Summary
HashMap is one of the most commonly used container classes in Java development and a frequent visitor to interviews.It's actually the preceding " Notes on Data Structure and Algorithms (2) The implementation of Hash List in JDK 1.8 uses the Chain List method to handle hash conflicts, and it is optimized to turn a chain list into a red-black tree when a certain number of chain lengths are reached.
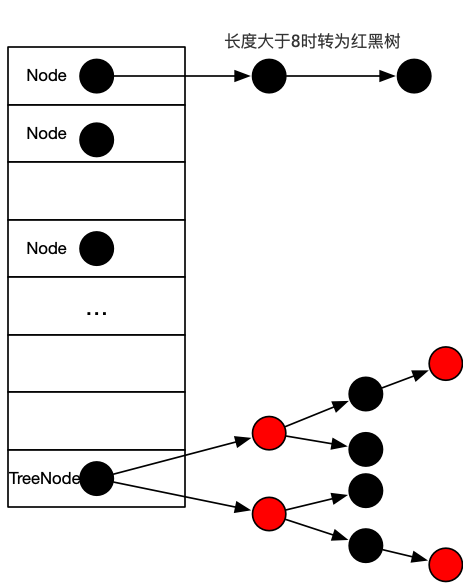
Therefore, the HashMap implementation in JDK 1.8 can be interpreted as Array + Chain List + Red and Black Tree.Internal structure diagram:
The inheritance structure and class signature of HashMap are as follows:
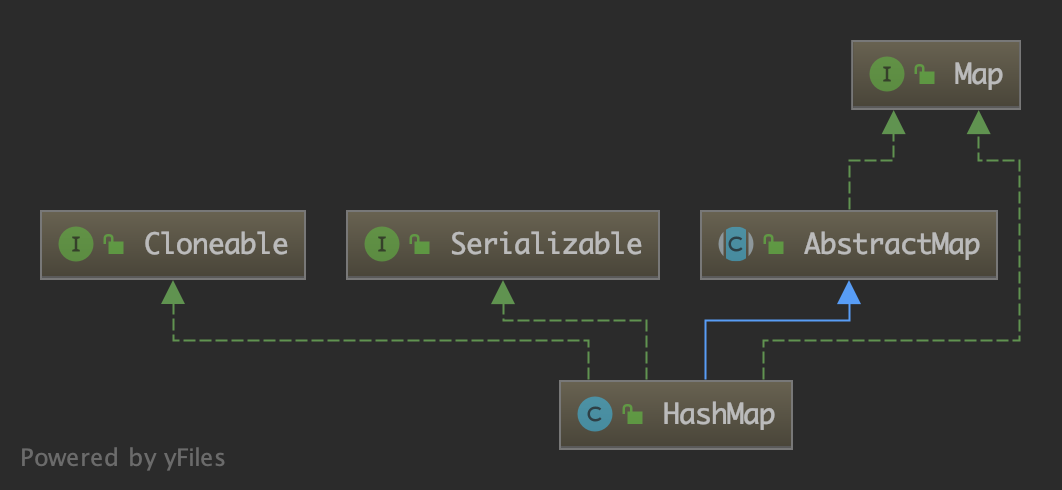
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable {}
PS: Remember that when I first read the HashMap source code, I spent two days at the weekend and was still confused after reading it.I didn't take any notes at that time. Take notes this time.
code analysis
Some member variables
// Default Initialization Capacity (must be a power of 2) static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 // Maximum capacity (must be a power of 2 and less than or equal to 2)^30) static final int MAXIMUM_CAPACITY = 1 << 30; // Default Load Factor static final float DEFAULT_LOAD_FACTOR = 0.75f; // Converts a list of chains to a tree threshold (when bin Convert the list to a tree when the number is greater than or equal to this value) // The value must be greater than 2 and at least 8, static final int TREEIFY_THRESHOLD = 8; // Threshold for converting a tree to a list of chains static final int UNTREEIFY_THRESHOLD = 6;
Node Class
First look at a nested class Node in HashMap, as follows (omitted from some methods):
/** * Basic hash bin node, used for most entries. (See below for * TreeNode subclass, and in LinkedHashMap for its Entry subclass.) */ static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; V value; Node<K,V> next; Node(int hash, K key, V value, Node<K,V> next) { this.hash = hash; this.key = key; this.value = value; this.next = next; } public final int hashCode() { return Objects.hashCode(key) ^ Objects.hashCode(value); } public final boolean equals(Object o) { if (o == this) return true; if (o instanceof Map.Entry) { Map.Entry<?,?> e = (Map.Entry<?,?>)o; if (Objects.equals(key, e.getKey()) && Objects.equals(value, e.getValue())) return true; } return false; } }
The Node class implements the Map.Entry interface, is the basic bin node in HashMap, and TreeNode.Refer to the structure diagram above.
constructor
Constructor 1: parameterless constructor
// Load factor final float loadFactor; /** * Constructs an empty HashMap with the default initial capacity * (16) and the default load factor (0.75). */ public HashMap() { this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted }
Notes show that this constructor constructs an empty HashMap using the default initialization capacity (16) and the default load factor (0.75).
Constructors 2, 3:
// Use specified initialization capacity and default load factor (0).75)Construct an empty HashMap public HashMap(int initialCapacity) { this(initialCapacity, DEFAULT_LOAD_FACTOR); } // Threshold for expansion (capacity) * Load factor) int threshold; // Construct an empty one using the specified initialization capacity and load factor HashMap public HashMap(int initialCapacity, float loadFactor) { if (initialCapacity < 0) throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; // PS: Load factor can be greater than 1 if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal load factor: " + loadFactor); this.loadFactor = loadFactor; this.threshold = tableSizeFor(initialCapacity); }
You can see that these two constructors are essentially the same.It is worth noting that a tableSizeFor method is used in the constructor to handle the initial capacity:
/** * Returns a power of two size for the given target capacity. */ static final int tableSizeFor(int cap) { int n = cap - 1; n |= n >>> 1; n |= n >>> 2; n |= n >>> 4; n |= n >>> 8; n |= n >>> 16; return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1; }
The purpose of this method is to process a given capacity cap and convert it to a number greater than or equal to the second power of cap.For example:
Given a cap of 5, it returns 8 (2^3);
Given a cap of 8, return 8 (2^3);
Given a cap of 12, the return is 16 (2^4).
Furthermore, the threshold variable, the threshold value, is assigned here.
Constructor 4:
// Use the specified Map Construct a HashMap,Default load factor is 0.75,Sufficient capacity public HashMap(Map<? extends K, ? extends V> m) { this.loadFactor = DEFAULT_LOAD_FACTOR; putMapEntries(m, false); }
As you can see from the constructor, when you create a HashMap, there are only a few variables initialized inside, and no space is allocated.
Common & Core Approach
Next, the most common and core methods of HashMap are put, get, and resize.
put method:
public V put(K key, V value) { return putVal(hash(key), key, value, false, true); }
This method first deals with the key, the hash(key) method, as follows:
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }
This method takes the hashCode of the key and treats its hashCode as XOR (^) with the value shifted 16 bits to the right.What is the purpose of this step?Let's start with an example of this:
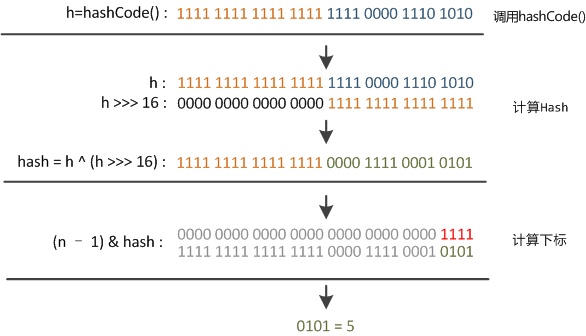
HashCode is a 32-bit integer. After shifting its unsigned right by 16 bits, its 16-bit height becomes all zero. After XOR with its hashCode, the 16-bit height of hashCode remains unchanged, while the 16-bit low retains the 16-bit height information in some form.The goal is to increase the randomness of low-number numbers and minimize hash conflicts.
For reference here: https://www.zhihu.com/question/20733617/answer/111577937
The following code does a bit-by-bit and operation (equivalent to taking the remainder of n-1, which is more efficient) to locate elements by subtracting the previously generated hash value from the length of the array by one (n-1).A hash function equivalent to a hash list.
Continue to analyze the put method:
// Hash array transient Node<K,V>[] table; final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; // if table Empty, then call resize Method Initialization if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; // To store bin If the position is empty, insert directly into the node if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); // To store bin Location is not empty (i.e. hash conflict) else { Node<K,V> e; K k; // key Already exists if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; // p Is the tree node (has been converted to a red-black tree), insert the new node into the red-black tree else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); // Not a tree node, new elements may need to be converted to a red-black tree else { for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); // When the tree threshold is greater than or equal to, the chain list is converted to a red-black tree if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } // Handle key Existing Conditions if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; // Replace old values afterNodeAccess(e); return oldValue; } } ++modCount; // If the threshold is exceeded ( capacity * 0.75),Expansion if (++size > threshold) resize(); afterNodeInsertion(evict); return null; }
Where:
1. Operations involving red and black trees may be referred to as " JDK Source Analysis-TreeMap(2) "TreeMap analysis and the red and black trees above;
2. There are two methods afterNodeAccess(e) and afterNodeInsertion(evict) that are callback methods for LinkedHashMap (a subclass of HashMap), which will not be analyzed here.
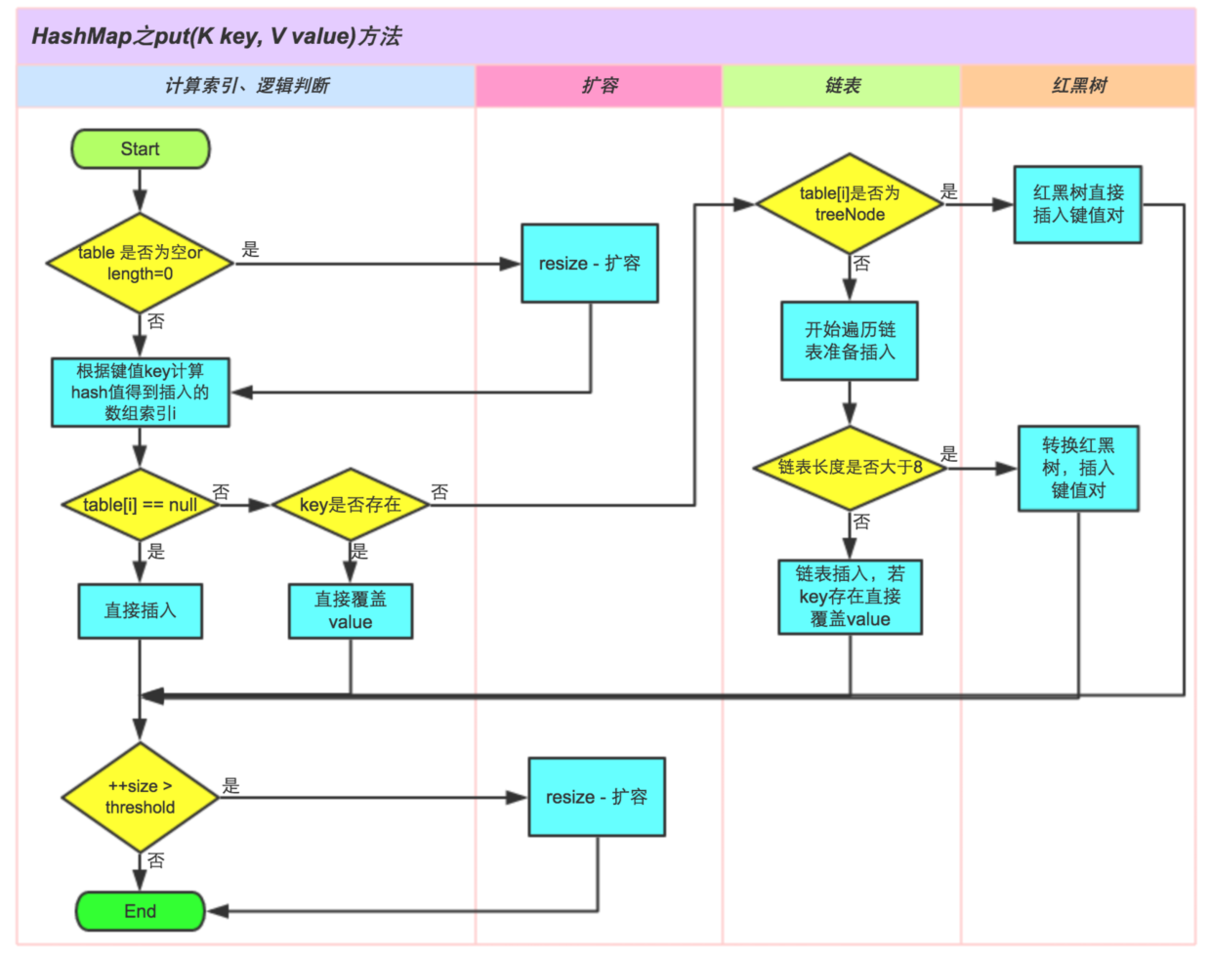
The put method operation flow is shown in the diagram:
The resize method, which is also the core method of HashMap expansion, is analyzed below:
// Initialization table Or expand it final Node<K,V>[] resize() { Node<K,V>[] oldTab = table; int oldCap = (oldTab == null) ? 0 : oldTab.length; int oldThr = threshold; int newCap, newThr = 0; // primary table Not empty if (oldCap > 0) { // if table If the capacity is greater than the maximum, the threshold is adjusted to Integer.MAX_VALUE,No expansion if (oldCap >= MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return oldTab; } // New capacity doubled // If the doubled capacity is less than int Maximum, with original capacity greater than or equal to default initial capacity (16), expanding the threshold to twice the original capacity else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) newThr = oldThr << 1; // double threshold } // Replace initial capacity with a threshold (the constructor specifying the initial capacity) else if (oldThr > 0) // initial capacity was placed in threshold newCap = oldThr; // Parameterless constructor (default capacity and threshold) else { // zero initial threshold signifies using defaults newCap = DEFAULT_INITIAL_CAPACITY; newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); } // New Threshold if (newThr == 0) { float ft = (float)newCap * loadFactor; newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE); } threshold = newThr; // Create a new array (size is the expanded capacity size) @SuppressWarnings({"rawtypes","unchecked"}) Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; table = newTab; // Expand if the original array is not empty if (oldTab != null) { for (int j = 0; j < oldCap; ++j) { Node<K,V> e; if ((e = oldTab[j]) != null) { oldTab[j] = null; // There is only one element in this location, move it to a new location if (e.next == null) newTab[e.hash & (newCap - 1)] = e; // This location is a red-black tree structure that splits or turns tree nodes into chained lists else if (e instanceof TreeNode) ((TreeNode<K,V>)e).split(this, newTab, j, oldCap); // This location is a chain table structure else { // preserve order Node<K,V> loHead = null, loTail = null; Node<K,V> hiHead = null, hiTail = null; Node<K,V> next; do { next = e.next; // Original index location (note) oldCap Is the power of 2, so only one of its binary representations is 1, and the others are all 0) if ((e.hash & oldCap) == 0) { // Chain list is empty if (loTail == null) loHead = e; // Add a new node to the end of the previous node else loTail.next = e; loTail = e; } // Original Index Location+oldCap else { if (hiTail == null) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null); // Set up j and oldCap+j Head Node of Position if (loTail != null) { loTail.next = null; newTab[j] = loHead; } if (hiTail != null) { hiTail.next = null; newTab[j + oldCap] = hiHead; } } } } } return newTab; }
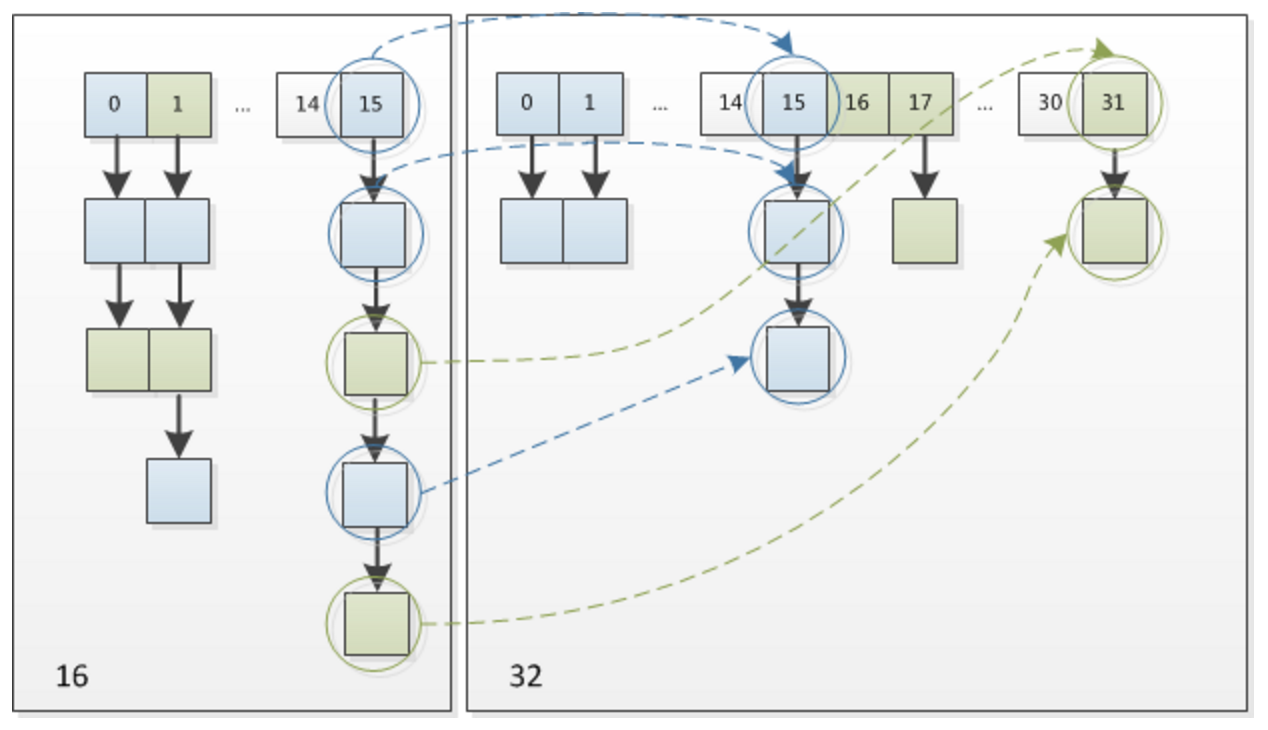
The new capacity after expansion is twice as large as the original capacity. The principle of expansion is analyzed below:
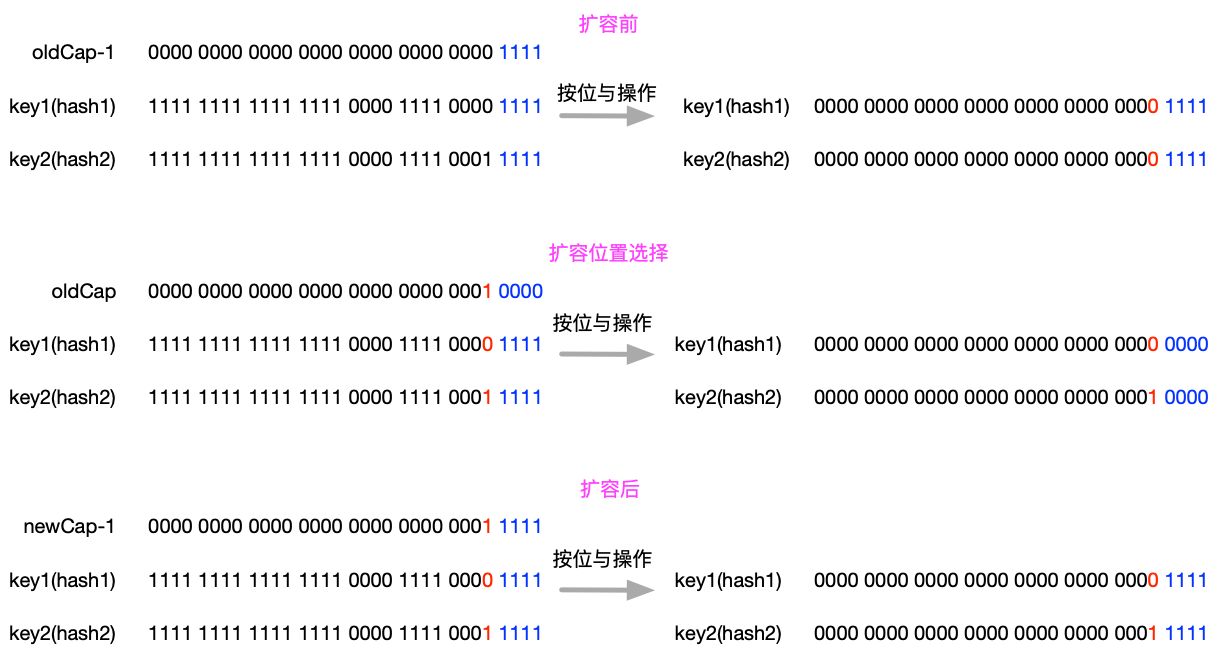
Before expansion:
When the original capacity is 16, the hash value corresponding to key 1 and key2 differs only from the fifth-last position, bitwise and operation is performed on oldCap-1 (15). Both results are 1111, which is stored in the fifteenth position.
Location selection after expansion:
The criterion in the code is if ((e.hash & oldCap) == 0), which means that hash1 and hash2 are bitwise and operated on with oldCap (16, 0b10000) to determine their position in the new expanded array based on whether they are 0 or not.You can see that in the fifth last place, key1 is 0 and key2 is 1.
After expansion:
The new capacity is 32, and key1 with the original hash value at the fifth-last position of 0 remains 15 (0b1111) in the new array, while key2 with the fifth-last position of the original hash value at the new array is 0b11111, that is, 15 + 16 = 31.
As shown in the diagram:
get method
The put method has been analyzed earlier, and the get method has many similarities, so it is much simpler to analyze.The code is as follows:
public V get(Object key) { Node<K,V> e; return (e = getNode(hash(key), key)) == null ? null : e.value; } final Node<K,V> getNode(int hash, Object key) { Node<K,V>[] tab; Node<K,V> first, e; int n; K k; if ((tab = table) != null && (n = tab.length) > 0 && (first = tab[(n - 1) & hash]) != null) { // The first node is the element to find if (first.hash == hash && // always check first node ((k = first.key) == key || (key != null && key.equals(k)))) return first; // This location has a sequential node (a chain table or a red-black tree) if ((e = first.next) != null) { // If it is a tree node, the location is a red-black tree, look in the red-black tree if (first instanceof TreeNode) return ((TreeNode<K,V>)first).getTreeNode(hash, key); // Traversing through a list of chains do { if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } while ((e = e.next) != null); } } return null; }
Summary
This paper mainly analyses the internal structure of HashMap and the three core methods: put, resize and get.The summary is as follows:
1. HashMap is an implementation of hash lists, which uses the Chain List method to handle hash conflicts and introduces red and black trees for further optimization in JDK 1.8.
2. The internal structure is Array+Chain List+Red-Black Tree;
3. The default initialization capacity is 16, the load factor is 0.75, and the threshold for expansion is 16 * 0.75 = 12.
4. When the capacity of the elements in the container is greater than the threshold, HashMap will automatically expand to twice its original capacity.
Reference article:
https://tech.meituan.com/2016/06/24/java-hashmap.html
Related reading:
Notes on Data Structure and Algorithms (2)
JDK Source Analysis-TreeMap(2)
Stay hungry, stay foolish.

PS: This article was first published on WeChat Public Number.