abstract
This blog will introduce the LinkedHashMap class in detail
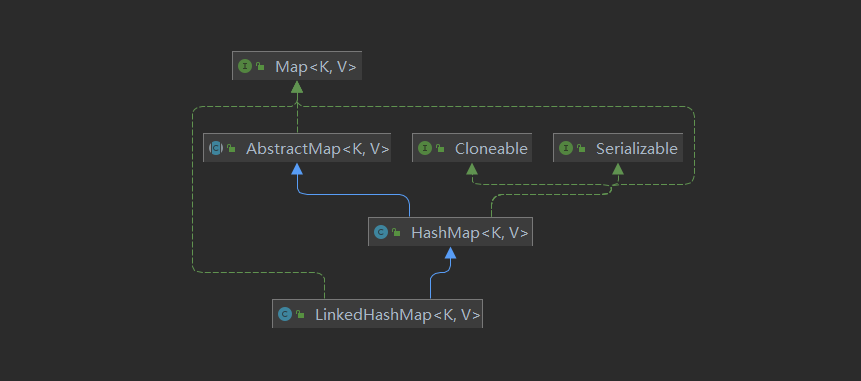
LinkedHashMap basic data structure
We know that HashMap is out of order, that is, the order of iterators has nothing to do with the insertion order. On the basis of HashMap, LinkedHashMap adds order: insert order and access order respectively. That is, when traversing LinkedHashMap, the order consistent with the insertion order can be maintained; Or the order consistent with the access order.
How does LinkedHashMap implement these two sequences internally? It is maintained through a double linked list. Therefore, LinkedHashMap can be understood as "double linked list + hash table" or "ordered hash table".
Member variables of LinkedHashMap
/** * Head pointer */ transient LinkedHashMap.Entry<K,V> head; /** * Tail pointer */ transient LinkedHashMap.Entry<K,V> tail; /** * LinkedHashMap Iteration order: true is the access order; false is the insertion order. */ final boolean accessOrder;
Node class of LinkedHashMap
LinkedHashMap has a nested class Entry, which inherits from the Node class in the HashMap, as follows:
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
// ...
}The Entry class is the Node class in LinkedHashMap. It can be seen that it adds before and after variables on the basis of the Node class. They save the precursor and successor of the Node (which can also be inferred from the literal meaning), so as to maintain the order of LinkedHashMap.
Constructor of LinkedHashMap
public LinkedHashMap() {
super();
accessOrder = false;
}
there super() Method called HashMap A parameterless constructor for. The constructor method constructs a capacity of 16 (default initial capacity) and a load factor of 0.75(Empty for default load factor) LinkedHashMap,The order is the insertion order.
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super();
accessOrder = false;
putMapEntries(m, false);
}
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}You can see that the above constructors are initialized by calling the constructor method of the parent class (HashMap), which will not be analyzed. The default value of the accessOrder variable of the first four constructors is false; the last one is slightly different, and its accessOrder can be specified during initialization, that is, the order of LinkedHashMap (insertion or access order).
put method of LinkedHashMap
LinkedHashMap itself does not implement the put method. It reads and writes by calling the method of the parent class (HashMap). The put method of HashMap is pasted here:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
// New bin node
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
// key already exists
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// Hash collision
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
// Traversal linked list
for (int binCount = 0; ; ++binCount) {
// Insert the new node at the end of the linked list
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}Where is this method related to LinkedHashMap? How can I keep the order of LinkedHashMap? Let's look at the newNode() method. Its code in HashMap is as follows:
Node<K,V> newNode(int hash, K key, V value, Node<K,V> next) {
return new Node<>(hash, key, value, next);
}However, LinkedHashMap overrides this method: each time a new node is inserted, it is saved to the end of the list. I see. The insertion order of LinkedHashMap is implemented here.
// Create a LinkedHashMap Entry node
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
// Connect the new node to the end of the list
linkNodeLast(p);
return p;
}
// link at the end of list
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
// list is empty
if (last == null)
head = p;
else {
// Insert the new node at the end of the list
p.before = last;
last.after = p;
}
}In addition, when analyzing HashMap above, we mentioned two callback methods: afterNodeAccess and afterNodeInsertion. They are empty in HashMap:
void afterNodeAccess(Node<K,V> p) { }
void afterNodeInsertion(boolean evict) { }Similarly, LinkedHashMap rewrites them. First, analyze the afterNodeAccess method:
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
// accessOrder = true indicates the access order
if (accessOrder && (last = tail) != e) {
// p is the visited node, b is its predecessor, and a is its successor
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
// p is the header node
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}get method of LinkedHashMap
LinkedHashMap rewrites the get method of HashMap, mainly to maintain the access order.
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
// For access order, move the accessed node to the end of the list
if (accessOrder)
afterNodeAccess(e);
return e.value;
}The getNode method here is the parent class (HashMap). If accessOrder is true (i.e. specified as access order), the accessed node will be moved to the end of the list.
Overridden afterNodeInsertion method in LinkedHashMap:
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
// The default return value in LinkedHashMap is false, that is, the removeNode method here does not execute
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}The removeNode method is in the parent class HashMap:
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable
) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
// table is not empty, and the location of the given hash value is not empty
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
// The node corresponding to the given key is the first position in the array
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
// The given key is located in a red black tree or linked list
else if ((e = p.next) != null) {
if (p instanceof TreeNode)
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
// Delete node
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
++modCount;
--size;
// Action after deleting a node
afterNodeRemoval(node);
return node;
}
}
return null;
}The implementation of afterNodeRemoval method in HashMap is also empty:
void afterNodeRemoval(Node<K,V> p) { }LinkedHashMap overrides this method:
void afterNodeRemoval(Node<K,V> e) { // unlink
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.before = p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a == null)
tail = b;
else
a.before = b;
}LinkedHashMap actual combat
LinkedHashMap, you can maintain the insertion order:
Map<String, String> map = new LinkedHashMap<>();
map.put("bush", "a");
map.put("obama", "b");
map.put("trump", "c");
map.put("lincoln", "d");
System.out.println(map);
// Output results (insertion order):
// {bush=a, obama=b, trump=c, lincoln=d}Map<String, String> map = new LinkedHashMap<>(2, 0.75f, true);
map.put("bush", "a");
map.put("obama", "b");
map.put("trump", "c");
map.put("lincoln", "d");
System.out.println(map);
map.get("obama");
System.out.println(map);
// Output results (insertion order):
// {bush=a, obama=b, trump=c, lincoln=d}
// After visiting obama, obama moved to the end
// {bush=a, trump=c, lincoln=d, obama=b}LinkedHashMap summary
- LinkedHashMap inherits from HashMap, and its structure can be understood as ordered [double linked list + hash table];
- Two orders can be maintained: insert order or access order;
- LRU cache can be easily realized;
- Thread unsafe.