Concurrent HashMap -- design intent
Thread safety of HashMap:
(1) Initialization is easy to cause two threads to initialize at the same time. (2) when expanding capacity, it is easy to judge the thread problem of the code in real time
(3) For the insertion of linked list and red black tree, the global operations that affect the results will produce thread safety, such as circular linked list;
Performance inefficiency of HashTable:
hashTable directly all threads share a lock, and put\get\resize is executed serially. Different key s will also cause competition. The performance is too low
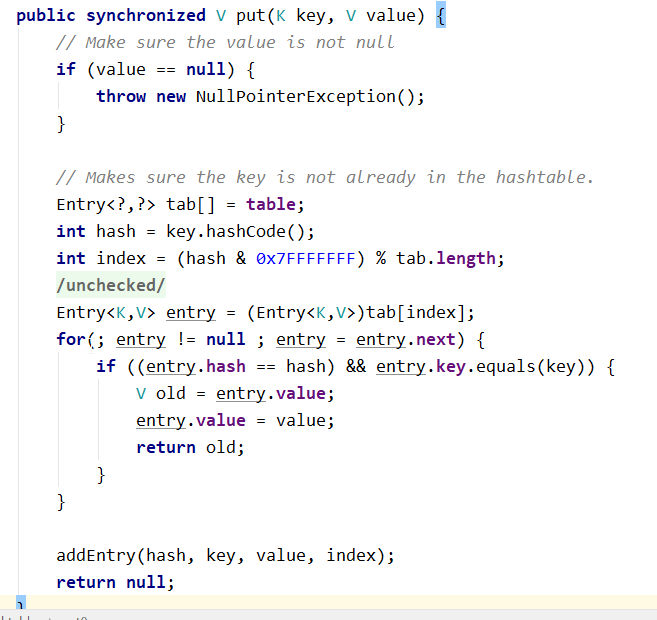
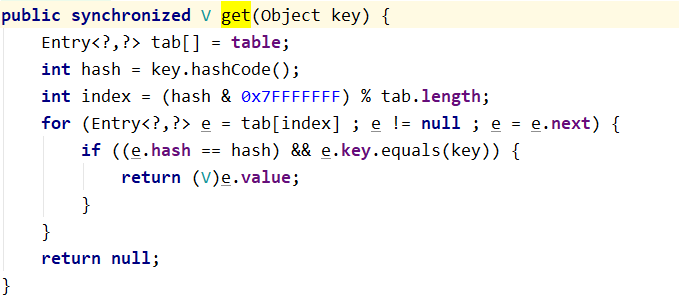
ConcurrentHashMap -- version comparison
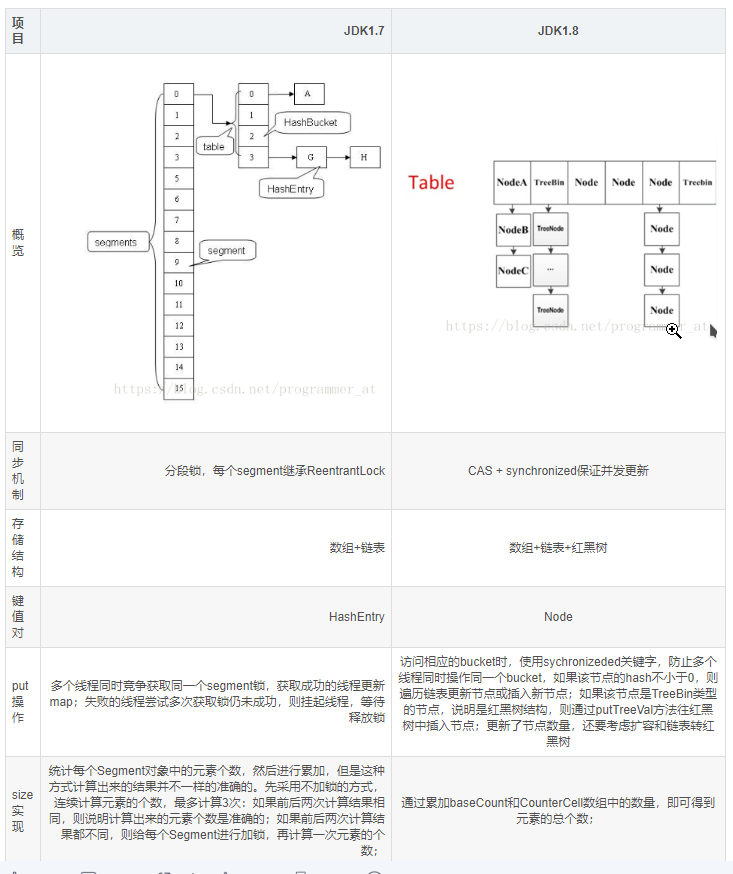
Original text of this picture: https://blog.csdn.net/programmer_at/article/details/79715177
ConcurrentHashMap - applicable scenario
HashTable: strong consistency; get\put serial execution; not suitable for a large number of inserts. In the future, isolation between different key s may also be optimized;
ConcurrentHashMap: weak consistency needs to reduce hash conflicts; otherwise, weight locks, linked lists and red black trees will also affect the results locally, so it may be optimized here for future version upgrades;
ConcurrentHashMap -- data structure
nextTable property
/** * @Transfer transfer place * When expanding, move the elements in the table to nextTable; first, double the capacity * After expansion, empty nextTable */ private transient volatile Node<K,V>[] nextTable;
sizeCtl attribute
/** * @Capacity expansion status mark / capacity expansion threshold * This is a data of joint meaning, which may be used as a state marker, or as a threshold judgment; * Among multiple threads, read sizeCtl attribute in a volatile way to judge the current state of ConcurrentHashMap. Set sizecl property through cas to inform other threads of status change of ConcurrentHashMap * Uninitialized: sizeCtl=0: indicates that no initial capacity has been specified. Sizectl > 0: indicates the initial capacity. * Initializing: sizeCtl=-1, mark function, inform other threads, initializing * Normal state: sizeCtl=0.75n, expansion threshold * Expanding: sizectl < 0: indicates another thread is expanding; sizectl = (resizestamp (n) < resize_ STAMP_ Shift) + 2: only one thread is expanding at this time */ private transient volatile int sizeCtl;
transferIndex property
/** * The expanding thread must migrate at least 16 hash buckets at a time */ private static final int MIN_TRANSFER_STRIDE = 16; /** * @Array pointer to split migration task * Under high concurrency emptying, multi-threaded capacity expansion will conflict; instead of blocking other threads, it is better to let other threads assist in capacity expansion * So first press MIN_TRANSFER_STRIDE, 16 hash buckets are divided into multiple migration tasks * transferIndex It represents the current execution position of the task. Of course, there will be concurrency conflicts when obtaining the expansion task, so cas is used to solve them * Before expansion: transferIndex is on the far right of the array * During capacity expansion: transferindex = transferindex strip (the strip is so that the hash is first press min_ TRANSFER_ Integer multiple of stride, representing more than one unit at a time) * It can be seen that the migration is from the back to the front */ private transient volatile int transferIndex;
ForwardingNode inner class
Flag function, indicating that other threads are expanding, and this node has been expanded //nextTable is associated,During the expansion, you can use the find Method, access has been migrated to nextTable Data in static final class ForwardingNode<K,V> extends Node<K,V> { final Node<K,V>[] nextTable; ForwardingNode(Node<K,V>[] tab) { //The node whose hash value is MOVED (- 1) is ForwardingNode super(MOVED, null, null, null); this.nextTable = tab; } //With this method, access the data migrated to nextTable Node<K,V> find(int h, Object k) { ... } } //Mainly reflected in get method public V get(Object key) { Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek; int h = spread(key.hashCode()); if ((tab = table) != null && (n = tab.length) > 0 && (e = tabAt(tab, (n - 1) & h)) != null) { if ((eh = e.hash) == h) { if ((ek = e.key) == key || (ek != null && key.equals(ek))) return e.val; } /** *@eh.hash<0,In this way, you can access the migrated data during the expansion */ else if (eh < 0) return (p = e.find(h, key)) != null ? p.val : null; while ((e = e.next) != null) { if (e.hash == h && ((ek = e.key) == key || (ek != null && key.equals(ek)))) return e.val; } } return null; }
Help expand source code:
final V putVal(K key, V value, boolean onlyIfAbsent) { ... //f.hash == MOVED means: ForwardingNode, indicating that other threads are expanding capacity else if ((fh = f.hash) == MOVED) tab = helpTransfer(tab, f); ... }
ConcurrentHashMap -- insert element
final V putVal(K key, V value, boolean onlyIfAbsent) { if (key == null || value == null) throw new NullPointerException(); /** * @Hash uniform processing */ int hash = spread(key.hashCode()); int binCount = 0; for (Node<K,V>[] tab = table;;) { /* * tab Reference to array * n Length reference of array * i Calculated hash value * f Traversal of the current node found each time * fh The original hash value of the current node */ Node<K,V> f; int n, i, fh; /** * @(1)If the array is empty, it will be lazy to load. Initialize a wave */ if (tab == null || (n = tab.length) == 0) tab = initTable(); /** * @(2)Indicates that the current position is empty * Update nodes directly with cas to avoid being inserted */ else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null))) break; // no lock when adding to empty bin } /** * @(3)Indicates that the current location is expanding * To avoid thread safety, the capacity expansion operation will be performed externally. In this place, you will occupy the space first and wait for the capacity expansion to be completed before you join * Expanded node list or red black tree */ else if ((fh = f.hash) == MOVED) tab = helpTransfer(tab, f); /** * @(4)Indicates that the current location is a red black tree and a linked list * Because of the concurrency problem, the global nature of linked list and red black tree will affect the insertion result * Therefore, it is better not to have any nodes during the insertion process, and the synchronized lock is not allowed * So frequent hash conflicts can affect performance * binCount */ else { V oldVal = null; synchronized (f) { if (tabAt(tab, i) == f) { if (fh >= 0) { binCount = 1; for (Node<K,V> e = f;; ++binCount) { K ek; if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) { oldVal = e.val; if (!onlyIfAbsent) e.val = value; break; } Node<K,V> pred = e; if ((e = e.next) == null) { pred.next = new Node<K,V>(hash, key, value, null); break; } } } else if (f instanceof TreeBin) { Node<K,V> p; binCount = 2; if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) { oldVal = p.val; if (!onlyIfAbsent) p.val = value; } } } } if (binCount != 0) { if (binCount >= TREEIFY_THRESHOLD) treeifyBin(tab, i); if (oldVal != null) return oldVal; break; } } } /* * Add quantity and expansion judgment */ addCount(1L, binCount); return null; }
ConcurrentHashMap - get quantity
The number of elements of ConcurrentHashMap is equal to the sum of baseCounter and the value of each CounterCell in the array. The reason for this is that when multiple threads execute CAS to modify baseCount at the same time, the failed thread will put the value into CounterCell. So when counting the number of elements, consider both baseCount and counterCells arrays
final long sumCount() { CounterCell[] as = counterCells; CounterCell a; long sum = baseCount; if (as != null) { for (int i = 0; i < as.length; ++i) { if ((a = as[i]) != null) sum += a.value; } } return sum; }
Concurrent HashMap -- capacity expansion mechanism
/** * x,Expand one * check,Check the cardinality of the original node (for example, the linked list is originally on the site, a single node is one, and the red black tree is the number of nodes) */ private final void addCount(long x, int check) { CounterCell[] as; long b, s; /** * @(1)Processing of concurrent basic size * Used to return the size and the judgment basis of various expansion * BASECOUNT: Offset address * baseCount: expected value * s: Final value equals original value + 1 * counterCells as Failed thread for update */ if ((as = counterCells) != null || !U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) { CounterCell a; long v; int m; boolean uncontended = true; if (as == null || (m = as.length - 1) < 0 || (a = as[ThreadLocalRandom.getProbe() & m]) == null || !(uncontended = U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) { /** * @When the baseCount is modified by multithreading, the LongAdder method is used to realize digital concurrency. After modification, the whole method is return ed directly * Split into multiple cell s and merge numbers to increase concurrent efficiency * Finally, it's a direct return */ fullAddCount(x, uncontended);// return; } /** * @Concurrent failure once, if only single node increase * It is also a direct return. Otherwise, the number of concurrent modifications will be accumulated for capacity expansion judgment */ if (check <= 1) return; s = sumCount(); } /** * @Processing of concurrent capacity expansion * If there is no concurrent problem of baseCount, it will enter the expansion judgment process */ if (check >= 0) { /** * tab Array pointer * nt Pointer to a segmented array * n Length pointer to array * sc Expansion threshold */ Node<K,V>[] tab, nt; int n, sc; /** * Meet the capacity expansion threshold for capacity expansion */ while (s >= (long)(sc = sizeCtl) && (tab = table) != null && (n = tab.length) < MAXIMUM_CAPACITY) { int rs = resizeStamp(n); /** * @sc<0 Indicates that concurrent capacity expansion is needed * During concurrent capacity expansion, nextTable may not be initialized or has already been initialized, so bring an nt */ if (sc < 0) { if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 || sc == rs + MAX_RESIZERS || (nt = nextTable) == null || transferIndex <= 0) break; if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) transfer(tab, nt); } /** * @Using time stamp to judge that only one thread is expanding at this time */ else if (U.compareAndSwapInt(this, SIZECTL, sc, (rs << RESIZE_STAMP_SHIFT) + 2)) transfer(tab, null); s = sumCount(); } } }
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) { /** * @n: Original table array length * @nextTab: It is used to identify whether it is the first thread to come in for capacity expansion. If so, you need to initialize nextTale * @stride: Using the idle cpu, we can figure out that the thread should get multiple tasks here */ int n = tab.length, stride; if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE) stride = MIN_TRANSFER_STRIDE; /** * @(1)Building a nextTable with nothing is twice the size of a table */ if (nextTab == null) { // initiating try { @SuppressWarnings("unchecked") Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1]; nextTab = nt; } catch (Throwable ex) { // try to cope with OOME sizeCtl = Integer.MAX_VALUE; return; } nextTable = nextTab; transferIndex = n;//Set transferIndex equal to array length } /** * @Build a loop to complete the copy function */ int nextn = nextTab.length; ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab); boolean advance = true; boolean finishing = false; /** * @nextn: The length of the expanded array; * @fwd: Wrap the newly copied talbe with a ForwardingNode node * @advance: * @finishing: Mark that all nodes have completed the replication work * @i: The built-in counter of each thread, which is used to determine where the task is executed * @bound: The number of built-in hashes of each thread, which is used to determine whether the task is completed * f The expanding thread will traverse and get multiple nodes of its own according to the transferIndex task tag number * fh Hash of nodes traversed each time */ for (int i = 0, bound = 0;;) { Node<K,V> f; int fh; /** * @(1)It mainly synchronizes the transferIndex to the bound, and then continuously explains the progress of task execution * Each expansion thread gets the task number transferIndex first * Let the concurrent expansion thread get the transferIndex and get the migration task */ while (advance) { //Update migration index i. int nextIndex, nextBound; /** * The loop needs to exit directly after the completion of marking */ if (--i >= bound || finishing) advance = false; /** * transferIndex<=0 Indicates that there is no hash bucket to be migrated. Set i to - 1, and the thread is ready to exit */ else if ((nextIndex = transferIndex) <= 0) { i = -1; advance = false; } /* * Update your own bound try to update transferIndex */ else if (U.compareAndSwapInt (this, TRANSFERINDEX, nextIndex, nextBound = (nextIndex > stride ? nextIndex - stride : 0))) { bound = nextBound; i = nextIndex - 1; advance = false; } } /** * @Using algorithm to determine whether all hash pokes have been migrated */ if (i < 0 || i >= n || i + n >= nextn) { int sc; /** * @If you have finished copying * Just assign nextTable to null, and the table pointer points to our nextTab * Then the expansion threshold increases */ if (finishing) { nextTable = null; table = nextTab; sizeCtl = (n << 1) - (n >>> 1); return; } if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) { if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT) return; finishing = advance = true; i = n; // recheck before commit } } /** * Empty node direct insertion */ else if ((f = tabAt(tab, i)) == null) advance = casTabAt(tab, i, null, fwd); /** * If you traverse to the ForwardingNode node, it means that this point has been processed, and you can skip it directly */ else if ((fh = f.hash) == MOVED) advance = true; // already processed /** * Non empty node expansion needs to be locked, but it is very detailed that the object locks its own threads effectively (the task division of each thread is not the same), which realizes the segmented locking */ else { synchronized (f) { if (tabAt(tab, i) == f) { Node<K,V> ln, hn; if (fh >= 0) { int runBit = fh & n; Node<K,V> lastRun = f; for (Node<K,V> p = f.next; p != null; p = p.next) { int b = p.hash & n; if (b != runBit) { runBit = b; lastRun = p; } } if (runBit == 0) { ln = lastRun; hn = null; } else { hn = lastRun; ln = null; } for (Node<K,V> p = f; p != lastRun; p = p.next) { int ph = p.hash; K pk = p.key; V pv = p.val; if ((ph & n) == 0) ln = new Node<K,V>(ph, pk, pv, ln); else hn = new Node<K,V>(ph, pk, pv, hn); } setTabAt(nextTab, i, ln); setTabAt(nextTab, i + n, hn); setTabAt(tab, i, fwd); advance = true; } else if (f instanceof TreeBin) { TreeBin<K,V> t = (TreeBin<K,V>)f; TreeNode<K,V> lo = null, loTail = null; TreeNode<K,V> hi = null, hiTail = null; int lc = 0, hc = 0; for (Node<K,V> e = t.first; e != null; e = e.next) { int h = e.hash; TreeNode<K,V> p = new TreeNode<K,V> (h, e.key, e.val, null, null); if ((h & n) == 0) { if ((p.prev = loTail) == null) lo = p; else loTail.next = p; loTail = p; ++lc; } else { if ((p.prev = hiTail) == null) hi = p; else hiTail.next = p; hiTail = p; ++hc; } } ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) : (hc != 0) ? new TreeBin<K,V>(lo) : t; hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) : (lc != 0) ? new TreeBin<K,V>(hi) : t; setTabAt(nextTab, i, ln); setTabAt(nextTab, i + n, hn); setTabAt(tab, i, fwd); advance = true; } } } } } }
ConcurrentHashMap -- key combing
The implementation of segmented lock: jdk7 is implemented with built-in lock lock after it is divided into two arrays, while jdk8 is implemented with task segmentation using tranferIndex, each key lock only locks its own thread to realize segmented lock;
When inserting: if it is marked as a Forward node, it can expand its capacity and increase its capacity expansion efficiency. In addition, common nodes directly use cas, red black trees and linked lists to lock their own nodes with keywords, with smaller lock granularity
When obtaining: if you are expanding the capacity, you can use the find method of Forward node to obtain quickly and enhance the consistency;
Number of updates: if concurrent updates compete for an array, a cell thread will be generated, similar to the principle of long adder's concurrent implementation to merge the final update results;
size return: so the actual number of threads is the sum of baseCount and the number of threads that are still fullAddCount;
Capacity expansion mechanism: first, determine null with nextTab to determine twice the initialization of nextTab array; then use two counters, one represents the current hash migration progress, and the other represents the index boundary; the overall size of strcip task is determined according to the idle cpu, and then each thread will continue to cas to obtain its own split task size, tranferIndex After the synchronization, some processing is done for the bound. Finally, the for loop + i is continued until the current thread completes the capacity expansion task. The next task may continue to be acquired. finshing is used to determine whether all nodes have been migrated;
GodSchool
We are committed to simple knowledge engineering and output high-quality knowledge output. Let's work together
Blogger's personal wechat: superlzf