Link to this article: https://blog.csdn.net/zqz_zqz/article/details/70246212
Object structure
In the HotSpot virtual machine, the layout of objects stored in memory can be divided into three areas: object Header, Instance Data and Padding.
The following figure shows the data structure of ordinary object instances and array object instances:
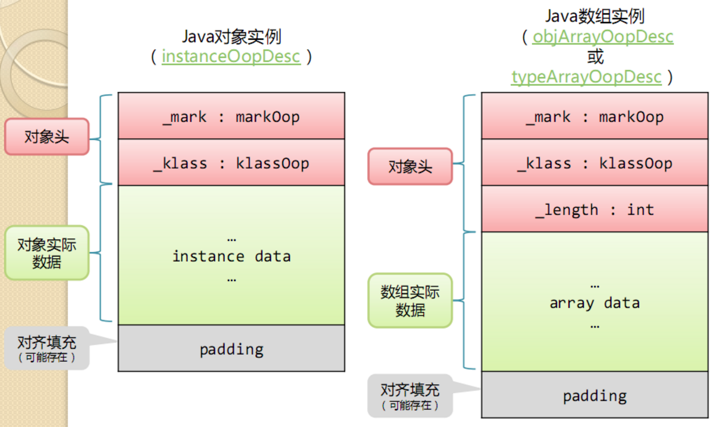
Object header
The object header of HotSpot virtual machine includes two parts of information:
markword
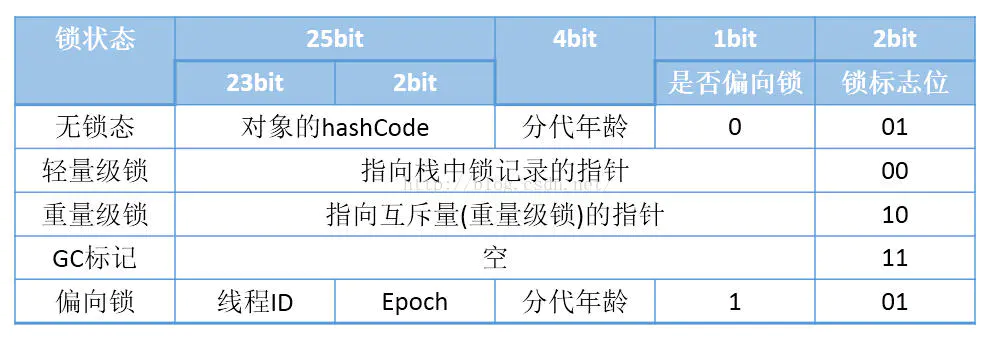
The first part of MarkWord is used to store the runtime data of the object itself, such as HashCode, GC generation age, lock status flag, lock held by thread, biased thread ID, biased timestamp, etc. the length of this part of data is 32bit and 64bit in 32-bit and 64 bit virtual machines (unopened compressed pointer), which is officially called "MarkWord".
Mark Word is designed as a non fixed data structure to store more effective data. It will reuse its own storage space according to the state of the object itself, that is, Mark Word will change with the operation of the program, and the change state is as follows (32-bit virtual machine):
klass
Another part of the object header is the klass type pointer, that is, the pointer of the object to its class metadata. The virtual machine uses this pointer to determine which class the object is an instance of
Array length (only array objects have)
If the object is an array, there must also be a piece of data in the object header to record the length of the array
Instance data
The instance data part is not only the effective information actually stored by the object, but also the content of various types of fields defined in the program code. Whether it is inherited from the parent class or defined in the child class, it needs to be recorded.
Align fill
The third part of alignment filling does not necessarily exist and has no special meaning. It only plays the role of placeholder. Because the automatic memory management system of HotSpot VM requires that the starting address of the object must be an integer multiple of 8 bytes, in other words, the size of the object must be an integer multiple of 8 bytes. The object header is exactly a multiple of 8 bytes (1 or 2 times). Therefore, when the object instance data part is not aligned, it needs to be filled in by alignment.
Object size calculation
main points
1. In 32-bit system, the space for storing Class pointer is 4 bytes, MarkWord is 4 bytes and object header is 8 bytes.
2. In 64 bit system, the space for storing Class pointer is 8 bytes, MarkWord is 8 bytes and object header is 16 bytes.
3. When 64 bit pointer compression is enabled, the space for storing Class pointer is 4 bytes, markword is 8 bytes, and the object header is 12 bytes. Array length 4 bytes + array object header 8 bytes (object reference 4 bytes (64 bits without pointer compression are 8 bytes) + array markword 4 bytes (64 bits without pointer compression are 8 bytes)) + alignment 4 = 16 bytes.
4. Static attributes are not included in the object size.
Supplement:
HotSpot object model
HotSpot adopts OOP Klass model, which is a model describing Java object instances. It is divided into two parts:
When a class is loaded into memory, it is encapsulated into klass. klass contains the metadata information of the class, such as class methods and constant pools. You can think of it as java in java Lang. class object, which records all the information of the class;
OOP (Ordinary Object Pointer) refers to an Ordinary Object Pointer, which includes MarkWord and metadata pointer. MarkWord is used to store some state data of the object pointed to by the current pointer during operation; The metadata pointer points to klass, which is used to tell you what type of object the current pointer points to, that is, which class is used to create it;
So why design such a binary object model? This is because the designer of the HotSopt JVM doesn't want every object to contain a vtable (virtual function table), so he divides the object model into klass and oop. oop does not contain any virtual functions, while klass contains virtual function table, so method dispatch can be carried out.
In HotSpot, the codes of oop Klass implementation are all in the path of / hotspot/src/share/vm/oops /. oop implementation is instanceOop and arrayOop, which describe the object header. arrayOop object is used to describe the array type.
The following is OOP HHP file oopDesc source code, you can see two variables_ mark is MarkWord_ Metadata refers to the metadata pointer, which points to the klass object. The compressed pointer is 32 bits and the uncompressed pointer is 64 bits;
volatile markOop _mark; //Identify runtime data
union _metadata {
Klass* _klass;
narrowKlass _compressed_klass;
} _metadata; //klass pointerThe layout of a Java object in memory can be divided into two parts: instanceOop (inherited from oop.hpp) and instance data;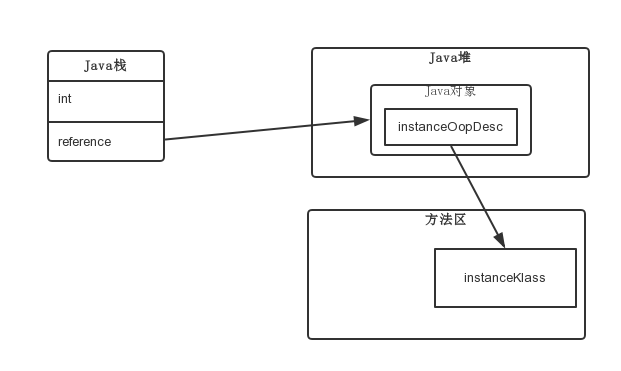
As can be seen from the above figure, find the object in the Java heap through the object reference reference in the stack frame, and then find the instanceKlass in the method area through the metadata pointer klass in the instanceOop of the object, so as to determine the type of the object.
Let's analyze what the JVM does when executing new A(). First, if the Class has not been loaded, the JVM will load the Class and create an instanceKlass object inside the JVM to represent the runtime metadata of the Class (equivalent to the Class object of the Java layer). When initializing the object (execute invokespecial A::), the JVM will create an instanceOopDesc object to represent the instance of the object, then fill in Mark Word, point the metadata pointer to the Klass object, and fill in the instance variable.
Metadata - instanceKlass object will exist in meta space (method area), while object instance instanceOopDesc will exist in Java heap. The reference of this object instance will be stored in the Java virtual machine stack.
Member variable reordering
In order to improve performance, the starting address of each object is aligned to 8 bytes. When encapsulating an object, for efficiency, the order of object field declarations will be rearranged into the following order based on byte size:
double (8 bytes) and long (8 bytes)
int (4 bytes) and float (4 bytes)
short (2 bytes) and char (2 bytes): char is 2 bytes in java. java uses unicode, two bytes (16 bits) to represent a character.
boolean (1 byte) and byte (1 byte)
reference (4 / 8 bytes)
< repeat the above order for subclass Fields >
Repeat the above sequence for subclass fields.
We can test the reordering of different types by java, using jdk1 8. Use reflection to get the unsafe class first, and then get the offset address of each field in the class, and you can see it
The test code is as follows:
import java.lang.reflect.Field;
import sun.misc.Contended;
import sun.misc.Unsafe;
public class TypeSequence {
@Contended
private boolean contended_boolean;
private volatile byte a;
private volatile boolean b;
@Contended
private int contended_short;
private volatile char d;
private volatile short c;
private volatile int e;
private volatile float f;
@Contended
private int contended_int;
@Contended
private double contended_double;
private volatile double g;
private volatile long h;
public static Unsafe UNSAFE;
static {
try {
@SuppressWarnings("ALL")
Field theUnsafe = Unsafe.class.getDeclaredField("theUnsafe");
theUnsafe.setAccessible(true);
UNSAFE = (Unsafe) theUnsafe.get(null);
} catch (Exception e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws NoSuchFieldException, SecurityException{
System.out.println("e:int \t"+UNSAFE.objectFieldOffset(TypeSequence.class.getDeclaredField("e")));
System.out.println("g:double \t"+UNSAFE.objectFieldOffset(TypeSequence.class.getDeclaredField("g")));
System.out.println("h:long \t"+UNSAFE.objectFieldOffset(TypeSequence.class.getDeclaredField("h")));
System.out.println("f:float \t"+UNSAFE.objectFieldOffset(TypeSequence.class.getDeclaredField("f")));
System.out.println("c:short \t"+UNSAFE.objectFieldOffset(TypeSequence.class.getDeclaredField("c")));
System.out.println("d:char \t"+UNSAFE.objectFieldOffset(TypeSequence.class.getDeclaredField("d")));
System.out.println("a:byte \t"+UNSAFE.objectFieldOffset(TypeSequence.class.getDeclaredField("a")));
System.out.println("b:boolean\t"+UNSAFE.objectFieldOffset(TypeSequence.class.getDeclaredField("b")));
System.out.println("contended_boolean:boolean\t"+UNSAFE.objectFieldOffset(TypeSequence.class.getDeclaredField("contended_boolean")));
System.out.println("contended_short:short\t"+UNSAFE.objectFieldOffset(TypeSequence.class.getDeclaredField("contended_short")));
System.out.println("contended_int:int\t"+UNSAFE.objectFieldOffset(TypeSequence.class.getDeclaredField("contended_int")));
System.out.println("contended_double:double\t"+UNSAFE.objectFieldOffset(TypeSequence.class.getDeclaredField("contended_double")));
}
}
The running results of the above code are as follows
e:int 12
g:double 16
h:long 24
f:float 32
c:short 38
d:char 36
a:byte 40
b:boolean 41
contended_boolean:boolean 170
contended_short:short 300
contended_int:int 432
contended_double:double 568In addition to the int field, there are two fields added with contented annotation. The other fields are sorted according to the reordering order, and the type is sorted from the longest to the shortest;
Effect of sorting member variables on objects
Some children's shoes are confused. Why did int run to the front? This is because the int field is promoted to fill the object header in front. The object header has 12 bytes. Priority will be given to selecting one or more fields in the field that can fill the object header into 16 bytes in front. If the filling is not enough, add padding. In the above example, add a 4-byte int, which is exactly 16 bytes, and the address is aligned according to 8 bytes;
The influence of extended contended on the ordering of member variables
What about the contended annotation? This annotation is to solve the problem of cpu cache line pseudo sharing. cpu cache pseudo sharing is a killer of concurrent programming performance. If you don't know what pseudo sharing is, you can check the source code interpretation of LongAdder class I wrote earlier or the article lock in java - bias lock, lightweight lock, spin lock and heavyweight lock, The fields with contented annotation will be placed at the end according to the declaration order. If the contented annotation is used on the field of the class, 128 bytes of padding will be inserted in front of the field. If it is used on the class, 128 bytes of padding will be added before and after all fields of the class.