Thread pool
Why do I need a thread pool
- In practical use, threads occupy resources very much, and poor management of them is easy to cause system problems. Therefore, in most concurrency frameworks, thread pools are used to manage threads
benefit
- Using thread pool can reuse existing threads to continue executing tasks, avoiding the consumption caused by thread creation and destruction
- It can improve the response speed of the system
- Threads can be reasonably managed, and the number of threads that can be run can be adjusted according to the bearing capacity of the system
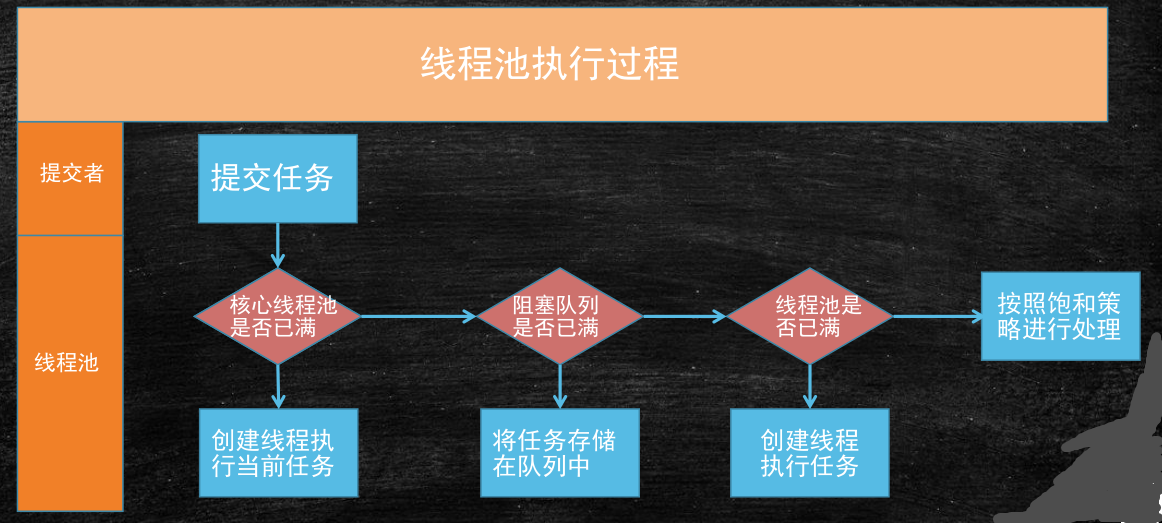
working principle
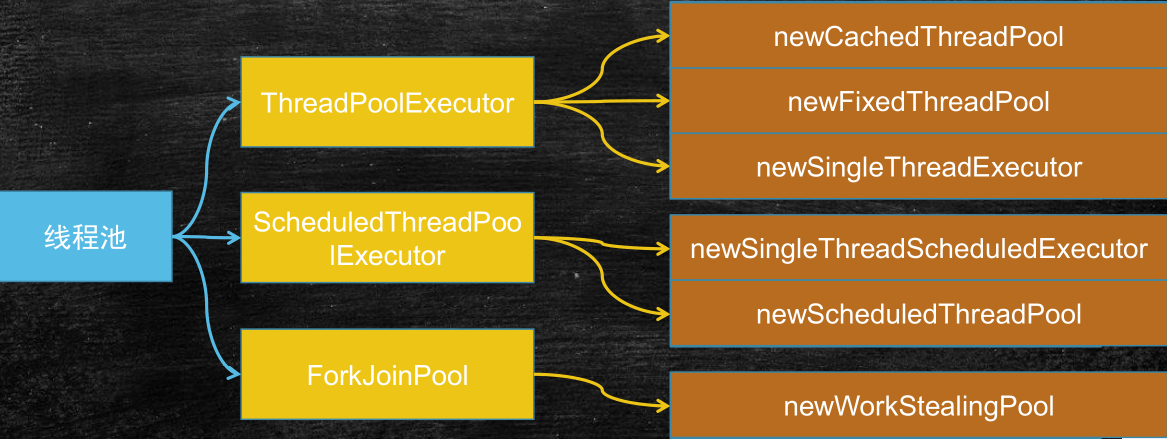
Classification of thread pool
ThreadPoolExecutor
CacheThreadPool
Create a thread pool that can create new threads as needed, but reuse previously constructed threads when they are available and create new threads using the provided ThreadFactory when needed
features
- The number of threads in the thread pool is not fixed and can reach the maximum value (Interger. MAX_VALUE)
- Threads in the thread pool can be reused and recycled (the default recycling time is 1 minute)
- When there are no available threads in the thread pool, a new thread will be created
give an example
public class Task implements Runnable{
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+"running");
}
}
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class CacheThreadPoolDemo {
public static void main(String[] args) {
//Generate thread pool
ExecutorService executorService = Executors.newCachedThreadPool();
//Submit thread pool task
for(int i=0;i<20;i++){
executorService.execute(new Task());
}
executorService.shutdown();
}
}

FixedThreadPool
Create a reusable thread pool with a fixed number of threads to run these threads in a shared unbounded queue. At any point, most nThreads threads are active in processing tasks. If an additional task is submitted while all threads are active, the additional task will wait in the queue until there are available threads. If any thread terminates due to failure during execution before shutdown, a new thread will perform subsequent tasks instead of it (if necessary). Threads in the pool will exist until a thread is explicitly shut down.
features
- Threads in the thread pool are in a certain amount, which can well control the concurrency of threads
- Threads can be reused and will exist until the display is turned off
- When more than a certain number of threads are submitted, they need to wait in the queue
give an example
public class Task implements Runnable{
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+"running");
}
}
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class FixedThreadPoolDemo {
public static void main(String[] args) {
//Only 5 threads are allowed to be created
ExecutorService executorService = Executors.newFixedThreadPool(5);
for(int i=0;i<20;i++){
executorService.execute(new Task());
}
executorService.shutdown();
}
}
SingleThreadExecutor
Create an Executor that uses a single worker thread to run the thread in an unbounded queue. (note that if this single thread is terminated due to a failure during execution before shutdown, a new thread will perform subsequent tasks instead of it if necessary). It can ensure that each task is executed sequentially, and no more than one thread will be active at any given time. Unlike other equivalent newFixedThreadPool(1), it ensures that other threads can be used without reconfiguring the Executor returned by this method.
features
- At most one thread can be executed in the thread pool, and then the thread activities submitted will be queued for execution
give an example
public class Task implements Runnable{
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+"running");
}
}
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class SingleThreadPoolDemo {
public static void main(String[] args) {
ExecutorService executorService = Executors.newSingleThreadExecutor();
for(int i=0;i<20;i++){
executorService.execute(new Task());
}
executorService.shutdown();
}
}
ScheduledThreadPoolExecutor
newSingleThreadScheduledExecutor
Create a single threaded execution program that can schedule commands to run after a given delay or execute periodically.
features
- At most one thread can be executed in the thread pool, and then the thread activities submitted will be queued for execution
- Thread activities can be executed regularly or delayed
newScheduledThreadPool
Create a thread pool that can schedule commands to run after a given delay or execute periodically.
features
- There are a specified number of threads in the thread pool, and even empty threads will be retained
- Thread activities can be executed regularly or delayed
give an example
Example 1
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
public class ScheduledThreadPoolDemo {
public static void main(String[] args) {
ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(3);
System.out.println(System.currentTimeMillis());//Output time
scheduledExecutorService.schedule(new Runnable() {
@Override
public void run() {
System.out.println("Three second delay in execution");
System.out.println(System.currentTimeMillis());//Output time
}
}, 3, TimeUnit.SECONDS);
scheduledExecutorService.shutdown();
}
}

Example 2
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
public class ScheduledThreadPoolDemo {
public static void main(String[] args) {
ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(3);
System.out.println(System.currentTimeMillis());
scheduledExecutorService.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
System.out.println("Execution is delayed by one second and executed every three seconds");
System.out.println(System.currentTimeMillis());
}
}, 1,3, TimeUnit.SECONDS);
}
}
ForkJoinPool
newWorkStealingPool
Create a thread pool with parallel level. The parallel level determines the maximum number of threads executing at the same time. If the parallel level parameter is not passed, it will default to the number of CPU s of the current system
give an example
package forkjoin;
import java.util.concurrent.RecursiveAction;
class PrintTask extends RecursiveAction {
private static final int THRESHOLD = 50; //You can only print up to 50 numbers
private int start;
private int end;
public PrintTask(int start, int end) {
super();
this.start = start;
this.end = end;
}
@Override
protected void compute() {
if(end - start < THRESHOLD){
for(int i=start;i<end;i++){
System.out.println(Thread.currentThread().getName()+"of i Value:"+i);
}
}else {
int middle =(start+end)/2;
PrintTask left = new PrintTask(start, middle);
PrintTask right = new PrintTask(middle, end);
//Execute two "small tasks" in parallel
left.fork();
right.fork();
}
}
}
package forkjoin;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.TimeUnit;
/**
*The idea of divide and rule
* Simply print the value of 0-300. Parallel execution with multithreading
*
*/
public class ForkJoinPoolAction {
public static void main(String[] args) throws Exception{
PrintTask task = new PrintTask(0, 300);
//Create an instance and perform the split task
ForkJoinPool pool = new ForkJoinPool();
pool.submit(task);
//Thread blocking, waiting for all tasks to complete
pool.awaitTermination(2, TimeUnit.SECONDS);
pool.shutdown();
}
}
Thread pool life cycle
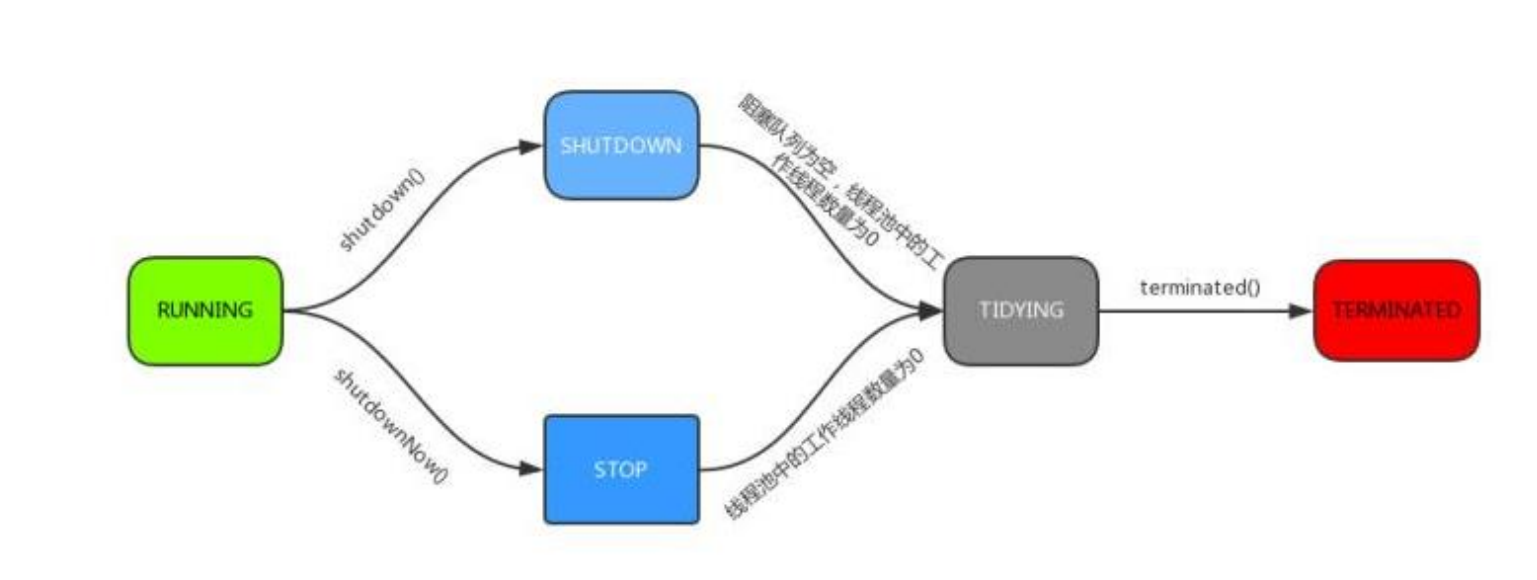
There are only two
- RUNNING
- TERMINATED
- But there are three transition states
- SHUIDOWN
- STOP
- TIDYING
- But there are three transition states

Creation of thread pool

corePoolSize
- Number of core thread pools
maximumPoolSize
- The maximum number of threads that a thread pool can create
keepAliveTime
- Idle thread lifetime
unit
- Time unit, specify the time unit for keepAliveTime
workQueue
- Blocking queue, which is used to save the blocking queue of tasks
threadFactory
- Create project class of thread
handler
- Saturation policy (reject Policy)
Blocking queue
ArrayBlockingQueue
The implementation of array based blocking queue maintains a fixed length array in the ArrayBlockingQueue to cache the data objects in the queue. This is a common blocking queue. In addition to a fixed length array, ArrayBlockingQueue also stores two shaping variables, which respectively identify the position of the head and tail of the queue in the array.
ArrayBlockingQueue shares the same lock object when the producer places data and the consumer obtains data, which also means that the two cannot run in parallel, which is especially different from LinkedBlockingQueue; According to the analysis of the implementation principle, ArrayBlockingQueue can fully adopt separate lock, so as to realize the complete parallel operation of producer and consumer operations. The reason why Doug Lea didn't do this may be that the data writing and obtaining operations of ArrayBlockingQueue are light enough to introduce an independent locking mechanism. In addition to bringing additional complexity to the code, it can't take any advantage in performance. Another obvious difference between ArrayBlockingQueue and LinkedBlockingQueue is that the former will not generate or destroy any additional object instances when inserting or deleting elements, while the latter will generate an additional Node object. In the system that needs to process large quantities of data efficiently and concurrently for a long time, its impact on GC is still different. When creating ArrayBlockingQueue, we can also control whether the internal lock of the object adopts fair lock, and non fair lock is adopted by default.
give an example
1. Producers
package ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
public class Producer implements Runnable {
private BlockingQueue<Integer> blockingQueue;
private static int element = 0;
public Producer(BlockingQueue<Integer> blockingQueue) {
this.blockingQueue = blockingQueue;
}
public void run() {
try {
while(element < 20) {
System.out.println("The elements to be put in are:"+element);
blockingQueue.put(element++);
}
} catch (Exception e) {
System.out.println("The producer was interrupted while waiting for free space!");
e.printStackTrace();
}
System.out.println("The producer has terminated the production process!");
}
}
2. Consumers
package ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
public class Consumer implements Runnable {
private BlockingQueue<Integer> blockingQueue;
public Consumer(BlockingQueue<Integer> blockingQueue) {
this.blockingQueue = blockingQueue;
}
public void run() {
try {
while(true) {
System.out.println("The extracted elements are:"+blockingQueue.take());
}
} catch (Exception e) {
System.out.println("Consumers are interrupted while waiting for new products!");
e.printStackTrace();
}
}
}
3. Testing
package ArrayBlockingQueue;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
public class MainClass {
public static void main(String[] args) {
BlockingQueue<Integer> blockingQueue = new ArrayBlockingQueue<Integer>(3,true);
Producer producerPut = new Producer(blockingQueue);
Consumer consumer = new Consumer(blockingQueue);
// ProducerOffer producerOffer = new ProducerOffer(blockingQueue);
new Thread(producerPut).start();
new Thread(consumer).start();
}
}
LinkedBlockingQueue
Similar to ArrayListBlockingQueue, the blocking queue based on linked list also maintains a data buffer queue (the queue is composed of a linked list). When the producer puts a data into the queue, the queue will get the data from the producer and store it in the queue, and the producer will return immediately; Only when the queue buffer reaches the maximum cache capacity (LinkedBlockingQueue can specify this value through the constructor) will the producer queue be blocked. Until the consumer consumes a piece of data from the queue, the producer thread will be awakened. On the contrary, the processing on the consumer side is also based on the same principle. The reason why LinkedBlockingQueue can efficiently process concurrent data is that it uses independent locks for producer and consumer to control data synchronization, which also means that in the case of high concurrency, producers and consumers can operate the data in the queue in parallel, so as to improve the concurrency performance of the whole queue.
give an example
Similar to ArrayBlockingQueue
DelayQueue
The element in DelayQueue can be obtained from the queue only when the specified delay time has expired. DelayQueue is a queue with no size limit, so the operation of inserting data into the queue (producer) will never be blocked, but only the operation of obtaining data (consumer) will be blocked.
Usage scenario:
DelayQueue has few usage scenarios, but they are quite ingenious. Common examples are using a DelayQueue to manage a connection queue that does not respond to timeout.
give an example
package delayqueue;
import java.util.concurrent.DelayQueue;
import java.util.concurrent.Delayed;
import java.util.concurrent.TimeUnit;
public class DelayQueueTest {
public static void main(String[] args) {
DelayQueue<DelayTask> queue = new DelayQueue<>();
queue.add(new DelayTask("1", 1000L, TimeUnit.MILLISECONDS));
queue.add(new DelayTask("2", 2000L, TimeUnit.MILLISECONDS));
queue.add(new DelayTask("3", 3000L, TimeUnit.MILLISECONDS));
System.out.println("queue put done");
while(!queue.isEmpty()) {
try {
DelayTask task = queue.take();
System.out.println(task.name + ":" + System.currentTimeMillis());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
class DelayTask implements Delayed {
public String name;
public Long delayTime;
public TimeUnit delayTimeUnit;
public Long executeTime;//ms
DelayTask(String name, long delayTime, TimeUnit delayTimeUnit) {
this.name = name;
this.delayTime = delayTime;
this.delayTimeUnit = delayTimeUnit;
this.executeTime = System.currentTimeMillis() + delayTimeUnit.toMillis(delayTime);
}
@Override
public int compareTo(Delayed o) {
if(this.getDelay(TimeUnit.MILLISECONDS) > o.getDelay(TimeUnit.MILLISECONDS)) {
return 1;
}else if(this.getDelay(TimeUnit.MILLISECONDS) < o.getDelay(TimeUnit.MILLISECONDS)) {
return -1;
}
return 0;
}
@Override
public long getDelay(TimeUnit unit) {
return unit.convert(executeTime - System.currentTimeMillis(), TimeUnit.MILLISECONDS);
}
}
PriorityBlockingQueue
Priority based blocking queue (the priority is determined by the comparer object passed in by the constructor), but it should be noted that PriorityBlockingQueue will not block the data producer, but only the data consumer when there is no consumable data. Therefore, special attention should be paid when using. The speed of producer production data must not be faster than that of consumer consumption data, otherwise all available heap memory space will be exhausted over time. When implementing PriorityBlockingQueue, the lock of internal thread synchronization adopts fair lock.
give an example
package priorityqueue;
public class Task implements Comparable<Task> {
private int id;
private String name;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public int compareTo(Task task) {
return this.id > task.id ? 1 : (this.id < task.id ? -1 : 0);
}
public String toString() {
return this.id + "," + this.name;
}
}
package priorityqueue;
import java.util.concurrent.PriorityBlockingQueue;
public class UsePriorityBlockingQueue {
public static void main(String[] args) throws Exception{
PriorityBlockingQueue<Task> q = new PriorityBlockingQueue<Task>();
Task t1 = new Task();
t1.setId(3);
t1.setName("id For 3");
Task t2 = new Task();
t2.setId(4);
t2.setName("id For 4");
Task t3 = new Task();
t3.setId(1);
t3.setName("id Is 1");
q.add(t1); //3
q.add(t2); //4
q.add(t3); //1
System.out.println("Container:" + q);
System.out.println(q.take().getId());
System.out.println("Container:" + q);
}
}
SynchronousQueue
A non buffered waiting queue is similar to direct transaction without intermediary. It is a bit like producers and consumers in primitive society. Producers take products to the market to sell to the final consumers of products, and consumers must go to the market to find the direct producer of the goods they want. If one party fails to find a suitable target, I'm sorry, everyone is waiting in the market. Compared with the buffered BlockingQueue, there is no intermediate dealer link (buffer zone). If there is a dealer, the producer directly wholesales the products to the dealer, without worrying that the dealer will eventually sell these products to those consumers. Because the dealer can stock some goods, compared with the direct transaction mode, Generally speaking, the intermediate dealer mode will have higher throughput (can be sold in batches); On the other hand, due to the introduction of dealers, additional transaction links are added from producers to consumers, and the timely response performance of a single product may be reduced.
There are two different ways to declare a synchronous queue, which have different behavior. The difference between fair mode and unfair mode:
If the fair mode is adopted: the synchronous queue will adopt a fair lock and cooperate with a FIFO queue to block redundant producers and consumers, so as to the overall fair strategy of the system;
However, in the case of unfair mode (SynchronousQueue default): SynchronousQueue adopts unfair lock and cooperates with a LIFO queue to manage redundant producers and consumers. In the latter mode, if there is a gap between the processing speed of producers and consumers, it is easy to be hungry, That is, there may be some producers or consumers whose data will never be processed.
give an example
package Synchronousqueue;
import java.util.Random;
import java.util.UUID;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.SynchronousQueue;
public class SynchronousQueueExample {
static class SynchronousQueueProducer implements Runnable {
protected BlockingQueue<String> blockingQueue;
final Random random = new Random();
public SynchronousQueueProducer(BlockingQueue<String> queue) {
this.blockingQueue = queue;
}
@Override
public void run() {
while (true) {
try {
String data = UUID.randomUUID().toString();
System.out.println("Put: " + data);
blockingQueue.put(data);
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
static class SynchronousQueueConsumer implements Runnable {
protected BlockingQueue<String> blockingQueue;
public SynchronousQueueConsumer(BlockingQueue<String> queue) {
this.blockingQueue = queue;
}
@Override
public void run() {
while (true) {
try {
String data = blockingQueue.take();
System.out.println(Thread.currentThread().getName()
+ " take(): " + data);
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public static void main(String[] args) {
final BlockingQueue<String> synchronousQueue = new SynchronousQueue<String>();
SynchronousQueueProducer queueProducer = new SynchronousQueueProducer(
synchronousQueue);
new Thread(queueProducer).start();
SynchronousQueueConsumer queueConsumer1 = new SynchronousQueueConsumer(
synchronousQueue);
new Thread(queueConsumer1).start();
SynchronousQueueConsumer queueConsumer2 = new SynchronousQueueConsumer(
synchronousQueue);
new Thread(queueConsumer2).start();
}
}
The difference between ArrayBlockingQueue and LinkedBlockingQueue
-
The implementation of locks in queues is different
The locks in the queue implemented by ArrayBlockingQueue are not separated, that is, production and consumption use the same lock;
The locks in the queue implemented by LinkedBlockingQueue are separated, that is, putLock is used for production and takeLock is used for consumption
-
Different queue sizes and initialization methods
The size of the queue must be specified in the queue implemented by ArrayBlockingQueue;
The size of the queue can not be specified in the queue implemented by LinkedBlockingQueue, but the default is integer MAX_ VALUE
Reject strategy
ThreadPoolExecutor.AbortPolicy
- Discard the task and throw a RejectedExecutionException exception.
ThreadPoolExecutor.DiscardPolicy
- It also discards the task without throwing an exception.
ThreadPoolExecutor.DiscardOldestPolicy
- Discard the task at the top of the queue and try to execute the task again (repeat this process)
ThreadPoolExecutor.CallerRunsPolicy
- The task is handled by the calling thread
execute method
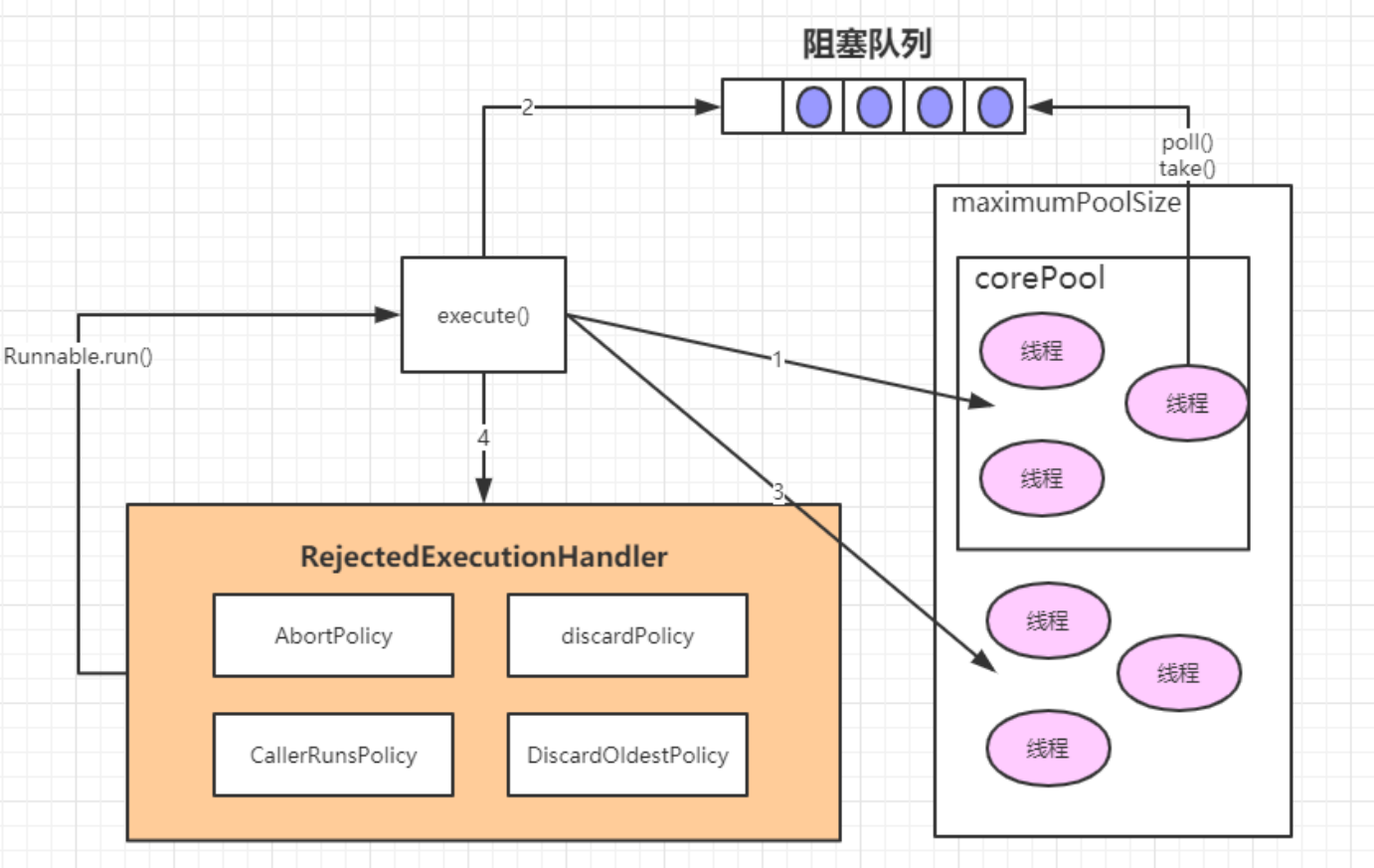
▪ If the current running thread is less than corePoolSize, a new thread will be created to execute a new task;
▪ If the number of running threads is equal to or greater than corePoolSize, the submitted task will be stored in the blocking queue workQueue;
▪ If the current workQueue queue is full, a new thread will be created to execute the task;
▪ If the number of threads has exceeded the maximumPoolSize, the saturation policy RejectedExecutionHandler will be used for processing.
Executor and Submit
submit is the base method executor An extension of execute (runnable), which can be used to cancel execution and / or wait for completion by creating and returning a Future class object.

import java.util.concurrent.Callable;
public class Task1 implements Callable {
@Override
public Object call() throws Exception {
return Thread.currentThread().getName()+"is running";
}
}
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
public class Test {
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(5);
for(int i=0;i<10;i++){
Future<String> submit = executorService.submit(new Task1());
try {
String str = submit.get();
System.out.println(str);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
}
}
Shutdown of thread pool
To close the thread pool, you can use the shutdown and shutdown now methods
Principle: traverse all threads in the thread pool, and then interrupt in turn
▪ 1. shutdownNow first sets the status of the thread pool to STOP, then attempts to STOP all threads that are executing and not executing tasks, and returns the list of tasks waiting to be executed;
▪ 2. Shutdown simply sets the state of the thread pool to shutdown, and then interrupts all threads that are not executing tasks