Article reference: Xiao Liu speaks the source code
Source code analysis of ConcurrentHashMap_ 01 member attribute, internal class and construction method resolution
1. Introduction
- ConcurrentHashMap is a thread safe version of HashMap. Internally, it also uses the structure of (array + linked list + red black tree) to store elements. Compared with HashTable with the same thread safety, the efficiency and other aspects have been greatly improved.
- Before learning the source code of ConcurrentHashMap, by default, you have read the source code of HashMap to understand the LongAdder atomic class and red black tree. reference resources: Red black tree learning notes (implement a simple red black tree by yourself),Detailed analysis of HashMap underlying source code,JDK collection LinkedHashMap source code analysis,Source code analysis of LongAdder, a new feature of JDK 8
First, briefly introduce the overall process of ConcurrentHashMap:
The overall process is similar to that of HashMap, which consists of the following steps:
- If the bucket array is not initialized, it will be initialized;
- If the bucket where the element to be inserted is empty, try to insert this element directly into the first position in the bucket;
- If capacity expansion is in progress, the current thread will be added to the process of capacity expansion;
- If the bucket of the element to be inserted is not empty and there are no migrated elements, lock the bucket (segment lock)
- If the element in the current bucket is stored in a linked list, look for the element or insert the element in the linked list;
- If the element in the current bucket is stored as a red black tree, look for the element or insert the element in the red black tree;
- If the element exists, the old value is returned
- If the element does not exist, add 1 to the element of the whole Map and check whether it needs to be expanded;
The locks used in the operation of adding elements mainly include (spin lock + CAS + synchronized + segmented lock).
Why use synchronized instead of ReentrantLock?
Because synchronized has been greatly optimized, it is no worse than ReentrantLock in specific cases.
2,JDK1. 8 structure diagram of concurrenthashmap
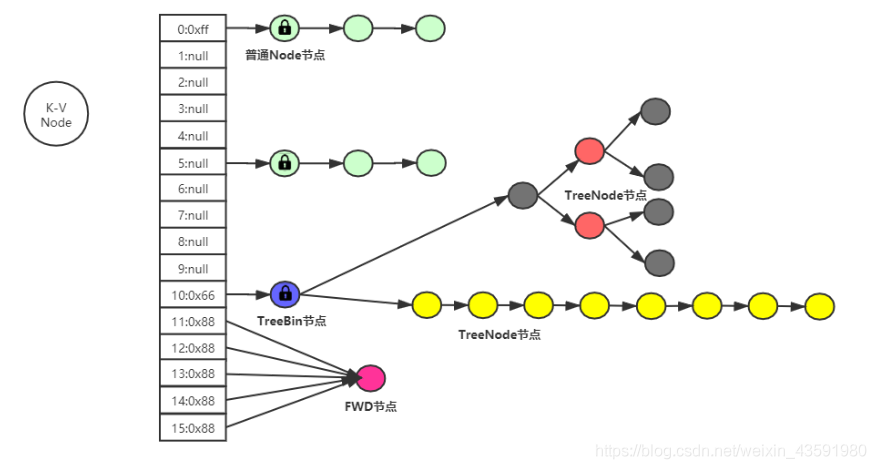
3. Member properties
/** * Hash table array maximum limit */ private static final int MAXIMUM_CAPACITY = 1 << 30; /** * Hash table defaults */ private static final int DEFAULT_CAPACITY = 16; /** * Maximum supported array length, MAX_INTEGER_VALUE */ static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8; /** * Concurrency level: jdk1 7 left over, jdk1 8. It is only used during initialization, which does not represent the concurrency level */ private static final int DEFAULT_CONCURRENCY_LEVEL = 16; /** * Load factor, jdk1 In 8, ConcurrentHashMap is a fixed value */ private static final float LOAD_FACTOR = 0.75f; /** * Tree threshold. If the length of the specified bucket linked list reaches 8, tree operation may occur */ static final int TREEIFY_THRESHOLD = 8; /** * The threshold value of red black tree into linked list */ static final int UNTREEIFY_THRESHOLD = 6; /** * Joint tree_ Threshold controls whether the bucket is trealized. Only when the length of the table array reaches 64 and the length of the linked list in a bucket reaches 8 can it be truly trealized */ static final int MIN_TREEIFY_CAPACITY = 64; /** * The minimum step size of thread migration data controls the minimum interval of thread migration tasks */ private static final int MIN_TRANSFER_STRIDE = 16; /** * Related to capacity expansion, an identification stamp generated during capacity expansion calculation */ private static int RESIZE_STAMP_BITS = 16; /** * 65535,Indicates the maximum number of threads for concurrent capacity expansion */ private static final int MAX_RESIZERS = (1 << (32 - RESIZE_STAMP_BITS)) - 1; /** * Capacity expansion correlation */ private static final int RESIZE_STAMP_SHIFT = 32 - RESIZE_STAMP_BITS; /* * Encodings for Node hash fields. See above for explanation. */ // When the hash value of the node node is - 1, it indicates that the current node is an FWD node static final int MOVED = -1; // hash for forwarding nodes // When the hash value of the node node is - 2, it indicates that the current node has been trealized and the current node is a TreeBin object. The TreeBin object agent operates the red black tree static final int TREEBIN = -2; // hash for roots of trees static final int RESERVED = -3; // hash for transient reservations // 0x7fffffff = > 0111 1111 1111 1111 1111 1111 1111 1111 a negative number can be obtained by bit sum operation, but many take absolute values static final int HASH_BITS = 0x7fffffff; // usable bits of normal node hash // Number of CPU s in the current system static final int NCPU = Runtime.getRuntime().availableProcessors(); // The length of hash table object must be the power of 2 transient volatile Node<K,V>[] table; // In the process of capacity expansion, the new table in the capacity expansion will be assigned to nextTable to keep the reference. After the capacity expansion, it will be set to null private transient volatile Node<K,V>[] nextTable; // The baseCount in the LongAdder. When there is no competition or the current LongAdder is locked, the increment is accumulated to the baseCount private transient volatile long baseCount; /** * sizeCtl < 0 * 1.-1 Indicates that the current table is initializing (a thread is creating a table array) and the current thread needs to wait * 2.Indicates that the current map is being expanded. The high 16 bits indicate the ID stamp of the expansion. The low 16 bits indicate: (1 + nThread) the number of threads participating in concurrent expansion * * sizeCtl == 0 Indicates that default is used when creating a table array_ Capability is the size * * sizeCtl > 0 * 1. If the table is not initialized, it indicates the initialization size * 2. If the table has been initialized, it indicates the trigger condition (threshold) for the next capacity expansion */ private transient volatile int sizeCtl; // During capacity expansion, the current progress is recorded. All threads need to allocate interval tasks from transferIndex to execute their own tasks private transient volatile int transferIndex; // cellsBusy 0 in LongAdder indicates that the current LongAdder object is unlocked, and 1 indicates that it is locked private transient volatile int cellsBusy; // The cells array in LongAdder. When the baseCount competes, the cells array will be created // In the case of multithreading, the thread will get its own cell location by calculating the hash value and accumulate the increment to the cell // Total number = sum(cells) + baseCount private transient volatile CounterCell[] counterCells;
4. Static properties
// Unsafe mechanics private static final sun.misc.Unsafe U; // Represents the memory offset address of sizeCtl attribute in ConcurrentHashMap private static final long SIZECTL; // Indicates the memory offset address of the transferIndex attribute in the ConcurrentHashMap private static final long TRANSFERINDEX; // Represents the memory offset address of baseCount attribute in ConcurrentHashMap private static final long BASECOUNT; // Indicates the memory offset address of the cellsbusy attribute in the ConcurrentHashMap private static final long CELLSBUSY; // Represents the memory offset address of the cellsvalue attribute in the CounterCell private static final long CELLVALUE; // Represents the offset address of the first element of the array private static final long ABASE; // This attribute is used for array addressing. You can understand it by reading further private static final int ASHIFT;
5. Static code block
static {
try {
U = sun.misc.Unsafe.getUnsafe();
Class<?> k = ConcurrentHashMap.class;
SIZECTL = U.objectFieldOffset
(k.getDeclaredField("sizeCtl"));
TRANSFERINDEX = U.objectFieldOffset
(k.getDeclaredField("transferIndex"));
BASECOUNT = U.objectFieldOffset
(k.getDeclaredField("baseCount"));
CELLSBUSY = U.objectFieldOffset
(k.getDeclaredField("cellsBusy"));
Class<?> ck = CounterCell.class;
CELLVALUE = U.objectFieldOffset
(ck.getDeclaredField("value"));
Class<?> ak = Node[].class;
// Get the offset address of the first element of the array
ABASE = U.arrayBaseOffset(ak);
// Represents the space occupied by each cell in the array, that is, scale represents the space occupied by each cell in the Node [] array
int scale = U.arrayIndexScale(ak);
// (scale & (scale - 1)) != 0: judge whether the value of scale is a secondary idempotent of 2
// In the java language specification, the scale calculated in the array must be a secondary idempotent of 2
// 1 0000 % 0 1111 = 0
if ((scale & (scale - 1)) != 0)
throw new Error("data type scale not a power of two");
// numberOfLeadingZeros(scale) according to scale, after the current value is returned and converted into binary, the statistics will start from the high position to the status. The statistics will show how many zeros are in one piece continuously: eg, 8, binary = > 1000, then the result of numberOfLeadingZeros(8) is 28. Why? Because Integer is 32 bits and 1000 occupies 4 bits, there are 32-4 zeros in front, that is, the number of consecutive longest zeros is 28
// 4 convert binary = > 100, then the result of numberOfLeadingZeros(8) is 29
// ASHIFT = 31 - Integer.numberOfLeadingZeros(4) = 2. What is the function of ashift? In fact, it has a function of array addressing:
// Get the offset address (storage address) of the Node [] array element with subscript 5: assume that the ashift calculated according to scale = 2
// Abase + (5 < < ashift) = = abase + (5 < < 2) = = abase + 5 * scale, the offset address of the array element with subscript 5 is obtained
ASHIFT = 31 - Integer.numberOfLeadingZeros(scale);
} catch (Exception e) {
throw new Error(e);
}
}
6. Inner class
6.1 Node
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
// Save memory visibility
volatile V val;
volatile Node<K,V> next;
Node(int hash, K key, V val, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.val = val;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return val; }
public final int hashCode() { return key.hashCode() ^ val.hashCode(); }
public final String toString(){ return key + "=" + val; }
public final V setValue(V value) {
throw new UnsupportedOperationException();
}
// Here, equals is accessed by comparing with the Entry node
public final boolean equals(Object o) {
Object k, v, u; Map.Entry<?,?> e;
return ((o instanceof Map.Entry) &&
(k = (e = (Map.Entry<?,?>)o).getKey()) != null &&
(v = e.getValue()) != null &&
(k == key || k.equals(key)) &&
(v == (u = val) || v.equals(u)));
}
/**
* Virtualized support for map.get(); overridden in subclasses.
*/
Node<K,V> find(int h, Object k) {
Node<K,V> e = this;
if (k != null) {
do {
K ek;
if (e.hash == h &&
((ek = e.key) == k || (ek != null && k.equals(ek))))
return e;
} while ((e = e.next) != null);
}
return null;
}
}
6.2. ForwardingNode node
This internal class will be explored in detail when analyzing and expanding the capacity later. Let's get familiar with it first:
// If it is a write thread (eg: concurrent capacity expansion thread), you need to contribute to creating a new table
// If it is a read thread, call the find(int h, Object k) method of the inner class
static final class ForwardingNode<K,V> extends Node<K,V> {
// nextTable represents a reference to the new hash table
final Node<K,V>[] nextTable;
ForwardingNode(Node<K,V>[] tab) {
super(MOVED, null, null, null);
this.nextTable = tab;
}
// Read the data on the new table
Node<K,V> find(int h, Object k) {
// loop to avoid arbitrarily deep recursion on forwarding nodes
outer: for (Node<K,V>[] tab = nextTable;;) {
Node<K,V> e; int n;
if (k == null || tab == null || (n = tab.length) == 0 ||
(e = tabAt(tab, (n - 1) & h)) == null)
return null;
for (;;) {
int eh; K ek;
if ((eh = e.hash) == h &&
((ek = e.key) == k || (ek != null && k.equals(ek))))
return e;
if (eh < 0) {
if (e instanceof ForwardingNode) {
tab = ((ForwardingNode<K,V>)e).nextTable;
continue outer;
}
else
return e.find(h, k);
}
if ((e = e.next) == null)
return null;
}
}
}
}
6.3 TreeNode node
This node will be used in TreeBin, which will be described in detail later:
static final class TreeNode<K,V> extends Node<K,V> {
// Parent node
TreeNode<K,V> parent; // red-black tree links
// Left child node
TreeNode<K,V> left;
// Right node
TreeNode<K,V> right;
// Precursor node
TreeNode<K,V> prev; // needed to unlink next upon deletion
// Nodes have two colors: red and black~
boolean red;
TreeNode(int hash, K key, V val, Node<K,V> next,
TreeNode<K,V> parent) {
super(hash, key, val, next);
this.parent = parent;
}
Node<K,V> find(int h, Object k) {
return findTreeNode(h, k, null);
}
/**
* Returns the TreeNode (or null if not found) for the given key
* starting at given root.
*/
final TreeNode<K,V> findTreeNode(int h, Object k, Class<?> kc) {
if (k != null) {
TreeNode<K,V> p = this;
do {
int ph, dir; K pk; TreeNode<K,V> q;
TreeNode<K,V> pl = p.left, pr = p.right;
if ((ph = p.hash) > h)
p = pl;
else if (ph < h)
p = pr;
else if ((pk = p.key) == k || (pk != null && k.equals(pk)))
return p;
else if (pl == null)
p = pr;
else if (pr == null)
p = pl;
else if ((kc != null ||
(kc = comparableClassFor(k)) != null) &&
(dir = compareComparables(kc, k, pk)) != 0)
p = (dir < 0) ? pl : pr;
else if ((q = pr.findTreeNode(h, k, kc)) != null)
return q;
else
p = pl;
} while (p != null);
}
return null;
}
}
7. Construction method
public ConcurrentHashMap() {
}
public ConcurrentHashMap(int initialCapacity) {
if (initialCapacity < 0)
throw new IllegalArgumentException();
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
MAXIMUM_CAPACITY :
tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
this.sizeCtl = cap;
}
public ConcurrentHashMap(Map<? extends K, ? extends V> m) {
this.sizeCtl = DEFAULT_CAPACITY;
putAll(m);
}
public ConcurrentHashMap(int initialCapacity, float loadFactor) {
this(initialCapacity, loadFactor, 1);
}
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (initialCapacity < concurrencyLevel) // Use at least as many bins
initialCapacity = concurrencyLevel; // as estimated threads
long size = (long)(1.0 + (long)initialCapacity / loadFactor);
int cap = (size >= (long)MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY : tableSizeFor((int)size);
this.sizeCtl = cap;
}
By comparing the construction method with HashMap, it can be found that instead of threesold and loadFactor in HashMap, sizaCtl is used to control and only stored in the capacity. How is it used? The official explanation is as follows:
- -1 indicates that a thread is initializing.
- -(1 + nThreads), indicating that n threads are expanding together.
- 0, the default value. The default capacity is used for subsequent real initialization.
- >0, the next expansion threshold after initialization or expansion.
8. Internal small method analysis
Before formally analyzing the concurrent HashMap member methods, first analyze the sub methods and functions in some internal classes:
First, let's take a look at the calculation method spread(int h) of hash member attribute value in the internal class Node of ConcurrentHashMap:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;// This attribute is calculated by the spread(int h) method ~ H stands for key
final K key;
volatile V val;
volatile Node<K,V> next;
Node(int hash, K key, V val, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.val = val;
this.next = next;
}
...
}
8.1. spread(int h) method
// Disturbance function
/**
* Algorithm for calculating Node hash value: hash value with parameter h
* eg:
* h Binary: - > 1100 0011 1010 0101 0001 1100 0001 1110
* (h >>> 16) --> 0000 0000 0000 0000 1100 0011 1010 0101
* (h ^ (h >>> 16)) --> 1100 0011 1010 0101 1101 1111 1011 1011
* Note: (h ^ (h > > > 16)) the purpose is to let the high 16 bits of h also participate in addressing, so as to make the obtained hash values more scattered and reduce the number of hash conflicts
* --------------------------------------------------------------------------------------
* HASH_BITS --> 0111 1111 1111 1111 1111 1111 1111 1111
* (h ^ (h >>> 16)) --> 1100 0011 1010 0101 1101 1111 1011 1011
* (h ^ (h >>> 16)) & HASH_BITS 0100 0011 1010 0101 1101 1111 1011 1011
* Note that the results obtained by (H ^ (H > > > 16)) are in & hash_ Bits. The purpose is to make the obtained hash value always be a positive number
*/
static final int spread(int h) {
// Move the original hash value XOR ^ 16 bits to the right of the original hash value, and then & up hash_ Bits (0x7fffff: 31 bits 1)
return (h ^ (h >>> 16)) & HASH_BITS;
}
The following describes the tabat (Node < K, V > [] tab, int i) method: get the Node with the specified subscript i in the tab[Node []] array.
8.2. tabAt (node < K, V > [] tab, int i) method
/**
* Gets the Node element of the specified subscript position i in the tab(Node []) array
* Node<K,V> tab:Represents a Node [] array
* int i: Represents an array subscript
*/
@SuppressWarnings("unchecked")
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {
// ((long) I < < ashift) + abase: please see the following analysis
return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
}
When analyzing ((long) I < < ashift) + abase, first review the meanings of some static attribute fields introduced above:
// Class object of Node array
Class<?> ak = Node[].class;
// U.arrayBaseOffset(ak): obtain the offset address of the first element of NOde [] array according to ak
ABASE = U.arrayBaseOffset(ak);
// Represents the space occupied by the array cells, and scale represents the space occupied by each cell in the Node [] array
int scale = U.arrayIndexScale(ak);
// In the java language, scale must be the power of two. Here is a small algorithm to judge whether scale is the power of two
// If not, an error is reported
if ((scale & (scale - 1)) != 0)
throw new Error("data type scale not a power of two");
// numberOfLeadingZeros(scale): according to scale, after the current value returned is converted into bit binary, note here (the value of scale must be the power of 2), count from the high order to the low order, and count how many zeros are in a row
// Eg: 8 - > 1000, then the value of numberOfLeadingZeros(8) is 28. Why? Because Integer is 32 bits and 1000 occupies 4 bits, there are 32-4 zeros in front, that is, the number of consecutive longest zeros is 28
// 4 - > 100, then the value of numberOfLeadingZeros(4) is 29
// ASHIFT = 31 - Integer.numberOfLeadingZeros(4) = 2, what is the function of ashift? In fact, it has a function of array addressing:
// Get the offset address (storage address) of the Node [] array element with subscript 5: assume that the ashift calculated according to scale = 2
// ASHIFT is mainly used for memory addressing. If we want to find the address of the 6th bucket, ABSE + 5 * scale
// Convert to abase + (5 < < ashift)
ASHIFT = 31 - Integer.numberOfLeadingZeros(scale);
From the review and introduction of the above attribute fields, it is not difficult to find out:
- ((long) i < < ashift) + base is to get the offset address of the Node object whose subscript is i in the current Node [] array.
- Then, through the (Node < K, V >) u.getobjectvolatile (tab, ((long) i < < ashift) + abase) method, the Node object with subscript i is obtained according to the two parameters of Node [] and the offset address of the target Node.
- Although this is very convoluted, it is not as simple as using multiplication directly, but it is more efficient to find array elements directly according to the offset address.
8.3. casTabAt (node < K, V > [] tab, int i) method
/**
* Set the Node value to the specified position i of the Node array through CAS. If the setting is successful, return true; otherwise, return false
* Node<K,V>[] tab: Represents a Node [] array
* int i: Represents an array subscript
* Node<K,V> c: Expected node value
* Node<K,V> v: Node value to set
*/
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,
Node<K,V> c, Node<K,V> v) {
// Call Unsafe comparison and exchange to set the Node value at the specified position of Node [] array. The parameters are as follows:
// tab: Node [] array
// ((long) I < < ashift) + abase: offset address of array bucket with subscript i
// c: Expected node value
// v: The new value of the node to set
return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
}
8.4. Settabat (node < K, V > [] tab, int i, node < K, V > V) method
/**
* Set the Node value of the specified subscript position of the Node [] array according to the array subscript:
* Node<K,V>[] tab: Represents a Node [] array
* int i: Represents an array subscript
* Node<K,V> v: Node value to set
*/
static final <K,V> void setTabAt(Node<K,V>[] tab, int i, Node<K,V> v) {
// ((long) i < < ashift) + abase: the index is the offset address of the i array bucket
U.putObjectVolatile(tab, ((long)i << ASHIFT) + ABASE, v);
}
8.5. resizeStamp(int n) method
// When the table array is expanded, an expansion ID stamp is calculated. When concurrent expansion is required, the current thread must get the expansion ID stamp to participate in the expansion
static final int resizeStamp(int n) {
// RESIZE_STAMP_BITS: fixed value 16, which is related to capacity expansion. When calculating capacity expansion, a capacity expansion identification stamp will be generated according to the attribute value
return Integer.numberOfLeadingZeros(n) | (1 << (RESIZE_STAMP_BITS - 1));
}
For example:
- When we need to expand the table capacity from 16 to 32, integer Numberofleadingzeros (16) will get 27. How did you get it?
- numberOfLeadingZeros(n) returns the current value according to the passed in N. after it is converted into binary, statistics will be made from high to low, and the number of zeros will be counted continuously:
- eg: 16 convert binary = > 1 0000, then the result of numberOfLeadingZeros(16) is 27. Because Integer is 32 bits and 1 0000 accounts for 5 bits, there are 32 - 5 zeros in front, that is, the longest number of consecutive zeros is 27.
- numberOfLeadingZeros(n) returns the current value according to the passed in N. after it is converted into binary, statistics will be made from high to low, and the number of zeros will be counted continuously:
- 1 < < (RESIZE_STAMP_BITS - 1): where resize_ STAMP_ Bits is a fixed value of 16, which is related to capacity expansion. When calculating capacity expansion, a capacity expansion identification stamp will be generated according to the attribute value
- Let's calculate:
// From 16 to 32 16 -> 32 numberOfLeadingZeros(16) => 1 0000 => 27 => 0000 0000 0001 1011 // Represented by B: (1 << (RESIZE_STAMP_BITS - 1)) => (1 << (16 - 1)) => 1000 0000 0000 0000 => 32768 // A | B Integer.numberOfLeadingZeros(n) | (1 << (RESIZE_STAMP_BITS - 1)) ----------------------------------------------------------------- 0000 0000 0001 1011 ---> A 1000 0000 0000 0000 ---> B ------------------- ---> | Bitwise OR 1000 0000 0001 1011 ---> The capacity expansion identification stamp is calculated
8.6. tableSizeFor(int c) method
/**
* Returns the smallest power of 2 greater than or equal to c
* eg: c = 28
* n = c - 1 = 27 -> 0b11011
* n |= n >>> 1
* n => 11011 |= 01101 => 11111
* n |= n >>> 2
* n => 11111 |= 00111 => 11111
* ...
* => 1111 + 1 = 32
*/
private static final int tableSizeFor(int c) {
int n = c - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
8.7 construction method
// Nonparametric construction method
public ConcurrentHashMap() {
}
// Specify initialization capacity
public ConcurrentHashMap(int initialCapacity) {
// Judge whether the initial length of a given array is less than 0. If it is less than 0, an exception will be thrown directly
if (initialCapacity < 0)
throw new IllegalArgumentException();
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
MAXIMUM_CAPACITY :
tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
// sizeCtl>0
// When size is initialized, sizeCtl indicates the initialization capacity
this.sizeCtl = cap;
}
// Initialize according to a Map collection
public ConcurrentHashMap(Map<? extends K, ? extends V> m) {
// Sizecl is set to the default capacity value
this.sizeCtl = DEFAULT_CAPACITY;
putAll(m);
}
// Specify initialization capacity and load factor
public ConcurrentHashMap(int initialCapacity, float loadFactor) {
this(initialCapacity, loadFactor, 1);
}
// Specify initialization capacity, load factor, and concurrency level
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
// When the specified initialization capacity initialCapacity is less than the concurrency level concurrencyLevel
if (initialCapacity < concurrencyLevel) // Use at least as many bins
// The value of initialization capacity is set to the value of concurrency level
// That is, jdk1 After 8, the concurrency level is determined by the hash table length
initialCapacity = concurrencyLevel; // as estimated threads
// Calculate the size according to the initialization capacity and load factor
long size = (long)(1.0 + (long)initialCapacity / loadFactor);
// Recalculate array initialization capacity based on size
int cap = (size >= (long)MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY : tableSizeFor((int)size);
/**
* sizeCtl > 0
* When the current table is uninitialized, sizeCtl indicates the initialization capacity
*/
this.sizeCtl = cap;
}
So far, the preparation for source code analysis of ConcurrentHashMap has been completed, and some of the more troublesome methods will be updated later.