JDBC data source
Spark SQL supports reading data from relational databases (such as MySQL) using JDBC. The read data, still represented by DataFrame, can be easily processed using various operators provided by Spark Core.
Created by:
To connect Mysql during query:

It is very useful to use Spark SQL to process data in JDBC. For example, in your MySQL business database, there is a large amount of data, such as 10 million yuan. Now, you need to write a program to deal with some complex business logic of online dirty data, even if it involves repeatedly querying the data in Hive with Spark SQL for association processing.
At this time, it is the best choice to use Spark SQL to load data in MySQL through JDBC data source, and then process it through various operators. Because Spark is a distributed computing framework, for 10 million data, it must be distributed processing. But if you write a Java program by yourself, you can only deal with it in batches. You need to deal with 20000 pieces first, and then 20000 pieces. It takes too much time to run.
Case study:
package Spark_SQL.Hive_sql;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.SQLContext;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
import scala.Tuple2;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Statement;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* @Date: 2019/3/16 17:11
* @Author Angle
*/
public class JDBCDataSource {
public static void main(String[] args){
SparkConf conf = new SparkConf().setAppName("JDBCDataSource").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
SQLContext sqlContext = new SQLContext(sc);
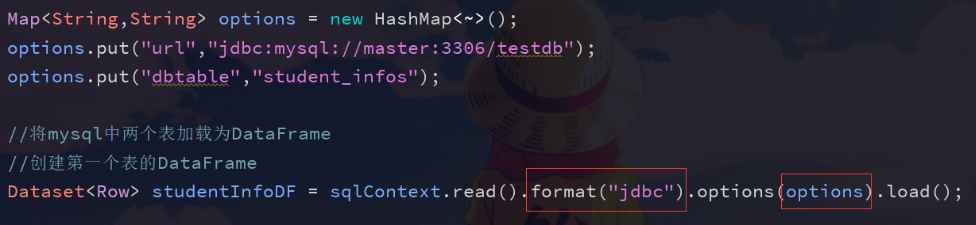
Map<String,String> options = new HashMap<String,String>();
options.put("url","jdbc:mysql://master:3306/testdb");
options.put("dbtable","student_infos");
//Load two tables in mysql as DataFrame
//Create the DataFrame of the first table
Dataset<Row> studentInfoDF = sqlContext.read().format("jdbc").options(options).load();
options.put("dbtable","studnet_scores");
//Create a second DataFrame
Dataset<Row> studentScoreDF = sqlContext.read().format("jdbc").options(options).load();
//Convert two dataframes to JavaPairRDD to perform join operation
JavaPairRDD<String, Tuple2<Integer, Integer>> studentsRDD = studentInfoDF.javaRDD().mapToPair(new PairFunction<Row, String, Integer>() {
@Override
public Tuple2<String, Integer> call(Row row) throws Exception {
return new Tuple2<String, Integer>
(row.getString(0), Integer.valueOf(String.valueOf(row.get(1))));
}
}).join(studentScoreDF.javaRDD().mapToPair(new PairFunction<Row, String, Integer>() {
@Override
public Tuple2<String, Integer> call(Row row) throws Exception {
//If you are not sure about the type of elements in row, you can get them and then convert them
return new Tuple2<String, Integer>
(String.valueOf(row.get(0)), Integer.valueOf(String.valueOf(row.get(1))));
}
}));
//Change JavaPairRDD to javardd < row >
JavaRDD<Row> studentsRowRDD = studentsRDD.map(new Function<Tuple2<String, Tuple2<Integer, Integer>>, Row>() {
@Override
public Row call(Tuple2<String, Tuple2<Integer, Integer>> tuple) throws Exception {
return RowFactory.create(tuple._1, tuple._2._1, tuple._2._2);
}
});
//Filter out data larger than score80
JavaRDD<Row> filterStudentRowRDD = studentsRowRDD.filter(new Function<Row, Boolean>() {
@Override
public Boolean call(Row v1) throws Exception {
if (v1.getInt(2) > 80){
return true;
}
return false;
}
});
//Convert to DataFrame
List<StructField> structFields = new ArrayList<StructField>();
structFields.add(DataTypes.createStructField("name",DataTypes.StringType,true));
structFields.add(DataTypes.createStructField("age",DataTypes.IntegerType,true));
structFields.add(DataTypes.createStructField("score",DataTypes.IntegerType,true));
StructType structType = DataTypes.createStructType(structFields);
Dataset<Row> studentsDF = sqlContext.createDataFrame(filterStudentRowRDD, structType);
//Print out the results
List<Row> rows = studentsDF.collectAsList();
for(Row row : rows){
System.out.println(row);
}
//Save the data in DataFrame to mysql table
options.put("dbtable","good_student_infos");
studentsDF.write().format("jdbc").options(options).save();
studentsDF.javaRDD().foreach(new VoidFunction<Row>() {
@Override
public void call(Row row) throws Exception {
String sql = "insert into good_student_infos values("
+ "'" + String.valueOf(row.getString(0)) + "',"
+ Integer.valueOf(String.valueOf(row.get(1))) + ","
+ Integer.valueOf(String.valueOf(row.get(2))) + ")";
Class.forName("com.mysql.jdbc.Driver");
Connection conn = null;
Statement stmt= null;
try{
DriverManager.getConnection("jdbc:mysql://master:3306/testdb","root","root");
stmt = conn.createStatement();
stmt.executeUpdate(sql);
}catch (Exception e){
e.printStackTrace();
}finally {
if (stmt != null);
stmt.close();
if (conn != null);
conn.close();
}
}
});
}
}