Java Learning Notes: January 9, 2022 (second)
Summary: This note mainly records the basic knowledge of Classes in Chapter 4, which was learned on January 9, and the significance of accessors and accessors in multithreading.
1. Multithreading
Multithreading refers to the simultaneous execution of multiple tasks within a program when each task is executed as a thread. Multi-threading can effectively improve the efficiency of operation. When the CPU has a strong multi-threading capability, the multi-threading capability of the computer will also be improved. That is, you can open multiple QQ Qs or DNF s at one time. Many studios will emphasize the multi-threading capability of the computer. CPU is divided into multiple cores. I have previously opened a core for a dual-core CPU and found that there really are two silicon crystal chips inside. Now the CPUs with eight cores, sixteen cores or even dozens of cores do not know what is inside. They may have been integrated into one chip. However, the cores and cores are still independent. Each core can run a thread at the same time. With more cores, multithreaded parallelism can be achieved.
However, we need to note that although a CPU can achieve multi-threaded parallelism, a core in a CPU can't. A core in a CPU can only run one program at a time, so when we use a CPU with only one core, its interior does not really allow threads to parallelism, but uses a virtualized method. Make the program appear to be executing concurrently. Of course, this can happen even with multicore CPUs when there are too many threads in the system.
Thus, when the number of bus threads is greater than the number of CPU cores, each core of the CPU will have to rotate in time slices to execute different threads separately over a period of time, thereby guaranteeing that the threads will all finish after a period of time, thus making them appear to be executed concurrently. This way of making tasks execute in turn on the CPU core is to specify a reasonable schedule for each thread so that they can execute on the core at intervals. They will be assigned time slices, consume time slices, and execute according to certain scheduling rules.
When a thread's time slice is nearly exhausted, the system saves its current running state, switches threads, replaces another thread to execute it, and assigns a new time slice to it to ensure that the thread can eventually run out. This saved state and switching behavior is called thread switching. Thread switching requires some overhead, such as space overhead, because the current thread that is about to end needs to run later, so the system needs to save its state when it is switched so that the next time it is turned on, it can start smoothly after the previous state, and it also requires some time overhead.
Thread switching is usually done at a security point, which means that when the basic method within a thread has finished running and the next method has not yet been run, thread switching will try to avoid happening when one of the thread's methods executes, since a thread's method often has a more complex system state. And for a method as a whole, a sudden interruption would destroy its atomicity. In a method, it is very likely that some variables are changing. This is an interruption, and it is likely to destroy the changes of these variables, so rollback behavior might occur, much like atomic operations in a database. Because some methods operate on the memory of the heap area, interruption of this method can lead to changes in the arguments, but it is difficult for the system to mark the middle state of a method. It can only start over the method at the next run time, which will result in errors as a whole and may lead to unsafe phenomena, such as variable changes twice. Therefore, the system will try to avoid this situation, typically in the security point between methods and memory threads switching, of course, in some special cases, there are also direct switching when methods are running, but this is rarely the case.
Multithreaded functionality exists in Java, so let's move on to considerations in multithreaded code:
public class Test{
public static void main(String[] args) {
Person a = new Person();
Thread t1 = new Thread(){
@Override
public void run(){
System.out.println("Hello I'm a thread2");
int[] xx = a.a();
xx[0] = 123;
}
};
Thread t2 = new Thread(){
@Override
public void run(){
System.out.println("Hello I'm a thread2");
int[] xx = a.a();
System.out.println(we[0]);
}
};
t1.start();
t2.start();
//System.out.println("11");
}
}
As shown in the code, to create multiple threaded code and execute it with multiple threads, you create it by using the thread construction method and writing the operations of each thread in its callback method. The way threads execute is by calling the start method on them.
Is start the way to get them to do it? In fact, not only that, the order in which the two threads execute is independent of who starts first and then starts. In this program, t2 may execute first than t1. This is because the start method is not a method for each thread to execute, it is a method for them to be ready, and when the thread is created, it is not executed instantly, but is in a default suspended state. In a system, threads that want to be executed by the CPU are in a ready queue, only in a ready queue can they be scheduled to execute by the CPU. The newly created thread object is not in this queue, but exists in memory, and is not transported to the CPU. This is a pending state. Using the start method, threads are put into a ready state from a pending state. That is, put into a ready queue, which can then be executed by the CPU. In a ready queue, it doesn't matter who is executed first and then who is executed first. It depends on who the CPU wants to execute first and who is executed first.
When threads are executed, the runtime of the Java virtual machine creates its own new thread stack for them, which immediately detaches from the main thread and has its own thread stack. Each thread stack has its own run method, which is similar to the main method of the main thread stack. Each new thread's thread stack is its own run method. The code in all threads we write runs in this run method, and like the main method, stacking occurs when we call other methods on the thread. Threads are created with the creation of new stacks in the stack area. They are equivalent to the main thread. At this time, no matter who runs first, everything is under the command of the system. After the new threads are created, they have nothing to do with the main thread, which can be understood as direct decomposition, running around, there is no longer a mutual restriction between them, who runs first depends on how the system commands.
Normally, however, the main thread runs first, because when a new thread is created, the main thread must be running and it is being executed, so there is a high probability that the operating system will not replace the running main thread for other threads, and generally the main thread will not be very long, and the CPU will run very quickly, so it will not temporarily switch threads anymore. Run the other threads after the main thread has finished. Variables with the same name can appear in threads because they belong to different domains and are unrelated to each other.
2. Encapsulation Ideas
Encapsulation is an important feature of object-oriented languages, which is emphasized in Java. Encapsulation is the principle of the inside to achieve all encapsulation, only to expose how to use, that is, to provide a simple and convenient interface to the outside, shielding the internal complex and cumbersome principles. In Java, to encapsulate attributes in objects, attributes must be identified by the private prefix, so that attributes cannot be accessed directly through objects, but sometimes we also need to use attributes in objects. What can we do? At this time, we will add modifiers and accessors to the class. Accessors are the way to get this property value. Modifiers are the way to modify this property value. Many ides can be generated directly by modifier accessors.
public class Person{
private int[] arr = {23,45,55,66};
public String name;
public static int flag;
public static void m1(){}
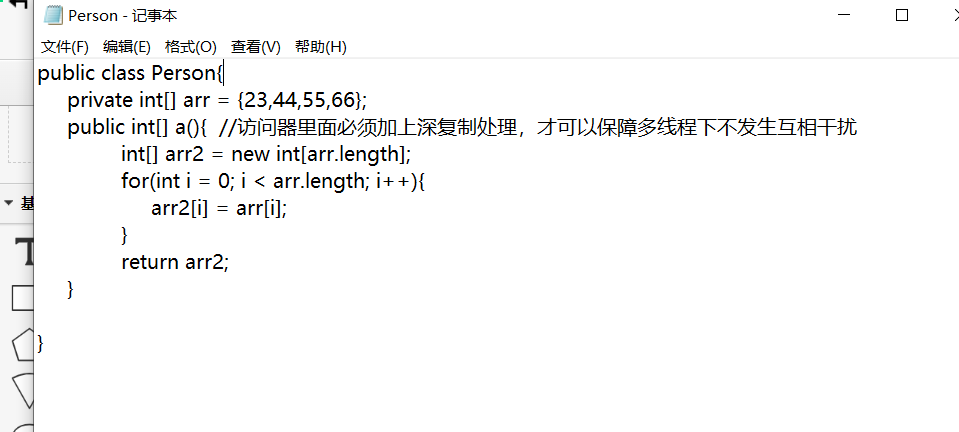
public int[] get_a(){
int[] arr2 = new int[arr.length];
for(int i = 0;i < arr.length;i++){
arr2[i] = arr[i];
}
return arr2;
}
}
In the code above, get_for the private property arr Method A is actually an accessor. When we set a property as a private property, we can't use it directly through the object. But we can indirectly access or modify this property through the public methods provided in the class. We can set some special operations on this method to make the operation on this property safer. At the same time, users do not need to know what is inside this method. They can complete the access or modification of this property by calling and filling in their own parameters. This can ensure the security of the whole system and the convenience of external operation, which is the benefit of encapsulation.
In the code above, we have added a deep copy to the accessor of the ARR attribute, that is, the ARR array we get from its accessor is actually the same as the ARR array, but not the same array, which is in memory at different addresses, just a substitute. The benefit of this deep copy operation is actually to facilitate security when accessing the same resource across multiple threads. When multiple threads access arr and make some modifications at the same time, they may cause operations between threads to interfere with each other and eventually run incorrectly. Using the accessor for deep copy operations, you can directly shield the effects of threads and threads operating on the same resource. In fact, they are not operating on the same resource at all. At the same time, it will make the threads'operation unable to affect the ARR attribute value in the original object, because they are only a substitute, which has great significance for information security in the system. This deep copy operation is also a frequently used operation in multi-threading, and is very effective and useful.
3. Original Note
Reference Type=For: Handle equals address of value, assignment of reference type means giving address of value on right to handle on left. handle = Address of value (address in heap), value does not correspond to base type C The inside pointer works the same way The reference address is the address of the variable in the stack, or the true address of the variable in the stack, where the variable has its own address The process is actually very similar C The pointer in the language, that is, the address stored in the address, maps the address of the value on the stack, and the address of the value maps on the stack, where the stack also has its own address, which is not open to users and is encapsulated. There is a stack in the stack and a variable stack in the function stack. When passed, the parameter copies the value of the argument. use = A copy of a reference type is the address, called a shallow copy java References to type input function arguments, where the parameter is assigned a value, are given the direction of the argument, not the address given. a No matter what code you write in the method, you can't change it b square Farizon declares the direction of the variable. This sum C The language is different because the incoming address is not the end result. a The value of the reference variable in the method is the address, and they cannot swap addresses anyway. Outside addresses are mapped, they are value-passing, value-manipulating, but this address is true, we really get the heap address, and manipulating the heap address really can have an impact. If we change something in the heap address, it really makes a difference. stay java It is not wise to use a shallow copy in the operation. When we change the value, if we change the public part, it will have an effect outside the function. If we do not change the public part, it will have no effect. What we really get with shallow copies is the shared portion of the heap address, and we can use parameters to have a real impact on the heap address portion, which results in a real impact on external variables. Pointer is also the principle person a person b And then we set the parameters in the method x = a,y = b. So what we get from the parameter is a direction to the address, which is x Pointing to a part of the heap address, y Points to a part of the heap address. The heap address is x and y Value of. x and y and a,b It doesn't matter at all, no matter how they are mapped or changed, it doesn't matter to the outside world, because the values of both are modified at this time, but we can really change the state of the information in the heap by their values, because the external ab It also points to the address in the heap, so we can pass xy Change the address in the heap, and then modify the outside ab Information. xy Can be used as an auxiliary symbol for logical understanding What we need to be aware of is that,.Is the address access symbol. The value of the base type is a direct copy, and the reference type is a change of direction. The value and handle of the basic type are together, and the assignment of the basic type is copied directly. The stacks in the operating system are all implemented with arrays, not chain storage, but sequential storage, so they are really contiguous. The reference address is the address of the stack, and then directly stores the handle above the address of the stack. Then the basic type is really here, the handle of the reference type is here, the handle points to the address of the value, for the address of the stack, Is called a reference address. The address of the stack directly stores information about the relevant variables. Chapter IV contains many interview points. Note that the address of the stack is called the reference address, which is a key piece of information. OOP Is Object Oriented Encapsulation inherits polymorphic abstraction, which are four object-oriented features Encapsulation is the principle of the inside to achieve all encapsulation, only to expose how to use, that is, to provide a simple and convenient interface to the outside, shielding the internal complex and cumbersome principles. The address of the variable depends on where it is declared, and if it is declared in a class, it is in the heap, and the method is in the stack Object of static type, handle in method area, value still in heap, static variable type is static resource area directly in method area Something like character arrays, they're in the string constant pool, and we can understand that the string constant pool is also in the heap. In summary, for some types of references, they are usually saved in the heap, and their values are generally changed to refer to, strings are more basic types of references, they are composed of a single, mostly character arrays, so there are few character changes to them. If we want to change the reference type, it is useless to simply change the reference type. This is the same as C Language is the same, C Address is what comes in the language, but Java What's coming in is a variable. I was a little vague here just now, but that's what I thought it was. Nevertheless, Java You can use variables to access the real address in, which is the difference between them. Although the function method declaration calls are similar, there is actually a small difference and it is easy to confuse. Java Classes in and C The structure in the language is very similar. C There is a common type of pointer in the Java Not in. Do not put C Pointer and Java Objects in the are confused. Objects are like structure type pointers. Handles are passed in. Use.To access the C Also available in language->Visit Direct Output Object can output its type and address Changers and accessors are the way to change access to private properties Changers and accessors are designed to be secure. This security has nothing to do with hackers. This is to prevent data from interfering with each other under multiple threads. It can guarantee data interference problem under multi-threading and multi-process. Simple writing does not have any defensive functions, and some processing must be added to make it defensive. With this changer and accessor, we can control a data as read-only or write-only, or even encapsulate it directly for internal assistance only. String security issues? Not here. The equals sign of the basic type is a deep copy, and deep assignment processing must be added inside the accessor to ensure multithreaded security. Otherwise, we can change the way we access it. Without this processing, the accessor will have no effect. Listen here again later. In a class, basic types and string types are safe in any case. First, basic types are deeply copied, while string types are immutable and their access is secure. CPU A core can only perform the same task at the same time, that is, only one thread can be executed at each time above, and multiple threads can execute concurrently on top in turn. Multitask parallelism is actually a fast switch between tasks. Threads switch to keep the state of the last thread, so that the state of the thread can continue at the beginning of the state. This switch has overhead, time overhead, and space overhead, since memory is required to record and save the state. Thread switching occurs at a security point. Generally speaking, the security point is that after the end of an underlying method, some methods will switch in the middle, but generally, the security point is confirmed between spaces. Therefore, it is not a safe practice for a thread to execute immediately. The specific execution scheme for a thread is specified by the system. start The method is to get ready. There is a ready queue in the operating system, which is full of tasks to be executed. The operating system will not schedule a task until it is ready. So we can explain that the order of execution is not determined by the operation entering the ready state, it is only the listening system. Getting ready means telling the operating system that I can be executed. In fact, it formally enters the ready queue, in which processes are waiting to be dispatched. When the thread is ready, the thread executes from run The method starts by creating two stacks of threads, each of which is its own, whenever executed run Methods, respective run Calling other methods in a method is essentially equivalent to copying these called methods and pushing them into your own thread stack. That is, threads are actually in the stack, and the creation of threads is accompanied by the creation of stacks. We're on our own java Threads created in, they will open their own thread stack, they belong to separate threads. The two threads themselves are objects, and when called, an extra thread stack is started for the threads. The program stays open because there is an infinite loop inside. //Threads do not wait for each other to execute sleep Is lets the thread sleep, the parameter inside is the milliseconds to sleep The main method is called the main thread. Once a new thread is created in the main thread, a new stack is built and a new thread is formed. The main and child threads are fine and split at birth. Threads just split at birth. When a thread is created, no one waits for any of the three threads, so it doesn't matter who the three threads are. When threads are created, they have no order, they don't wait for each other, and they write in code start The order does not matter. The main thread belongs to the currently executing thread, so it is generally ahead of other threads and has a greater probability that it will not be executed by CPU Replace, and when the main thread is not long, it is easy to finish, very easy It can be executed immediately in the current time slice. The reason that the main thread always executes first in the code is because the main thread is executing. If it is short, it may be executed before it can switch. It takes time to create a new thread. In this case, after two threads have been activated, a main thread will perform an operation. Although the main thread's operation is later, it usually finishes first because the main thread already exists, is running, and is short, so the main thread may have been executed without triggering a thread switch. Threads are always on the stack and will not be released until after execution. Appendix 1: Pictures A variable with the same name can appear in a thread because of different scopes java The different stacks in the stack area are the entities of threads. Threads in the system are all made up of arrays, which are contiguous arrays. Time to tidy up again.
Appendix 1: