Java uses POI to generate Word through template
preface
Recent work needs to be used, so write it down for easy search.
1, Overview
The core class used by POI to read and write word is XWPFDocument. An XWPFDocument represents a docx document, which can be used to read or write docx documents.
It mainly includes the following objects:
- XWPFParagraph: represents a paragraph.
- XWPFRun: represents a piece of text with the same attributes.
- XWPFTable: represents a table.
- XWPFTableRow: a row of the table.
- XWPFTableCell: a cell corresponding to the table.
Quote a well written structure description:
Original text: Introduction to Word document structure of Poi
1. Text paragraphs of word document structure introduction of poi
A document contains multiple paragraphs, a paragraph contains multiple Runs, and a run contains multiple Runs. Run is the smallest unit of the document
Get all paragraphs: List < xwpfparagraph > paragraphs = word getParagraphs();
Get all Runs in a paragraph: List < xwpfrun > xwpfrns = xwpfpparagraph getRuns();
Get a Run in a Run: xwpfrun Run = xwpfruns get(index);
2. Text table of word document structure introduction of poi
A document contains multiple tables, a table contains multiple rows, and a row contains multiple columns (cells). The content of each cell is equivalent to a complete document
Get all tables: List < xwpftable > xwpftables = doc getTables();
Get all rows in a table: List < xwpftablerow > xwpftablerows = xwpftablerow getRows();
Get all columns in a row: List < xwpftablecell > xwpftablecells = xwpftablerow getTableCells();
Get the contents in a cell: List < xwpfparagraph > paragraphs = xwpftablecell getParagraphs();
After that, it is the same as the main paragraph
Note:
- A grid of a table is equivalent to a complete docx document, but there is no header and footer. There can be tables in it. Use xwpftablecell Gettables() get.
- In POI documents, paragraphs and tables are completely separated. If there is a table in two paragraphs, there is no way to determine that the table is in the middle of the paragraph in poi. (of course, unless you knew it, this sentence is nonsense). Only when the format of the document is fixed can we get the structure of the document correctly
3. Page header of word document structure introduction of poi:
A document can have multiple headers (I don't know how to have multiple headers...), The header can contain paragraphs and tables
Get the header of the document: List < xwpfheader > headerlist = doc getHeaderList();
Get all paragraphs in the header: List < xwpfparagraph > para = header getParagraphs();
Get all tables in the header: List < xwpftable > tables = header getTables();
Then it's the same
4. Footer of introduction to word document structure of poi:
The footer is basically similar to the header. You can get the corner mark indicating the number of pages
2, Use case testing
First use the code to read and write word.
Data preparation
Write a word document as follows:
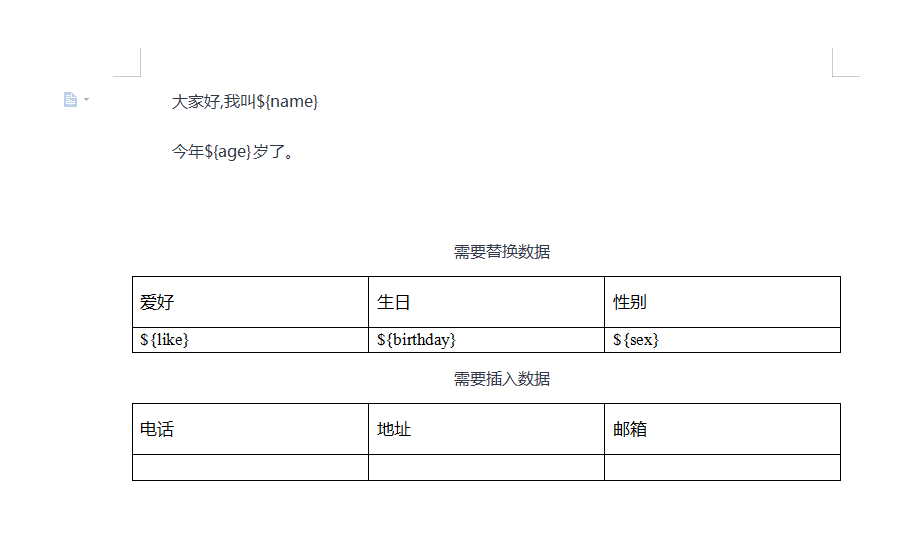
Source file address:
1-read
/**
* @Description Test reading word file
* @Author hacah
* @Date 2021/6/15 14:45
*/
public static void testReadWord() throws IOException {
// Fill in the input stream
XWPFDocument xwpfDocument = new XWPFDocument(new FileInputStream("E:\\OneDrive\\file\\self-introduction.docx"));
// Get text data
List<XWPFParagraph> paragraphs = xwpfDocument.getParagraphs();
for (XWPFParagraph paragraph : paragraphs) {
for (XWPFRun run : paragraph.getRuns()) {
System.out.println(run.text());
}
}
// Get table data
List<XWPFTable> tables = xwpfDocument.getTables();
for (XWPFTable table : tables) {
List<XWPFTableRow> rows = table.getRows();
for (XWPFTableRow row : rows) {
List<XWPFTableCell> tableCells = row.getTableCells();
for (XWPFTableCell tableCell : tableCells) {
List<XWPFParagraph> paragraphs1 = tableCell.getParagraphs();
for (XWPFParagraph xwpfParagraph : paragraphs1) {
List<XWPFRun> runs = xwpfParagraph.getRuns();
for (XWPFRun run : runs) {
System.out.println(run);
}
}
}
}
}
}
public static void main(String[] args) throws IOException {
testReadWord();
}
result:

2-write
/**
* @Description The test uses the template to write data, and the word after the new data is created
* @author hacah
* @Date 2021/6/15 15:09
*/
public static void testWriteWord() throws IOException {
XWPFDocument xwpfDocument = new XWPFDocument(new FileInputStream("E:\\OneDrive\\file\\self-introduction.docx"));
FileOutputStream fileOutputStream = new FileOutputStream("E:\\OneDrive\\file\\Data created by template.docx");
// Get the first run of the first segment file
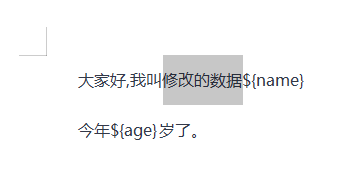
XWPFRun xwpfRun = xwpfDocument.getParagraphs().get(0).getRuns().get(0);
xwpfRun.setText("Modified data");
xwpfDocument.write(fileOutputStream);
fileOutputStream.close();
}
public static void main(String[] args) throws IOException {
testWriteWord();
}
result:
3, Case
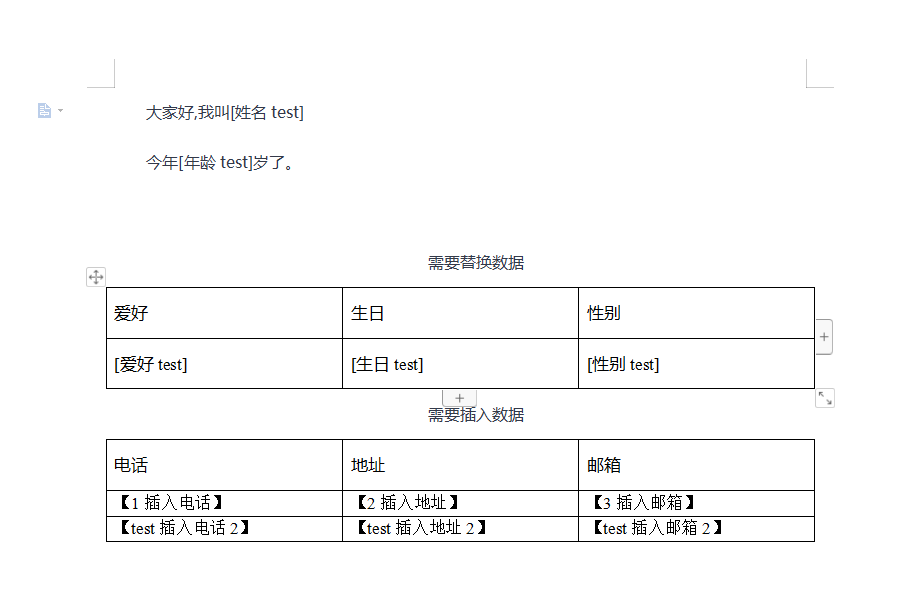
Use the unmodified original word file above. Replace the data of ${} and insert data into the empty table.
The code is as follows:
package com.hacah.word;
import org.apache.commons.codec.binary.StringUtils;
import org.apache.poi.util.StringUtil;
import org.apache.poi.xwpf.usermodel.*;
import java.io.*;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* @author Hacah
* @className: templateToWord
* @description: TODO Class description
* @date 2021/6/15 15:17
*/
public class templateToWord {
/**
* @param wordValue ${...} Variable with ${}
* @param map Store data that needs to be replaced
* @return java.lang.String
* @Description If the value of ${} matches the replaced data, the original data will be returned if there is no ${}
* @author hacah
* @Date 2021/6/15 16:02
*/
public static String matchesValue(String wordValue, Map<String, String> map) {
for (String s : map.keySet()) {
String s1 = new StringBuilder("${").append(s).append("}").toString();
if (s1.equals(wordValue)) {
wordValue = map.get(s);
}
}
return wordValue;
}
/**
* @return boolean
* @Description Test whether it contains data that needs to be replaced
* @author hacah
* @Date 2021/6/15 15:30
*/
public static boolean isReplacement(String text) {
boolean check = false;
if (text.contains("$")) {
check = true;
}
return check;
}
/**
* @Description Process all segment data except tables
* @param xwpfDocument
* @param insertTextMap
* @author hacah
* @Date 2021/6/17 10:04
*/
public static void handleParagraphs(XWPFDocument xwpfDocument, Map<String, String> insertTextMap) {
for (XWPFParagraph paragraph : xwpfDocument.getParagraphs()) {
String text = paragraph.getText();
if (isReplacement(text)) {
for (XWPFRun run : paragraph.getRuns()) {
// Judge run with ${}
// System.out.println(run);
run.setText(matchesValue(run.text(), insertTextMap), 0);
}
}
}
}
/**
* @Description The main method of generating word through word template
* @param inputStream
* @param outputStream
* @param insertTextMap
* @param addList
* @author hacah
* @Date 2021/6/17 10:03
*/
public static void generateWord(InputStream inputStream, OutputStream outputStream, Map<String, String> insertTextMap, List<String[]> addList) throws IOException {
//Get docx parsing object
XWPFDocument xwpfDocument = new XWPFDocument(inputStream);
// Process all segment data except tables
handleParagraphs(xwpfDocument, insertTextMap);
// Processing tabular data
handleTable(xwpfDocument, insertTextMap, addList);
// Write data
xwpfDocument.write(outputStream);
outputStream.close();
}
/**
* @Description Methods of processing tabular data
* @param xwpfDocument
* @param insertTextMap
* @param addList
* @author hacah
* @Date 2021/6/17 10:04
*/
public static void handleTable(XWPFDocument xwpfDocument, Map<String, String> insertTextMap, List<String[]> addList) {
List<XWPFTable> tables = xwpfDocument.getTables();
for (XWPFTable table : tables) {
List<XWPFTableRow> rows = table.getRows();
if (rows.size() > 1) {
if (isReplacement(table.getText())) {
// Replace data
for (XWPFTableRow row : rows) {
List<XWPFTableCell> tableCells = row.getTableCells();
for (XWPFTableCell tableCell : tableCells) {
if (isReplacement(tableCell.getText())) {
// Replace data
List<XWPFParagraph> paragraphs = tableCell.getParagraphs();
for (XWPFParagraph paragraph : paragraphs) {
List<XWPFRun> runs = paragraph.getRuns();
for (XWPFRun run : runs) {
run.setText(matchesValue(tableCell.getText(), insertTextMap), 0);
}
}
}
}
}
} else {
// insert data
for (int i = 1; i < addList.size(); i++) {
XWPFTableRow row = table.createRow();
}
List<XWPFTableRow> rowList = table.getRows();
for (int i = 1; i < rowList.size(); i++) {
XWPFTableRow xwpfTableRow = rowList.get(i);
List<XWPFTableCell> tableCells = xwpfTableRow.getTableCells();
for (int j = 0; j < tableCells.size(); j++) {
XWPFTableCell xwpfTableCell = tableCells.get(j);
xwpfTableCell.setText(addList.get(i - 1)[j]);
}
}
}
}
}
}
public static void main(String[] args) throws IOException {
// Replace text data construction
HashMap<String, String> insertTextMap = new HashMap<>(16);
insertTextMap.put("like", "[hobby test]");
insertTextMap.put("birthday", "[birthday test]");
insertTextMap.put("sex", "[Gender test]");
insertTextMap.put("name", "[full name test]");
insertTextMap.put("age", "[Age test]");
// Insert data build
ArrayList<String[]> addList = new ArrayList<>();
addList.add(new String[]{"[1 [insert phone]", "[2 [insert address]", "[3 [insert mailbox]"});
addList.add(new String[]{"[test [insert phone 2]", "[test [insert address 2]", "[test [insert mailbox 2]"});
// Set template input and result output
FileInputStream fileInputStream = new FileInputStream("E:\\OneDrive\\file\\self-introduction.docx");
FileOutputStream fileOutputStream = new FileOutputStream("E:\\OneDrive\\file\\Data created by template.docx");
// Generate word
generateWord(fileInputStream, fileOutputStream, insertTextMap, addList);
}
}
result:
Reference or related articles
https://www.iteye.com/blog/elim-2049110
https://www.jianshu.com/p/6603b1ea3ad1