Download Spark on Spark official website
Spark Download The version is free. After downloading, extract it and put it under bigdata (the directory can be changed)
Download the file winutils.exe required by Hadoop under Windows
Let's find it on the Internet. It won't be uploaded here. In fact, this file is optional, and error reporting doesn't affect Spark's operation. Obsessive-compulsive disorder can be downloaded, so I have obsessive-compulsive disorder ~ ~. After downloading, the file will be placed in bigdata\hadoop\bin directory.
You do not need to create environment variables, and then define system variables at the beginning of Java, as follows:
System.setProperty("hadoop.home.dir", HADOOP_HOME);
Create Java Maven project Java spark SQL Excel
The establishment of related directory levels is as follows:
Parent directory (the directory where the project is located)
- java-spark-sql-excel
- bigdata
- spark
- hadoop
- bin
- winutils.exe
Code
Initialize SparkSession
static{ System.setProperty("hadoop.home.dir", HADOOP_HOME); spark = SparkSession.builder() .appName("test") .master("local[*]") .config("spark.sql.warehouse.dir",SPARK_HOME) .config("spark.sql.parquet.binaryAsString", "true") .getOrCreate(); }
Read excel
public static void readExcel(String filePath,String tableName) throws IOException{ DecimalFormat format = new DecimalFormat(); format.applyPattern("#"); //create a file(Can receive uploaded files, springmvc Use CommonsMultipartFile,jersey have access to org.glassfish.jersey.media.multipart.FormDataParam(Upload blog by referring to my file)) File file = new File(filePath); //Create a file stream InputStream inputStream = new FileInputStream(file); //Create a buffer for the stream BufferedInputStream bufferedInputStream = new BufferedInputStream(inputStream); //Definition Excel workbook Quote Workbook workbook =null; //.xlsx Format file use XSSFWorkbook Subclass xls Format file use HSSFWorkbook if(file.getName().contains("xlsx")) workbook = new XSSFWorkbook(bufferedInputStream); if(file.getName().contains("xls")&&!file.getName().contains("xlsx")) workbook = new HSSFWorkbook(bufferedInputStream); System.out.println(file.getName()); //Obtain Sheets iterator Iterator<Sheet> dataTypeSheets= workbook.sheetIterator(); while(dataTypeSheets.hasNext()){ //Every last sheet Is a table for each sheet ArrayList<String> schemaList = new ArrayList<String>(); // dataList data set ArrayList<org.apache.spark.sql.Row> dataList = new ArrayList<org.apache.spark.sql.Row>(); //field List<StructField> fields = new ArrayList<>(); //Get current sheet Sheet dataTypeSheet = dataTypeSheets.next(); //Get first row as field Iterator<Row> iterator = dataTypeSheet.iterator(); //No next sheet skip if(!iterator.hasNext()) continue; //Get the first row to build the table structure Iterator<Cell> firstRowCellIterator = iterator.next().iterator(); while(firstRowCellIterator.hasNext()){ //Get each column in the first row as a field Cell currentCell = firstRowCellIterator.next(); //Character string if(currentCell.getCellTypeEnum() == CellType.STRING) schemaList.add(currentCell.getStringCellValue().trim()); //numerical value if(currentCell.getCellTypeEnum() == CellType.NUMERIC) schemaList.add((currentCell.getNumericCellValue()+"").trim()); } //Establish StructField(spark For the field object in, you need to provide the field name, field type and the third parameter true Indicates that the column can be empty)And fill in List<StructField> for (String fieldName : schemaList) { StructField field = DataTypes.createStructField(fieldName, DataTypes.StringType, true); fields.add(field); } //according to List<StructField>Establish spark Table structure org.apache.spark.sql.types.StructType StructType schema = DataTypes.createStructType(fields); //Number of fields len int len = schemaList.size(); //Get current sheet Data rows int rowEnd = dataTypeSheet.getLastRowNum(); //Ergodic current sheet All rows for (int rowNum = 1; rowNum <= rowEnd; rowNum++) { //Make a row of data into one List ArrayList<String> rowDataList = new ArrayList<String>(); //Get a row of data Row r = dataTypeSheet.getRow(rowNum); if(r!=null){ //Traverses the cells of the current row based on the number of fields for (int cn = 0; cn < len; cn++) { Cell c = r.getCell(cn, Row.MissingCellPolicy.RETURN_BLANK_AS_NULL); if (c == null) rowDataList.add("0");//Null value simple zero filling if (c != null&&c.getCellTypeEnum() == CellType.STRING) rowDataList.add(c.getStringCellValue().trim());//Character string if (c != null&&c.getCellTypeEnum() == CellType.NUMERIC){ double value = c.getNumericCellValue(); if (p.matcher(value+"").matches()) rowDataList.add(format.format(value));//Do not retain decimal point if (!p.matcher(value+"").matches()) rowDataList.add(value+"");//Keep decimal point } } } //dataList Add a row to the dataset dataList.add(RowFactory.create(rowDataList.toArray())); } //Create temporary tables based on data and table structure spark.createDataFrame(dataList, schema).createOrReplaceTempView(tableName+dataTypeSheet.getSheetName()); } }
Create a test file in the project directory

First Sheet:
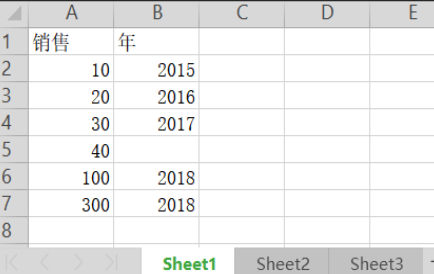
Second Sheet:
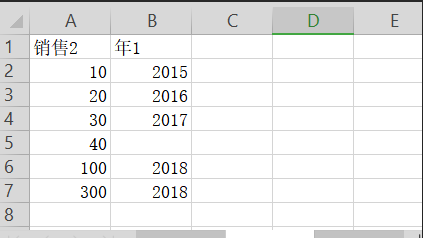
The third Sheet:
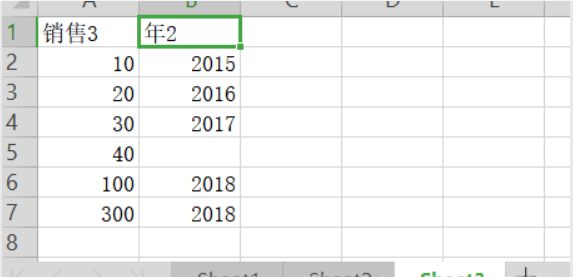
Testing
public static void main(String[] args) throws Exception { //Need to query excel Route String xlsxPath = "test2.xlsx"; String xlsPath = "test.xls"; //Define table name String tableName1="test_table1"; String tableName2="test_table2"; //read excel Table name is tableNameN+Sheet Name readExcel(xlsxPath,tableName2); spark.sql("select * from "+tableName2+"Sheet1").show(); readExcel(xlsPath,tableName1); spark.sql("select * from "+tableName1+"Sheet1").show(); spark.sql("select * from "+tableName1+"Sheet2").show(); spark.sql("select * from "+tableName1+"Sheet3").show(); }
Operation result
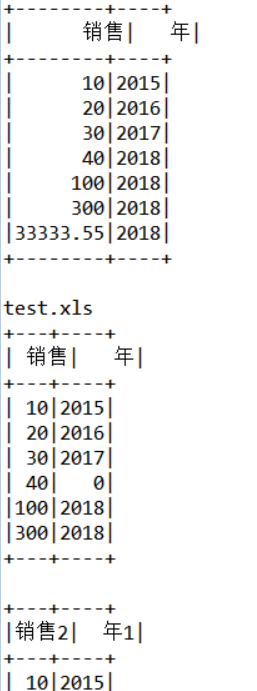
Related dependence
<dependencies> <dependency> <groupId>org.spark-project.hive</groupId> <artifactId>hive-jdbc</artifactId> <version>1.2.1.spark2</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.11</artifactId> <version>2.3.1</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.11</artifactId> <version>2.3.1</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.6.0</version> </dependency> <dependency> <groupId>org.apache.poi</groupId> <artifactId>poi</artifactId> <version>3.17</version> </dependency> <dependency> <groupId>org.apache.poi</groupId> <artifactId>poi-ooxml</artifactId> <version>3.17</version> </dependency> </dependencies>