); // 23:59:59
DateTimeFormatter germanFormatter = DateTimeFormatter.ofLocalizedTime(FormatStyle.SHORT).withLocale(Locale.GERMAN);
LocalTime leetTime = LocalTime.parse("13:37", germanFormatter); System.out.println(leetTime); // 13:37
LocalDate local date
Local Date indicates an exact Date, such as March 11, 2014. The object value is immutable and is basically consistent with LocalTime. The following example shows how to add or subtract day / month / year to a Date object. Also note that these objects are immutable, and the operation always returns a new instance.
The code is as follows:
LocalDate today = LocalDate.now(); LocalDate tomorrow = today.plus(1, ChronoUnit.DAYS); LocalDate yesterday = tomorrow.minusDays(2); LocalDate independenceDay = LocalDate.of(2014, Month.JULY, 4); DayOfWeek dayOfWeek = independenceDay.getDayOfWeek(); System.out.println(dayOfWeek); // FRIDAY parsing a LocalDate type from a string is as simple as parsing LocalTime:
The code is as follows:
DateTimeFormatter germanFormatter = DateTimeFormatter.ofLocalizedDate(FormatStyle.MEDIUM) .withLocale(Locale.GERMAN);
LocalDate xmas = LocalDate.parse("24.12.2014", germanFormatter); System.out.println(xmas); // 2014-12-24
LocalDateTime local datetime
LocalDateTime represents both time and date, which is equivalent to merging the contents of the first two sections into one object. Like LocalTime and LocalDate, LocalDateTime is immutable. LocalDateTime provides some methods to access specific fields.
The code is as follows:
LocalDateTime sylvester = LocalDateTime.of(2014, Month.DECEMBER, 31, 23, 59, 59); DayOfWeek dayOfWeek = sylvester.getDayOfWeek(); System.out.println(dayOfWeek); // WEDNESDAY Month month = sylvester.getMonth(); System.out.println(month); // DECEMBER long minuteOfDay = sylvester.getLong(ChronoField.MINUTE_OF_DAY); System.out.println(minuteOfDay); // 1439
As long as the time zone information is attached, it can be converted into a point in time Instant object, which can be easily converted into old Java util. Date.
The code is as follows:
Instant instant = sylvester.atZone(ZoneId.systemDefault()).toInstant(); Date legacyDate = Date.from(instant); System.out.println(legacyDate); // Wed Dec 31 23:59:59 CET 2014
Formatting LocalDateTime is the same as formatting time and date. In addition to using the predefined format, we can also define the format ourselves:
The code is as follows:
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("MMM dd, yyyy - HH:mm");
LocalDateTime parsed = LocalDateTime.parse("Nov 03, 2014 - 07:13", formatter); String string = formatter.format(parsed);
System.out.println(string); // Nov 03, 2014 - 07:13
And Java text. Unlike numberformat, the new DateTimeFormatter is immutable, so it is thread safe.
10, Annotation annotation
Multiple annotations are supported in Java 8. Let's take a look at an example to understand what it means. First, define a wrapper class Hints annotation to place a group of specific Hints annotations:
The code is as follows:
@interface Hints {
Hint[] value();
}
@Repeatable(Hints.class)
@interface Hint {
String value();
}
Java 8 allows us to use the same type of annotation multiple times. We only need to mark @ Repeatable for the annotation.
Example 1: use wrapper class as container to store multiple annotations (old method)
The code is as follows:
@Hints({@Hint("hint1"), @Hint("hint2")})
class Person {}
Example 2: using multiple annotations (new method)
The code is as follows:
@Hint("hint1") @Hint("hint2")
class Person {}
In the second example, the java compiler will implicitly help you define the @ Hints annotation. Understanding this will help you use reflection to obtain this information:
The code is as follows:
Hint hint = Person.class.getAnnotation(Hint.class); System.out.println(hint); // null Hints hints1 = Person.class.getAnnotation(Hints.class); System.out.println(hints1.value().length); // 2 Hint[] hints2 = Person.class.getAnnotationsByType(Hint.class); System.out.println(hints2.length); // 2
Even if we do not define @ Hints annotation on the Person class, we can still obtain @ Hints annotation through getAnnotation(Hints.class). A more convenient way is to directly obtain all @ Hint annotations by using getAnnotationsByType. In addition, Java 8 annotations are added to two new target s:
The code is as follows:
@Target({ElementType.TYPE_PARAMETER, ElementType.TYPE_USE})
@interface MyAnnotation {}
I've written about the new features of Java 8. There must be more features to explore. There are many useful things in JDK 1.8, such as arrays Parallelsort, stampedlock, completable future, etc.
What are the differences between rewriting and overloading in Java
Method overloading and rewriting are ways to realize polymorphism. The difference is that the former realizes compile time polymorphism, while the latter realizes run-time polymorphism. Overloading occurs in a class, If a method with the same name has different parameter lists (different parameter types, different number of parameters, or both), it is regarded as overloaded; rewriting occurs between a child class and a parent class. Rewriting requires that the child class rewritten method and the parent class rewritten method have the same return type, which is better accessible than the parent class rewritten method, and cannot declare more exceptions than the parent class rewritten method (Richter substitution principle). Overloads have no special requirements for return types.
Rules for method overloading:
1. The method names are consistent, and the order, type and number of parameters in the parameter list are different.
2. Overloading has nothing to do with the return value of the method and exists in the parent and child classes.
3. Different exceptions and modifiers can be thrown
Rule for method override:
1. The parameter list must be completely consistent with that of the overridden method, and the return type must be completely consistent with that of the overridden method.
2. Construction methods cannot be overridden, methods declared final cannot be overridden, and methods declared static cannot be overridden, but can be declared again.
3. The access permission cannot be lower than that of the overridden method in the parent class.
4. The overridden method can throw any non mandatory exception (UncheckedException, also known as non runtime exception), regardless of whether the overridden method throws an exception. However, the overridden method cannot throw a new mandatory exception or a broader mandatory exception than that declared by the overridden method, and vice versa.

What are the differences between interfaces and abstract classes
Different:
Abstract class:
1. Constructors can be defined in abstract classes
2. There can be abstract methods and concrete methods
3. All members in the interface are public
4. Member variables can be defined in abstract classes
5. Classes with abstract methods must be declared as abstract classes, and abstract classes do not necessarily have abstract methods
6. Abstract classes can contain static methods
7. A class can only inherit one abstract class
Interface:
1. Constructor cannot be defined in the interface
2. All methods are abstract methods
3. Members in an abstract class can be private, default, protected, or public
4. The member variables defined in the interface are actually constants
5. Static methods are not allowed in the interface
6. A class can implement multiple interfaces
Same:
1. Cannot instantiate
2. Abstract classes and interface types can be used as reference types
3. If a class inherits an abstract class or implements an interface, all of its abstract methods need to be implemented, otherwise the class still needs to be declared as an abstract class
How to declare that a class will not be inherited, and what scenarios will it be used
If a class is finally modified, it cannot have subclasses and cannot be inherited by other classes. If all methods in a class do not need to be overridden and the current class has no subclasses, you can use the final modified class.
What are the differences between = = and equals in Java
The biggest difference between equals and = = is that one is a method and the other is an operator.
==: if the comparison object is a basic data type, the comparison is whether the values are equal; If you are comparing reference data types, you are comparing whether the address values of the objects are equal.
equals(): used to compare whether the contents of two objects of the method are equal.
Note: the equals method cannot be used for variables of basic data type. If the equals method is not overridden, the address of the object pointed to by the variable of reference type will be compared.
Differences and usage scenarios of String, StringBuffer and StringBuilder
The Java platform provides two types of strings: String and StringBuffer/StringBuilder, which can store and manipulate strings. The differences are as follows.
1) String is a read-only string, which means that the string content referenced by string cannot be changed. Beginners may have this misunderstanding:
String str = "abc"; str = "bcd";
As above, the string str can be changed! In fact, str is just a reference object, which points to a string object "abc". The first
The meaning of the two lines of code is to make str point to a new string "bcd" object again, and the "abc" object has not changed, but the object has become an unreachable object.
2) The string object represented by StringBuffer/StringBuilder can be modified directly.
3) StringBuilder is introduced in Java 5. Its method is exactly the same as that of StringBuffer. The difference is that it is used in a single threaded environment. Because all its methods are not synchronized, its efficiency is theoretically higher than that of StringBuffer.
Several implementation methods of Java agent
The first one: static proxy, which can only represent some classes or methods statically. It is not recommended. It has weak functions but simple coding
The second is dynamic Proxy, including Proxy proxy and CGLIB dynamic Proxy
Proxy proxy is a dynamic proxy built into JDK
Features: it is interface oriented and does not need to import dynamic agents that depend on three parties. It can enhance multiple different interfaces. When reading annotations through reflection, only the annotations on the interface can be read
Principle: interface oriented, only the methods defined by the implementation class in the implementation interface can be enhanced
Define interfaces and implementations
package com.proxy;
public interface UserService {
public String getName(int id);
public Integer getAge(int id);
}
package com.proxy;
public class UserServiceImpl implements UserService {
@Override
public String getName(int id) {
System.out.println("------getName------");
return "riemann";
}
@Override
public Integer getAge(int id) {
System.out.println("------getAge------");
return 26;
}
}
package com.proxy;
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
public class MyInvocationHandler implements InvocationHandler {
public Object target;
MyInvocationHandler() {
super();
}
MyInvocationHandler(Object target) {
super();
this.target = target;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
if ("getName".equals(method.getName())) {
System.out.println("++++++before " + method.getName() + "++++++");
Object result = method.invoke(target, args);
System.out.println("++++++after " + method.getName() + "++++++");
return result;
} else {
Object result = method.invoke(target, args);
return result;
}
}
}
package com.proxy;
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Proxy;
public class Main1 {
public static void main(String[] args) {
UserService userService = new UserServiceImpl();
InvocationHandler invocationHandler = new MyInvocationHandler(userService);
UserService userServiceProxy = (UserService) Proxy.newProxyInstance(userService.getClass().getClassLoader(),
userService.getClass().getInterfaces(),invocationHandler);
System.out.println(userServiceProxy.getName(1));
System.out.println(userServiceProxy.getAge(1));
}
}
CGLIB dynamic proxy
Features: dynamic proxy for parent class needs to import third-party dependencies
Principle: facing the parent class, the underlying class inherits the parent class and rewrites the method to realize enhancement
Proxy and CGLIB are very important proxy patterns, which are the two main ways to realize the bottom layer of spring AOP
Core classes of CGLIB:
net.sf.cglib.proxy.Enhancer – main enhancement classes
net.sf.cglib.proxy.MethodInterceptor - the main method interception class. It is a sub interface of the Callback interface and needs to be implemented by the user
net.sf.cglib.proxy.MethodProxy – Java. Proxy of JDK lang.reflect. The proxy class of method class can easily call the source object method, such as:
Object o = methodProxy.invokeSuper(proxy, args);// Although the first parameter is the proxied object, there will be no dead loop problem.
net.sf.cglib.proxy.MethodInterceptor interface is the most common callback type. It is often used by agent-based AOP to intercept method calls. This interface defines only one method
public Object intercept(Object object, java.lang.reflect.Method method,
Object[] args, MethodProxy proxy) throws Throwable;
The first parameter is the proxy object, and the second and third parameters are the intercepted method and method parameters respectively. The original method may be through the use of Java lang.reflect. Method object, or use net sf. cglib. proxy. Methodproxy object call. net.sf.cglib.proxy.MethodProxy is usually preferred because it is faster.
package com.proxy.cglib;
import net.sf.cglib.proxy.MethodInterceptor;
import net.sf.cglib.proxy.MethodProxy;
import java.lang.reflect.Method;
public class CglibProxy implements MethodInterceptor {
@Override
public Object intercept(Object o, Method method, Object[] args, MethodProxy methodProxy) throws Throwable {
System.out.println("++++++before " + methodProxy.getSuperName() + "++++++");
System.out.println(method.getName());
Object o1 = methodProxy.invokeSuper(o, args);
System.out.println("++++++before " + methodProxy.getSuperName() + "++++++");
return o1;
}
}
package com.proxy.cglib;
import com.test3.service.UserService;
import com.test3.service.impl.UserServiceImpl;
import net.sf.cglib.proxy.Enhancer;
public class Main2 {
public static void main(String[] args) {
CglibProxy cglibProxy = new CglibProxy();
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(UserServiceImpl.class);
enhancer.setCallback(cglibProxy);
UserService o = (UserService)enhancer.create();
o.getName(1);
o.getAge(1);
}
}
How to use hashcode and equals
equals() comes from Java Lang. Object, which is used to simply verify the equality of two objects. The default implementation defined in the Object class only checks the Object references of two objects to verify their equality. By rewriting this method, you can customize the new rules for verifying Object equality. If you use ORM to process some objects, you should ensure that getter s and setter s are used in hashCode() and equals() objects instead of directly referring to member variables
hashCode() is derived from Java Lang. Object, which is used to obtain the unique integer (hash code) of a given Object. When the Object needs to be stored in a data structure such as a hash table, this integer is used to determine the location of the bucket. By default, the hashCode() method of an Object returns an integer representation of the memory address where the Object is located. hashCode() is used by HashTable, HashMap, and HashSet. By default, the hashCode() method of the Object class returns the number of the memory address stored by the Object.
Hash hash algorithm, so that the speed of finding a record in the hash table becomes O(1) Each record has its own hashcode, and the hash algorithm places the record in the appropriate position according to the hashcode When searching for a record, first quickly locate the location of the record through hashcode Then compare whether they are equal by equals. If hashcode is not found, equal is not allowed, and the element does not exist in the hash table; Even if it is found, it only needs to execute equal of several elements with the same hashcode. If it is not equal, it still does not exist in the hash table.
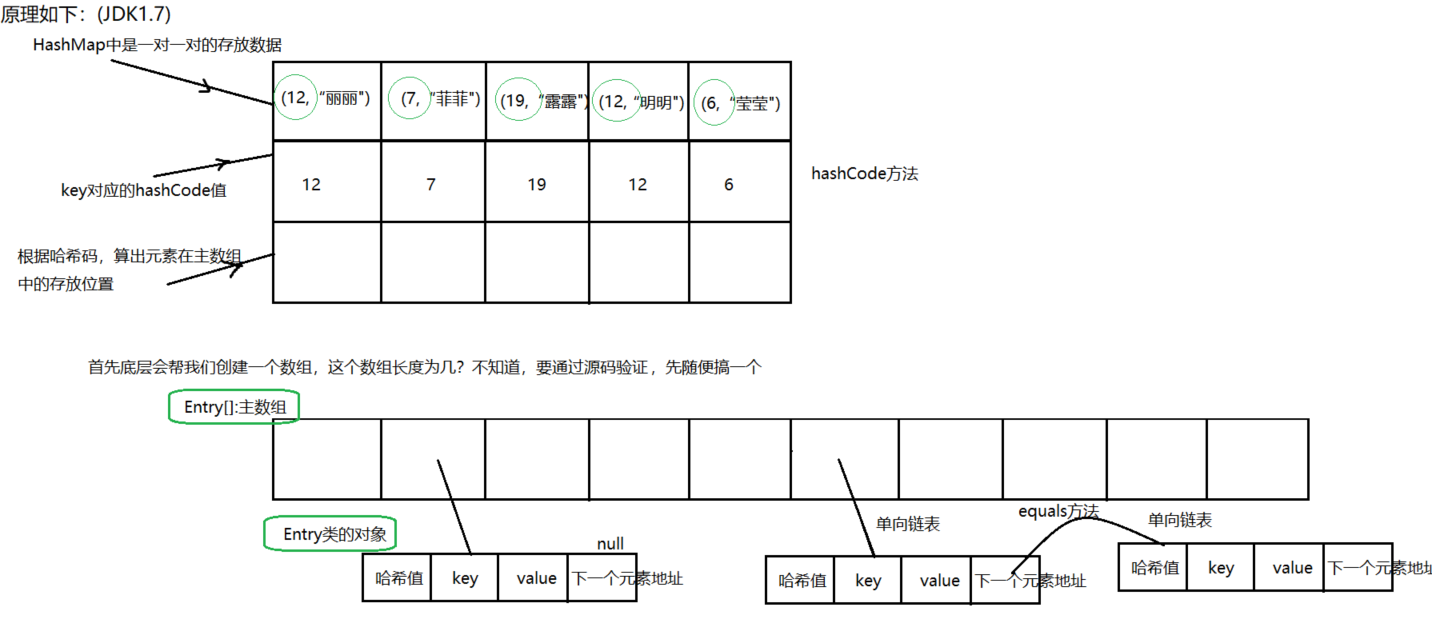
Differences between HashMap and HashTable and their underlying implementation
Comparison between HashMap and HashTable
- HashTable thread synchronization, HashMap non thread synchronization.
- HashTable does not allow < key, value > has empty value, HashMap allows < key, value > has empty value.
- HashTable uses Enumeration and HashMap uses Iterator.
- The default size of hash array in HashTable is 11, and the increase method is old*2+1. The default size of hash array in HashMap is 16, and the increase method is exponential times of 2.
- HashMap jdk1.8 list + linked list jdk1 After 8, the list + linked list is transformed into a red black tree when the length of the linked list reaches 8
- The HashMap linked list inserts nodes in Java 1 7, the header insertion method is used to insert the linked list node. Java1. In 8, it becomes tail interpolation (to prevent capacity expansion from forming a closed loop)
- Java1. In the hash() of 8, the high bit (the first 16 bits) of the hash value is involved in the modulo operation, which enhances the uncertainty of the calculation result and reduces the probability of hash collision.
HashMap expansion Optimization:
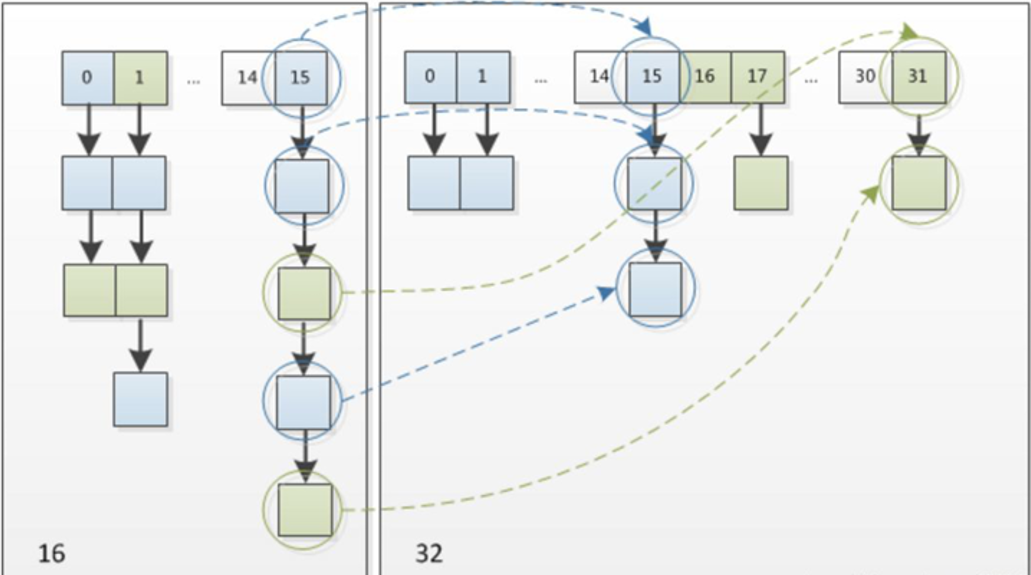
After capacity expansion, 1.7 rehash the elements to calculate the original position of each element in the hash table after capacity expansion. 1.8 with the double capacity expansion mechanism, the element does not need to recalculate the position
During capacity expansion, JDK 1.8 does not recalculate the hash value of each element as JDK 1.7, but determines whether the element needs to be moved through the high-order operation * * (e.hash & oldcap). For example, the information of key1 is as follows:

The higher bit of the result obtained by using e.hash & oldcap is 0. When the result is 0, it means that the position of the element will not change during capacity expansion, and the key 2 information is as follows

The higher bit is 1. When the result is 1, it indicates that the position of the element has changed during capacity expansion. The new subscript position is equal to the original subscript position + the original array length hashmap, * * it is not necessary to recalculate the position as in 1.7
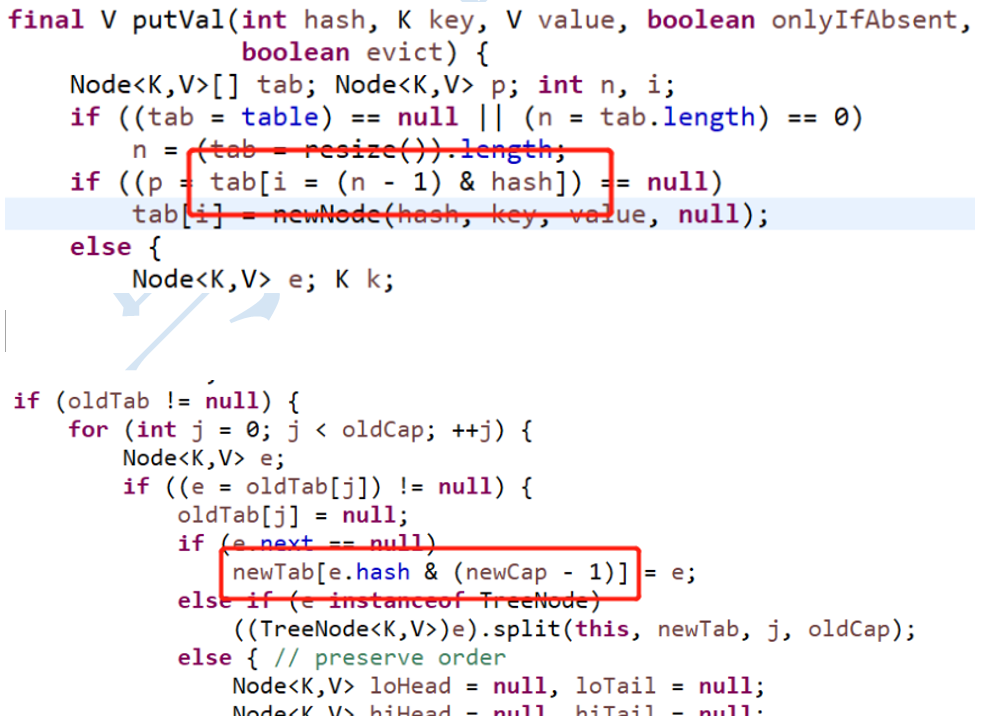
Why is hashmap twice as large?
View source code
When storing an element, there is an algorithm of (n-1) & hash and hash & (newcap-1) at the position of the element. Here, an & bit operator is used
When the capacity of HashMap is 16, its binary is 10000, and the binary of (n-1) is 01111. The calculation results of hash value are as follows
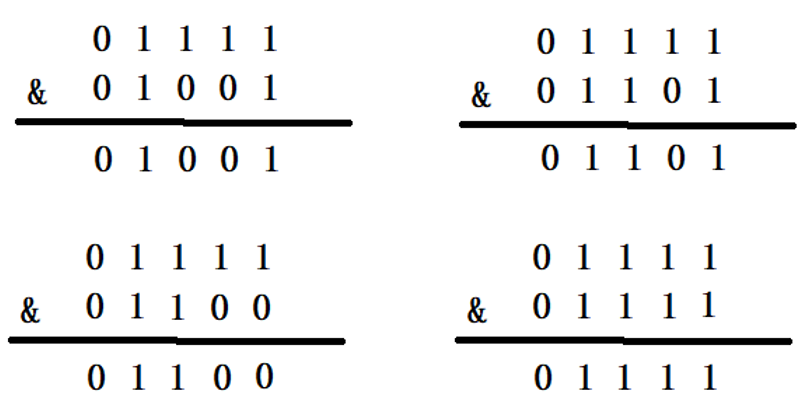
Let's take a look at the case where the capacity of HashMap is not the nth power of 2. When the capacity is 10, the binary is 01010, and the binary of (n-1) is 01001. Add the same element to it, and the result is
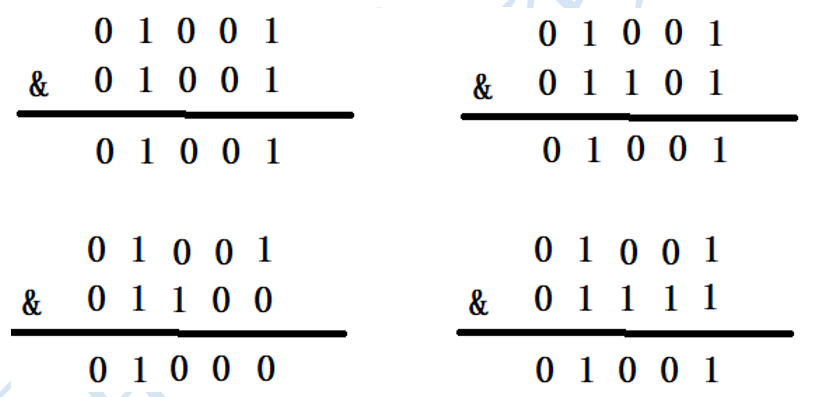
It can be seen that three different elements have gone through & operation and obtained the same result, resulting in serious hash collision
Only when the value of n is the nth power of 2 and the & bit operation is carried out, can we only look at the last few bits without calculating them all
hashmap thread safe way?
HashMap is not thread safe, and it often needs some methods to avoid when writing programs In fact, JDK native provides two methods to make HashMap support thread safety
Method 1: through collections Synchronizedmap () returns a new Map, which is thread safe This requires you to get used to interface based programming, because the return is not a HashMap, but an implementation of a Map
Method 2: rewrite the HashMap. For details, see Java util. concurrent. ConcurrentHashMap. This method is a great improvement over method 1
Method 1 features:
Via collections Synchronizedmap () encapsulates all unsafe HashMap methods, including toString and hashcode There are two key points of encapsulation: 1) the classic synchronized is used for mutual exclusion, 2) the proxy mode is used, and a new class is created, which also implements the Map interface On the HashMap, synchronized locks objects, so the first application gets the lock, and other threads will block and wait for wake-up Advantages: the code implementation is very simple and easy to understand Disadvantages: from the perspective of locking, method 1 directly uses the locking method, which basically locks the largest possible code block Poor performance
Method 2 features:
The HashMap is rewritten. The major changes are as follows A new locking mechanism is used to split the HashMap into multiple independent blocks, which reduces the possibility of lock conflict in the case of high concurrency. NonfairSync.com is used This feature calls CAS instructions to ensure atomicity and mutual exclusion If multiple threads operate on the same segment, only one thread will be run
Advantages: there are few mutually exclusive code segments, and the performance will be better ConcurrentHashMap divides the whole Map into multiple blocks, which greatly reduces the probability of lock collision and has better performance Disadvantages: cumbersome code
Java exception handling
Java handles exceptions through object-oriented methods. Once the method throws an exception, The system automatically finds the appropriate Exception Handler according to the exception object (Exception Handler) to handle the exception, classify various exceptions, and provide a good interface. In Java, each exception is an object, which is an instance of the Throwable class or its subclass. When an exception occurs in a method, an exception object will be thrown. The object contains exception information, which can be caught by the method calling the object Exception and can be handled.
Java exception handling is implemented through five Keywords: try, catch, throw, throws and finally.
In Java applications, exception handling mechanisms are divided into declaring exceptions, throwing exceptions and catching exceptions.
The difference between throw and throws:
(1) Different locations:
throw: method internal
throws: method signature, method declaration
(2) Different contents:
throw + exception object (check exception, runtime exception)
throws + type of exception (multiple types can be used, spliced)
(3) Different functions:
throw: the source of the exception, creating the exception.
throws: at the declaration of the method, tell the caller of the method that these exceptions I declared may appear in the method. Then the caller processes the exception: either processing it by oneself or continuing to throw the exception out.
1.throws declaration exception
Usually, you should catch those exceptions that know how to handle and pass on those exceptions that don't know how to handle. When passing an exception, you can use the throws keyword at the method signature to declare the exception that may be thrown. Note that non check exceptions (Error, RuntimeException, or their subclasses) cannot use the throws keyword to declare the exception to be thrown.
If a compilation time exception occurs in a method, it needs to be handled by try catch / throws, otherwise it will lead to compilation errors
2.throw throw exception
If you think you can't solve some exception problems and don't need to be handled by the caller, you can throw an exception. Throw keyword is used to throw an exception of Throwable type inside a method. Any Java code can throw an exception through the throw statement.
3.trycatch catch exception
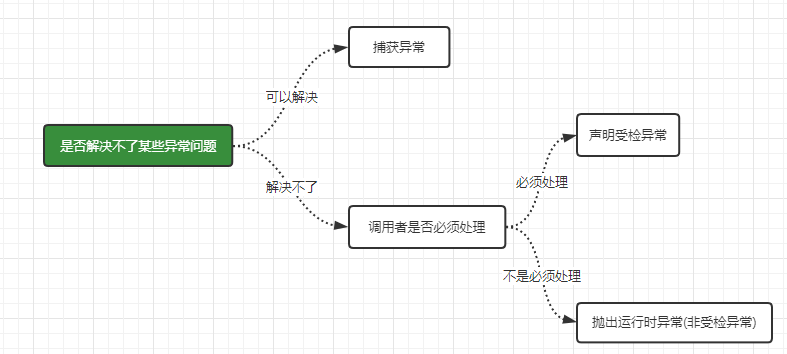
The program usually does not report errors before running, but some unknown errors may occur after running, but it does not want to throw them directly to the upper level, so it needs to catch exceptions in the form of try... Catch... And then deal with them according to different exceptions. How to select exception type
You can choose whether to catch an exception, declare an exception or throw an exception according to the following figure
How to apply custom exceptions in production
Although Java provides rich exception handling classes, custom exceptions are often used in projects. The main reason is that the exception classes provided by Java still can not meet the actual needs in some cases. For example:
1. Some errors in the system conform to Java syntax, but do not conform to business logic.
2. In layered software architecture, exceptions at other levels of the system are usually captured and handled uniformly at the presentation layer.