1. Introduction to XML
1.1. What is xml
xml is an extensible markup language.
1.2. The role of xml
- The main functions of xml are:
- It is used to save data, and the data is self descriptive
- It can also be used as a configuration file for a project or module
- It can also be used as the format for network data transmission (now JSON is the main format).
2. XML syntax
- Document declaration.
- Element (label)
- xml attribute
- xml annotation
- Text area (CDATA area)
2.1 document declaration
- We first create a simple XML file to describe book information.
<?xml version="1.0" encoding="UTF-8"?> xml Statement. <!-- xml statement version It means version encoding It's coding-->
-
This <? XML should be written together, otherwise there will be an error
-
attribute
- Version is the version number
- Encoding is the encoding of xml files
- standalone="yes/no" indicates whether the xml file is a separate xml file
-
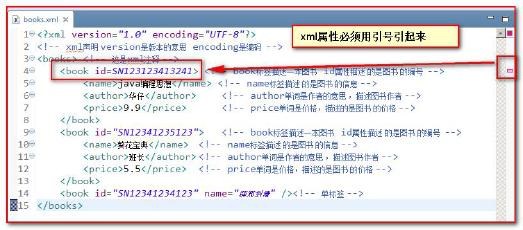
The book has id attribute, which indicates unique identification, book title, author and price information
<?xml version="1.0" encoding="UTF-8"?>
<!-- xml statement version It means version encoding It's coding-->
<books> <!-- This is xml notes-->
<book id="SN123123413241"> <!-- book The label describes a book id Property describes the number of the book-->
<name>java Programming thought</name> <!-- name The label describes the information of the book-->
<author>Huazi</author> <!-- author Words mean the author and describe the author of the book-->
<price>9.9</price> <!-- price The word is the price and describes the price of books-->
</book>
<book id="SN12341235123"> <!-- book The label describes a book id Property describes the number of the book-->
<name>Sunflower collection</name> <!-- name The label describes the information of the book-->
<author>monitor</author> <!-- author Words mean the author and describe the author of the book-->
<price>5.5</price> <!-- price The word is the price and describes the price of books-->
</book>
</books>
2.2. xml comments
html and XML comments are the same: <-- html comments -- >
2.3 elements (labels)
- html tag:
- Format: < tag name > encapsulated data < / tag name >
- Single label: < label name / >, < br / > line feed, < HR / > horizontal line
- Double tag < tag name > encapsulated data < / tag name >
- Tag names are case insensitive
- Tags have attributes, basic attributes and event attributes
- Tags should be closed (if not closed, no error will be reported in html. But we should develop good writing habits.)
What is an XML element
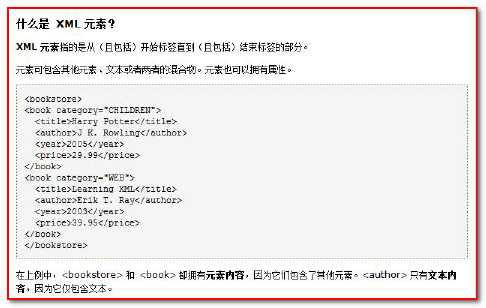
- Element refers to the content from the start tag to the end tag.
- For example: < title > java programming ideas < / Title >
- Elements can be simply understood as tags.
- Element translation element
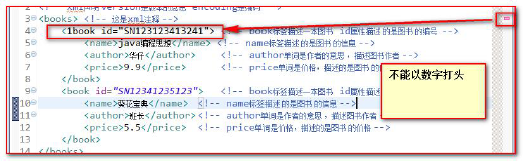
XML naming rules
- XML elements must follow the following naming rules:
- Names can contain letters, numbers, and other characters
<book id="SN213412341"> <!-- Describe a Book-->
<author>Class guide</author> <!-- Describe the author of the book-->
<name>java Programming thought</name> <!-- title-->
<price>9.9</price> <!-- Price-->
</book>
-
The name cannot start with a number or punctuation mark
-
The name cannot contain spaces

Elements (tags) in XML are also divided into single tags and double tags
- Single label
- Format: < tag name attribute = "value" attribute = "value"... / >
- Double label
- Format: < tag name attribute = "value" attribute = "value"... > Text data or sub tags < / tag name >
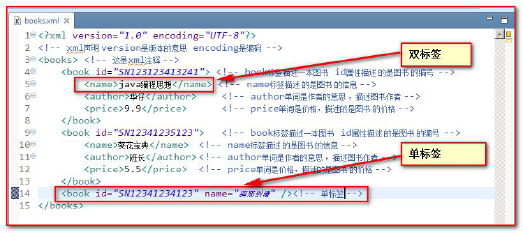
- Format: < tag name attribute = "value" attribute = "value"... > Text data or sub tags < / tag name >
2.4. xml attribute
- xml tag attributes are very similar to html tag attributes. Attributes can provide additional information about elements
- Attributes can be written on the label:
- Multiple attributes can be written on a label. The value of each attribute must be enclosed in quotation marks.
- The rules are consistent with the writing rules of the label.
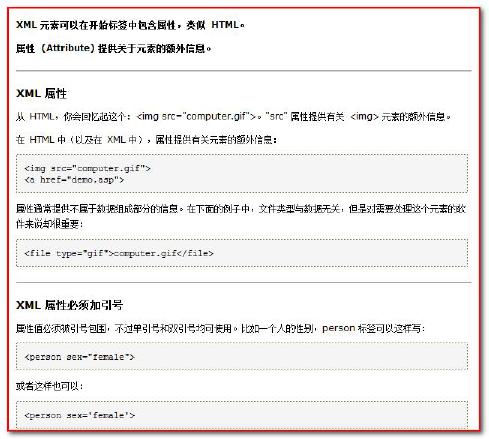
Attributes must be enclosed in quotation marks. If they are not quoted, an error will be reported
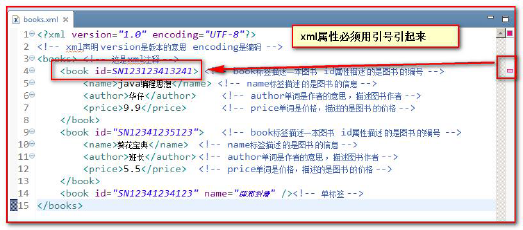
2.5 grammar rules
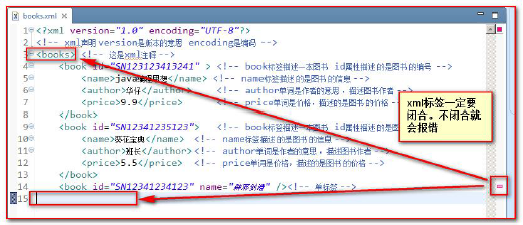
All XML elements must have a close tag (that is, close)
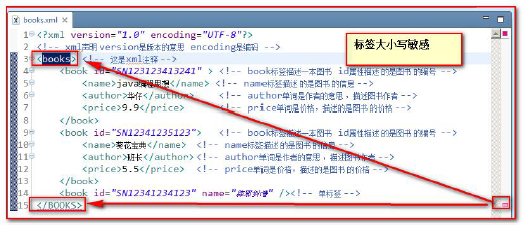
XML tags are case sensitive
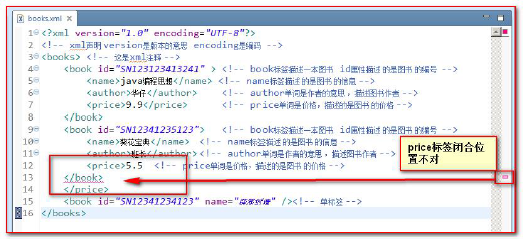
XML must be nested correctly
The XML document must have a root element
- The root element is the top element,
- An element without a parent tag is called a top-level element.
- The root element is a top-level element without a parent tag and is the only one.

XML attribute values must be quoted
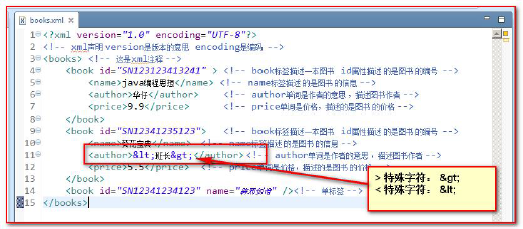
Special characters in XML
Text area (CDATA area)
- CDATA syntax can tell the xml parser that the text content in CDATA is only plain text and does not need xml syntax parsing
- CDATA format: <! [CDATA [here you can display the characters you entered as they are, without parsing XML]] >

3. Introduction to xml parsing technology
-
xml is an extensible markup language.
-
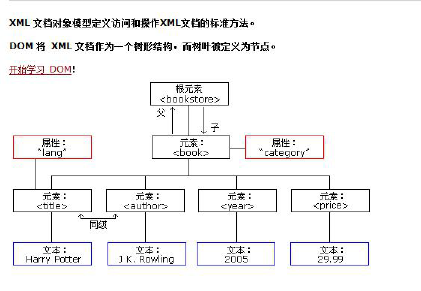
Whether html files or xml files, they are markup documents that can be parsed using dom technology developed by w3c organization.
-
The document object represents the entire document (either html or xml)
-
The early JDK provided us with an introduction to two xml parsing technologies DOM and Sax (outdated, but we need to know these two technologies)
-
dom parsing technology is developed by W3C organization
- All programming languages implement this parsing technology using the characteristics of their own language.
- Java also implements dom technology parsing tags.
-
sun company upgraded dom parsing technology in JDK5 version: SAX (Simple API for XML)
- SAX parsing, which is different from the parsing formulated by W3C. It uses a similar event mechanism to tell the user the content being parsed through a callback.
- It reads and parses the xml file line by line. A large number of dom objects will not be created.
- Therefore, when parsing xml, it is in the use of memory. And performance. Are better than Dom parsing.
-
Third party resolution:
- jdom is encapsulated on the basis of dom
- dom4j also encapsulates jdom.
- pull is mainly used in Android mobile phone development. It is very similar to sax. It is an event mechanism to parse xml files.
-
This Dom4j is a third-party parsing technique. We need a good class library provided by a third party to parse xml files.
4. dom4j parsing technology (key)
Because dom4j is not the technology of sun company, but the technology of a third-party company, we need to download the jar package of dom4j from the official website of dom4j if we need to use dom4j.
4.1 use of Dom4j class library
4.2 introduction to dom4j directory
- docs Directory: learning documents for third-party class libraries
- How to check Dom4j's documents
- Locate the package directory for Dom4j
- Find the docs directory
- Find index Double click the HTML file to open it
- Dom4j quick start
- Quick Start is a Quick Start example
- How to check Dom4j's documents
- lib Directory: Dom4j needs to rely on other third-party class libraries
- src Directory: the source directory of the third-party class library
4.3 dom4j programming steps
- Step 1: first load the xml file and create a Document object
- Step 2: get the root element object through the Document object
- Step 3: pass the root element Elelemts (tag name); You can return a set, which is placed in the set. All element objects with the tag name you specify
- Step 4: find the child element you want to modify or delete and perform the corresponding operation
- Step 5: save to the hard disk
4.4. Get document object
<?xml version="1.0" encoding="UTF-8"?>
<books>
<book sn="SN12341232">
<name>Evil dispelling sword manual</name>
<price>9.9</price>
<author>headmaster</author>
</book>
<book sn="SN12341231">
<name>Sunflower collection</name>
<price>99.99</price>
<author>monitor</author>
</book>
</books>
- Parse the code to get the Document object
- Create the saxoreader object first. This object is used to read the xml file and create the Document
/*
* dom4j Get Documet object
*/
@Test
public void getDocument() throws DocumentException {
// To create a Document object, we need to create a SAXReader object first
SAXReader reader = new SAXReader();
// This object is used to read the xml file and then return a Document.
Document document = reader.read("src/books.xml");
// Print to the console to see if the creation is successful
System.out.println(document);
}
4.5. Traverse the tags to get the contents of all tags (key points)
- There are four steps:
- The first step is to create a SAXReader object. To read the xml file and get the Document object
- The second step is to use the Document object. Get the root element object of XML
- The third step, through the root element object. Get all book tag objects
- Step 4: traverse each book tag object. Then get each element in the book tag object, and then get the text content between the start tag and the end tag through the getText() method
/*
* Read the contents of the xml file
*/
@Test
public void readXML() throws DocumentException {
// There are four steps:
// The first step is to create a SAXReader object. To read the xml file and get the Document object
// The second step is to use the Document object. Get the root element object of XML
// The third step, through the root element object. Get all book tag objects
// Step 4: traverse each book tag object. Then get each element in the book tag object, and then get the text content between the start tag and the end tag through the getText() method
// The first step is to create a SAXReader object. To read the xml file and get the Document object
SAXReader reader = new SAXReader();
Document document = reader.read("src/books.xml");
// The second step is to use the Document object. Get the root element object of XML
Element root = document.getRootElement();
// Print test
// Element.asXML() which converts the current element into a String object
// System.out.println( root.asXML() );
// The third step, through the root element object. Get all book tag objects
// Element. Elements (tag name), which can get the set of specified child elements under the current element
List<Element> books = root.elements("book");
// Step 4: traverse each book tag object. Then get each element in the book tag object,
for (Element book : books) {
// test
// System.out.println(book.asXML());
// Get the name element object under the book
Element nameElement = book.element("name");
// Get the price element object under book
Element priceElement = book.element("price");
// Get the author element object under book
Element authorElement = book.element("author");
// Then get the text content between the start tag and the end tag through the getText() method
System.out.println("title" + nameElement.getText() + " , Price:"
+ priceElement.getText() + ", Author:" + authorElement.getText());
}
}
Print content:
Book{sn='SN12341232', name='Evil dispelling sword manual', price=9.9, author='headmaster'}
Book{sn='SN12341231', name='Sunflower collection', price=99.99, author='monitor'}