aggregate
Collection usage scenario
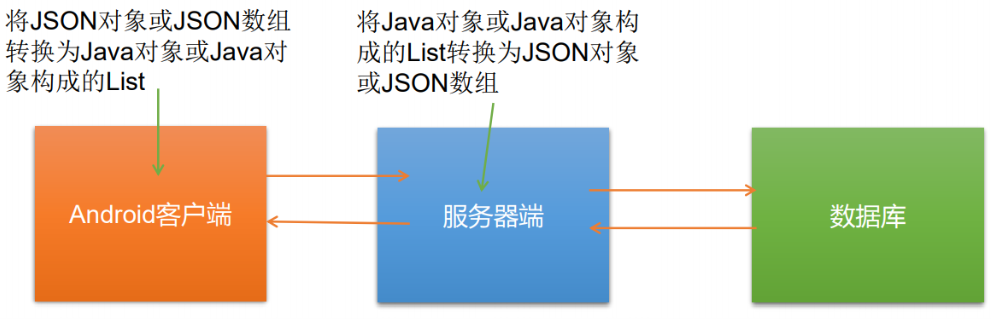
Classification of sets
-
Java collections can be divided into Collection and Map systems
-
Collection interface: single column data, which defines the collection of methods to access a group of objects
- List: an ordered and repeatable collection of elements
- Set: an unordered and non repeatable set of elements
-
Map interface: double column data, which saves the set with mapping relationship "key value pair"
Collection interface
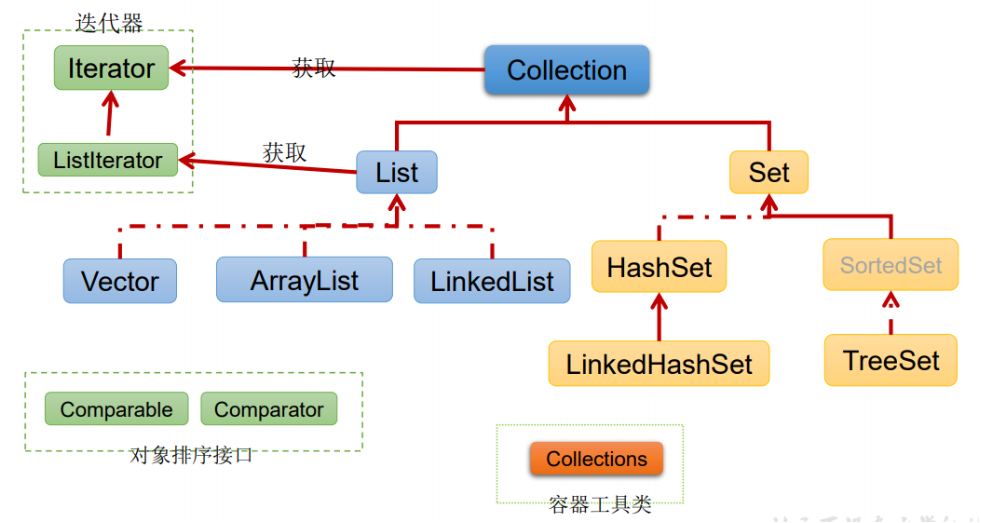
1. Collection common methods
public class CollectionMethod {
@SuppressWarnings({"all"})
public static void main(String[] args) {
List list = new ArrayList();
// Add: add a single element
list.add("jack");
list.add(10);//list.add(new Integer(10))
list.add(true);
System.out.println("list=" + list);
// remove: deletes the specified element
//list.remove(0);// Delete first element
list.remove(true);//Specifies to delete an element
System.out.println("list=" + list);
// contains: find whether the element exists
System.out.println(list.contains("jack"));//T
// size: get the number of elements
System.out.println(list.size());//2
// isEmpty: judge whether it is empty
System.out.println(list.isEmpty());//F
// Clear: clear
list.clear();
System.out.println("list=" + list);
// addAll: add multiple elements
ArrayList list2 = new ArrayList();
list2.add("The Dream of Red Mansion");
list2.add("Romance of the Three Kingdoms");
list.addAll(list2);
System.out.println("list=" + list);
// containsAll: find whether multiple elements exist
System.out.println(list.containsAll(list2));//T
// removeAll: deletes multiple elements
list.add("Liaozhai");
list.removeAll(list2);
System.out.println("list=" + list);//[Liaozhai]
// Description: demonstrate with ArrayList implementation class
}
}
2. Traversal element mode
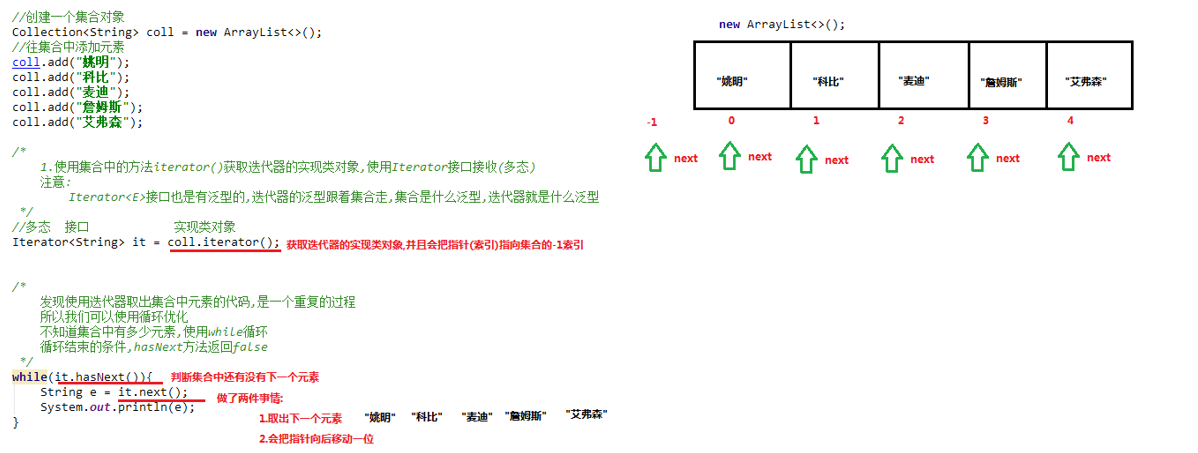
- Use Iterator
- The Iterator object is called an Iterator and is mainly used to traverse the elements in the Collection.
- All Collection classes that implement the Collection interface have an iterator0 method to return an object that implements the Iterator interface, that is, an Iterator can be returned.
- The Iterator is only used to traverse the collection, and the Iterator itself does not store objects.
public class CollectionIterator {
@SuppressWarnings({"all"})
public static void main(String[] args) {
Collection col = new ArrayList();
col.add(new Book("Romance of the Three Kingdoms", "Luo Guanzhong", 10.1));
col.add(new Book("knife man ", "Gulong", 5.1));
col.add(new Book("The Dream of Red Mansion", "Cao Xueqin", 34.6));
//System.out.println("col=" + col);
//Now the teacher wants to be able to traverse the col set
//1. Get the iterator corresponding to col first
Iterator iterator = col.iterator();
//2. Use the while loop to traverse
// while (iterator.hasNext()) {/ / judge whether there is still data
// //Returns the next element of type Object
// Object obj = iterator.next();
// System.out.println("obj=" + obj);
// }
//The teacher teaches you a shortcut key to quickly generate while = > itIt
//Show all shortcut keys ctrl + j
while (iterator.hasNext()) {
Object obj = iterator.next();
System.out.println("obj=" + obj);
}
//3. After exiting the while loop, the iterator iterator points to the last element
// iterator.next();//NoSuchElementException
//4. If we want to traverse again, we need to reset our iterator
iterator = col.iterator();
System.out.println("===Second traversal===");
while (iterator.hasNext()) {
Object obj = iterator.next();
System.out.println("obj=" + obj);
}
}
}
class Book {
private String name;
private String author;
private double price;
public Book(String name, String author, double price) {
this.name = name;
this.author = author;
this.price = price;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
@Override
public String toString() {
return "Book{" +
"name='" + name + '\'' +
", author='" + author + '\'' +
", price=" + price +
'}';
}
}
3. List interface
- The List interface is a sub interface of the Collection interface
-
- The elements in the List collection class are ordered (that is, the order of addition and extraction) and repeatable
-
- Each element in the List collection has its corresponding sequential index, that is, it supports index.
-
- The elements in the List container correspond to an integer serial number, recording their position in the container. The elements in the container can be accessed according to the serial number.
1. Methods of the List interface
public class ListMethod {
@SuppressWarnings({"all"})
public static void main(String[] args) {
List list = new ArrayList();
list.add("Zhang Sanfeng");
list.add("Jia Baoyu");
// void add(int index, Object ele): inserts an ele element at the index position
//Insert an object at index = 1
list.add(1, "oracle ");
System.out.println("list=" + list);
// boolean addAll(int index, Collection eles): add all elements in eles from the index position
List list2 = new ArrayList();
list2.add("jack");
list2.add("tom");
list.addAll(1, list2);
System.out.println("list=" + list);
// Object get(int index): gets the element at the specified index position
//Yes
// int indexOf(Object obj): returns the position where obj first appears in the collection
System.out.println(list.indexOf("tom"));//2
// int lastIndexOf(Object obj): returns the last occurrence of obj in the current collection
list.add("oracle ");
System.out.println("list=" + list);
System.out.println(list.lastIndexOf("oracle "));
// Object remove(int index): removes the element at the specified index position and returns this element
list.remove(0);
System.out.println("list=" + list);
// Object set(int index, Object ele): sets the element at the specified index position to ele, which is equivalent to replacement
list.set(1, "Mary");
System.out.println("list=" + list);
// List subList(int fromIndex, int toIndex): returns a subset from fromIndex to toIndex
// Note the returned subset fromindex < = sublist < toindex
List returnlist = list.subList(0, 2);
System.out.println("returnlist=" + returnlist);
}
}
2,ArrayList
1. Precautions
- ArrayList can add null, and there can be multiple
- ArrayList implements data storage by arrays
- ArrayList is basically equivalent to Vector, except that ArrayList is thread unsafe (high execution efficiency). Look at the source code ArrayList is not recommended for multithreading
2. Source code analysis
- 1. ArrayList maintains an array of object type elementdata [transient Object[] elementData ]
- Transient indicates instantaneous and transient, indicating that the attribute will not be used by the serial number
- 2. When creating an object, if a parameterless constructor is used, the initial elementData capacity is 0 (jdk7 is 10)
- 3. When adding elements: first judge whether capacity expansion is required. If capacity expansion is required, call the grow method. Otherwise, directly add elements to the appropriate location
- 4. If a parameterless constructor is used, if it needs to be expanded for the first time, the expanded elementData is 10. If it needs to be expanded again, the expanded elementData is 1.5 times.
- 5. If you are using a constructor that specifies capacity, the initial elementData capacity is capacity
- 6. If the constructor with the specified capacity is used, if the capacity needs to be expanded, directly expand the capacity of elementData to 1.5 times

3,Vector
1. Basic introduction
-
The bottom layer of Vector is also an object array, protected Object] elementData;
-
Vector is thread synchronous, that is, thread safe. The operation methods of vector class are synchronized
public synchronized void copyInto(Object[] anArray) { System.arraycopy(elementData, 0, anArray, 0, elementCount); } public synchronized void trimToSize() { modCount++; int oldCapacity = elementData.length; if (elementCount < oldCapacity) { elementData = Arrays.copyOf(elementData, elementCount); } }
2. Source code analysis
- In development, when thread synchronization safety is required, consider using Vector
public class Vector_ {
public static void main(String[] args) {
//Parameterless constructor
//Parametric construction
Vector vector = new Vector(8);
for (int i = 0; i < 10; i++) {
vector.add(i);
}
vector.add(100);
System.out.println("vector=" + vector);
//Lao Han interpretation source code
//1. new Vector() bottom layer
/*
public Vector() {
this(10);
}
Supplement: if it is Vector vector = new Vector(8);
How to walk:
public Vector(int initialCapacity) {
this(initialCapacity, 0);
}
2. vector.add(i)
2.1 //The following method adds data to the vector collection
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}
2.2 //Determine whether capacity expansion is required: mincapacity - elementdata length>0
private void ensureCapacityHelper(int minCapacity) {
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
2.3 //If the required array size is not enough, expand the capacity, and the expansion algorithm
//newCapacity = oldCapacity + ((capacityIncrement > 0) ?
// capacityIncrement : oldCapacity);
//That's double the expansion
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
*/
}
}
3. ArrayList and Vector comparison
| Bottom structure | edition | Thread safety (synchronization) efficiency | Expansion multiple | |
|---|---|---|---|---|
| ArrayList | Variable array | jdk1.2 | Unsafe and efficient | If a parametric constructor is used, the capacity shall be expanded by 1.5 times. If a nonparametric constructor is used, it shall be 10 for the first time and 1.5 times for the second time |
| Vector | Variable array Object [] | jdk1.0 | Safety and low efficiency | If a parametric constructor is used, double the capacity. If a nonparametric constructor is used, it is 10 for the first time and double the capacity for the second time |
4,LinkedList
1. Basic introduction
- 1. LinkedList bottom layer implements the characteristics of two-way linked list and two terminal queue
- 2. You can add any element (elements can be repeated), including null
- 3. Thread is unsafe and synchronization is not implemented
2. Source code analysis
- 1. The underlying LinkedList maintains a two - way linked list
- 2. The LinkedList maintains two attributes, first and last, which point to the first node and the last node respectively
- 3. Each Node (Node object) maintains prev Next and item attributes, in which prev points to the previous Node and next points to the next Node. Finally, the bidirectional linked list is realized
- 4. Therefore, the addition and deletion of LinkedList elements are not completed through arrays, which is relatively efficient.
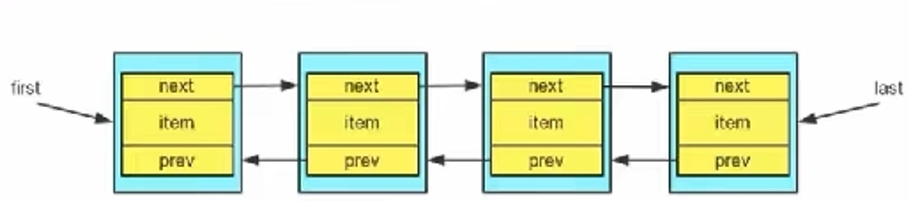
public class LinkedListCRUD {
public static void main(String[] args) {
LinkedList linkedList = new LinkedList();
linkedList.add(1);
linkedList.add(2);
linkedList.add(3);
System.out.println("linkedList=" + linkedList);
//Demonstrate a method of deleting nodes
linkedList.remove(); // The first node is deleted by default
//linkedList.remove(2);
System.out.println("linkedList=" + linkedList);
//Modify a node object
linkedList.set(1, 999);
System.out.println("linkedList=" + linkedList);
//Get a node object
//get(1) is the second object to get the bidirectional linked list
Object o = linkedList.get(1);
System.out.println(o);//999
//Because LinkedList implements the List interface and traversal mode
System.out.println("===LinkeList Traversal iterator====");
Iterator iterator = linkedList.iterator();
while (iterator.hasNext()) {
Object next = iterator.next();
System.out.println("next=" + next);
}
System.out.println("===LinkeList Ergodic enhancement for====");
for (Object o1 : linkedList) {
System.out.println("o1=" + o1);
}
System.out.println("===LinkeList Ergodic ordinary for====");
for (int i = 0; i < linkedList.size(); i++) {
System.out.println(linkedList.get(i));
}
//Old Korean source code reading
/* 1. LinkedList linkedList = new LinkedList();
public LinkedList() {}
2. At this time, the linklist property first = null, last = null
3. Execute add
public boolean add(E e) {
linkLast(e);
return true;
}
4.Add the new node to the end of the bidirectional linked list
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
*/
/*
Lao Han reads the source code LinkedList remove(); // The first node is deleted by default
1. Execute removeFirst
public E remove() {
return removeFirst();
}
2. implement
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
3. Execute unlinkFirst to remove the first node of the two-way linked list pointed to by f
private E unlinkFirst(Node<E> f) {
// assert f == first && f != null;
final E element = f.item;
final Node<E> next = f.next;
f.item = null;
f.next = null; // help GC
first = next;
if (next == null)
last = null;
else
next.prev = null;
size--;
modCount++;
return element;
}
*/
}
}
3. ArrayList and LinkedList comparison
| Bottom structure | Addition and deletion efficiency | Modification efficiency | |
|---|---|---|---|
| ArrayList | Variable array | Low, array expansion | higher |
| LinkedList | Bidirectional linked list | High, append through linked list | Lower |
How to select ArrayList and LinkedList:
- 1. If we have many operations to change, select ArrayList
- 2. If we add and delete many operations, select LinkedList
- 3. Generally speaking, in the program, 80% - 90% are queries, so ArrayList will be selected in most cases
- 4) In a project, it can be selected flexibly according to the business. One module uses ArrayList and the other module uses LinkedList
4. Set interface
1. Basic introduction
- Out of order (the order of addition and extraction is inconsistent) and there is no index
- Duplicate elements are not allowed, so it can contain at most one null
2. Traversal mode
- You can use iterators
- Enhanced for
- Cannot be retrieved by index
3,HashSet
1. Basic introduction
-
HashSet implements the Set interface
-
HashSet is actually a HashMap
public HashSet() { map = new HashMap<>(); } -
You can store null values, but there can only be one null value
-
HashSet does not guarantee that the elements are ordered. It depends on the result of determining the index after hash
-
Cannot have duplicate elements / objects
2. Source code analysis
-
The bottom layer of HashMap is: array + linked list + red black tree
-
The bottom layer of HashSet is HashMap. When adding for the first time, the table array is expanded to 16, and the threshold is 16 * the LoadFactor is 0.75 = 12
-
If the table array uses the critical value of 12, it will be expanded to 16 * 2 = 32, and the new critical value is 32 * 0.75 = 24, and so on
-
In Java 8, if the number of elements in a linked list reaches treeify_ Threshold (default is 8) If the size of the table > = min tree capability (64 by default), it will be trealized (red black tree) Otherwise, the array expansion mechanism is still used
-
1. Get the hash value of the element first (hashCode method)
-
2. Calculate the hash value to obtain an index value, that is, the position number to be stored in the hash table
-
3. If there are no other elements in this position, the value is stored
- If there are other elements in this position, you need to judge the equals. If they are equal, they will not be added. If they are not equal, they are added as a linked list.
public class HashSet01 {
public static void main(String[] args) {
HashSet set = new HashSet();
//explain
//1. After executing the add method, a boolean value will be returned
//2. If the addition is successful, return true; otherwise, return false
//3. You can specify which object to delete through remove
System.out.println(set.add("john"));//T
System.out.println(set.add("lucy"));//T
System.out.println(set.add("john"));//F
System.out.println(set.add("jack"));//T
System.out.println(set.add("Rose"));//T
set.remove("john");
System.out.println("set=" + set);//3
//
set = new HashSet();
System.out.println("set=" + set);//0
//4 can't HashSet add the same element / data?
set.add("lucy");//Added successfully
set.add("lucy");//Can't join
set.add(new Dog("tom"));//OK
set.add(new Dog("tom"));//Ok
System.out.println("set=" + set);
//It's deepening Very classic interview questions
//Look at the source code and do analysis. First leave a hole for the little partner. After talking about the source code, you will know
//Go to his source code, that is, what happened to add? = > Underlying mechanism
set.add(new String("hsp"));//ok
set.add(new String("hsp"));//I can't join
System.out.println("set=" + set);
}
}
class Dog { //The Dog class is defined
private String name;
public Dog(String name) {
this.name = name;
}
@Override
public String toString() {
return "Dog{" +
"name='" + name + '\'' +
'}';
}
}
public class HashSetSource {
public static void main(String[] args) {
HashSet hashSet = new HashSet();
hashSet.add("java");//At this position, the first add analysis is completed
hashSet.add("php");//At this position, the second add analysis is completed
hashSet.add("java");
System.out.println("set=" + hashSet);
/*
Lao Han's interpretation of the source code of HashSet
1. Execute HashSet()
public HashSet() {
map = new HashMap<>();
}
2. Execute add()
public boolean add(E e) {//e = "java"
return map.put(e, PRESENT)==null;//(static) PRESENT = new Object();
}
3.Execute put(), which will execute hash(key) to get the hash value corresponding to the key, and the algorithm H = key hashCode()) ^ (h >>> 16)
public V put(K key, V value) {//key = "java" value = PRESENT share
return putVal(hash(key), key, value, false, true);
}
4.Execute putVal
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i; //Auxiliary variables are defined
//table It is an array of HashMap. The type is Node []
//if Statement indicates if the current table is null or size = 0
//This is the first expansion to 16 spaces
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//(1)According to the key, get the hash to calculate which index position the key should be stored in the table
//And assign the object at this position to p
//(2)Determine whether p is null
//(2.1) If p is null, it means that the element has not been stored, and a node is created (key = "Java", value = present)
//(2.2) Put it in this position tab[i] = newNode(hash, key, value, null)
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
//A development tip: when you need local variables (auxiliary variables), create
Node<K,V> e; K k; //
//If the first element of the linked list corresponding to the current index position is the same as the hash value of the key to be added
//And meet one of the following two conditions:
//(1) The key to be added and the key of the Node pointed to by p are the same object
//(2) p The equals() of the key of the Node pointed to is the same as the key to be added after comparison
//You can't join
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//Then judge whether p is a red black tree,
//If it is a red black tree, call putTreeVal to add it
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {//If the table corresponds to the index position and is already a linked list, use the for loop comparison
//(1) If it is different from each element of the linked list in turn, it will be added to the end of the linked list
// Note that after adding elements to the linked list, you can immediately judge whether the linked list has reached 8 nodes
// , Call treeifyBin() to tree the current linked list (turn it into a red black tree)
// Note that when turning to red black tree, judge the conditions
// if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY(64))
// resize();
// If the above conditions are true, expand the table first
// Only when the above conditions are not tenable can it be transformed into red black tree
//(2) In the process of comparing with each element of the linked list in turn, if there is the same situation, break directly
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD(8) - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//size That is, every time we add a node Node(k,v,h,next), size++
if (++size > threshold)
resize();//Capacity expansion
afterNodeInsertion(evict);
return null;
}
*/
}
}
4,LinkedHashSet
1. Basic introduction
-
1. LinkedHashSet is a subclass of HashSet
-
2. The underlying layer of LinkedHashSet is a LinkedHashMap, and the underlying layer maintains an array + two-way linked list
-
3. LinkedHashSet determines the storage location of elements according to the hashCode value of elements, and uses the linked list to maintain the order of elements (Figure), which makes the elements appear to be saved in insertion order.
-
4. LinkedHashSet does not allow adding duplicate elements
2. Source code analysis
- 1. A hash table and a two-way linked list are maintained in the LinkedHastSet (the LinkedHastSet has head and tail)
- 2. Each node has before and after attributes, which can form a two-way linked list. 3) when adding an element, first calculate the hash value and then the index Determine the position of the element in the table, and then add the added element to the two-way linked list (if it already exists, do not add it [the principle is the same as hashset])
- tail.next = newElement / / schematic code
- newElement.pre = tail
- tail = newEelment;
- 3. In this way, we can traverse the LinkedHashSet to ensure that the insertion order is consistent with the traversal order
public class LinkedHashSetSource {
public static void main(String[] args) {
//Analyze the underlying mechanism of LinkedHashSet
Set set = new LinkedHashSet();
set.add(new String("AA"));
set.add(456);
set.add(456);
set.add(new Customer("Liu", 1001));
set.add(123);
set.add("HSP");
System.out.println("set=" + set);
//Lao Han's interpretation
//1. The order of adding linkedhashset is consistent with the order of taking out elements / data
//2. A LinkedHashMap (a subclass of HashMap) is maintained at the bottom of the linkedhashset
//3. LinkedHashSet underlying structure (array table + bidirectional linked list)
//4. When adding for the first time, directly expand the array table to 16, and the stored node type is LinkedHashMap$Entry
//5. The array is the element / data stored in HashMap$Node [] and is of type LinkedHashMap$Entry
// Polymorphism
/*
The inheritance relationship is completed in the inner class
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
*/
}
}
class Customer {
private String name;
private int no;
public Customer(String name, int no) {
this.name = name;
this.no = no;
}
}
5,TreeSet
public class TreeSet_ {
public static void main(String[] args) {
//Lao Han's interpretation
//1. When we use a parameterless constructor to create a TreeSet, it is still out of order
//2. The elements that the teacher wants to add are sorted according to the size of the string
//3. A comparator (anonymous inner class) can be passed in using a constructor provided by TreeSet
// And specify the collation
//4. Simply look at the source code
//Lao Han's interpretation
/*
1. The constructor assigns the passed in comparator object to the attribute this. Of the underlying TreeMap of TreeSet comparator
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}
2. When calling TreeSet Add ("Tom") will be executed at the bottom
if (cpr != null) {//cpr Is our anonymous inner class (object)
do {
parent = t;
//Dynamically bind to our anonymous inner class (object) compare
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else //If it is equal, it returns 0, and the Key is not added
return t.setValue(value);
} while (t != null);
}
*/
// TreeSet treeSet = new TreeSet();
TreeSet treeSet = new TreeSet(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
//Next, call the compareTo method of String to compare the String size
//If Lao Han asks to add elements, they are sorted by length
//return ((String) o2).compareTo((String) o1);
return ((String) o1).length() - ((String) o2).length();
}
});
//Add data
treeSet.add("jack");
treeSet.add("tom");//3
treeSet.add("sp");
treeSet.add("a");
treeSet.add("abc");//3
System.out.println("treeSet=" + treeSet);
}
}
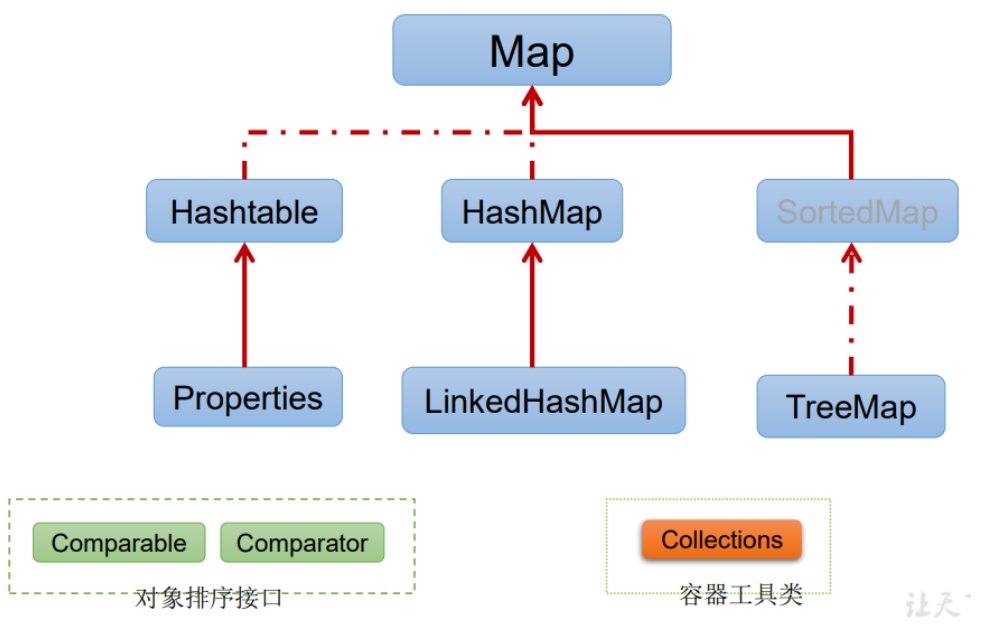
Map interface
1. Characteristics
- 1. Map and Collection exist side by side. Used to save data with mapping relationship: key value
- 2. The key and value in the Map can be data of any reference type and will be encapsulated in the HashMap$Node object
- 3. Duplicate key s in Map are not allowed for the same reason as HashSet
- 4. The value in the Map can be repeated
- 5. The key and value of Map can be null. Note that there can be only one key and multiple values
- 6. String class is often used as the key of Map
- 7. There is a one-way one-to-one relationship between key and value, that is, the corresponding value can always be found through the specified key
- 8. For the key value diagram of Map storing data, a pair of k-v is placed in a Node. Because the Node implements the Entry interface, some books also say that a pair of k-v is an Entry (as shown in the figure)
public class MapFor {
public static void main(String[] args) {
Map map = new HashMap();
map.put("Deng Chao", "Sun Li");
map.put("Wang Baoqiang", "Ma Rong");
map.put("Song Zhe", "Ma Rong");
map.put("Liu Lingbo", null);
map.put(null, "Liu Yifei");
map.put("Lu Han", "Guan Xiaotong");
//Group 1: take out all keys first, and take out the corresponding Value through the Key
Set keyset = map.keySet();
//(1) Enhanced for
System.out.println("-----The first way-------");
for (Object key : keyset) {
System.out.println(key + "-" + map.get(key));
}
//(2) Iterator
System.out.println("----The second way--------");
Iterator iterator = keyset.iterator();
while (iterator.hasNext()) {
Object key = iterator.next();
System.out.println(key + "-" + map.get(key));
}
//Group 2: take out all values
Collection values = map.values();
//Here you can use the traversal methods used by all Collections
//(1) Enhanced for
System.out.println("---Remove all value enhance for----");
for (Object value : values) {
System.out.println(value);
}
//(2) Iterator
System.out.println("---Remove all value iterator ----");
Iterator iterator2 = values.iterator();
while (iterator2.hasNext()) {
Object value = iterator2.next();
System.out.println(value);
}
//Group 3: get k-v through EntrySet
Set entrySet = map.entrySet();// EntrySet<Map.Entry<K,V>>
//(1) Enhanced for
System.out.println("----use EntrySet of for enhance(Type 3)----");
for (Object entry : entrySet) {
//Convert entry to map Entry
Map.Entry m = (Map.Entry) entry;
System.out.println(m.getKey() + "-" + m.getValue());
}
//(2) Iterator
System.out.println("----use EntrySet Iterator for(Type 4)----");
Iterator iterator3 = entrySet.iterator();
while (iterator3.hasNext()) {
Object entry = iterator3.next();
//System.out.println(next.getClass());//HashMap$Node - Implementation - > map Entry (getKey,getValue)
//Transition down map Entry
Map.Entry m = (Map.Entry) entry;
System.out.println(m.getKey() + "-" + m.getValue());
}
}
}
public class MapSource_ {
public static void main(String[] args) {
Map map = new HashMap();
map.put("no1", "oracle ");//k-v
map.put("no2", "zhang wuji");//k-v
map.put(new Car(), new Person());//k-v
//Lao Han's interpretation
//1. k-v finally HashMap$Node node = newNode(hash, key, value, null)
//2. k-v in order to facilitate the programmer's traversal, an EntrySet collection is also created. The type of element stored in this collection is Entry, and an Entry
// The object has k, V entryset < entry < K, V > > that is, transient set < map Entry<K,V>> entrySet;
//3. In the entryset, the defined type is map Entry, but the HashMap$Node is actually stored
// Because static class node < K, V > implements map Entry<K,V>
//4. When the HashMap$Node object is stored in the entrySet, it is convenient for us to traverse, because the map Entry provides an important method
// K getKey(); V getValue();
Set set = map.entrySet();
System.out.println(set.getClass());// HashMap$EntrySet
for (Object obj : set) {
//System.out.println(obj.getClass()); //HashMap$Node
//To extract k-v from HashMap$Node
//1. Make a downward transformation first
Map.Entry entry = (Map.Entry) obj;
System.out.println(entry.getKey() + "-" + entry.getValue() );
}
Set set1 = map.keySet();
System.out.println(set1.getClass());
Collection values = map.values();
System.out.println(values.getClass());
}
}
class Car {}
class Person{}
2,HashMap
1. HashMap summary
- 1. Common implementation classes of Map interface: HashMap, Hashtable and Properties
- 2. HashMap is the most frequently used implementation class of Map interface.
- 3. HashMap stores data in key Val pairs (HashMap$Node type)
- 4. The key cannot be repeated, but the value can be repeated. Null keys and null values are allowed.
- 5. If the same key is added, the original key val will be overwritten, which is equivalent to modification (key will not be replaced, val will be replaced)
- 6. Like HashSet, the mapping order is not guaranteed, because the underlying is stored in the form of hash table (jdk8's hashMap bottom array + linked list + red black tree)
- 7. HashMap does not achieve synchronization, so it is thread unsafe. The method does not synchronize and mutually exclusive, and is not synchronized
2. Source code analysis
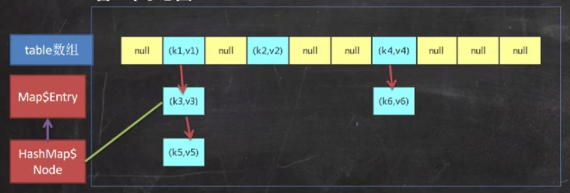
- 1. (k,v) is a Node that implements map Entry < K, V >, you can see the source code of HashMap
- 2,jdk7.0's hashmap underlying implementation [array + linked list], jdk8 0 bottom layer [array + linked list + red black tree]
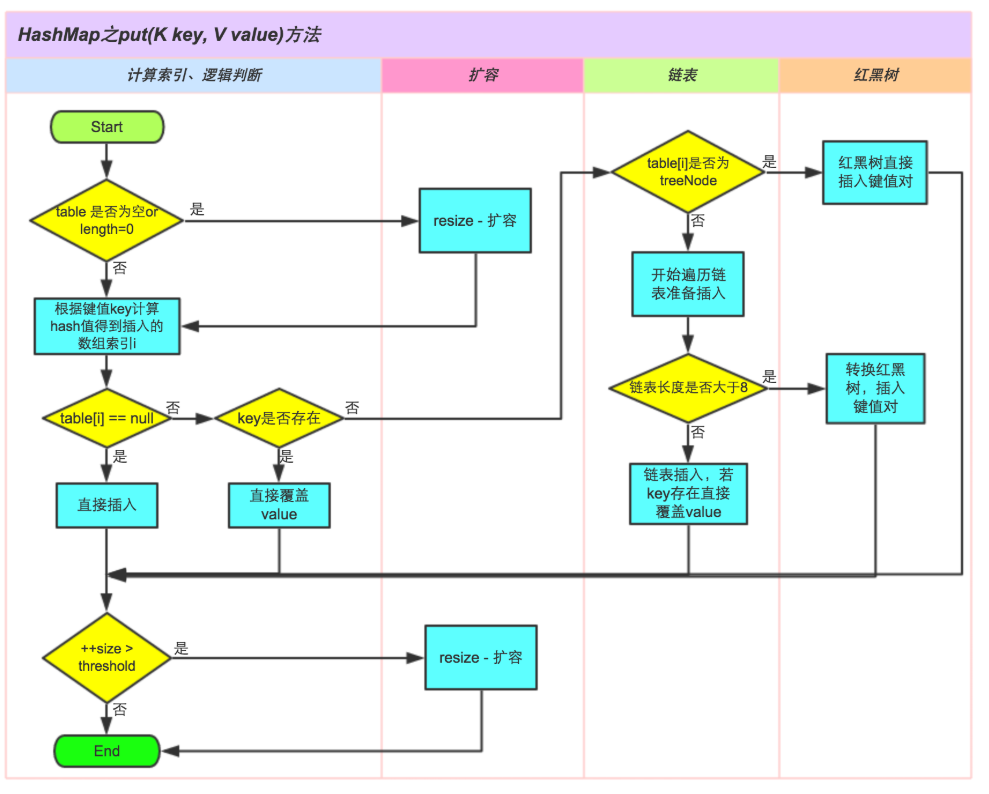
Capacity expansion mechanism
- 1. The underlying layer of HashMap maintains an array table of Node type, which is null by default
- 2. When creating an object, initialize the load factor to 0.75
- 3. When adding key val, the index in the table is obtained through the hash value of the key. Then judge whether there are elements at the index. If there are no elements, add them directly. If there is an element in the index, continue to judge whether the key of the element is consistent with the key to be added. If it is equal, directly replace val; If it is not equal, you need to judge whether it is a tree structure or a linked list structure and deal with it accordingly. If it is found that the capacity is insufficient when adding, it needs to be expanded.
- 4. For the first addition, the capacity of the table needs to be expanded. The capacity is 16 and the threshold is 12 (16 * 0.75)
- 5. For future capacity expansion, the capacity of the table needs to be twice as large (32), the critical value is twice as large (24), and so on
- 6. In Java 8, if the number of elements in a linked list exceeds tree threshold (8 by default), and the size of the table > = min tree capability (64 by default), it will be trealized (red black tree)
public class HashMapSource1 {
public static void main(String[] args) {
HashMap map = new HashMap();
map.put("java", 10);//ok
map.put("php", 10);//ok
map.put("java", 20);//Replace value
System.out.println("map=" + map);//
/*Lao Han interprets the source code + diagram of HashMap
1. Execute constructor new HashMap()
Initialization load factor loadfactor = 0.75
HashMap$Node[] table = null
2. Execute put, call the hash method, and calculate the hash value of the key (H = key. Hashcode()) ^ (H > > > 16)
public V put(K key, V value) {//K = "java" value = 10
return putVal(hash(key), key, value, false, true);
}
3. Execute putVal
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;//Auxiliary variable
//If the underlying table array is null or length =0, it will be expanded to 16
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//Take out the Node at the index position of the table corresponding to the hash value. If it is null, directly add the k-v
//, Create a Node and join the location
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;//Auxiliary variable
// If the hash value of the key at the index position of the table is the same as that of the new key,
// (the key of the existing node of the table and the key to be added are the same object | equals returns true)
// I think we can't add a new k-v
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)//If the existing Node of the current table is a red black tree, it will be processed as a red black tree
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//If the found node is followed by a linked list, it will be compared circularly
for (int binCount = 0; ; ++binCount) {//Dead cycle
if ((e = p.next) == null) {//If the whole linked list is not the same as him, it will be added to the end of the linked list
p.next = newNode(hash, key, value, null);
//After adding, judge whether the number of the current linked list has reached 8, and then
//The treeifyBin method is called to convert the red black tree
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash && //If you find the same in the process of cyclic comparison, you break and just replace value
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value; //Replace, key corresponds to value
afterNodeAccess(e);
return oldValue;
}
}
++modCount;//Every time a Node is added, the size is increased++
if (++size > threshold[12-24-48])//If size > critical value, expand the capacity
resize();
afterNodeInsertion(evict);
return null;
}
5. About tree (turning into red black tree)
//If the table is null or the size has not reached 64, it will not be treed temporarily, but will be expanded
//Otherwise, it will be really trealized - > pruning (after treeing, delete nodes and convert them into linked lists to a certain extent)
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
}
*/
}
}
3,Hashtable
1. Characteristics
- 1. The stored elements are key value pairs: K-V
- 2. Neither key nor value of hashtable can be null
- 3. hashTable is basically used in the same way as HashMap
- 4. hashTable is thread safe and hashMap is thread unsafe
public class HashTableExercise {
public static void main(String[] args) {
Hashtable table = new Hashtable();//ok
table.put("john", 100); //ok
//table.put(null, 100); // Exception NullPointerException
//table.put("john", null);// Exception NullPointerException
table.put("lucy", 100);//ok
table.put("lic", 100);//ok
table.put("lic", 88);//replace
table.put("hello1", 1);
table.put("hello2", 1);
table.put("hello3", 1);
table.put("hello4", 1);
table.put("hello5", 1);
table.put("hello6", 1);
System.out.println(table);
//Briefly explain the bottom layer of Hashtable
//1. There is an array Hashtable$Entry [] in the bottom layer. The initialization size is 11
//2. threshold 8 = 11 * 0.75
//3. Capacity expansion: just follow your own capacity expansion mechanism
//4. Execute the method addEntry(hash, key, value, index); Add K-V encapsulation to Entry
//5. Expand the capacity when if (count > = threshold) is satisfied
//5. According to int newcapacity = (oldcapacity < < 1) + 1; The size of the expansion
}
}
Comparison between HashMap and Hashtable
| edition | Thread safe (synchronous) | efficiency | Allow null keys and null values | |
|---|---|---|---|---|
| HashMap | 1.2 | unsafe | high | sure |
| Hashtable | 1.0 | security | Lower | may not |
4,Properties
1. Basic introduction
- 1. The Properties class inherits from the Hashtable class and implements the Map interface. It also uses a key value pair to save data.
- 2. Its usage features are similar to Hashtable
- 3. Properties can also be used from XXX In the properties file, load the data into the properties class object, and read and modify it
public class Properties_ {
public static void main(String[] args) {
//Lao Han's interpretation
//1. Properties inherit Hashtable
//2. Data can be stored through k-v. of course, key and value cannot be null
//increase
Properties properties = new Properties();
//properties.put(null, "abc");// Throw null pointer exception
//properties.put("abc", null); // Throw null pointer exception
properties.put("john", 100);//k-v
properties.put("lucy", 100);
properties.put("lic", 100);
properties.put("lic", 88);//If there is the same key, value is replaced
System.out.println("properties=" + properties);
//Obtain the corresponding value through k
System.out.println(properties.get("lic"));//88
//delete
properties.remove("lic");
System.out.println("properties=" + properties);
//modify
properties.put("john", "John");
System.out.println("properties=" + properties);
}
}
5,TreeMap
public class TreeMap_ {
public static void main(String[] args) {
//Using the default constructor, create a TreeMap that is unordered (and not sorted)
/*
Lao Han requires sorting according to the size of the incoming k(String)
*/
// TreeMap treeMap = new TreeMap();
TreeMap treeMap = new TreeMap(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
//Sort by the size of the k(String) passed in
//Sort by the length of K(String)
//return ((String) o2).compareTo((String) o1);
return ((String) o2).length() - ((String) o1).length();
}
});
treeMap.put("jack", "jack");
treeMap.put("tom", "Tom");
treeMap.put("kristina", "Cristino");
treeMap.put("smith", "smith ");
treeMap.put("hsp", "oracle ");//Can't join
System.out.println("treemap=" + treeMap);
/*
Lao Han interpretation source code:
1. Constructor Pass the passed in anonymous inner class (object) that implements the comparator interface to the comparator of TreeMap
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}
2. Call the put method
2.1 For the first time, encapsulate the k-v into the Entry object and put it into root
Entry<K,V> t = root;
if (t == null) {
compare(key, key); // type (and possibly null) check
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
2.2 Add later
Comparator<? super K> cpr = comparator;
if (cpr != null) {
do { //Traverse all keys to find the appropriate location for the current key
parent = t;
cmp = cpr.compare(key, t.key);//compare dynamically bound to our anonymous inner class
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else //If the Key to be added is found to be equal to the existing Key during traversal, it will not be added
return t.setValue(value);
} while (t != null);
}
*/
}
},
Collections
public class Collections_ {
public static void main(String[] args) {
//Create an ArrayList collection for testing
List list = new ArrayList();
list.add("tom");
list.add("smith");
list.add("king");
list.add("milan");
list.add("tom");
//reverse(List): reverses the order of elements in the List
Collections.reverse(list);
System.out.println("list=" + list);
//shuffle(List): randomly sort the elements of the List collection
// for (int i = 0; i < 5; i++) {
// Collections.shuffle(list);
// System.out.println("list=" + list);
// }
// sort(List): sorts the elements of the specified List set in ascending order according to the natural order of the elements
Collections.sort(list);
System.out.println("After natural sorting");
System.out.println("list=" + list);
// sort(List, Comparator): sort the List collection elements according to the order generated by the specified Comparator
//We want to sort by the length and size of the string
Collections.sort(list, new Comparator() {
@Override
public int compare(Object o1, Object o2) {
//Verification codes can be added
return ((String) o2).length() - ((String) o1).length();
}
});
System.out.println("String length size sort=" + list);
// swap(List, int, int): exchange the elements at i and j in the specified list set
//such as
Collections.swap(list, 0, 1);
System.out.println("Situation after exchange");
System.out.println("list=" + list);
//Object max(Collection): returns the largest element in a given collection according to the natural order of elements
System.out.println("Natural order maximum element=" + Collections.max(list));
//Object max(Collection, Comparator): returns the largest element in a given collection according to the order specified by the Comparator
//For example, we want to return the element with the largest length
Object maxObject = Collections.max(list, new Comparator() {
@Override
public int compare(Object o1, Object o2) {
return ((String)o1).length() - ((String)o2).length();
}
});
System.out.println("Maximum length element=" + maxObject);
//Object min(Collection)
//Object min(Collection,Comparator)
//For the above two methods, refer to max
//int frequency(Collection, Object): returns the number of occurrences of the specified element in the specified collection
System.out.println("tom Number of occurrences=" + Collections.frequency(list, "tom"));
//void copy(List dest,List src): copy the contents of src to dest
ArrayList dest = new ArrayList();
//In order to complete a full copy, we need to assign dest, size and list Same as size ()
for(int i = 0; i < list.size(); i++) {
dest.add("");
}
//Copy
Collections.copy(dest, list);
System.out.println("dest=" + dest);
//Boolean replaceall (List, Object oldVal, Object newVal): replaces all old values of the List object with new values
//If there is tom in the list, replace it with tom
Collections.replaceAll(list, "tom", "Tom");
System.out.println("list After replacement=" + list);
}
}
Collection summary
-
In development, the selection of set implementation class mainly depends on the business operation characteristics, and then the selection is made according to the characteristics of set implementation class. The analysis is as follows:
-
1) First determine the type of storage (a group of objects [single column] or a group of key value pairs [double columns)
-
2) A set of objects [single column]: Collection interface
- Allow duplicates: List
- Add / delete: LinkedList [a two-way linked list is maintained at the bottom]
- Change query: ArrayList [variable array of Object type maintained at the bottom]
- Duplicate not allowed: Set
- Unordered: HashSet [the bottom layer is HashMap, which maintains a hash table (array + linked list + red black tree)]
- Sort: TreeSet [Lao Han's example]
- The order of insertion and extraction is the same: LinkedHashSet [underlying HashMap of underlying LinkeHashMap], maintenance array + bidirectional linked list
- Allow duplicates: List
-
3) A set of key value pairs: Map
- Key disorder: HashMap [bottom layer: hash table jdk7: array + linked list, jdk8: array + linked list + red black tree]
- Key sorting: TreeMap
- The order of key insertion and extraction is the same: LinkedHashMap
- Read file: Properties
-
Try to analyze how HashSet and TreeSet realize de duplication respectively
-
(1) HashSet's de duplication mechanism: hashCode() + equals(), the bottom layer first stores the object and obtains a hash value through operation, and then obtains the corresponding index through the hash value. If there is no data found in the location of the table index, it will be stored directly. If there is data, it will be compared with equals [traversal comparison]. If it is different after comparison, it will be added, otherwise it will not be added
-
(2)TreeSet's de duplication mechanism: if you pass in a Comparator anonymous object, use the implemented compare to de duplication. If the method returns 0, it is considered to be the same element / data and will not be added. If you do not pass in a Comparator anonymous object, use the compareTo of the comparable interface implemented by the object you added to de duplication
public class Homework06 {
public static void main(String[] args) {
HashSet set = new HashSet();//ok
Person p1 = new Person(1001,"AA");//ok
Person p2 = new Person(1002,"BB");//ok
set.add(p1);//ok
set.add(p2);//ok
p1.name = "CC";
set.remove(p1);
System.out.println(set);//2
set.add(new Person(1001,"CC"));
System.out.println(set);//3
set.add(new Person(1001,"AA"));
System.out.println(set);//4
}
}
class Person {
public String name;
public int id;
public Person(int id, String name) {
this.name = name;
this.id = id;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return id == person.id &&
Objects.equals(name, person.name);
}
@Override
public int hashCode() {
return Objects.hash(name, id);
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", id=" + id +
'}';
}
}