In the previous article, I have published common interview questions. Here I spent some time sorting out the corresponding answers. Due to my limited personal ability, it may not be in place. If there are unreasonable answers, please give me some advice. Thank you here.
This paper mainly describes the concurrent HashMap, a high-frequency interview point in java multithreading. The implementation of concurrent HashMap is similar to HashMap. For example, the underlying data structure, expansion multiple, calculation of table value, etc. The biggest difference between HashMap and HashMap is how to ensure thread safety. We will also focus on the guarantee of thread safety. If you are interested in the content of hashMap, you can see the previous articles in the official account, and interview with HashMap and source code analysis of HashMap. If you are interested in java multithreading, you can see the articles in the official account multithread series, which may help you.
Have you seen the source code of ConcurrentHashMap? Tell me about its put and get processes?
Concurrent hashMap is the key content of concurrent package. Its put and get processes are similar to the implementation of hashMap. After all, the underlying data structure is consistent as follows.
put process:
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());//Calculate the hash value, which is calculated to achieve a more uniform distribution
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)//If not initialized, initialize directly
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {//If the position has no value temporarily
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; //cas adds the first value
}
else if ((fh = f.hash) == MOVED)//If capacity expansion is in progress
tab = helpTransfer(tab, f);//Help expand capacity
else {
V oldVal = null;
synchronized (f) {//Lock the head node of the hash bucket
if (tabAt(tab, i) == f) {//If it is the first node
if (fh >= 0) {//If it's a linked list
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {//Traverse the linked list
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {//hash and equals are equal
oldVal = e.val;
if (!onlyIfAbsent)//Direct replacement
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {//Empty, add
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {//Red black tree node
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {//Add node
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)//Judge whether the threshold value is exceeded
treeifyBin(tab, i);//Convert to red black tree
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);//Add data and expand the capacity if the length exceeds
return null;
} The process of Put can be roughly divided into the following steps:
- Find the hash value
- Whether the array has been initialized. If not
- Whether the location is empty. If it is empty, directly cas set the first node
- Judge whether the capacity is being expanded. If the capacity is being expanded, join in the expansion
- If it is not empty, lock the head node and start the insertion operation. If it is a linked list, traverse whether it is the same. If it is a red black tree, add it directly
- After adding, judge whether to expand the capacity. If it exceeds the threshold, expand the capacity.
The operations marked in red above are the difference between concurrent hashMap and hashMap. These points are that concurrent hashMap ensures thread safety in the process of adding.
Get procedure:
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode());//Find the hashcode value
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))//If the first node is found, return directly
return e.val;
}
else if (eh < 0)//If eh < 0, it means red black tree or capacity expansion
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {//Linked list structure, direct traversal
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
} Get process:
- Get hash value
- If it is the first node, return directly
- If not, judge whether it is expanding or red black tree, then call the find method
- If not, it is the linked list structure. You can find it directly while
Why doesn't the get process need locking like the put process? The reason is that val in node is volatile. We take the latest value every time. Here we use the visibility of volatile.
Talk about the process of capacity expansion of ConcurrentHashMap? What is capacity expansion assistance?
The capacity expansion process of concurrenthashmap allows multiple threads to operate at the same time. When a thread is put ting and finds that it is expanding, it will help to expand the capacity together. This process is called assisted capacity expansion. How to determine whether capacity expansion is in progress? Concurrent HashMap uses sizectl to control. Let's first look at the state change of sizectl.
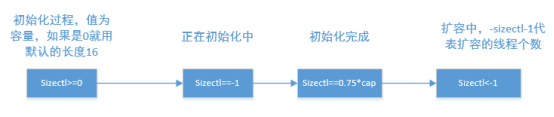
Assist in the expansion process:
final Node<K,V>[] helpTransfer(Node<K,V>[] tab, Node<K,V> f) {
Node<K,V>[] nextTab; int sc;
if (tab != null && (f instanceof ForwardingNode) &&//If the node is a ForwardingNode, it indicates that a thread is expanding
(nextTab = ((ForwardingNode<K,V>)f).nextTable) != null) {//The expanded nextTable is not empty
int rs = resizeStamp(tab.length);
while (nextTab == nextTable && table == tab &&
(sc = sizeCtl) < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || transferIndex <= 0)//Help judge the condition of capacity expansion, and judge whether the capacity expansion thread exceeds the limit
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) {//Set the value of sizectl
transfer(tab, nextTab);//Data migration
break;
}
}
return nextTab;//Returns a new hash array
}
return table;//Returns the old hash array
} The real capacity expansion process is in the transfer function. The core idea of its implementation is to set a step size, move the data one step at a time, and apply for the next step after the relocation. The expansion part of the source code is very long, but I suggest you take a look.
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
int n = tab.length, stride;
// Set the step size and the number of cores
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE; // subdivide range
// The first thread creates the nextTab first
if (nextTab == null) {
try {
// Capacity doubled
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];
nextTab = nt;
} catch (Throwable ex) {
sizeCtl = Integer.MAX_VALUE;
return;
}
nextTable = nextTab;
transferIndex = n;
}
// Length of new table
int nextn = nextTab.length;
// ForwardingNode refers to the node that has been migrated, and the hash value is MOED(-1)
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);
boolean advance = true;// advance identifies whether the migration is complete
boolean finishing = false; // Table identification ensures that it can be submitted
// i is the index value and bound is the boundary value of this migration
for (int i = 0, bound = 0;;) {
Node<K,V> f; int fh;
// i = transferIndex,bound = transferIndex-stride
while (advance) {
int nextIndex, nextBound;
if (--i >= bound || finishing)
advance = false;
// All positions of the original TABLE are processed by threads
else if ((nextIndex = transferIndex) <= 0) {
i = -1;
advance = false;//Set to not required
}
else if (U.compareAndSwapInt//cas set boundary value
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ?
nextIndex - stride : 0))) {
bound = nextBound;
i = nextIndex - 1;
advance = false;
}
}
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
// Have you finished all the migration work
if (finishing) {
nextTable = null;
table = nextTab;// Assign the new nextTab to the table property
sizeCtl = (n << 1) - (n >>> 1);// Recalculate sizeCtl
return;//return
}
// Modify the value of sizeCtl
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
// Exit method
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
return;
finishing = advance = true;
i = n; // Reconfirm before submission
}
}
// If location i is empty, use cas to set the initialized fwd node
else if ((f = tabAt(tab, i)) == null)
advance = casTabAt(tab, i, null, fwd);
// The location has been migrated
else if ((fh = f.hash) == MOVED)
advance = true; // It has been handled
//Need to migrate
else {
synchronized (f) {// Lock before migration and start migration
if (tabAt(tab, i) == f) {
Node<K,V> ln, hn;
// Linked list migration: divide the linked list into two and move them separately
if (fh >= 0) {
int runBit = fh & n;
Node<K,V> lastRun = f;
for (Node<K,V> p = f.next; p != null; p = p.next) {
int b = p.hash & n;
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
if (runBit == 0) {
ln = lastRun;
hn = null;
}
else {
hn = lastRun;
ln = null;
}
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0)
ln = new Node<K,V>(ph, pk, pv, ln);
else
hn = new Node<K,V>(ph, pk, pv, hn);
}
// One of the linked lists is placed in the position i of the new array
setTabAt(nextTab, i, ln);
// Another linked list is placed in the position i+n of the new array
setTabAt(nextTab, i + n, hn);
// Set the position of the original array to fwd, which means that the position has been processed,
setTabAt(tab, i, fwd);
// Setting this location has been migrated
advance = true;
}
else if (f instanceof TreeBin) {
// The migration of red black tree is divided into 2
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> lo = null, loTail = null;
TreeNode<K,V> hi = null, hiTail = null;
int lc = 0, hc = 0;
for (Node<K,V> e = t.first; e != null; e = e.next) {
int h = e.hash;
TreeNode<K,V> p = new TreeNode<K,V>
(h, e.key, e.val, null, null);
if ((h & n) == 0) {
if ((p.prev = loTail) == null)
lo = p;
else
loTail.next = p;
loTail = p;
++lc;
}
else {
if ((p.prev = hiTail) == null)
hi = p;
else
hiTail.next = p;
hiTail = p;
++hc;
}
}
//If the number of nodes is less than 8, the red black tree is converted back to the linked list
ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :
(hc != 0) ? new TreeBin<K,V>(lo) : t;
hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :
(lc != 0) ? new TreeBin<K,V>(hi) : t;
// Place ln in the position i of the new array
setTabAt(nextTab, i, ln);
// Place hn in the new array position i+n
setTabAt(nextTab, i + n, hn);
// Set the position of the original array to fwd, which means that the position has been processed,
setTabAt(tab, i, fwd);
// If advance is set to true, it means that the location has been migrated
advance = true;
}
}
}
}
}
}
How does ConcurrentHashMap ensure thread safety?
- CAS operation data: modification of sizectl, expansion value, etc. CAS is used to ensure the atomicity of data modification.
- Synchronized mutex: put and capacity expansion process. Use synchronized to ensure that the thread has only one operation and thread safety.
- Volatile modification variables: variables such as table and sizeCtl are modified with volatile to ensure visibility
Concurrent HashMap is a high-frequency knowledge point in the interview. This article mainly describes the difference between concurrent HashMap and HashMap, which is also a common point in the interview. It may help you better understand it in combination with the previous HashMap. This article is longer than before. It mainly introduces the source code of concurrenthashmap. If you have time, you can see it. If you don't have time, you can write down the process conclusion.
There are so many contents in this article. If you think it is helpful for your study and interview, please give me a favor or forward it. Thank you.
Want to know more java content (including big factory interview questions and questions) can pay attention to the official account, also can leave messages in official account, help push Ali, Tencent and other Internet factories.